オートスケーリング - Horizontal Pod Autoscaler(HPA)
Back to Top商用環境で実際にサービスが運用されると、時間帯やイベント等、様々な要因によってトラフィックが変動し、それに合わせてシステム負荷も増減します。
コンテナ以前の従来のシステムでは、あらかじめ最大のスループットを見積もり、それに合わせてサーバーのサイジングをすることが一般的でした。
ただ、これはほとんどのケースでオーバースペックとなり、費用対効果が良いとは言えない状況でした。
また、いざサーバーを増やすとなると調達やセットアップ等のリードタイムがかかり、変化の激しいビジネス要求に追従していくのが難しい状況でした。
この状況はコンテナ技術の登場で大きく変わりました。
軽量なコンテナは、必要な実行環境がイメージとして含まれていますので、コンテナランタイム環境があればすぐにデプロイ可能で、高価なサーバーは不要です。
このような特性は負荷に応じた即時のオートスケールを容易にし、Kubernetesを始めとするほとんどのコンテナオーケストレーションツールではオートスケール機能が備わっています。
Kubernetesには、以下の2種類のオートスケーリング機能があります。
Cluster Auto Scaling
Cluster Auto ScalingはPodがスケジュールできない状況になったとき、クラウドプロバイダが提供するAPIを通して自動でNodeを追加します。
また、負荷状況が改善され、NodeがオーバースペックとなったらNodeを削減します。
Kubernetesでは、公式のCluster Autoscalerが利用できます。
主要なクラウドプロバイダに対応していますので、対応したクラウド環境を利用している場合は、別途導入しておくと良いでしょう。
AWSは2021/11にKarpenterという新しい仕組みのOSSをGAリリースしました。
これはCluster Autoscalerを超える高速スケールに加えて、クラウドプロバイダの提供する機能をフル活用できる柔軟性を備えています。AWS EKSでの利用の場合はこちらを第一候補とすると良いかと思います。
Karpenterについては、別の記事で紹介していますので、興味がある方はこちらを参照してください。
Pod Auto Scaling
もう1つのPod Auto Scalingは、CPU使用率等のメトリクスを収集し、Podレベルでスケーリングします。
水平方向か垂直方向かで2種類のオートスケール機能が提供されています。
- Horizontal Pod Autoscaler(HPA)
- Vertical Pod Autoscaler(VPA)
Horizontal Pod Autoscaler(HPA)は、その名の通り水平方向のオートスケーラです。
CPUやメモリの使用率等のメトリクスを監視し、しきい値を超えた場合にPodのレプリカ数を増やしてスケールアウトさせます。
逆に、しきい値を下回った場合はレプリカ数を下げて、オーバースペックにならないよう調整します。
使用するメトリクスはPrometheus等、多様なメトリクスも利用できます。
Vertical Pod Autoscaler(VPA)はレプリカ数ではなく、Podのリソーススペック(resources.requests)を調整します。
こちらは、長らくBetaステータスで、別途VPAコントローラの導入が必要です[1]。
今回は最も利用されていることが多いであろうHorizontal Pod Autoscaler(HPA)を導入し、その動きを見ていきましょう。
事前準備
#ここではAWS EKSで実施しますが、HPAはビルトインで組み込まれていますのでminikube等のローカル環境でも実行可能です。
また、アプリケーションにアクセスするためのIngress Controllerも別途用意してください。今回はNGINX Ingress Controllerを使用します。
メトリクスサーバー導入
#HPAはメトリクスを収集して、Podのオートスケールを行います。
今回はCPU使用率にもとづいたオートスケールをします。
まずは、メトリクスを収集するための仕組みを事前に入れておく必要があります。
これに対応するMetrics Serverを導入しましょう。
HPAではPodのメトリクス以外にもリクエストスループットや外部のメトリクスにもとづいたスケール機能も備わっています。
これを利用する場合は、メトリクス収集のためのCustom Metrics APIを実装するプロダクトの導入が別途必要です。
たとえば、Prometheusのメトリクス収集には、Prometheus Adapterがあります。
また、さらに柔軟なオートスケールを実現する、KEDAというプロダクトがあります。
こちらもCustom Metrics APIを実装しており、CloudWatch等の多様なメトリクスに対応可能です。
KEDAもスケールの仕組みにはHPAを使いますが、現時点(v1.23)のHPAデフォルトでは実現できない(Alphaステータス)ゼロスケールにも対応しています。
Metrics ServerもHelmチャートが提供されていますので、こちらを利用します。
まずは、Helmチャートのリポジトリを登録します。
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/
helm repo update
続いて、Metrics Serverをインストールします。以下は現時点で最新の3.8.0のチャートを使用しています。
特にパラメータは指定不要です(最低限の構成)。
helm upgrade metrics-server metrics-server/metrics-server \
--install --version 3.8.0 \
--namespace metrics-server --create-namespace \
--wait
インストールが終わったら、Metrics Serverの状況を見てみましょう。
kubectl get pod -n metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-79c48b9c97-snsb5 1/1 Running 0 44s
Metrics Serverが、実行中であることが確認できます。
Metrics Serverを導入すると、kubectlでNode/Podのメトリクスを確認できます。
例えば、Nodeのメトリクスを確認する場合は、以下のコマンドを実行します。
kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ip-192-168-38-243.ap-northeast-1.compute.internal 41m 2% 597Mi 8%
ip-192-168-89-125.ap-northeast-1.compute.internal 45m 2% 639Mi 9%
kubectl describe nodeよりも簡単に各NodeのCPU/メモリの使用状況が分かります。
サンプルアプリデプロイ
#オートスケール対象のサンプルアプリをデプロイします。ここではシンプルなモックAPIサーバーであるhttpbinを利用します。
以下のマニフェストファイル(app.yaml)を用意します。
kind: Deployment
apiVersion: apps/v1
metadata:
name: app
labels:
app: app
spec:
replicas: 2
selector:
matchLabels:
app: app
template:
metadata:
name: app
labels:
app: app
spec:
containers:
- name: app
image: kennethreitz/httpbin
ports:
- name: http
containerPort: 80
resources:
requests:
cpu: 20m
---
apiVersion: v1
kind: Service
metadata:
name: app
spec:
selector:
app: app
ports:
- name: http
port: 80
targetPort: http
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: app
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /
backend:
service:
name: app
port:
name: http
pathType: Prefix
注意点としてHPAは、Podの要求スペックから使用率を算出します。
このため、resources.requestsは必ず設定する必要があり、未設定の場合はオートスケールされません。
ここではCPU使用率ベースのスケールを行うため、20m(0.02コア)を要求スペックとしました。
それ以外はシンプルなので説明は不要でしょう。
このモックAPIはIngress(NGINX Ingress Controller)経由でアクセスできるようにしています。
このアプリをデプロイしましょう。
kubectl apply -f app.yaml
デプロイ後はNGINXを通してアクセスできるかを確認しましょう。
今回は、カスタムドメインを使用せずに、AWSで自動生成されたドメインでアクセスします(AWS ELBが作成されるまで割当に少し時間がかかります)。
以下を実行して、変数にエンドポイントを設定しておきましょう。
# ADDRESSが割り当てられたことを確認
kubectl get ing app
# ADDRESSを変数に保存
APP_ENDPOINT=$(kubectl get ing app -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')
curlコマンドでアクセスしてみます。
curl -I ${APP_ENDPOINT}/get
HTTP/1.1 200 OKが返ってきていれば、問題ありません。
HorizontalPodAutoscaler(HPA)リソース作成
#それでは作成したアプリに対するオートスケール設定を追加しましょう。
HorizontalPodAutoscalerというリソースを作成します(以下HPAと略します)。
以下のマニフェストファイル(app-hpa.yaml)を作成します。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: app-hpa
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: app
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
behavior:
scaleDown:
stabilizationWindowSeconds: 60 # デフォルトは300(5分)
policies:
- type: Percent
value: 20
periodSeconds: 30
spec配下がオートスケール設定です
まず、maxReplicasで最大レプリカ数、minReplicasで最小レプリカ数を指定します。
minRelicasとDeploymentのreplicasを両方指定するとHPAリソースが優先されます。
scaleTargetRefでオートスケール対象のリソースを指定します。ここで先程作成したアプリを指定します。
最後に、metricsにオートスケール対象のしきい値を指定します。
ここではtype: Resourceとして、Podのリソースフィールド(resources)のCPU使用率を対象に、平均50%と指定しています。
これにより、CPU使用率の全Pod平均値が50%を超えるとオートスケールが起動します。
これ以外にもスループット等のカスタムメトリクスも指定可能です。
カスタムメトリクスの詳細は、こちらを参照してください。
なお、複数メトリクスを指定した場合は、それぞれ評価され、算出されたレプリカ数の大きいしきい値でオートスケールします。
behaviorを指定するとメトリクス収集間隔やスケールダウン/アップの調整可能です。
上記では、スケールダウンの様子を把握するために、負荷が減って1分経過すると、20%ずつ緩やかにスケールダウンするよう調整しました。
詳細はこちらを参照してください。
HPAリソースのapiVersionに注意してください。
ここではKubernetes v1.21で環境構築していますので、それに対応するautoscaling/v2beta2を設定しています。
これ以外にautoscaling/v1も利用できますが、これは古いI/Fのためここでは使用しません。
なお、Kubernetes v1.23からはStableバージョンのautoscaling/v2が利用可能です。
これをクラスタ環境に反映しましょう。
kubectl apply -f app-hpa.yaml
HPAを参照してみましょう。
kubectl get hpa app-hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
app-hpa Deployment/app <unknown>/50% 1 10 0 9s
TARGETSの部分が<unknown>になっています。HPAのメトリクス収集にはタイムラグがありますので、しばらく待ってから再度実施しましょう。
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
app-hpa Deployment/app 3%/50% 1 10 2 81s
このようにTARGETSの部分が3%となり、メトリクスが収集できていることが分かります。
なお、各Podレベルの利用状況はkubectl top podコマンドで確認できます。
NAME CPU(cores) MEMORY(bytes)
app-c4677c7c6-j8dfh 1m 37Mi
app-c4677c7c6-nkkng 1m 37Mi
5分経過すると実行中のPodが1台なります。これはDeploymentではreplicas: 2と指定しましたが、HPAの最小レプリカ数minReplicasで1と指定したからです。
HPAがメトリクスから1レプリカで十分と判断されたためです。
このように両方を指定するとHPAの方が優先されますので、混乱を招かないよう、Deploymentの方は指定しない(またはminReplicasに揃える)方が良いかと思います。
動作確認
#それでは負荷をかけて、Podをオートスケールしてみましょう。
今回負荷をかけるツールとして、loadtestを使用します。
以下コマンドでインストールしておきます。
npm install -g loadtest
オートスケールの様子を見るために、別ターミナルを起動して以下を実行しておきましょう。
kubectl get hpa app-hpa -w
50の並行度で3分間負荷をかけます。また、モックAPIは1秒の遅延させてトラフィックを溢れさせます。
loadtest -c 50 -t 180 -k http://${APP_ENDPOINT}/delay/1
別ターミナルでウォッチしていたHPAの状態は、以下のようになります。
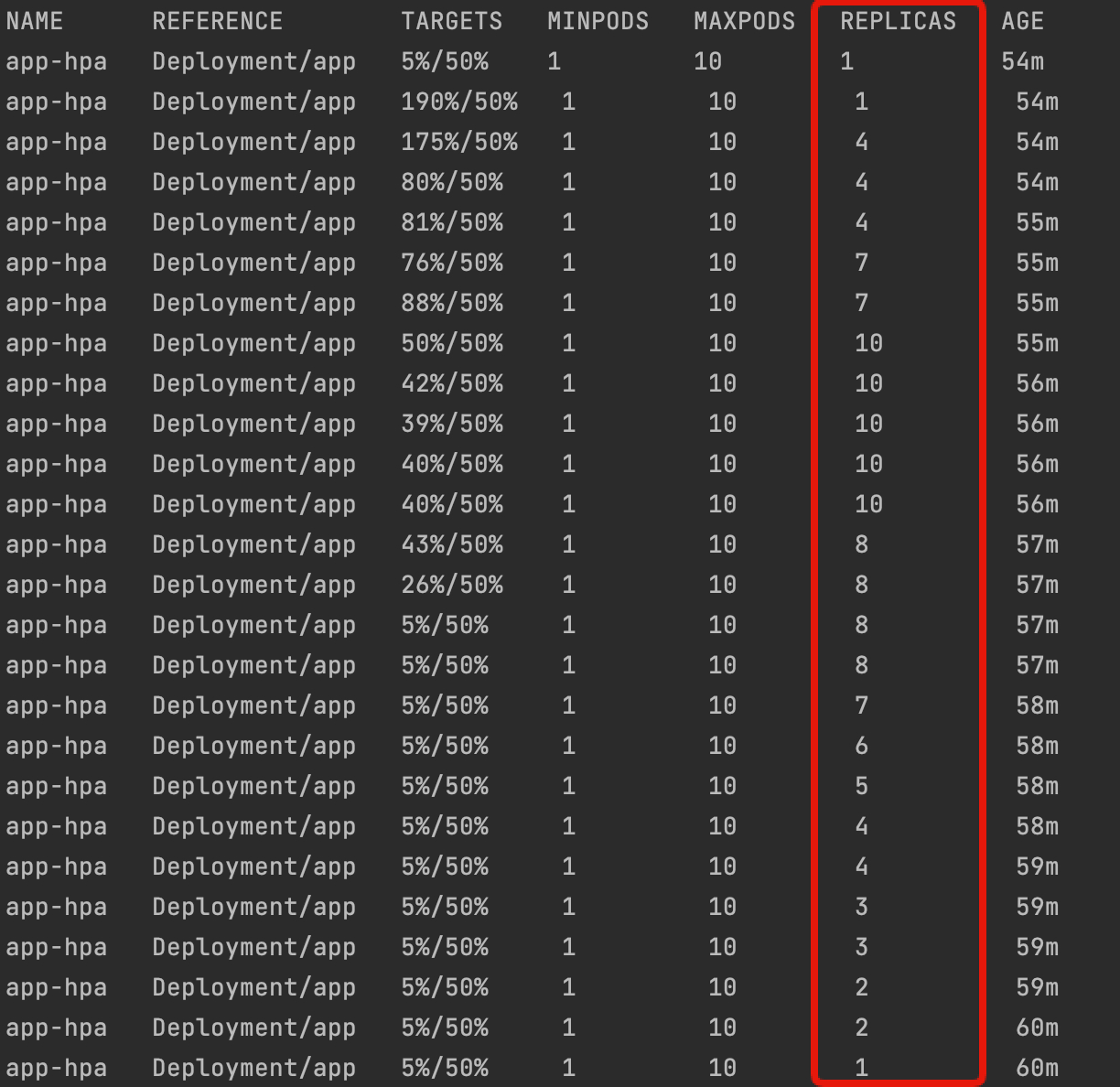
HPAが負荷とともに最小レプリカ1から最大値レプリカの10までPodをスケールさせ、負荷が解消した後は、レプリカ数1まで徐々に減っていることが分かります。
HPAのレプリカ数評価式は以下のようになります(引用元はこちら)。
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
例えば上記2行目は1 * (190 / 50)となり3.8を切り上げて4レプリカが望ましいレプリカ数として算出し、Deployment/ReplicaSet経由でPodを増やしています。
なお、デフォルトでは、現在のレプリカの2倍を上限としてスケールするようになります(この値はHPAのbehaviorで変更可能)。
また、今回スケールダウンは徐々に減るようにカスタム調整しましたが、デフォルトは5分経過後に負荷がない状態であれば一気にスケールダウンします。
behaviorを指定しない場合のデフォルトでは以下のようになります。
flowchart TD
A[Start] --> B["desired replica計算(15秒間隔)"]
B --> C{check}
C -->|current < desired| D["Scale Out\n(2倍 or 4Pod)"] --> B
C -->|current > desired| E{"5分経過?"}
C -->|current = desired| B
E -->|Yes| F["Scale Down\n(100%)"] --> B
E -->|No| Bこの辺りのしきい値を、最初に決めるのはかなり難しいので、負荷試験や実運用を通して継続的に見直していくことが望ましいでしょう。
クリーンアップ
#今回作成したリソースは以下の手順で削除します。
kubectl delete -f app.yaml
kubectl delete -f app-hpa.yaml
helm uninstall metrics-server -n metrics-server
最後にクラスタ環境を削除します。以下のクリーンアップ手順を参照してください。
まとめ
#オートスケールはシステム全体の利用効率を高めるためには必須の機能と言えます。
もちろん、HPAはPodレベルのため、オートスケールはNodeのキャパシティ内という制約があります。
これを解消するためには、Nodeレベルのオートスケーリングを組み合わせることで、現在の負荷状況に応じて臨機応変にシステム全体を調整可能です。
ここで重要なことは、アプリケーションの廃棄容易性です。
オートスケールを利用すると、アプリケーションが頻繁にスケジューリングされることになります。
つまり、アプリケーションのデプロイ・アンデプロイの頻度は確実に増えることになります(もちろん、オートスケールだけが要因とは限りません)。
このため、まずはアプリケーションに安全に停止可能にすることが大切です。突然の停止でデータ不整合等を起こしては意味がありません。
これにはThe Twelve-Factor AppのDisposabilityを参考に、使用している言語・フレームワークに合うように実装するのが良いでしょう。
また、Podのライフサイクルフック(preStop)を利用して、単純にスリープしてアプリケーションのシャットダウン処理に時間的猶予を与えたり、個別にシャットダウン処理を実行するなども考えられます。
さらに、高速なスケールアウトのためには、起動速度も重要です。これには以下の要素を考慮すると良いでしょう。
- コンテナイメージを軽量に保つ(不要なものは入れない)
- 起動時のフットプリントが小さい言語/フレームワークを選択する
- 重量なアプリケーションの初期化処理を遅延させる
参考資料
弊社の社内システムで運用しているEKS on FargateではVPAを利用し、作成されるPod(Fargate Node)のスペックを調整しています。 ↩︎