Karpenterのオートスケールを試してみました
Back to Top2021/11/29に、AWSはKarpenterというKubernetesのオートスケーラーをGAリリースしました。
これは有料のサービスではなく、OSSとしての提供です。現在はAWSのみに対応していますが、構造上はそれ以外のクラウドプロバイダーでも使えるものになっています。
Kubernetesには、既にNodeレベルのオートスケーラーとしてCluster Autoscalerという仕組みがあります。
AWS EKSの場合は、Auto Scaling Group(ASG)の希望のサイズ(Desired Number)を増減させることで、Node(EC2)のスケールアウト・ダウンを実現します。
KarpenterはASG経由ではなく、直接NodeとなるEC2インスタンスをプロビジョニングします。
これにより、現在のCluster Autoscalerと比較して、スケール速度の向上や、ワークロードに応じたインスタンスタイプ選択等、柔軟な指定が可能となっています。
今回はこのKarpenterを使ってNodeのスケールアウト/ダウンを試してみました。
Karpenterインストール
#現時点で最新の0.6.1をセットアップしました。
Karpenterのインストールは、公式ドキュメントに記載されている通りに実施すれば問題ありませんでした。
上記はeksctlですがTerraformで構築したEKSでの利用も可能です。
今回は、以下のeksctl設定でクラスタ環境を作成しました。
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: mz-karpenter
region: ap-northeast-1
version: "1.21"
# ProvisionerのsubnetSelector/securityGroupSelectorで使う
tags:
karpenter.sh/discovery: mz-karpenter
managedNodeGroups:
- name: minimum
# cpu:2 memory:8Gi
instanceType: m5.large
desiredCapacity: 1
iam:
withOIDC: true
KarpenterのProvisionerがサブネット、セキュリティグループを探せるようにtags.karpenter.sh/discoveryを指定しています。
これは、後でProvisionerのセットアップ時に使います。値は他と衝突しなければ任意で構いません。
また、NodeGroupは最小構成(m5.large1台)として、これを超える部分はKarpenterのオートースケールに委ねます。
初期状態のNodeは、以下のようになります。
kubectl get node
NAME STATUS ROLES AGE VERSION
ip-192-168-88-26.ap-northeast-1.compute.internal Ready <none> 24m v1.21.5-eks-9017834
eksctlでASGは1台のみの構成にしましたので、Kubernetes上でも、1Nodeのみが認識されています。
Nodeの詳細を確認してみます。
kubectl describe node <node-name>
以下抜粋です。
Name: ip-192-168-88-26.ap-northeast-1.compute.internal
(省略)
Non-terminated Pods: (6 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
karpenter karpenter-controller-57f49d7db7-fmpmh 1 (51%) 1 (51%) 1Gi (14%) 1Gi (14%) 20m
karpenter karpenter-webhook-6cdfbc74c8-89xxw 100m (5%) 100m (5%) 50Mi (0%) 50Mi (0%) 20m
kube-system aws-node-p74z4 25m (1%) 0 (0%) 0 (0%) 0 (0%) 26m
kube-system coredns-76f4967988-5w222 100m (5%) 0 (0%) 70Mi (0%) 170Mi (2%) 39m
kube-system coredns-76f4967988-7hjbw 100m (5%) 0 (0%) 70Mi (0%) 170Mi (2%) 39m
kube-system kube-proxy-tfp4b 100m (5%) 0 (0%) 0 (0%) 0 (0%) 26m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1425m (73%) 1100m (56%)
memory 1214Mi (17%) 1414Mi (19%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
attachable-volumes-aws-ebs 0 0
(省略)
Control PlaneとKarpenterのPodで、CPUは1.4コアと既に73%が使用中の状態です。
Provisioner作成
#Karpenterを動作するためには、Provisionerカスタムリソースを作成する必要があります。
ここでは、以下の構成でマニフェストを作成しました(provisioner.yaml)。
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
# Spotインスタンスが優先される
values: ["spot", "on-demand"]
# クラスタ全体の制限。Podのlimitで誤った指定した場合の過度なインスタンス生成を抑制
limits:
resources:
cpu: 100
# AWS Providerの設定
provider:
subnetSelector:
karpenter.sh/discovery: mz-karpenter
securityGroupSelector:
karpenter.sh/discovery: mz-karpenter
# 作成したNodeでPodが30秒起動してなければ削除
ttlSecondsAfterEmpty: 30
# Nodeの有効期限(30分)
ttlSecondsUntilExpired: 1800
requirementsには、Karpenterが作成するNode(EC2)の条件を指定します。今回は安価に利用可能なスポットインスタンスの作成を許可するようにしました。
これ以外にも、EC2のインスタンスタイプやAZを限定する等の指定も可能です。指定可能なオプションの詳細は、こちらをご確認ください。
providerには、EC2インスタンスを起動する際のサブネットやセキュリティグループを指定します。
ここでは、クラスタ作成時にeksctlで指定したタグを設定しています。
AWSがサポートされるようになると、ここにクラウドプロバイダー固有の設定が入ると思います。
ttlSecondsAfterEmpty/ttlSecondsUntilExpiredはNodeのスケールダウンに関する設定です。
ttlSecondsAfterEmptyは、Node内にPodが起動していない場合のタイムアウト値です。ここでは、Podがない場合には30秒経過後に対象Nodeを終了するようにしました。
ttlSecondsUntilExpiredを指定すると、Podの起動有無に関係なく、この時間を超えるとNodeは削除されます。
ここで削除されたPodを収容する空き容量が他のNodeにない場合は、結果的にKarpenterが必要なインスタンスタイプを再計算して、Nodeが再作成されます(つまり再スケールアウト)。
今回は、スケールダウンを確認するために、30分とかなり短い値を設定しました。
この指定だと、頻繁にPodが再スケジュールされることになるため、実運用では日単位で指定した方が良いかと思います。
とはいえ、これを設定することで、現在のクラスタ状態に見合ったインスタンスタイプで定期的に見直しできます。
一時的なバーストによるオーバースペックのNode(=高コスト)をいつまでも残しておかないよう、一定のサイクルで更新するようにしておいた方が良さそうです。
スケールダウンの詳細はこちらを参照してください。
この構成でProvisionerを作成しておきます。
kubectl apply -f provisioner.yaml
サンプルPodデプロイ
#今回は、サンプルアプリとしてalpineコンテナでスリープするだけのものをデプロイします。
以下のマニフェスト(app.yaml)を用意します。
kind: Deployment
apiVersion: apps/v1
metadata:
name: app
labels:
app.kubernetes.io/name: app
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: app
template:
metadata:
name: app
labels:
app.kubernetes.io/name: app
spec:
containers:
- name: app
image: alpine:latest
command: [sh, -c, "sleep infinity"]
resources:
requests:
cpu: 500m
memory: 512Mi
初期状態はレプリカ数を1としました。
また、コンテナのスペックはcpu: 500, memory: 512Miとしています(もちろん必要以上に大きな値です)。
これは現状のクラスタ構成にギリギリ収まる範囲です。
サンプルアプリをデプロイします。
kubectl apply -f app.yaml
Podの状態を確認します。
kubectl get pod -o wide
以下必要なフィールドを抜粋して掲載します(以降同様)。
NAME READY STATUS RESTARTS AGE NODE
app-6ffb6f8dcd-2kn9r 1/1 Running 0 10s ip-192-168-88-26.ap-northeast-1.compute.internal
期待通りに、最小構成の初期NodeでPodが起動しました。ここではまだKarpenterは動作していません。
スケールアウト
#それでは、サンプルアプリをスケールアウトさせて、Karpenterの動きを見ていきます。
その前に、別のターミナルでNodeの状態を常時ウォッチしておきます。
kubectl get node -w
まずは、レプリカ数を5に上げてみます。
kubectl scale deploy app --replicas 5
Podは以下の状態となりました。
kubectl get pod --sort-by .status.startTime
NAME READY STATUS RESTARTS AGE
app-6ffb6f8dcd-zr8dn 0/1 Pending 0 6s
app-6ffb6f8dcd-lzgc5 0/1 Pending 0 6s
app-6ffb6f8dcd-cjfmg 0/1 Pending 0 6s
app-6ffb6f8dcd-cck7v 0/1 Pending 0 6s
app-6ffb6f8dcd-2kn9r 1/1 Running 0 46s
追加となった4つのPodはPending状態となっています。
Podのイベントを確認すると、以下のようになっています。
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 24s (x2 over 26s) default-scheduler 0/1 nodes are available: 1 Insufficient cpu.
このPodを起動するためのキャパシティ(CPU)が、初期Nodeにないということが分かります。
この状態になると、すぐにKarpenterが検知して、新しいNodeのプロビジョニングを開始します。
ウォッチしていたNodeの状態を確認します。
ip-192-168-122-149.ap-northeast-1.compute.internal Unknown <none> 0s
ip-192-168-122-149.ap-northeast-1.compute.internal Unknown <none> 54s
ip-192-168-122-149.ap-northeast-1.compute.internal NotReady <none> 55s v1.21.5-eks-9017834
ip-192-168-122-149.ap-northeast-1.compute.internal Ready <none> 84s v1.21.5-eks-9017834
新たなNode(ip-192-168-122-149...)が起動している様子が分かります。
PodがどのNodeに配置されたかを確認してみます。
kubectl get pod -o wide --sort-by .status.startTime
NAME READY STATUS RESTARTS AGE NODE
app-6ffb6f8dcd-2kn9r 1/1 Running 0 3m ip-192-168-88-26.ap-northeast-1.compute.internal
app-6ffb6f8dcd-cck7v 1/1 Running 0 2m20s ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-cjfmg 1/1 Running 0 2m20s ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-lzgc5 1/1 Running 0 2m20s ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-zr8dn 1/1 Running 0 2m20s ip-192-168-122-149.ap-northeast-1.compute.internal
NODE列から、Karpenterによって作成された新しいNode(ip-192-168-122-149...)でPodが実行中となっています。
ここでは表現できませんでしたが、Nodeが作成されると(Ready前でも)、PodはすぐにそのNodeにスケジューリングされました(CotainerCreatingステータスに変化)。
Karpenterによって作成されたNodeのスペックを確認します。
kubectl describe node <new-node-name>
以下抜粋です。
Name: ip-192-168-122-149.ap-northeast-1.compute.internal
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=c4.xlarge -> EC2のインスタンスタイプ
beta.kubernetes.io/os=linux
failure-domain.beta.kubernetes.io/region=ap-northeast-1
failure-domain.beta.kubernetes.io/zone=ap-northeast-1a
karpenter.sh/capacity-type=spot -> スポットインスタンス
karpenter.sh/provisioner-name=default
kubernetes.io/arch=amd64
kubernetes.io/hostname=ip-192-168-122-149.ap-northeast-1.compute.internal
kubernetes.io/os=linux
node.kubernetes.io/instance-type=c4.xlarge
topology.kubernetes.io/region=ap-northeast-1
topology.kubernetes.io/zone=ap-northeast-1a
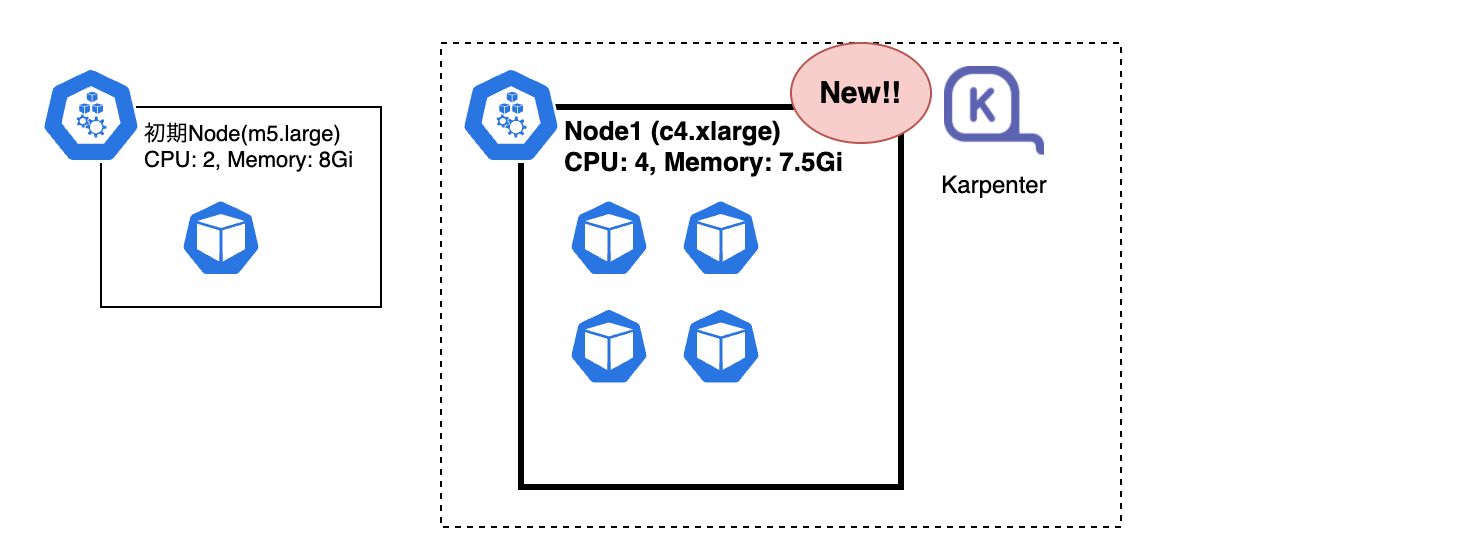
今回はPodのスペック(resources.requests)からc4.xlargeのEC2が最適と判定されたようです[1]。
また、スポットインスタンスとして作成されて、オンデマンドインスタンスと比べて費用的にもお得になりました。
以降、このNodeをNode1と表記します。
現在は以下のイメージの状態になっています。
さらにスケールアウト
#もっとPodを増やしてみます。今回は一気に20レプリカまで増やしてみます。
kubectl scale deploy app --replicas 20
Nodeの状態ウォッチしていたターミナルを見ると、先程同様に新たなNodeが作成されていることが分かります。
ip-192-168-162-96.ap-northeast-1.compute.internal Unknown <none> 0s
ip-192-168-162-96.ap-northeast-1.compute.internal NotReady <none> 64s
ip-192-168-162-96.ap-northeast-1.compute.internal NotReady <none> 68s
ip-192-168-162-96.ap-northeast-1.compute.internal NotReady <none> 68s v1.21.5-eks-9017834
ip-192-168-162-96.ap-northeast-1.compute.internal NotReady <none> 74s v1.21.5-eks-9017834
ip-192-168-162-96.ap-northeast-1.compute.internal Ready <none> 88s v1.21.5-eks-9017834
全てのレプリカを収容するための、3つ目のNode(ip-192-168-162-96...)が作成されました。
こちらもNodeのスペックを確認してみます。
Name: ip-192-168-162-96.ap-northeast-1.compute.internal
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=t3a.2xlarge -> EC2のインスタンスタイプ
beta.kubernetes.io/os=linux
failure-domain.beta.kubernetes.io/region=ap-northeast-1
failure-domain.beta.kubernetes.io/zone=ap-northeast-1d
karpenter.sh/capacity-type=spot
karpenter.sh/provisioner-name=default
kubernetes.io/arch=amd64
kubernetes.io/hostname=ip-192-168-162-96.ap-northeast-1.compute.internal
kubernetes.io/os=linux
node.kubernetes.io/instance-type=t3a.2xlarge
topology.kubernetes.io/region=ap-northeast-1
topology.kubernetes.io/zone=ap-northeast-1d
(省略)
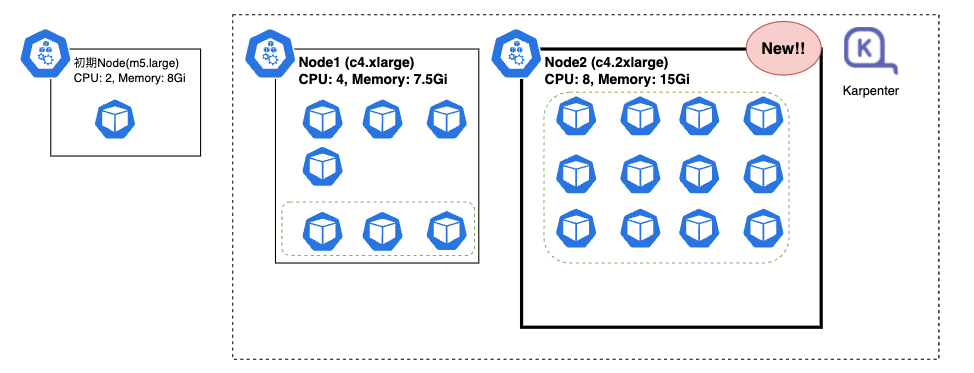
今度はt3a.2xlargeのインスタンスタイプと、先程よりも高スペックで作成されました。
より多くのレプリカを収容する最適サイズとして、Karpenterがこれを割り出しているようです。
以降このNodeをNode2と表記します。
Podの配置状況も確認してみます。
NAME READY STATUS RESTARTS AGE NODE
app-6ffb6f8dcd-2kn9r 1/1 Running 0 13m ip-192-168-88-26.ap-northeast-1.compute.internal
↓ Node1の既存Pod
app-6ffb6f8dcd-cck7v 1/1 Running 0 13m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-lzgc5 1/1 Running 0 13m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-cjfmg 1/1 Running 0 13m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-zr8dn 1/1 Running 0 13m ip-192-168-122-149.ap-northeast-1.compute.internal
↓ Node1の新規Pod
app-6ffb6f8dcd-lqjkq 1/1 Running 0 2m53s ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-wsc6q 1/1 Running 0 2m53s ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-9xxc7 1/1 Running 0 2m53s ip-192-168-122-149.ap-northeast-1.compute.internal
↓ Node2(Node1で収容できなかったPod)
app-6ffb6f8dcd-lv9p8 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-dzph7 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-6hm5h 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-cvtwb 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-7f64h 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-2mbrz 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-qpkn2 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-tgrnj 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-9bkfn 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-x2pps 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-z9rxr 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-jdjfg 1/1 Running 0 2m53s ip-192-168-162-96.ap-northeast-1.compute.internal
新たに追加となった15レプリカがNode1, Node2にそれぞれスケジューリングされていることが分かります。
これで以下の状態になりました。
スケールダウン
#今度は段階的にスケールダウンしてみます。
まずは10レプリカまで下げます。
# 20 => 10
kubectl scale deploy app --replicas 10
Podの状態を確認してみます。
NAME READY STATUS RESTARTS AGE NODE
app-6ffb6f8dcd-2kn9r 1/1 Running 0 15m ip-192-168-88-26.ap-northeast-1.compute.internal
↓ Node1
app-6ffb6f8dcd-cck7v 1/1 Running 0 14m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-lzgc5 1/1 Running 0 14m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-cjfmg 1/1 Running 0 14m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-zr8dn 1/1 Running 0 14m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-lqjkq 1/1 Running 0 4m43s ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-wsc6q 1/1 Running 0 4m43s ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-9xxc7 1/1 Running 0 4m43s ip-192-168-122-149.ap-northeast-1.compute.internal
↓ Node2
app-6ffb6f8dcd-lv9p8 1/1 Terminating 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-dzph7 1/1 Terminating 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-6hm5h 1/1 Running 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-cvtwb 1/1 Terminating 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-7f64h 1/1 Running 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-2mbrz 1/1 Terminating 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-qpkn2 1/1 Terminating 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-tgrnj 1/1 Terminating 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-9bkfn 1/1 Terminating 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-x2pps 1/1 Terminating 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-z9rxr 1/1 Terminating 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-jdjfg 1/1 Terminating 0 4m43s ip-192-168-162-96.ap-northeast-1.compute.internal
スケールダウンによって、Node2に配置されたPodがTerminatingとなりシャットダウンされました。
この段階では、まだ全てのNodeにPodが起動している状態ですので、Nodeのスケールダウンは発生しません。
ただ、先程KarpenterのProvisionerの設定でttlSecondsUntilExpiredを30分と指定しました。
このため、30分経過するとNodeの更新が実施されます。
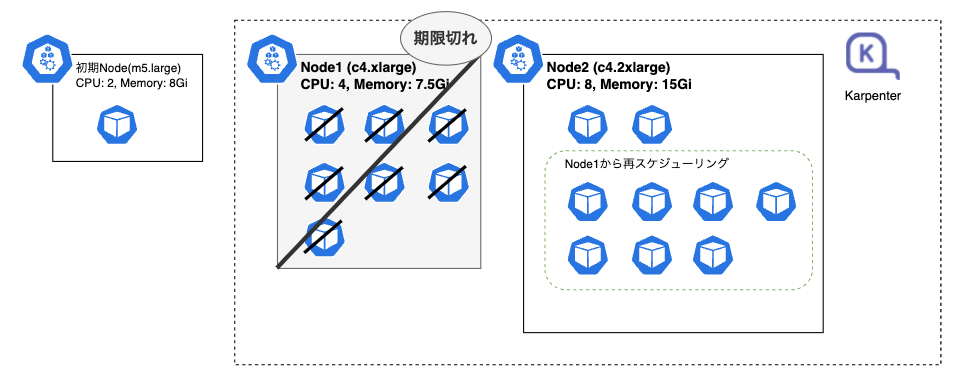
まず、Node1の有効期限が切れます。
NAME STATUS ROLES AGE VERSION
ip-192-168-122-149.ap-northeast-1.compute.internal Ready <none> 30m v1.21.5-eks-9017834
ip-192-168-122-149.ap-northeast-1.compute.internal Ready,SchedulingDisabled <none> 30m v1.21.5-eks-9017834
ip-192-168-122-149.ap-northeast-1.compute.internal Ready,SchedulingDisabled <none> 30m v1.21.5-eks-9017834
ip-192-168-122-149.ap-northeast-1.compute.internal Ready,SchedulingDisabled <none> 30m v1.21.5-eks-9017834
ステータスの遷移だけだとちょっと分かりにくいですが、KarpenterがNode1をシャットダウンしました。
ただ、Node2の方は、2Podのみがデプロイされている状態で余裕があります。新たなNode作成は不要です。
Node1にデプロイされていた7つのPodは、このNode2の方に再配置されました。
NAME READY STATUS RESTARTS AGE NODE
app-6ffb6f8dcd-2kn9r 1/1 Running 0 31m ip-192-168-88-26.ap-northeast-1.compute.internal
↓ Node1のPodはシャットダウン
app-6ffb6f8dcd-cck7v 0/1 Terminating 0 31m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-lzgc5 1/1 Terminating 0 31m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-cjfmg 0/1 Terminating 0 31m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-zr8dn 0/1 Terminating 0 31m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-9xxc7 0/1 Terminating 0 20m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-wsc6q 0/1 Terminating 0 20m ip-192-168-122-149.ap-northeast-1.compute.internal
app-6ffb6f8dcd-lqjkq 0/1 Terminating 0 20m ip-192-168-122-149.ap-northeast-1.compute.internal
↓ Node2
app-6ffb6f8dcd-6hm5h 1/1 Running 0 20m ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-7f64h 1/1 Running 0 20m ip-192-168-162-96.ap-northeast-1.compute.internal
↓ 以下再スケジューリング(Node1 -> Node2)
app-6ffb6f8dcd-lfwf6 1/1 Running 0 61s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-cpdx8 1/1 Running 0 61s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-7ggz7 1/1 Running 0 61s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-pbrxn 1/1 Running 0 61s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-vlh8q 1/1 Running 0 61s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-9xzbh 1/1 Running 0 61s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-99qv5 1/1 Running 0 61s ip-192-168-162-96.ap-northeast-1.compute.internal
Karpenterのスケールダウンによって、以下の状態となりました。
さらにスケールダウン
#今度はさらに5レプリカまでスケールダウンさせます。
# 10 => 5
kubectl scale deploy app --replicas 5
これだけではNodeに変動はありません。
NAME READY STATUS RESTARTS AGE NODE
app-6ffb6f8dcd-2kn9r 1/1 Running 0 33m ip-192-168-88-26.ap-northeast-1.compute.internal
↓ Node1の5Podが終了
app-6ffb6f8dcd-6hm5h 1/1 Running 0 22m ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-7f64h 1/1 Running 0 22m ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-7ggz7 1/1 Terminating 0 2m32s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-99qv5 1/1 Running 0 2m32s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-9xzbh 1/1 Terminating 0 2m32s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-cpdx8 1/1 Terminating 0 2m32s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-lfwf6 1/1 Terminating 0 2m32s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-pbrxn 1/1 Running 0 2m32s ip-192-168-162-96.ap-northeast-1.compute.internal
app-6ffb6f8dcd-vlh8q 1/1 Terminating 0 2m32s ip-192-168-162-96.ap-northeast-1.compute.internal
とはいえ、現在Node2は4Podしかデプロイされておらず、オーバースペックの状態です。
Nodeの状態は、以下のようになっています。
Name: ip-192-168-162-96.ap-northeast-1.compute.internal
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=t3a.2xlarge
(省略)
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 2125m (26%) 0 (0%)
memory 2Gi (6%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
attachable-volumes-aws-ebs 0 0
(省略)
CPUが26%しか使われておらず、リソース利用効率が悪い状態です。
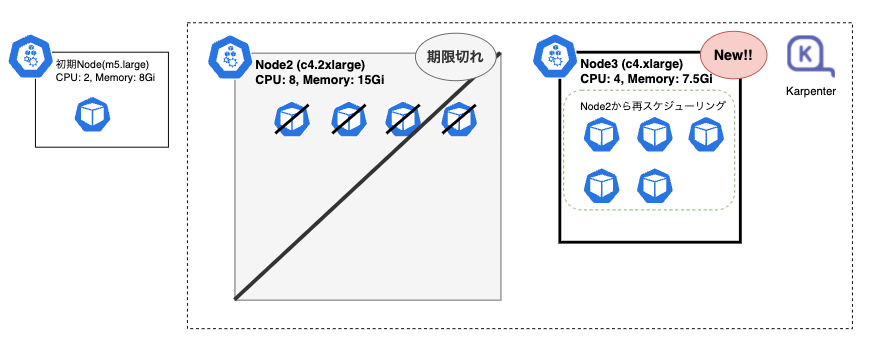
ここでも有効期限(ttlSecondsUntilExpired)が効くはずです。しばらく待つとNode2も有効期限を迎えます。
NAME STATUS ROLES AGE VERSION
ip-192-168-162-96.ap-northeast-1.compute.internal Ready <none> 30m v1.21.5-eks-9017834
ip-192-168-162-96.ap-northeast-1.compute.internal Ready,SchedulingDisabled <none> 30m v1.21.5-eks-9017834
ip-192-168-162-96.ap-northeast-1.compute.internal Ready,SchedulingDisabled <none> 30m v1.21.5-eks-9017834
ip-192-168-124-93.ap-northeast-1.compute.internal Unknown <none> 0s
ip-192-168-124-93.ap-northeast-1.compute.internal Unknown <none> 0s
ip-192-168-124-93.ap-northeast-1.compute.internal Unknown <none> 0s
ip-192-168-162-96.ap-northeast-1.compute.internal Ready,SchedulingDisabled <none> 30m v1.21.5-eks-9017834
ip-192-168-124-93.ap-northeast-1.compute.internal Unknown <none> 60s
ip-192-168-124-93.ap-northeast-1.compute.internal NotReady <none> 60s v1.21.5-eks-9017834
ip-192-168-124-93.ap-northeast-1.compute.internal NotReady <none> 60s v1.21.5-eks-9017834
ip-192-168-124-93.ap-northeast-1.compute.internal NotReady <none> 61s v1.21.5-eks-9017834
ip-192-168-124-93.ap-northeast-1.compute.internal Ready <none> 90s v1.21.5-eks-9017834
今回Karpenterは削除だけでなく、スケジュールできなくなったPodのために、新たなNode(ip-192-168-124-93...)を作成していることが分かります。
この新しいNodeのスペックとCPU利用率は以下になっていました。
Name: ip-192-168-124-93.ap-northeast-1.compute.internal
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=c4.xlarge
(省略)
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 2125m (54%) 0 (0%)
memory 2Gi (31%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
attachable-volumes-aws-ebs 0 0
今回はインスタンスタイプc4.xlargeと、先程よりワンランク下のNodeが作成されていました。
CPU使用率も54%と先程のオーバースペック状態が緩和され、身の丈にあったNodeのスペックになりました。
ゼロスケール
#最後にゼロスケールしてみます。
kubectl scale deploy app --replicas 0
全てのPodが削除され、Karpenterが追加したNodeはもう不要になっています。
ここでProvisionerのttlSecondsAfterEmpty指定が効くはずです。こちらは30秒に指定しましたので、Podが削除されるとすぐにNodeが削除されます。
ip-192-168-124-93.ap-northeast-1.compute.internal Ready <none> 7m50s v1.21.5-eks-9017834
ip-192-168-124-93.ap-northeast-1.compute.internal Ready,SchedulingDisabled <none> 7m50s v1.21.5-eks-9017834
最終的に、Nodeは以下のようになりました。
NAME STATUS ROLES AGE VERSION
ip-192-168-88-26.ap-northeast-1.compute.internal Ready <none> 175m v1.21.5-eks-9017834
全てのPodが起動していないので、Karpenterは不要になったNode(EC2)を全てシャットダウンして、初期状態に戻りました。
まとめ
#Karpenterによって、柔軟で無駄のないオートースケール環境が構築できそうです。
今回はkubectl scaleを使い、手動でPod数を増減させましたが、HPA(Horizontal Pod Autoscaler)と組み合わせることで、クラスタ利用状況に応じて自律的にオートースケールできるでしょう。
既にEKSでCluster Autoscalerを利用している場合は、こちらへの乗り換えを検討する価値がありそうです。
AWS以外のクラウドプロバイダーでもKarpenterが使えるようなってくると、既存のCluster AutoscalerもKarpenterベースとなっていく可能性もあるかもしれませんね。
余談ですが、KarpenterではFargateと同じく、CRIはDockerではなくcontainerdを利用するようになっていました。 ↩︎