Podスケジューリング - NodeAffinity / TaintToleration
Back to TopKubernetesで作成したPodは、Node[1]が割り当てられ、コンテナランタイムを通して実行されます。
Nodeは、多数のVMでクラスタ構成され、データセンター障害に備えて物理的に分散して配置されることが一般的です。
また、コスト最適化やワークロード要件を満たすために、コア数やメモリ容量だけでなく、OS種類やCPU/GPU、SSD/HDD等様々なスペックを持っていることもあるでしょう。
PodはどのようにしてNodeに割り当てられるでしょうか?
これを担うKubernetesのスケジューラは、主にFilteringとScoringのステージで構成されています。これらは以下の流れで動作します。
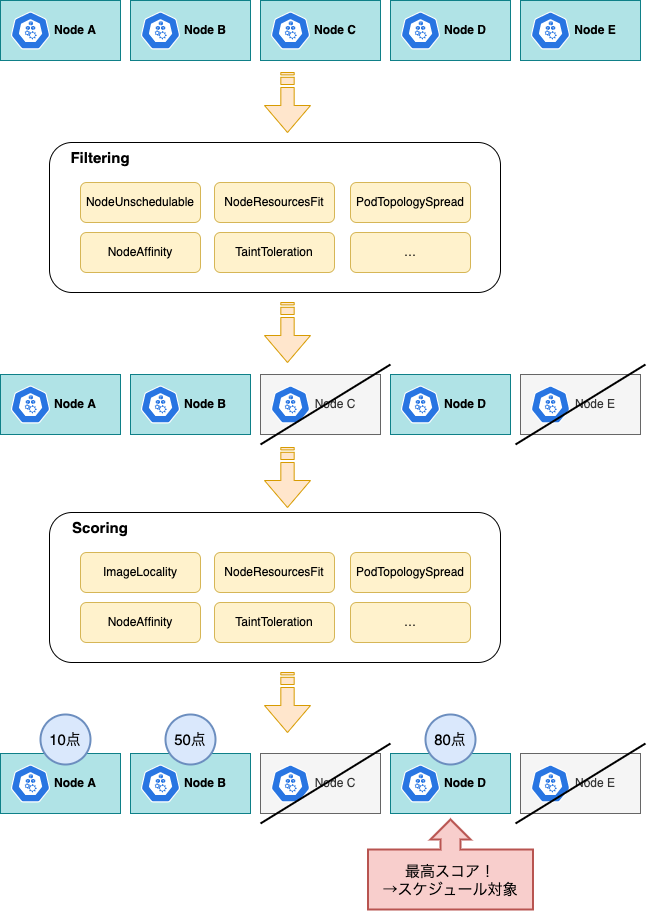
まず、Filteringで条件に満たないNodeを除外し、その後にScoringで残ったNodeのスコアを計算し、優先順位付けを行います。
ここで最高スコアとなったNodeが、スケジュール対象として登録(Bind)されます[2]。
Filtering/Scoringはプラグインとして実装されており、以下のようなものがあります。
NodeUnschedulable(Filtering)
スケジュール不可のNodeを候補から除外します。
NodeResourcesFit(Scoring / Filtering)
Podのリソース要求スペックresource.requestsを充足しないNodeを除外します。
Scoringでは最もPodのリソース割当が少ないNodeに高いスコアをつけます(デフォルト)。
PodTopologySpread(Scoring / Filtering)
各Topology(Nodeのラベル)でPodが分散してスケジュールされるよう除外または重み付けをします。
デフォルトでは各Node、AZ(Availability Zone)に偏りがないようにPodを分散させますが[3]、Podの指定(topologySpreadConstraints)で変更可能です。
詳細は公式ドキュメントを参照しくてださい。
NodeAffinity(Scoring / Filtering)
PodのnodeSelector/affinity.nodeAffinityの設定にもとづいて、Nodeの除外または重み付けをします。
TaintToleration(Scoring / Filtering)
Nodeに指定されたtaintsをPodが許容しない場合(tolerations)に、対象Nodeを除外または低い重み付けとします。
ImageLocality(Scoring)
Podのコンテナイメージをキャッシュ済みのNodeにより高いスコアをつけます。
他にも多数のプラグインがあります。詳細は公式リファレンスを参照してください。
今回はこの仕組みを利用して、Podのスケジューリングを調整してみましょう。
ここでは、NodeAffinityとTaintTolerationプラグインの動きを確認します。
Filteringでスケジュール対象のNodeがなくなった場合、PodはPending状態になります。
このとき、そのPodより優先順位(Priority)の低い実行中のPodを退場(Evict)させることができます。
詳細は公式ドキュメントを参照しくてださい。
ここでは、Kubernetesのデフォルトのスケジューラ(default-scheduler)のみを扱いますが、カスタムスケジューラの作成も可能です。
上級編ではありますが、興味のある方は公式ドキュメントを参照してください。
事前準備
#eksctlでEKSクラスタ環境を準備しておきましょう[4]。
ただし、スケジューラの検証のために今回はNode構成を変えます。
事前に以下のeksctlの設定ファイルを作成します(ここではcluster.yamlとします)。
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: mz-k8s
region: ap-northeast-1
version: "1.21"
managedNodeGroups:
- name: ap-northeast-1a-general-ng
availabilityZones: [ap-northeast-1a]
instanceName: ap-northeast-1a-general-node
instanceType: m5.large # 汎用インスタンス
desiredCapacity: 2
- name: ap-northeast-1c-general-ng
availabilityZones: [ap-northeast-1c]
instanceName: ap-northeast-1c-general-node
instanceType: m5.large # 汎用インスタンス
desiredCapacity: 2
- name: ap-northeast-1a-cpu-ng
availabilityZones: [ap-northeast-1a]
instanceName: ap-northeast-1a-cpu-node
instanceType: c5.xlarge # コンピューティング最適化
desiredCapacity: 1
iam:
withOIDC: true
以下のようにAZやインスタンスタイプを変えて、複数のNodeGroupを指定しています。
| NodeGroup | AZ | Node数 | インスタンスタイプ | 用途 |
|---|---|---|---|---|
| ap-northeast-1a-general-ng | ap-northeast-1a | 2 | m5.large | 汎用 |
| ap-northeast-1c-general-ng | ap-northeast-1c | 2 | m5.large | 汎用 |
| ap-northeast-1a-cpu-ng | ap-northeast-1a | 1 | c5.xlarge | 計算速度重視 |
こちらでEKSクラスタ環境を作成します。
eksctl create cluster -f cluster.yaml
構築が完了したらNodeの状況を確認しましょう。
# AZ/InstanceTypeのラベルを追加表示
kubectl get node -L topology.kubernetes.io\/zone,node.kubernetes.io\/instance-type
以下必要部分のみ抜粋します。
NAME STATUS ZONE INSTANCE-TYPE
ip-192-168-34-122.ap-northeast-1.compute.internal Ready ap-northeast-1a m5.large -> ap-northeast-1a-general-ng
ip-192-168-41-178.ap-northeast-1.compute.internal Ready ap-northeast-1a m5.large -> ap-northeast-1a-general-ng
ip-192-168-60-243.ap-northeast-1.compute.internal Ready ap-northeast-1a c5.xlarge -> ap-northeast-1a-cpu-ng
ip-192-168-72-28.ap-northeast-1.compute.internal Ready ap-northeast-1c m5.large -> ap-northeast-1c-general-ng
ip-192-168-77-172.ap-northeast-1.compute.internal Ready ap-northeast-1c m5.large -> ap-northeast-1c-general-ng
Nodeが指定したAZ、インスタンスタイプで配置されていることが確認できます。
今回はスケジューラの検証のため、minikubeやDocker Desktopでは実施できません。
ローカル環境で試す場合はkindの利用をお勧めします。このようなマルチNodでのクラスタ構成を簡単に組むことができます。
マニフェストファイルの準備
#検証用のPodは以下のマニフェストを使用します(app.yamlとします)。
kind: Deployment
apiVersion: apps/v1
metadata:
name: ap-northeast-1a-app
labels:
app: ap-northeast-1a-app
spec:
replicas: 5
selector:
matchLabels:
app: ap-northeast-1a-app
template:
metadata:
name: ap-northeast-1a-app
labels:
app: ap-northeast-1a-app
spec:
containers:
- name: ap-northeast-1a-app
image: alpine:latest
command: [sh, -c, "sleep infinity"]
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: ap-northeast-1c-app
labels:
app: ap-northeast-1c-app
spec:
replicas: 5
selector:
matchLabels:
app: ap-northeast-1c-app
template:
metadata:
name: ap-northeast-1c-app
labels:
app: ap-northeast-1c-app
spec:
containers:
- name: ap-northeast-1c-app
image: alpine:latest
command: [sh, -c, "sleep infinity"]
2つのアプリを5レプリカずつ起動します。
各アプリは特定のAZ内のリソースに依存していると仮定します。
Podの配置が分かりやすくなるように、Podの名前を<az-name>-appと依存するAZの名称を含めています。
単純にこのマニフェストをそのまま適用する(kubectl apply)と、Podの配置状況は以下のようになります。
kubectl get pod -o custom-columns=NAME:metadata.name,NODE:spec.nodeName
必要部分のみ抜粋・編集しています(以降同様)
NAME NODE
ap-northeast-1a-app-577fc5654-5z2mf ip-192-168-34-122.ap-northeast-1.compute.internal -> ap-northeast-1a: OK
ap-northeast-1a-app-577fc5654-9xbmt ip-192-168-41-178.ap-northeast-1.compute.internal -> ap-northeast-1a: OK
ap-northeast-1a-app-577fc5654-kbnb5 ip-192-168-72-28.ap-northeast-1.compute.internal -> ap-northeast-1c: NG
ap-northeast-1a-app-577fc5654-r2cbz ip-192-168-60-243.ap-northeast-1.compute.internal -> ap-northeast-1a: OK
ap-northeast-1a-app-577fc5654-v52sh ip-192-168-77-172.ap-northeast-1.compute.internal -> ap-northeast-1c: NG
ap-northeast-1c-app-d95f68684-8mbhr ip-192-168-34-122.ap-northeast-1.compute.internal -> ap-northeast-1a: OK
ap-northeast-1c-app-d95f68684-bnczb ip-192-168-72-28.ap-northeast-1.compute.internal -> ap-northeast-1c: OK
ap-northeast-1c-app-d95f68684-g7lmj ip-192-168-41-178.ap-northeast-1.compute.internal -> ap-northeast-1a: NG
ap-northeast-1c-app-d95f68684-sx7ft ip-192-168-60-243.ap-northeast-1.compute.internal -> ap-northeast-1a: NG
ap-northeast-1c-app-d95f68684-tr4gb ip-192-168-77-172.ap-northeast-1.compute.internal -> ap-northeast-1c: OK
現在はスケジューラの調整はしていませんので、一部のPodは期待するAZとは異なるNodeに配置されてしまっています。
実運用でこのような状態になると、Podが起動できずにエラーとなることもあるでしょう。
Node Affinity
#それでは、スケジューラのNodeAffinityプラグインの動きを確認してみましょう。
このプラグインは以下2つの指定方法があります。
- NodeSelector
- NodeAffinity
NodeSelector
#NodeSelectorは、指定したラベルにを持つNodeのみにPodがスケジュールされるように調整します(Filtering)。
Podのマニフェストを以下のように変更します。
kind: Deployment
apiVersion: apps/v1
metadata:
name: ap-northeast-1a-app
# (省略)
spec:
# (省略)
template:
# (省略)
spec:
# スケジュールされるAZをap-northeast-1aに限定
nodeSelector:
topology.kubernetes.io/zone: ap-northeast-1a
# (省略)
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: ap-northeast-1c-app
# (省略)
spec:
# (省略)
template:
# (省略)
spec:
# スケジュールされるAZをap-northeast-1cに限定
nodeSelector:
topology.kubernetes.io/zone: ap-northeast-1c
# (省略)
nodeSelectorフィールドを追加し、そこにNodeが持つラベル(topology.kubernetes.io/zone)を指定します。
このラベルはWell-Known Labelsと言われ、Kubernetesで一般的に使用するラベルで、EKS等のクラウドプロバイダ側で設定されることも多いです。
Well-Known Labelsの詳細はこちらを参照してください。
もちろん、Well-Known Labelsではなく、Nodeに独自のラベルをつけて、それにもとづいたNodeSelectorの設定もできます。
前回実施したものを一旦削除し、これを反映しましょう。
kubectl delete deploy --all
kubectl apply -f app.yaml
再度Podのスケジュール状況を確認します。
kubectl get pod -o custom-columns=NAME:metadata.name,NODE:spec.nodeName
NAME NODE
ap-northeast-1a-app-644f5bb54-9pjkk ip-192-168-41-178.ap-northeast-1.compute.internal -> ap-northeast-1a
ap-northeast-1a-app-644f5bb54-kmchx ip-192-168-34-122.ap-northeast-1.compute.internal -> ap-northeast-1a
ap-northeast-1a-app-644f5bb54-lc2jz ip-192-168-60-243.ap-northeast-1.compute.internal -> ap-northeast-1a
ap-northeast-1a-app-644f5bb54-rmkkd ip-192-168-60-243.ap-northeast-1.compute.internal -> ap-northeast-1a
ap-northeast-1a-app-644f5bb54-rzndf ip-192-168-60-243.ap-northeast-1.compute.internal -> ap-northeast-1a
ap-northeast-1c-app-655d89c874-l44rx ip-192-168-72-28.ap-northeast-1.compute.internal -> ap-northeast-1c
ap-northeast-1c-app-655d89c874-ldbgr ip-192-168-77-172.ap-northeast-1.compute.internal -> ap-northeast-1c
ap-northeast-1c-app-655d89c874-pdb8l ip-192-168-72-28.ap-northeast-1.compute.internal -> ap-northeast-1c
ap-northeast-1c-app-655d89c874-q5kfj ip-192-168-72-28.ap-northeast-1.compute.internal -> ap-northeast-1c
ap-northeast-1c-app-655d89c874-s2ttf ip-192-168-77-172.ap-northeast-1.compute.internal -> ap-northeast-1c
今回は、期待通りにPodが対応するAZのNodeにスケジュールされています。
NodeAffinity
#NodeSelectorは指定したラベルに合致したNodeのみが対象となりますが、NodeAffinityはもっと柔軟な指定が可能です。
上記NodeSelectorは、以下に書き換えられます。
kind: Deployment
apiVersion: apps/v1
metadata:
name: ap-northeast-1a-app
# (省略)
spec:
# (省略)
template:
# (省略)
spec:
# nodeSelector:
# topology.kubernetes.io/zone: ap-northeast-1a
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- ap-northeast-1a
# (省略)
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: ap-northeast-1c-app
# (省略)
spec:
# (省略)
template:
# (省略)
spec:
# nodeSelector:
# topology.kubernetes.io/zone: ap-northeast-1c
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- ap-northeast-1c
# (省略)
NodeSelectorの記述方法と比較して複雑になっていますが、より柔軟な指定が可能になっていることが推測できます。
まずは、requiredDuringSchedulingIgnoredDuringExecutionです。長いフィールド名ですが、requiredDuringSchedulingとIgnoredDuringExecutionの2つに分割すると意味が分かると思います。つまり、スケジューリング時に必須で、既に実行中のPodは無視するということになります。
これ以外に、preferredDuringSchedulingIgnoredDuringExecutionもあります。これは該当Nodeにスケジューリングされるのが望ましいが、必須ではないという意味になります。
つまり、スケジューラの実行ステージでいうと、requiredDuringSchedulingはFilteringで、preferredDuringSchedulingはScoringになります。
なお、現時点ではIgnoredDuringExecutionについては1択で、Nodeのラベルが変わっても、実行中Podの再スケジューリングは発生しません。
operatorには、ラベルの合致条件を指定します。上記で指定しているIn以外にもNotIn/Exists/DoesNotExists/Gt/Ltが指定できます。
ここではPodap-northeast-1a-appを、AZap-northeast-1aで、かつ汎用インスタンス(M5シリーズ)にのみ配置されるように調整してみましょう。
マニフェストを以下のように書き換えます(ap-northeast-1a-appのみ)。
kind: Deployment
apiVersion: apps/v1
metadata:
name: ap-northeast-1c-app
# (省略)
spec:
# (省略)
template:
# (省略)
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
# 複数条件を指定(AND条件)
- key: topology.kubernetes.io/zone
operator: In
values:
- ap-northeast-1a
- key: node.kubernetes.io/instance-type
operator: In
values:
- m5.large
- m5.xlarge
- m5.2xlarge
containers:
- name: ap-northeast-1a-app
image: alpine:latest
command: [sh, -c, "sleep infinity"]
resources:
requests:
# 検証のため1Node2台配置できるサイズで割当
cpu: 800m
# (省略)
requiredDuringScheduling...に、AZ配置に加えてインスタンスタイプの条件(node.kubernetes.io/instance-type)を追加しました。
また、検証のためPodの要求スペック(resources.requests)を800m(ミリコア)としています。これは今回構築した汎用インスタンス1Node(m5.large)に対して2つのPodがデプロイ可能なスペックです。
これを適用します。
kubectl delete deploy --all
kubectl apply -f app.yaml
Podのステータス(kubectl get pod)はこのようになります。
NAME READY STATUS RESTARTS AGE
ap-northeast-1a-app-6cff5bff5d-6m5wd 1/1 Running 0 8s
ap-northeast-1a-app-6cff5bff5d-6rsmw 1/1 Running 0 8s
ap-northeast-1a-app-6cff5bff5d-88gbg 1/1 Running 0 8s
ap-northeast-1a-app-6cff5bff5d-8rnsc 0/1 Pending 0 8s -> 実行可能なNodeがないためスケジュール不可
ap-northeast-1a-app-6cff5bff5d-hsb4n 1/1 Running 0 8s
ap-northeast-1c-app-7c6858695b-7hqbf 1/1 Running 0 8s
ap-northeast-1c-app-7c6858695b-g26dk 1/1 Running 0 8s
ap-northeast-1c-app-7c6858695b-l27kk 1/1 Running 0 8s
ap-northeast-1c-app-7c6858695b-lwq6z 1/1 Running 0 8s
ap-northeast-1c-app-7c6858695b-v5rlw 1/1 Running 0 8s
1つのPodでスケジュール可能な空きNodeがなく、Pending状態となってしまいました。
NodeAffinityの機能を使って、インスタンスタイプの条件をもう少し緩めてみましょう。
マニフェストファイルを以下のように書き換えます。
kind: Deployment
apiVersion: apps/v1
metadata:
name: ap-northeast-1a-app
# (省略)
spec:
replicas: 5
# (省略)
template:
# (省略)
spec:
affinity:
nodeAffinity:
# 必須条件(Filtering)
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- ap-northeast-1a
# 優先順位付け(Scoring)
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: node.kubernetes.io/instance-type
operator: In
values:
- m5.large
- m5.xlarge
- m5.2xlarge
weight: 100
# 以下変更なし
インスタンスタイプの条件をpreferredDuringScheduling...に変更しました。これにより、空きNodeがない場合は、別のインスタンスタイプで実行することを許容しています。
こちらを適用してみましょう。
kubectl delete deploy --all
kubectl apply -f app.yaml
Podのステータス(kubectl get pod)を再確認します。
NAME READY STATUS RESTARTS AGE
ap-northeast-1a-app-77bc9684f6-89klw 1/1 Running 0 65s
ap-northeast-1a-app-77bc9684f6-8bfc5 1/1 Running 0 65s
ap-northeast-1a-app-77bc9684f6-jjxvw 1/1 Running 0 65s
ap-northeast-1a-app-77bc9684f6-jx8qz 1/1 Running 0 65s
ap-northeast-1a-app-77bc9684f6-q82bx 1/1 Running 0 65s
ap-northeast-1c-app-7c6858695b-4bkjm 1/1 Running 0 65s
ap-northeast-1c-app-7c6858695b-5h7mn 1/1 Running 0 65s
ap-northeast-1c-app-7c6858695b-7kjkd 1/1 Running 0 65s
ap-northeast-1c-app-7c6858695b-dsdpb 1/1 Running 0 65s
ap-northeast-1c-app-7c6858695b-f8f6h 1/1 Running 0 65s
今回は全てのレプリカが正常に起動しました。
実際にどのNodeにスケジュールされたかを確認しましょう。
kubectl get pod -o custom-columns=NAME:metadata.name,NODE:spec.nodeName
NAME NODE
ap-northeast-1a-app-77bc9684f6-89klw ip-192-168-60-243.ap-northeast-1.compute.internal -> c5.xlarge
ap-northeast-1a-app-77bc9684f6-8bfc5 ip-192-168-34-122.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1a-app-77bc9684f6-jjxvw ip-192-168-41-178.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1a-app-77bc9684f6-jx8qz ip-192-168-34-122.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1a-app-77bc9684f6-q82bx ip-192-168-41-178.ap-northeast-1.compute.internal -> m5.large
(ap-northeast-1c-appは省略)
1つのPodがc5.xlargeのインスタンスタイプで実行されています。
このように、preferredDuringScheduling...を指定することで、ベストエフォート方式で条件を調節できます。
ここでは触れませんでしたが、Nodeではなく、Pod間の配置の近さを指定するInter-pod affinityとInter-pod anti-affinityもあります。
Inter-pod affinityはPodがなるべく物理的に近い場所に配置されるように調整します。
例えば、Webアプリとキャッシュ製品のPodは、同一AZ等に配置するよう指定することが考えられます。
一方で、Inter-pod anti-affinityは逆に物理的に遠い場所に配置されるように調整できます。
これは、リソース競合等の理由で他のPodに悪影響を与えるケースや、自分自身をAntiに指定することで均等に、各Nodeに分散配置するケース等が考えられます。
Inter-pod affinityとInter-pod anti-affinityの詳細は公式ドキュメントを参照してください。
TaintToleration
#基本的にNodeAffinityは、Podのマニフェストに対象Nodeの条件を記述することで、特定の種類のNodeで実行させます。
TaintTolerationは、アプローチの方向が逆で、Node側にキズ(Taints)をつけることで、該当NodeにPodをスケジュールさせません。
スケジュールするにはPod側でTolerationを記述し、これを許容する必要があります。
利用例としては、特定のワークロード専用のNodeを用意し、デフォルトで他のワークロードを実行するPodをスケジュールさせないようにしたい場合等が考えられます。
NodeへのTaints追加は以下のようにします。
# ここでは ip-192-168-60-243.ap-northeast-1.compute.internal
NODE_NAME=$(kubectl get node -l node.kubernetes.io/instance-type=c5.xlarge -o jsonpath='{.items[0].metadata.name}')
kubectl taint nodes ${NODE_NAME} compute-optimized=:NoSchedule
Taintsの指定の構文はkubectl taint nodes <node-name> key=value:<effect>で、valueは省略可能です。
ここではキー(compute-optimized)のみを指定しました。
effectにはNoScheduleの他に、NoExecute/PreferNoScheduleが指定可能です。
NoScheduleはNodeAffinityと同じで、スケジュール時のみ有効で、Taintsをつけたときに既に実行中のPodは無視します。
NoExecuteは、NodeAffinityにはないもので、既に実行中のPodでもTolerationがない場合は、別のNodeに再スケジュールされます(Evict)。
PreferNoScheduleは原則スケジュールされませんが、他に空きがない場合はこのNodeへのスケジュールを許容します(Scoringによる優先順位付け)。
Taintsの動きを確認するために、マニフェストを以下のように修正します。
kind: Deployment
apiVersion: apps/v1
metadata:
name: ap-northeast-1a-app
labels:
app: ap-northeast-1a-app
spec:
replicas: 5
selector:
matchLabels:
app: ap-northeast-1a-app
template:
metadata:
name: ap-northeast-1a-app
labels:
app: ap-northeast-1a-app
spec:
nodeSelector:
topology.kubernetes.io/zone: ap-northeast-1a
containers:
- name: ap-northeast-1a-app
image: alpine:latest
command: [sh, -c, "sleep infinity"]
# resources.requestsは削除
# (ap-northeast-1c-appは省略)
NodeAffinityを削除し、NodeSelectorでAZをap-northeast-1aに配置する設定へ戻しました。
また、全てのPodがNodeにスケジュールされるようresources.requestsの指定を削除しました。
これを適用します。
kubectl delete deploy --all
kubectl apply -f app.yaml
Podのスケジュール状況を確認します。
kubectl get pod -o custom-columns=NAME:metadata.name,NODE:spec.nodeName
NAME NODE
ap-northeast-1a-app-644f5bb54-8sknq ip-192-168-34-122.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1a-app-644f5bb54-ck2wl ip-192-168-41-178.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1a-app-644f5bb54-llh9p ip-192-168-34-122.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1a-app-644f5bb54-vpb2t ip-192-168-34-122.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1a-app-644f5bb54-zt6pl ip-192-168-41-178.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1c-app-7c6858695b-f24gb ip-192-168-72-28.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1c-app-7c6858695b-m264z ip-192-168-72-28.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1c-app-7c6858695b-qrfhz ip-192-168-77-172.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1c-app-7c6858695b-rzp27 ip-192-168-77-172.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1c-app-7c6858695b-v2hr2 ip-192-168-72-28.ap-northeast-1.compute.internal -> m5.large
先程Taints(compute-optimized)をつけたc5.xlargeのNode(ip-192-168-60-243...)は、AZがap-northeast-1aに配置されているにも係わらず、どのPodも実行されていないことが確認できます。
これは、PodでこのTaintsを許容しないため、FilteringでこのNodeがスケジュール対象から除外されているためです。
次に、仮定として高いCPUスペックを要求するPodを新規追加し、これにはTaintsを許容(Toleration)するようにしてみましょう。
以下のマニフェストファイルを作成します(app-cpu.yaml)。
kind: Deployment
apiVersion: apps/v1
metadata:
name: app-cpu
labels:
app: app-cpu
spec:
replicas: 3
selector:
matchLabels:
app: app-cpu
template:
metadata:
name: app-cpu
labels:
app: app-cpu
spec:
# compute-optimized taintsを許容
tolerations:
- key: compute-optimized
operator: Exists
effect: NoSchedule
# インスタンスタイプ限定
nodeSelector:
node.kubernetes.io/instance-type: c5.xlarge
containers:
- name: app-cpu
image: alpine:latest
command: [sh, -c, "sleep infinity"]
tolerationsでNodeに指定したTaints(compute-optimized)を許可するように指定しています。
ここではtaintsが存在しているかのみ(Exists)を指定していますが、EqualでTaintsの値に合致するかも指定可能です。
また、nodeSelectorでインスタンスタイプを指定する必要もあります。これを指定しない場合は、このPodは全てのNodeに対してスケジュールされてしまいます。
TolerationはあくまでもTaintsを許容できるかを指定しているもので、NodeAffinityのようにスケジュールする(したい)Nodeを限定するものではありません。
このPodを追加でデプロイします。
kubectl apply -f app-cpu.yaml
PodのNode配置状況を確認してみましょう。
kubectl get pod -o custom-columns=NAME:metadata.name,NODE:spec.nodeName
NAME NODE
ap-northeast-1a-app-644f5bb54-8sknq ip-192-168-34-122.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1a-app-644f5bb54-ck2wl ip-192-168-41-178.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1a-app-644f5bb54-llh9p ip-192-168-34-122.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1a-app-644f5bb54-vpb2t ip-192-168-34-122.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1a-app-644f5bb54-zt6pl ip-192-168-41-178.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1c-app-7c6858695b-f24gb ip-192-168-72-28.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1c-app-7c6858695b-m264z ip-192-168-72-28.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1c-app-7c6858695b-qrfhz ip-192-168-77-172.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1c-app-7c6858695b-rzp27 ip-192-168-77-172.ap-northeast-1.compute.internal -> m5.large
ap-northeast-1c-app-7c6858695b-v2hr2 ip-192-168-72-28.ap-northeast-1.compute.internal -> m5.large
app-cpu-5b465cd668-4tflm ip-192-168-60-243.ap-northeast-1.compute.internal -> c5.xlarge
app-cpu-5b465cd668-75t5k ip-192-168-60-243.ap-northeast-1.compute.internal -> c5.xlarge
app-cpu-5b465cd668-gfp99 ip-192-168-60-243.ap-northeast-1.compute.internal -> c5.xlarge
新しく追加したPod(app-cpu...)が、Taintsをつけたインスタンスタイプc5.xlargeのNode(ip-192-168-60-243...)にスケジュールされていることが分かります。
クリーンアップ
#デプロイしたPodは以下で削除します。
kubectl delete deploy --all
クラスタ環境は、以下のクリーンアップ手順を参照してください。
まとめ
#NodeAffinityやTaintTolerationを使うことで、柔軟にKubernetesのスケジューラを調整できることが実感できたと思います。
通常意識することは少ないかと思いますが、スケジューラを理解することで、様々なワークロードでKubernetesを活用することが可能となります。
参考資料
- 公式ドキュメント: Scheduling, Preemption and Eviction