Trying Unrequited Love with the Zengin System Failure
Back to TopTo reach a broader audience, this article has been translated from Japanese.
You can find the original version here.
This article is the 5th day article of the Mamezou Developer Site Advent Calendar 2023.
It's been a while since my last post, but how is everyone doing? Before I knew it, the end of the year was approaching. As someone who likes to keep up with trends, I've made sure to cover both COVID and influenza this year. Fortunately, it was after the transition to category 5, so I was able to recover without having to rush to find a hospital. The reassurance of being able to take measures based on a doctor's diagnosis is incredible.
Speaking of trends, there was a report on the investigation into the major outage of the Zengin Net system that occurred in October. Although I am not involved in this matter, as someone who has worked around quality, it was a troubling incident that made me feel the weight of responsibility. Knowing the trouble as I do, hindsight is unavoidable, but I'd like to consider what kind of attention needs to be paid using the incident as a learning point.
The content discussed here is based on publicly available information but includes a lot of my interpretation. There may be inaccuracies due to misreading or context omission, and I take full responsibility for these.
Hypothetical Plan
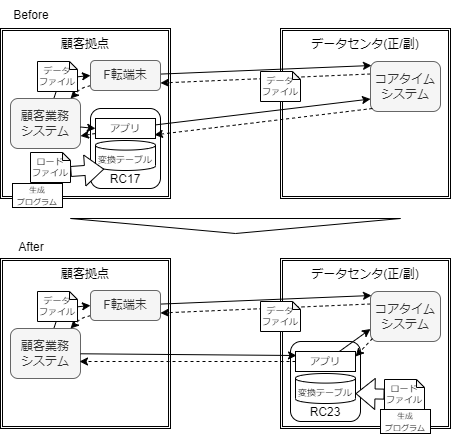
#Based on the information available, let's consider a hypothetical development plan as follows:
- Development involving the replacement of a relay computer (RC) that handles communication between customer sites and the data center
- Due to maintenance deadlines, changing computers (32bit->64bit) is unavoidable
- Areas that need changes due to machine/OS architecture changes should be identified in advance, and application behavior should maintain compatibility
- Considering future maintenance, the RC will be virtualized and consolidated at the data center side
- Due to maintenance deadlines, changing computers (32bit->64bit) is unavoidable
If I were planning tests for this virtual development, here's how I would approach it.
If I Were to Plan the Tests
#The biggest risk in this development is maintaining application behavior compatibility while changing the machine/OS architecture. As those involved in testing may know, conducting a "complete test" is impossible, so it's necessary to use reviews and other methods besides testing to make a reasonable judgment on whether compatibility is maintained.
One thing to note first is the increase in memory usage due to the switch to 64-bit. Other than that, it's necessary to check for changes such as OS API changes that could impair compatibility, and at a minimum, compatibility must be ensured by combining devices and programs. Also, if network configuration changes cause changes in communication content, it's necessary to check the impact of changes, making tests conducted in the latter stages of development (combining infrastructure and applications) quite critical.
Testing with combined infrastructure and applications means that preparing the test environment/data will likely be costly. However, since the equipment/OS is being replaced and the equipment layout is also changing, adopting an approach to shift testing left and verify early is expected to be challenging.
Regardless of whether it can be adopted, the following approaches should be considered:
- Prepare a test environment that replicates the production configuration (≒ virtual customer sites, etc.), and plan tests that follow production-like data/business procedures
- If possible, create test environments with both new and old configurations to verify compatibility
- Ensure that changes can be rolled back, such as making new data convertible to old data, so that if problems occur after operation starts, rollback is possible
- Release only one of the primary/secondary data centers first, and if problems occur, switch to the old configuration (using only the unreleased side) to operate
- Like a beta release, release to a limited number of customer sites where operations can continue with alternative methods if problems occur, and coordinate with customers to gradually deploy once it's confirmed that no problems occur
The approaches mentioned here, except for the initial "enhance testing before release," are means to evaluate the presence of problems after release and enable recovery if problems occur. In other words, these are shift-right testing approaches.
The Possibility of "Shift Right" for Complex Test Subjects
#As someone involved in testing, I had an emotional resistance to "shift right" in testing. However, since complete testing is impossible, I've come to think that working hard on shift-left might just be self-satisfaction if a problem occurs after release. In recent times, as systems have become larger and their impact wider, it's become necessary not only to make efforts in advance to prevent problems but also to plan how to minimize the impact when problems do occur.
For example, if the bank transfer issue had been handled so that the transfer processes were completed within the same day even if a failure occurred, the actual damage would have been minimal. In other words, the problem was not just the failure itself but that it couldn't be handled within the same day.
Recently, it seems that shift-right approaches are being adopted more by companies in the web sector. I thought that adopting shift-right in traditional business systems, due to the technologies used, would be difficult and unfamiliar. However, even if individual methods are difficult to adopt, "enabling rollback" or "contingency planning" are actually similar to concepts long considered in business systems, and I've revised my thinking accordingly.
In complex test subjects, it's important to clearly recognize the "range not covered by tests" and to plan thoroughly how to handle problems when they occur. Not limited to the Zengin Net outage, preparing for problems (assuming they can be minimized as much as possible) and being ready to handle them when they occur is becoming increasingly important.
Finally – Contradicting Heinrich
#Reading the report on the Zengin Net outage, what I felt was "no matter the measures taken, they can never be perfect." For instance, the report mentions "misunderstandings during design reviews led to overlooked risks" and "dual-system failures were unprecedented and difficult to handle," which seem to indicate that overconfidence in "major failures will not occur" was a factor.
There's a saying used in quality management called Heinrich's Law, which states that "behind one major accident, there are 29 minor accidents and 300 non-injury incidents." This is a trend derived from statistics on insurance accidents and, although there may be changes over time, I believe it generally still holds true.
However, reducing the "300 non-injury incidents" doesn't necessarily reduce the probability of "one major accident." On the contrary, the absence of small troubles might lead to a diminished awareness of failures, potentially neglecting preparations for major accidents. This led me to realize that while it's important to address small failures, it's also crucial to maintain the ability to respond to failures by experiencing a certain level of problems (controlled, of course). In that sense, there might be merit in "intentionally causing small near-misses to handle them."
"Being well-prepared for emergencies" might seem like an excess cost during normal times. Yet, just as having the capacity to receive a doctor's consultation provides reassurance, it's important to budget for some costs on the premise that emergencies can occur. Reflecting on both the Zengin Net outage and COVID/influenza, I hope for a year with fewer troubles in 2024, while not neglecting preparations.