全銀システム障害に片想いしてみる
Back to Topこの記事は豆蔵デベロッパーサイトアドベントカレンダー2023第5日目の記事です。
前回投稿からだいぶ時間が空いてしまいましたが、皆様お元気でしょうか。気付けば年の瀬に差し掛かってしまいました。流行りモノは押さえておく性分の筆者は、今年はシッカリとコロナもインフルエンザもカバーしました。幸いなことに5類移行後のタイミングでしたので病院探しに奔走することもなく無事に回復しています。医師の診断を受けて対策できることの安心感は半端ないですね。
さて、流行りモノと言えば10月に起きた全銀ネットの大規模障害[1]についての調査報告が出されていました[2]。筆者はこの件の関係者というわけではありませんが、品質まわりで仕事をしてきた身としては身が引き締まる思いのするトラブルでした。トラブルを知っている身として後知恵になることは避けられませんが、障害を他山の石としてどういったことに気を配っていく必要があるものか思いを馳せて[3]みようと思います。
ここで述べる内容は公開された情報をもとにしていますが筆者の解釈を多分に含みます。誤読や文脈疎漏により事実と異なる内容を記載しているかもしれませんが、当然のものとしてその責任は筆者に帰します。
仮想の計画
#さて、公開されている情報を参考にして、以下のような仮想の開発計画を想定してみます。
- 顧客拠点に存在する業務システムとデータセンタの通信による連携を担う中継コンピュータ(RC)の入替を伴う開発
- 機器の保守期限があるため、コンピュータの変更(32bit->64bit)は避けられない
- マシン/OSのアーキテクチャ変更に由来して変更が必要な箇所については事前に抽出し、アプリケーションの振る舞いは互換性を保つようにする
- 今後の保守を踏まえ、RCは仮想化してデータセンタ側に集約する
- 機器の保守期限があるため、コンピュータの変更(32bit->64bit)は避けられない
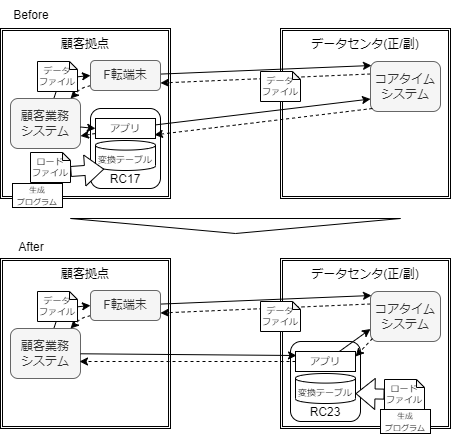
この仮想開発に対し、もし筆者がテストを計画する立場であったらどのようにアプローチしていたかを検討してみます。
テスト計画をたてるとしたら
#今回の開発においてリスクが大きいのは、機器/OSのアーキテクチ変更を伴いながらアプリケーションの振舞いは互換性を保たなければならないことです。テストに関わった方であればご存じだとは思いますが、互換性を担保するために「完全なテスト」の実施は不可能[4]ですのでレビューなどテスト以外の手段も併用して互換性を担保できているか妥当な判断ができるようにアプローチを考える必要があります。
まず留意するべきなのは64bit化に伴う利用メモリ量の拡大[5]が思い当たります。それ以外にもOSのAPI変更など、互換性を損なうような変更が行われていないかは確認が必要になり、最低でも機器とプログラムを結合した状態で互換性を担保していく必要があります。それ以外にもネットワーク構成変更によって通信内容に変化が起こるならば変更影響を確認していかないといけないため、結合テストなど開発後半に実施する(インフラとアプリケーションを組み合わせるような)テストがかなり重要になりそうです。
インフラとアプリケーションを組み合わせてのテストなので、テスト環境/データの準備はそれなりのコストになりそうです。とはいえ機器/OSを入れ替えて、機器配置も変更してのリリースですのでテストをシフトレフトして早期に確認するアプローチを採るのはかなり難しい[6]ことが想定されます。
採用できるかどうかは置いておき、以下のようなアプローチが採れないかは検討しておきたいことろです。
- 本番に近い構成の(≒仮想の顧客拠点などを再現した)テスト環境を準備し、本番に近いデータ/業務手順をとるようなテストを計画する
- 可能であれば新旧の構成でテスト環境を作成し、互換性を保っていることを確認する
- 新データ->旧データへの変換が可能なようにしておくなど、稼働開始後に問題が発生した際には切り戻しができるように変更内容をコントロールする
- データセンタの正/副いずれかのみ先行してリリースし、問題の発生時には旧構成に切り替えて(未リリースの側のみを利用して)動作できるような段階的リリースを採る
- ベータリリースのような形で(問題発生時に代替手段で運用できる程度の)限定した顧客拠点のみに対しリリースし、問題が発生しないことを確認できた段階で順次展開するように顧客と調整する
ここで挙げたアプローチは、最初の「リリース前に問題がないようテストを強化する」アプローチを除いて、リリース後に問題の発生有無を評価して問題発生時の復旧を可能にするための手段です。つまりはテストのシフトライトによったアプローチになります。
複雑化するテスト対象に対する「シフトライト」の可能性
#テストに関わってきた身として、筆者はテストの「シフトライト」には感情的な抵抗感[7]を持っていました。とは言え完全なテストが不可能な以上、シフトレフトで頑張ることは、万一問題が発生した際には「リリース前にこれだけ頑張った」という自己満足に過ぎないのではないかと思うようになりました。今回の障害のようにシステムが巨大化して影響範囲も広大になってきている昨今では、問題が起きないように事前に努力することは前提としつつも、問題発生時に影響を軽微な範囲にとどめるようにすることも要求されてきているのだと思います。
例えば今回の銀行振込の障害事象であれば、障害が発生したとしても振込処理が当日中に終わるように対処できていれば実害は少なく済んだ[8]ものではないかと思われます。つまり、障害自体も問題であるけれども、より深刻だったのは回避策などを含めて当日中に対処ができなかったこととも言えるわけです。
最近、Web系の企業などを中心にしてシフトライトのアプローチが採られることが増えてきている[9]ように感じます。それに対し、いわゆる業務系システムなどでテストをシフトライトすることは、採用技術に由来して難易度が高いものもあり、馴染みは悪いのではないかと考えていました。しかし、個別手法の採用は困難であったとしても、「切り戻しを可能にする」であったり「コンティンジェンシープラン」であったり、実は業務系システムでも古くから考えられてきていた内容と近しいものであるように筆者は考えを改めました。
こと複雑なテスト対象に対しては、「テストでカバーしきれない範囲」をしっかりと認識し、問題の発生時にどう対処するのかをしっかりと計画することが重要です。今回の全銀ネット障害に限らず、問題の発生は(可能な限り抑え込んでおくことを前提としても)避けられないものとして発生時に対処できるように備えておくことが大切になっていくのではないかと思います。
最後に ~ハインリッヒに逆張りしてみる~
#全銀ネット障害の報告を読んでいて筆者が感じたことは「どんなに対策を講じたとしても完全な対策にはならない」ということでした。例えば報告書に述べられているように「設計レビュー時に誤解があったためリスクに気付かなかった」といった内容や「両系障害は実績がなく対処困難であった」点などは「大規模障害は起きない」という過信が一因として存在しているもののように感じられます。
さて、品質管理の現場でも使われる格言に「1件の重大事故の裏には29件の軽微な事故と300件の怪我に至らない事故がある」というハインリッヒの法則があります。これは損害保険事故の統計から導き出された傾向ですので、(時代背景による変化はあるにしても)トラブルの発生に際しては概ね今でも成立しているものではないかと思います。
その帰結として、「小さなヒヤリ・ハットを防止する」という施策が採られることも多いかと思います。しかし、ハインリッヒ氏が報告したのはあくまで統計上の事実であって「怪我に至らない300件の事故」を減らせば「1件の重大事故」の発生確率を減らすことができるかどうかは分かりません。むしろ小さなトラブルが起こらなくなることで障害への意識が薄れ、大規模障害に対する備えが疎かになるという可能性もあるというのが筆者の思い至った内容です。
小さな障害を潰すことはもちろん大切であるのですが、同時に問題が一定程度発生する状況に身を置くことで障害への対応能力を保つことも同時に大切なのだと気付かされました(言うまでもなく障害はコントロールされているものが望ましいですが)。その意味では「小さなヒヤリ・ハットを意図的に起こして対応する」こともアプローチとして考えていく意味があるのかもしれません。
「非常時への備えをしっかりしておくこと」は平常時においては余剰なコストに見えることもあるかと思います。それでも、医師の診察に受入余力があることが安心材料になっているように、非常時は起こりうることを前提としてある程度のコストを積んでおくことは大切です。全銀ネット障害と、コロナ/インフルエンザを踏まえてその思いを新たにする一年でした。2024年はトラブルの少ない年になることを祈りつつ、備えは怠らないようにしたいですね。
話題性の大きな事象ですのでご存じかとは思いますが、10/7~9にシステムの更改を実施した後、10/10の業務開始時から影響を受けた10行で銀行間振込などの処理ができなくなり、暫定的な復旧にも時間を要したために10/10付の振込処理が完了しないという事象です。事象や経緯は全銀ネットがHPを通じて公開している資料に分かりやすくまとめられています。 ↩︎
金融庁への報告が11/30に行われ、12/1に全銀ネットHPなどを通じて公開されています。 ↩︎
とはいえ、所詮公開された情報程度しか検討材料のない身ですので、所詮は片想い/推しくらいの深度の浅い思考実験にしかなりません。「自分だったら障害を食い止められた」なんて意図は毛ほどもありませんので、もし関係者の方がいらっしゃったら「そんなことは当然うちらも考えてたんだよ~」と笑い飛ばしていただきたく。 ↩︎
想定される全てのパターンを組み合わせて確認するような「全数テスト」は、パターンが膨大になりすぎるため実現が不可能ということですね。「ソフトウェアテストの7原則」として古くから提唱されている話題ですし、筆者の認識する限り現時点でもこれを打破するようなブレークスルーは見られていません。 ↩︎
理論上はメモリ空間の扱いが2^32bit≒4GByteから2^64bit≒16EByteと拡大しますが、現実的にメモリサイズが莫大すぎるため物理メモリの制約を踏まえてOSなどで制限を定めているかと思います。扱われるメモリサイズが大きくなることによってかけるべき負荷量も大きくなりますし、メモリの確保を独自に行うような開発言語の場合は確保する領域の変化の影響も考慮が必要そうです。 ↩︎
例えば処理単位で互換性を損なわないことを確認したいのであればその範囲でテストして出力結果に差分を生じないか確認できます。しかし、このケースでは確認したいことが「変更後の環境において」互換性を保つことなので、処理単位でやるにしても各処理を新旧の環境で実行して差分を検証するような形が想定されるため開発中に処理を単独で動かしての確認は難しそうです。 ↩︎
乱暴な表現をしてしまうと「問題があったらリリースしてから見つけて対処する」というスタンスは「リリース前に問題を見つけるために知恵を振り絞る」ことを放棄しているように見えてしまいます。 ↩︎
筆者の拙い知識の中ではありますが、振込に関しては日単位で取引が処理されるものがほとんどだと思います。例えば今日の10時に申し込んだ振込が23時に相手方に着金したとして、困るのはごく一部の取引に限定されます。しかし、これが翌日着金になってしまうと(相手方での翌日の処理に影響を与える可能性があり)影響は拡大していく一方になります。 ↩︎
Netflix社が導入を公表している(本番環境で議事障害を発生させて復旧する)カオスエンジニアリングや、カナリアリリース、A/Bテストのようなリリース先を限定して切り替えを可能にするようなアプローチはリリース後に評価するアプローチにあたります。本番稼働しているシステムを評価するために可観測性を持たせるためのOpenTelemetryなどの技術もシフトライトの一環だと考えています。 ↩︎