OpenAI Realtime API の音声会話アプリを WebRTC を使って実装する
Back to Top2024年10月に登場したOpenAIのRealtime APIは、任意のアプリでAIとリアルタイム音声会話を実現する画期的なAPIです。
これまでWebSocketのみをサポートしていたRealtime APIですが、先日WebRTCへの対応が発表されました。
さらに、価格の大幅な引き下げや、音声品質の向上といったアップデートも加わり、より手軽に使えるAPIとなっています。
That’s it. That’s the tweet. The Realtime API now supports WebRTC—you can add Realtime capabilities with just a handful of lines of code.
— OpenAI Developers (@OpenAIDevs) December 17, 2024
We’ve also cut prices by 60%, added GPT-4o mini (10x cheaper than previous prices), improved voice quality, and made inputs more reliable. https://t.co/ggVAc5523K pic.twitter.com/07ep5rh0Kl
このアップデートにより、ブラウザ上で動作するクライアントアプリは、低遅延で実装が容易なWebRTCが推奨されるようになりました。
以前の記事では、WebSocketを利用して音声会話アプリをNuxtで実装しましたが、今回は新たにサポートされたWebRTCを使ったバージョンを試してみます。
以下はWebRTCバージョンのRealtime APIの構成です。
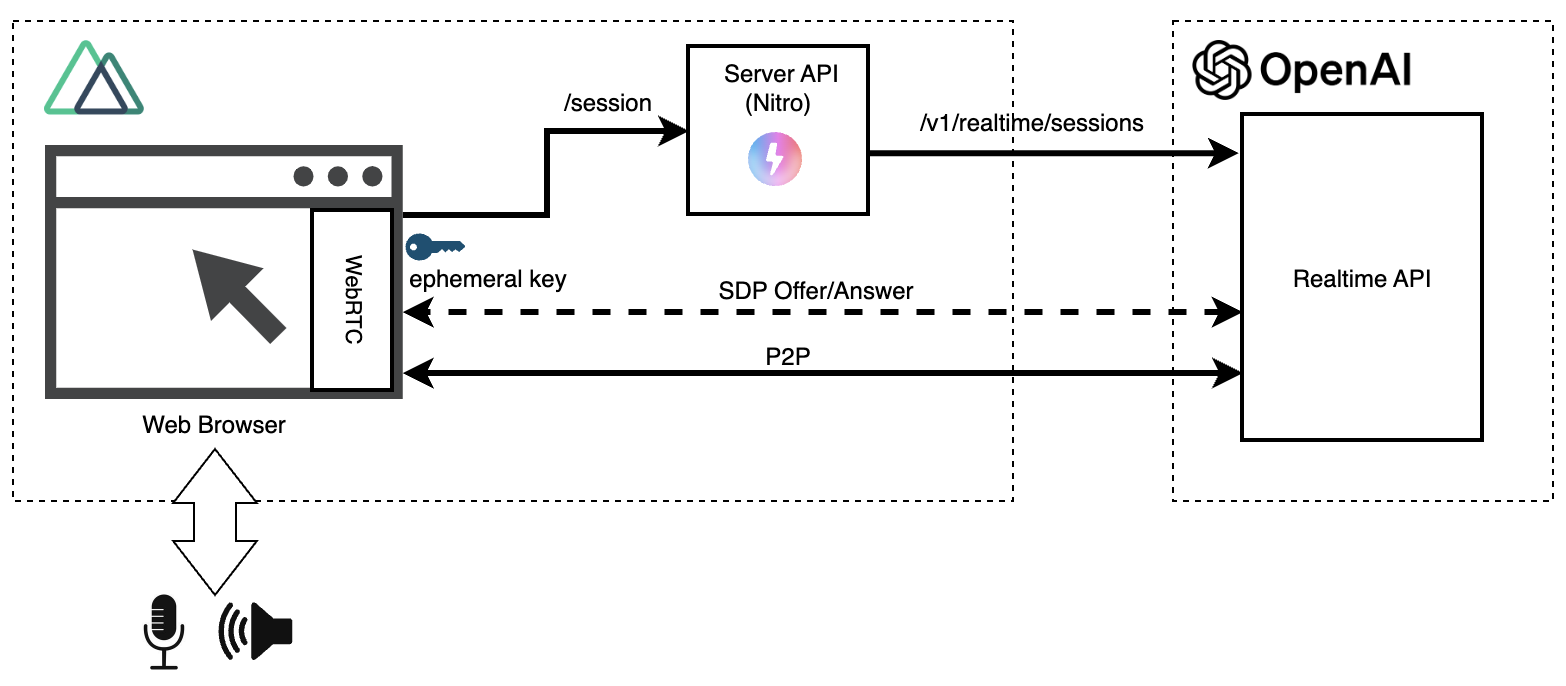
以前のWebSocketバージョンでは、OpenAIのAPIキーをブラウザに晒さないために、ブラウザとRealtime APIの間に中継サーバーを用意していました。
一方、WebRTCバージョンでは初回の一時認証キー(Ephemeral Key)取得を除き、Realtime APIとブラウザが直接通信(P2P: Peer to Peer) する設計になっています。
ソースコードはこちらで公開しています。ここではWebSocketバージョンに加えてWebRTCバージョンも追加した形になっています。
以降で、ポイントを絞って説明します(全てのソースコードは掲載しません)。
サーバーAPI(一時認証キー取得)
#Realtime APIとセッションを確立するためには、事前に一時的な認証キー(Ephemeral Key)を取得する必要があります。この操作には通常のOpenAI APIキーが必要です。
そのため、この部分はサーバーサイド側のAPIとして実装します。
ここでは、NuxtのサーバーAPIを使って以下のようなAPIを事前に用意しました[1]。
export default defineEventHandler(async () => {
return await $fetch<{ client_secret: { value: string } }>('https://api.openai.com/v1/realtime/sessions', {
method: 'POST',
headers: {
'Authorization': `Bearer ${process.env.OPENAI_API_KEY}`,
'Content-Type': 'application/json'
},
body: {
model: 'gpt-4o-realtime-preview-2024-12-17',
voice: 'shimmer',
instructions: 'あなたは元気なアシスタントです。敬語は使わずにフレンドリーに話してください。',
input_audio_transcription: { model: 'whisper-1' },
turn_detection: { type: 'server_vad' }
}
});
});
ここでリクエストボディでRealtime APIの各種設定をしていますが、WebSocketのようにセッション確立後にsession.updateイベントを発行して変更もできます。
上記エンドポイントを呼び出すと、以下のようなレスポンスが返ってきます。
{
"id": "sess_xxxxxxxxxxxxxxxxxxxxx",
"object": "realtime.session",
"model": "gpt-4o-realtime-preview-2024-12-17",
// (省略)
"client_secret": {
"value": "ek_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"expires_at": 1734673378
},
"tools": []
}
- client_secret.value: 一時認証キー(Ephemeral Key)
- client_secret.expires_at: 認証キーの有効期限(発行後1分間)
以降は、クライアントサイドのRealtime API関連のソースコードについて説明します。
全ソースコードは以下から確認できます。
認証キー取得
#ユーザーから接続要求があると、先ほど作成したサーバーAPIを呼び出し、Realtime APIから一時的な認証キー(Ephemeral Key)を取得します。
// 一時的な認証キーを取得
const tokenResponse = await $fetch('/session');
const ephemeralKey = tokenResponse.client_secret.value;
ここで取得したephemeralKeyを使って、Realtime APIとセッションを確立します。
このキーは有効期限が短い(発行後1分間)ため、セッション開始直前に取得するのがポイントです。
マイク音声の取得
#次に、Media Streams APIを使ってマイク音声を取得します。
// 入力音声取得(許可)
const mediaStream = await navigator.mediaDevices.getUserMedia({
audio: true
});
initAudioWaveFormCanvas(mediaStream); // 波形描画開始
初回実行時、ブラウザがユーザーにマイク使用の許可を求めます。
許可が得られた場合、取得した音声ストリーム(mediaStream)を用いて音声波形の描画を開始します。
音声波形の描画部分については本題でありませんので説明は省略します(WebSocketバージョンと同じものを使っています)。
RTCPeerConnection作成
#WebRTCの接続管理を担うRTCPeerConnectionオブジェクトを作成します。
peerConn = new RTCPeerConnection();
このオブジェクトが、Realtime APIとのP2P通信を確立・管理する役割を果たします。
RTCPeerConnectionには、音声やデータの送受信トラックを追加し、接続の設定を行います。
音声出力処理
#Realtime APIから受け取る音声トラックをaudioタグに設定し、再生します。
const audioEl = document.createElement('audio');
audioEl.autoplay = true;
// Realtime APIからのトラック受信時
peerConn.ontrack = event => {
const remoteStream = event.streams[0];
connectStreamToAnalyser(remoteStream); // 音声出力の波形表示
audioEl.srcObject = remoteStream; // 音声をaudioタグに接続
};
WebSocket版では、出力音声のキューイングや音声形式を変換する必要がありました。
しかし、WebRTCではaudioタグに受信した音声トラックを直接設定するだけで、AIが生成した音声をローカルのオーディオデバイスで再生できます。これにより、処理が大幅に簡素化されました。
入力音声(マイク)処理
#マイクから取得した音声トラックをRTCPeerConnectionに追加し、サーバーに送信します。
peerConn.addTrack(mediaStream.getTracks()[0]);
WebSocket版は、一定サイズまでバッファリグしてRealtime APIに送信するなど工夫しましたが、WebRTCバージョンでは1行になりました😅
データチャンネル作成とイベント処理
#WebRTCのデータチャンネルを作成し、Realtime APIのイベントを受信します。
channel = peerConn.createDataChannel('oai-events');
channel.addEventListener('message', (e) => {
const event = JSON.parse(e.data);
switch (event.type) {
case 'response.audio_transcript.done':
// 出力音声テキスト。ユーザー音声より先に発火することがあるので遅延表示
setTimeout(() => logMessage(`🤖: ${event.transcript}`), 100);
break;
case 'conversation.item.input_audio_transcription.completed':
if (event.transcript) logMessage(`😄: ${event.transcript}`);
break;
case 'error':
logEvent(event.error);
if (event.code === 'session_expired') disconnect();
break;
}
});
ここでは入力、出力の各音声のテキストやエラー情報を受け取り、それをUIに描画しています。
データチャンネルはこのようなサーバーイベント受信だけでなく、クライアントイベントを送信する場合にも使用します。
以下はsession.updateイベントでRealtime APIの設定を変更する例です[2]。
channel.onopen = () => {
channel.send(JSON.stringify({
type: 'session.update',
session: {
input_audio_transcription: { model: 'whisper-1' },
},
}))
}
SDP交換と接続確立
#WebRTCのSDP(Session Description Protocol)を交換し、接続を確立します。
const offer = await peerConn.createOffer();
await peerConn.setLocalDescription(offer);
const sdpResponse = await $fetch(
`https://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-12-17`, {
method: 'POST',
body: offer.sdp,
headers: {
Authorization: `Bearer ${ephemeralKey}`,
'Content-Type': 'application/sdp'
}
});
await peerConn.setRemoteDescription({
type: 'answer',
sdp: sdpResponse
});
まず、自分側の接続情報(SDPオファー)を生成し、ローカルの設定として登録しています。
次にその接続情報をRealtime APIに送信し、Realtime APIの接続情報(SDPアンサー)を生成します。この時、先ほど取得した一時認証キー(Ephemeral key)も渡します。
Realtime APIから返ってきた接続情報は、そのままリモート設定として登録します。
これにより、双方の接続条件が一致し、通信準備が整います。
ChromeでWebRTCをデバッグする場合は、chrome://webrtc-internals/にアクセスするとSDPオファー/アンサーのテキスト情報を確認できます。
動作確認
#主要なソースコードは以上です。以下ローカル環境で実行する例です。
npm run dev
以下はWebRTCバージョンのWebアプリを動かした動画です(ミュートを解除するとAIの音声が出ます。周囲の環境にご注意ください)。
まとめ
#WebSocket版では音声処理に苦労しながら実装しましたが、今回のWebRTC版ではそのような複雑な処理が不要になり、非常にシンプルな実装を実現できました。
OpenAIの推奨でもありますし、ブラウザアプリでRealtime APIを使う場合は、このWebRTC版を組み込んでいきたいですね。