使用 WebRTC 实现 OpenAI Realtime API 的语音对话应用
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
2024年10月推出的OpenAI Realtime API是一种革命性的API,可以在任意应用中实现与AI的实时语音对话。
此前,Realtime API仅支持WebSocket,而近日宣布也支持WebRTC。
此外,还进行了包括大幅降价、提高语音质量等更新,使得这个API更加易于使用。
That’s it. That’s the tweet. The Realtime API now supports WebRTC—you can add Realtime capabilities with just a handful of lines of code.
— OpenAI Developers (@OpenAIDevs) December 17, 2024
We’ve also cut prices by 60%, added GPT-4o mini (10x cheaper than previous prices), improved voice quality, and made inputs more reliable. https://t.co/ggVAc5523K pic.twitter.com/07ep5rh0Kl
通过这次更新,基于浏览器运行的客户端应用推荐使用延迟更低且更易实现的WebRTC。
在之前的文章中,我们实现了基于WebSocket的语音对话应用,这次我们将尝试使用新支持的WebRTC版本。
以下是使用WebRTC版本的Realtime API的构成图。
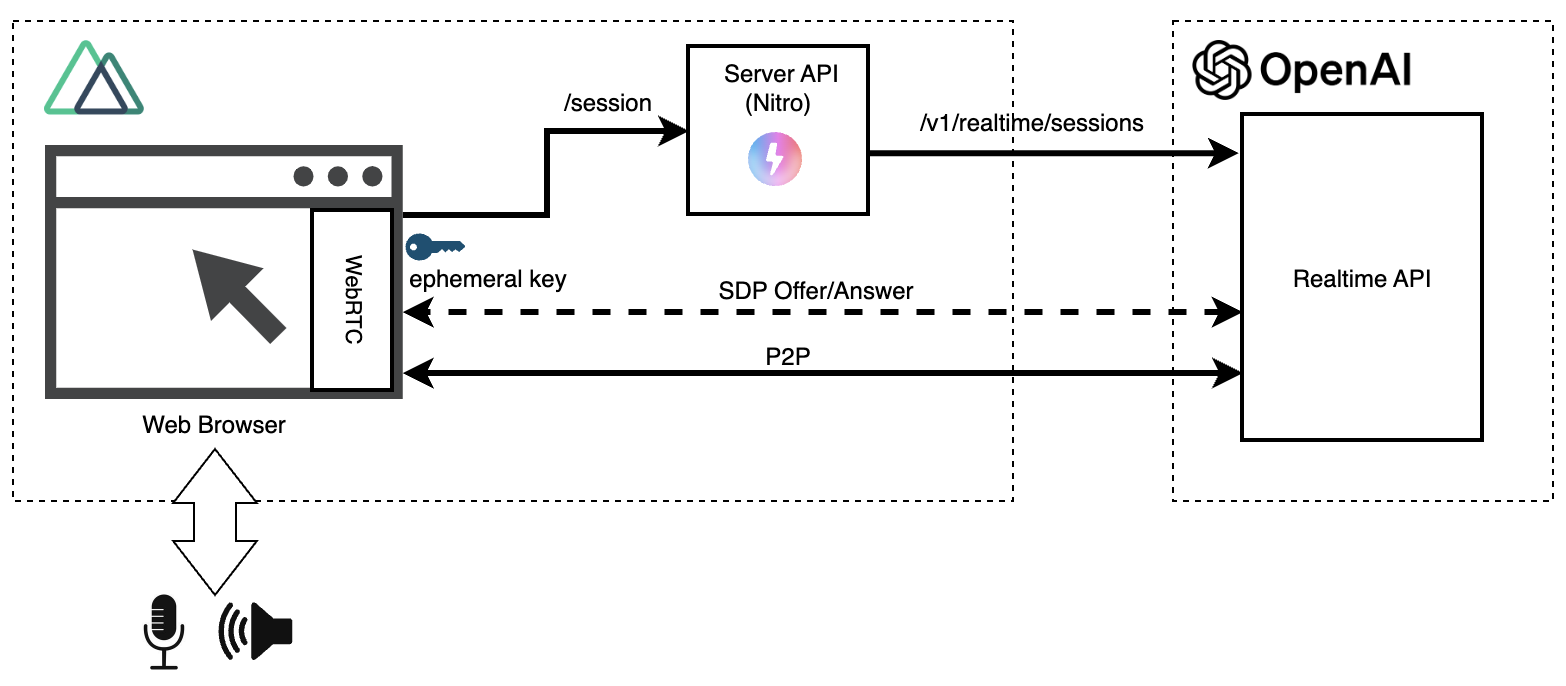
在之前的WebSocket版本中,为避免将OpenAI的API密钥暴露给浏览器,我们在浏览器和Realtime API之间设置了中继服务器。
而WebRTC版本中,除了首次获取临时认证密钥(Ephemeral Key)外,Realtime API与浏览器之间直接通信(P2P: Peer to Peer)。
源码已公开发布。在其中我们加入了WebRTC版本,扩展了之前WebSocket版本的实现。
接下来我们会集中讲解一些关键点(不会展示所有源码)。
服务器API(获取临时认证密钥)
#为了与Realtime API建立会话,需要提前获取一个临时认证密钥(Ephemeral Key)。这一步需要用到常规的OpenAI API密钥。
因此,我们在服务端实现了这个功能作为一个服务端API。
这里使用了Nuxt的服务端API功能来事先准备了如下API[1]。
export default defineEventHandler(async () => {
return await $fetch<{ client_secret: { value: string } }>('https://api.openai.com/v1/realtime/sessions', {
method: 'POST',
headers: {
'Authorization': `Bearer ${process.env.OPENAI_API_KEY}`,
'Content-Type': 'application/json'
},
body: {
model: 'gpt-4o-realtime-preview-2024-12-17',
voice: 'shimmer',
instructions: '你是一个活泼的助手,请用友好的语气说话,不用敬语。',
input_audio_transcription: { model: 'whisper-1' },
turn_detection: { type: 'server_vad' }
}
});
});
在这里的请求体中设置了Realtime API的各项参数,不过也可以像WebSocket一样在会话建立后通过触发session.update事件进行修改。
调用上述端点时,会返回如下响应。
{
"id": "sess_xxxxxxxxxxxxxxxxxxxxx",
"object": "realtime.session",
"model": "gpt-4o-realtime-preview-2024-12-17",
// (略)
"client_secret": {
"value": "ek_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"expires_at": 1734673378
},
"tools": []
}
- client_secret.value: 临时认证密钥(Ephemeral Key)
- client_secret.expires_at: 认证密钥的有效期(生成后1分钟)
以下将说明客户端侧与Realtime API相关的源码。
完整源码可通过以下路径查看。
获取认证密钥
#当用户发出连接请求时,会调用刚才创建的服务端API,以从Realtime API获取临时认证密钥(Ephemeral Key)。
// 获取临时认证密钥
const tokenResponse = await $fetch('/session');
const ephemeralKey = tokenResponse.client_secret.value;
通过取得的ephemeralKey,我们会与Realtime API建立会话。
由于密钥有效期较短(生成后1分钟),建议在即将开始会话时再获取密钥。
获取麦克风音频
#接下来,使用Media Streams API获取麦克风音频。
// 获取音频输入(需用户授权)
const mediaStream = await navigator.mediaDevices.getUserMedia({
audio: true
});
initAudioWaveFormCanvas(mediaStream); // 开始绘制音频波形
初次执行时,浏览器会请求用户授权使用麦克风。
在获得授权后,使用获取的音频流(mediaStream)启动音频波形绘制。
在这里,关于音频波形绘制的内容并非重点,因此省略了说明(使用了与WebSocket版本相同的实现)。
创建RTCPeerConnection
#接下来是创建负责WebRTC连接管理的RTCPeerConnection对象。
peerConn = new RTCPeerConnection();
此对象负责建立和管理与Realtime API的P2P连接。
需要将音频或数据的发送/接收轨道添加到RTCPeerConnection中,并设置好连接参数。
音频输出处理
#从Realtime API接收到的音频轨道被设置到audio标签中,并开始播放。
const audioEl = document.createElement('audio');
audioEl.autoplay = true;
// 接收到Realtime API的轨道
peerConn.ontrack = event => {
const remoteStream = event.streams[0];
connectStreamToAnalyser(remoteStream); // 显示音频输出的波形
audioEl.srcObject = remoteStream; // 将音频连接到audio标签
};
在WebSocket版本中,需要对输出音频进行排队或者格式转换。
而在WebRTC中,仅需直接将接收到的音轨设置到audio标签,即可利用本地音频设备播放AI生成的音频,使处理过程大幅简化。
输入音频(麦克风)处理
#将从麦克风取得的音频轨道添加到RTCPeerConnection中,并发送至服务器。
peerConn.addTrack(mediaStream.getTracks()[0]);
在WebSocket版本中,我们需要缓冲到固定大小后发送至Realtime API,而在WebRTC版本中,只需要一行代码完成😅。
创建数据通道及事件处理
#创建WebRTC的数据通道,用以接收来自Realtime API的事件。
channel = peerConn.createDataChannel('oai-events');
channel.addEventListener('message', (e) => {
const event = JSON.parse(e.data);
switch (event.type) {
case 'response.audio_transcript.done':
// 输出语音文本,可能会比用户语音的文本先触发,因此延迟显示
setTimeout(() => logMessage(`🤖: ${event.transcript}`), 100);
break;
case 'conversation.item.input_audio_transcription.completed':
if (event.transcript) logMessage(`😄: ${event.transcript}`);
break;
case 'error':
logEvent(event.error);
if (event.code === 'session_expired') disconnect();
break;
}
});
在这里接收并处理输入、输出音频文本和错误信息,并在UI上进行展示。
数据通道不仅用于接收事件,也用于发送客户端事件。
以下是通过session.update事件更新Realtime API设置的示例[2]。
channel.onopen = () => {
channel.send(JSON.stringify({
type: 'session.update',
session: {
input_audio_transcription: { model: 'whisper-1' },
},
}))
}
SDP交换与连接建立
#使用WebRTC的SDP(会话描述协议)完成交换以建立连接。
const offer = await peerConn.createOffer();
await peerConn.setLocalDescription(offer);
const sdpResponse = await $fetch(
`https://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-12-17`, {
method: 'POST',
body: offer.sdp,
headers: {
Authorization: `Bearer ${ephemeralKey}`,
'Content-Type': 'application/sdp'
}
});
await peerConn.setRemoteDescription({
type: 'answer',
sdp: sdpResponse
});
首先生成自身的连接信息(SDP offer),并将其设置为本地配置。
然后将该连接信息发送到Realtime API以生成Remote SDP answer,同时提供之前获取的临时认证密钥(Ephemeral key)。
最后将Realtime API返回的连接信息作为远端配置完成注册。
这样,双方的连接条件匹配,通信准备就绪。
在Chrome浏览器中调试WebRTC,可以通过访问chrome://webrtc-internals/来查看SDP offer/answer的文本信息。
运行验证
#以上是主要源码。以下是本地环境中的执行示例:
npm run dev
以下视频展示了运行WebRTC版本Web应用的样例(解除静音可听到AI声音,请注意周围环境)。
总结
#在实现WebSocket版本时,我们在音频处理上需要花费不少精力,而在WebRTC版本中,这些复杂的处理都不再需要,能够实现非常简洁的实现。
OpenAI也推荐在浏览器应用中采用这种WebRTC版本,未来我们也会将其集成到更多的场景中。