Spring Boot で作る Kafka Streams アプリケーション
Back to TopKafka Streams は Apache Kafka のクラスター上でデータのストリーム処理を実現するためのライブラリです。
Apache Kafka の公式ドキュメントには以下のようにあります(Google 翻訳による)。
ミッションクリティカルなリアルタイムアプリケーションとマイクロサービスを作成する最も簡単な方法
Kafka Streams は、アプリケーションとマイクロサービスを構築するためのクライアントライブラリであり、入力データと出力データは Kafka クラスターに格納されます。(Kafka Broker ではなく)クライアント側で標準の Java および Scala アプリケーションを作成およびデプロイする単純さと、Kafka のサーバー側クラスターテクノロジーの利点を組み合わせます。
Confluent のドキュメントによると、不正アクセス検知、テレメトリーデータ監視などリアルタイム性が要求されるシステムの構築に多く利用されているようです[1]。
Introduction | Confluent Documentation
Streams アプリのアーキテクチャ
#Kafka Streams アプリは Kafka Topic に関連づけられた Consumer (兼 Producer) で構成されます。
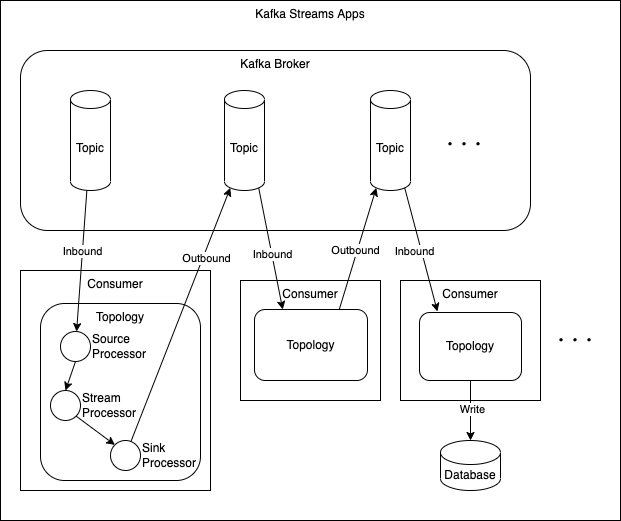
Consumer 内部で Topology と呼ばれるデータパイプラインを構築します。Source Processor で Inbound の Topic からメッセージを受け取り、Stream Processor でデータを処理、Sink Processor で Outbound の Topic に結果を送信します。送信先の Topic には別の Consumer がサブスクライブして更なるデータ処理をしたり、処理結果を何らかのデータベースに書き込むなどの処理を行います。
Kafka Streams アプリは、通常の Kafka Consumer/Producer ですので、VM やコンテナにデプロイして自由にスケールアウトでき、Kafka の可用性・耐障害性の恩恵を受けられます。
Spring Boot による Streams アプリ作成
#Kafka Streams は Kafka プロジェクトに含まれており、クライアントライブラリをインストールするだけで利用できます。Consumer の Topology を構成する Processor の処理を Kafka Streams API を使って実装します。
ここで紹介するコードは以下のリポジトリで全体を見ることができます。
kafka-study/hello-kafka-streams at main · kondoumh/kafka-study
Spring Boot アプリは以下のような構成にしました。Spring Boot 3.0.2 を利用しています。kafka-streams と spring-kafka への依存を追加する必要があります。
- build.gradle
plugins {
id 'java'
id 'org.springframework.boot' version '3.0.2'
id 'io.spring.dependency-management' version '1.1.0'
}
group = 'com.kondoumh'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '17'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter'
implementation 'org.apache.kafka:kafka-streams'
implementation 'org.springframework.kafka:spring-kafka'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'org.springframework.kafka:spring-kafka-test'
}
tasks.named('test') {
useJUnitPlatform()
}
プロジェクトに Configuration クラスを追加しました。Kafka と Kafka Streams を有効化、Kafka Cluster への接続やデフォルトのメッセージシリアライザー/デシリアライザー設定を追加しています。
- KafkaConfig.java
@Configuration
@EnableKafka
@EnableKafkaStreams
public class KafkaConfig {
@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)
KafkaStreamsConfiguration kStreamConfig() {
Map<String, Object> props = new HashMap<>();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
return new KafkaStreamsConfiguration(props);
}
}
簡単な Topology の実装
#Kafka Streams API には Kafka Streams DSL と呼ばれる抽象度の高い API と、Processor API と呼ばれる低レベルの API があります。DSL は Java の Stream API に似ていて処理が簡潔に書けるため推奨されています。
まずは、入力されたメッセージを加工するだけの単純な Topology を作成してみました。
- WordConvertProcesser.java
@Component
public class WordConvertProcesser {
private static final Logger LOGGER = LoggerFactory.getLogger(WordConvertProcesser.class);
private static final Serde<String> STRING_SERDE = Serdes.String();
@Autowired
void buildPipeline(StreamsBuilder streamsBuilder) {
KStream<String, String> messageStream = streamsBuilder
.stream("stream-input-topic", Consumed.with(STRING_SERDE, STRING_SERDE));
messageStream
.filter((k, v) -> v.startsWith("foo_"))
.mapValues((k, v) -> v.toUpperCase())
.peek((k, v) -> LOGGER.info("key: {} word: {}", k, v))
.to("stream-output-topic", Produced.with(STRING_SERDE, STRING_SERDE));
}
}
StreamBuilder クラスで Topology を構成します。
Consumed.with で Inbound の Topic("stream-input-topic") からのデータを取得し Stream を作成しています。このイデオムで Source Processor が生成されています。
中間処理(Stream Processor)として、"foo_" で始まるメッセージだけを選択して大文字に変換しします。
最後に、Produced.with で Topic("stream-output-topic") に結果を送信しています。このイデオムで Sink Processor が生成されています。
途中の peek は副作用のない中間処理を実装するための関数でログ出力用に利用しています。
データの受信・送信には、Serdes.String() で生成した String Serializer/Deserializer を使用しています。
実行は macOS に Homebrew で Kafka をインストールして確認しました。
brew install kafka
Kafka と ZooKeeper の起動は以下のコマンドで行います。
brew services start kafka
brew services start zookeeper
このアプリを起動する前に Inbound と Outbound の Topic を作成しておきます。
kafka-topics --create --bootstrap-server=localhost:9092 --replication-factor 1 --partitions 1 --topic stream-input-topic
kafka-topics --create --bootstrap-server=localhost:9092 --replication-factor 1 --partitions 1 --topic stream-output-topic
Spring Boot アプリを起動します。
./gradlew bootRun
kafka-console-producer を使って、Inbound Topic にいくつかメッセージを送信してみます。
$ kafka-console-producer --bootstrap-server=localhost:9092 --topic stream-input-topic
> foo_bar
> bar_foo
> foo_hello
kafka-console-consumer を使って、Outbound Topic からメッセージを読み出します。
$ kafka-console-consumer --bootstrap-server=localhost:9092 --topic stream-output-topic --from-beginning
FOO_BAR
FOO_HELLO
"foo_" で始まるメッセージが、大文字に変換されて送信されました。
ステートフルな Topology の実装
#上記の Topology は Consumer の状態に依存しないステートレスな処理でしたが、Streams ではステートフルな処理も実現できます。
単語をカウントする Topology の例です。この Topology では単語ごとのカウント値を保持するために KTable を利用しています。
- WordCountProcessor.java
@Component
public class WordCountProcessor {
private static final Logger LOGGER = LoggerFactory.getLogger(WordCountProcessor.class);
private static final Serde<String> STRING_SERDE = Serdes.String();
private static final Serde<Long> LONG_SERDE = Serdes.Long();
@Autowired
void buildPipeline(StreamsBuilder streamsBuilder) {
KStream<String, String> messageStream = streamsBuilder
.stream("word-input-topic", Consumed.with(STRING_SERDE, STRING_SERDE));
KTable<String, Long> wordCounts = messageStream
.mapValues((ValueMapper<String, String>) String::toLowerCase)
.flatMapValues(value -> Arrays.asList(value.split("\\W+")))
.peek((key, word) -> LOGGER.info("key: {} word: {}", key, word))
.groupBy((key, word) -> word, Grouped.with(STRING_SERDE, STRING_SERDE))
.count();
wordCounts.toStream()
.peek((word, count) -> LOGGER.info("word: {} count: {}", word, count))
.to("word-output-topic", Produced.with(STRING_SERDE, LONG_SERDE));
}
}
StreamBuilder のストリームを KTable で蓄積して単語ごとのカウント値を集計しています。
最後に、KTable 自体をストリーム化して、Outbound の Topic に送信します。
Outbound Topic への送信時にはカウント値が数値であるため、Serdes.Long() で生成した Serializer を指定しています。
動作確認前に、kafka-topics コマンドで Inbound Topic と Outbound Topic を作成しておきます。
kafka-topics --create --bootstrap-server=localhost:9092 --replication-factor 1 --partitions 1 --topic word-input-topic
kafka-topics --create --bootstrap-server=localhost:9092 --replication-factor 1 --partitions 1 --topic word-output-topic
Spring Boot アプリを起動して、Inbound topic に適当なメッセージを送信します。key とデータを分けるために key.separator を指定して kafka-console-producer を起動しています。送信メッセージの key はなんでも構いません。
$ kafka-console-producer --bootstrap-server=localhost:9092 --topic word-input-topic --property "parse.key=true" --property "key.separator=:"
>key1:hello world
>key1:hoge fuga
>key1:hello world
kafka-console-consumer で Outbound Topic からメッセージを取り出すには、少し面倒ですが deserializer の指定が必要です。--key-deserializer、--value-deserializer でそれぞれ指定します。
kafka-console-consumer --bootstrap-server=localhost:9092 --topic word-output-topic \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true --property print.value=true \
--property key.separator=":" \
--key-deserializer "org.apache.kafka.common.serialization.StringDeserializer" \
--value-deserializer "org.apache.kafka.common.serialization.LongDeserializer"
Producer 側で入力したデータに応じて、KTable が更新され、Outbound Topic に集計値が出力されます。複数回送信した単語はちゃんと加算されています。
hello:1
world:1
hoge:1
fuga:1
hello:2
world:2
KTable の他に GlobalKTable も利用できます。KTable は1つの Consumer すなわち Topic の 1 Partition のデータを集約するのに対し、GlobalKTable は全ての Partition、つまり Topic 全体のデータを集約するのに使用できます。
KTable は C++ 製の軽量データベース RocksDB の抽象化 API です。
最後に
#Kafka Streams は Kafka プラットフォームに完全に統合されたデータストリーム処理基盤でした。
Streams DSL によりデータ処理に注力できます。この記事で紹介した DSL 以外にデータの Branch や Merge、時間による Window 化などの API もあり、複雑な Topology を構築できます。
Apache には他にもストリーム系の基盤となる OSS がありますが、Kafka Streams は専用のサーバーを必要とせず Kafka Cluster さえあれば使えるところがメリットのようです。Java で Consumer を作った経験があれば、比較的簡単に Streams アプリの実装が出来そうです。
Streams の関連プロダクトとして、ksqlDB というのもあります。
ksqlDB: The database purpose-built for stream processing applications.
内部的には Streams を使っていて、継続的に更新されるストリームデータを SQL のセマンティクスでクエリ可能です。これについても別の機会に紹介してみたいと思います。
ksqlDB の記事書きました。
Kafka Streams パイプラインを迅速に作成できる ksqlDB を触ってみる
参考
10年ほど前に流行した CEP (Complex Event Processing) を想起させます。 ↩︎