Kafka Streams パイプラインを迅速に作成できる ksqlDB を触ってみる
Back to TopksqlDB は、Kafka クラスター上にリアルタイム性の高いアプリケーションを構築するための、ストリーム処理に特化したデータベースです。
ksqlDB: The database purpose-built for stream processing applications.
GitHub - confluentinc/ksql: The database purpose-built for stream processing applications.
先日の記事「Spring Boot で作る Kafka Streams アプリケーション」で紹介した Streams パイプラインは Kafka Streams API を使用して Spring Boot アプリケーションとして実装する方式でした。ksqlDB は SQL だけで Kafka Streams の処理が実現できます。この記事では公式ドキュメントを参照しながら ksqlDB を体験してみます。
アーキテクチャ
#ksqlDB の開発元である Confluent が ksqlDB のアーキテクチャを説明している開発者用コンテンツがあります。
How ksqlDB Works: Advanced Concepts, Queries, and Functions
典型的な Stream 処理パイプラインは、データを取得する Source connector、Stream 処理アプリケーション、イベントを保存するデータベースの書き込み用 Sink connector など多くの要素から構成されます[1]。
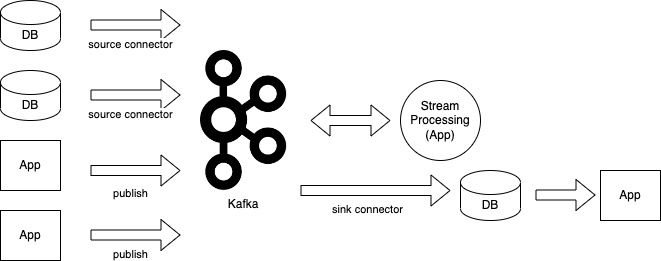
ksqlDB でパイプラインを構成すると ksqlDB がconnector、Stream 処理、イベントを保存するデータベースの機能を兼ね備えているため、単純になります。
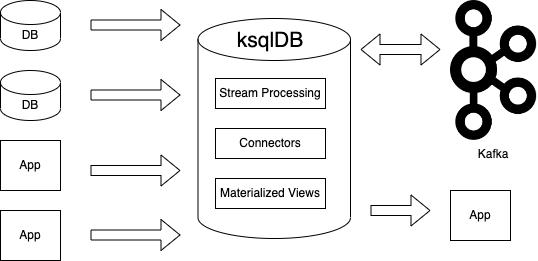
典型的なパイプラインに比べ、ksqlDB を利用するアーキテクチャは耐障害性・スケーラビリティ・セキュリティ・監視・デバッグ容易性において有利であるとのことです。
環境構築(Standalone)
#それでは ksqlDB による開発ができるように Docker で環境を構築していきます。
ksqlDB Quickstart のページから Standalone の環境構築方法に従い、docker compose で構築します[2]。
ksqldb-server と ksqldb-cli のコンテナを起動して、ksqldb-cli のコンテナに入って SQL を実行する構成になっています。ksqldb-server だけでなく ZooKeeper と Kafka Broker も構築する場合の docker-compose.yml です。
- docker-compose.yml
---
version: '2'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.3.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.3.0
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
ksqldb-server:
image: confluentinc/ksqldb-server:0.28.2
hostname: ksqldb-server
container_name: ksqldb-server
depends_on:
- broker
ports:
- "8088:8088"
environment:
KSQL_LISTENERS: http://0.0.0.0:8088
KSQL_BOOTSTRAP_SERVERS: broker:9092
KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: "true"
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: "true"
ksqldb-cli:
image: confluentinc/ksqldb-cli:0.28.2
container_name: ksqldb-cli
depends_on:
- broker
- ksqldb-server
entrypoint: /bin/sh
tty: true
ksqldb-server / ksqldb-cli は amd64 アーキテクチャのイメージのみ提供されています。今回は、Intel 版 MacBook Pro の Docker Desktop で環境を構築しました。
Quickstart のコードスニペットでは、ksqldb-server / ksqldb-client のタグが 0.28.3 になっていますが、このイメージは記事執筆時点では存在せずエラーになりました。1つ前のパッチバージョンを指定すると起動しました。
この docker-compose.yml を配置したディレクトリで docker compose を実行します。
docker compose up
ksql 起動
#ksqlDB 用 CLI を実行するためには以下のように docker exec を実行します。
docker exec -it ksqldb-cli ksql http://ksqldb-server:8088
以下のように ksql のシェルが起動します。
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
===========================================
= _ _ ____ ____ =
= | | _____ __ _| | _ \| __ ) =
= | |/ / __|/ _` | | | | | _ \ =
= | <\__ \ (_| | | |_| | |_) | =
= |_|\_\___/\__, |_|____/|____/ =
= |_| =
= The Database purpose-built =
= for stream processing apps =
===========================================
Copyright 2017-2022 Confluent Inc.
CLI v0.28.2, Server v0.28.2 located at http://ksqldb-server:8088
Server Status: RUNNING
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql>
docker compose で構築した直後の状態で Topic や Stream を表示するクエリを実行すると ksqlDB のログ用オブジェクトが表示されます。
ksql> SHOW TOPICS;
Kafka Topic | Partitions | Partition Replicas
---------------------------------------------------------------
default_ksql_processing_log | 1 | 1
---------------------------------------------------------------
ksql> SHOW STREAMS;
Stream Name | Kafka Topic | Key Format | Value Format | Windowed
------------------------------------------------------------------------------------------
KSQL_PROCESSING_LOG | default_ksql_processing_log | KAFKA | JSON | false
------------------------------------------------------------------------------------------
example スニペットを実行
#ksqlDB example snippets を参考にいくつかスニペットを実行してみます。
可変長文字列と整数の列を持つシンプルな Stream を Topic と共に作成する SQL です。
CREATE STREAM S1 (c1 VARCHAR, c2 INTEGER)
WITH (kafka_topic='s1', key_format='kafka', partitions=1, value_format='json');
これを ksql で実行すると作成された旨のメッセージが出力されます。
Message
----------------
Stream created
----------------
Example のスニペットは、以下のように既存の Topic を指定して Stream を作る例になっているので事前に Topic を作成していないとエラーになります。
CREATE STREAM s1 (c1 VARCHAR, c2 INTEGER)
WITH (kafka_topic='s1', value_format='json');
Topic s1 も一緒に作るためには partitions など作成に必要な情報を付加します。
Topic と Stream の一覧を表示すると Topic (s1) と Stream(S1) ができています。
ksql> SHOW TOPICS;
Kafka Topic | Partitions | Partition Replicas
---------------------------------------------------------------
default_ksql_processing_log | 1 | 1
s1 | 1 | 1
---------------------------------------------------------------
ksql> SHOW STREAMS;
Stream Name | Kafka Topic | Key Format | Value Format | Windowed
------------------------------------------------------------------------------------------
KSQL_PROCESSING_LOG | default_ksql_processing_log | KAFKA | JSON | false
S1 | s1 | KAFKA | JSON | false
------------------------------------------------------------------------------------------
Stream S1 を DESCRIBE してみました。
ksql> DESCRIBE S1 EXTENDED;
Name : S1
Type : STREAM
Timestamp field : Not set - using <ROWTIME>
Key format : KAFKA
Value format : JSON
Kafka topic : s1 (partitions: 1, replication: 1)
Statement : CREATE STREAM S1 (C1 STRING, C2 INTEGER) WITH (KAFKA_TOPIC='s1', KEY_FORMAT='kafka', PARTITIONS=1, VALUE_FORMAT='json');
Field | Type
-------------------------
C1 | VARCHAR(STRING)
C2 | INTEGER
-------------------------
Local runtime statistics
------------------------
(Statistics of the local KSQL server interaction with the Kafka topic s1)
Stream にデータを送信する SQL です。
INSERT INTO s1 (c1, c2) VALUES ('hoge', 1);
上記の SQL を実行して、以下の SQL を実行します。
SELECT * FROM s1 EMIT CHANGES;
送信したデータが取得されました。
+------------------------------------------+------------------------------------------+
|C1 |C2 |
+------------------------------------------+------------------------------------------+
|hoge |1 |
EMIT CHANGES は Stream からデータを受信し続ける "push query" という ksqlDB 特有の構文です。push query として実行すると、ksql のシェルは継続的にクエリを実行し続け、データが Stream から取得されるたびに結果を出力するモードになります。
EMIT CHANGES をつけない場合は、実行時点の最新情報を1度だけ取得してクエリを終了します。これは "pull query" と呼ばれます。
Stream を削除するには、以下の SQL を実行します。
DROP STREAM S1;
実行すると、以下のメッセージが表示されます[3]。
Message
--------------------------------------
Source `S1` (topic: s1) was dropped.
--------------------------------------
Stream の利用
#Quickstart の少し実用的なサンプルを見てみましょう。
まず、ライダーの位置が緯度経度で通知される Stream "riderLocations" を作成します。ライダーのプロフィールID、緯度・経度をカラムに持ちます。
CREATE STREAM riderLocations (profileId VARCHAR, latitude DOUBLE, longitude DOUBLE)
WITH (kafka_topic='quickstart-locations', value_format='json', partitions=1);
Message
----------------
Stream created
----------------
ドキュメントにはサンプルのシナリオは説明されていませんが、ライダーは配送業務などを行う従業員で、位置情報はスマホや車載機器などから取得しているのでしょう。
Stream に対して、マウンテンビュー[4]から5マイル以内の距離にあるすべての行を GEO_DISTANCE 関数を使って出力する push query を実行します。
SELECT * FROM riderLocations
WHERE GEO_DISTANCE(latitude, longitude, 37.4133, -122.1162) <= 5
EMIT CHANGES;
上記の SQL を実行すると ksql シェルは待ち状態に入り、Stream からデータが取得される度に出力するモードになります。
別の ksql セッションを作成して、以下のようにライダーの位置を Stream に送信します。
INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('c2309eec', 37.7877, -122.4205);
INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('18f4ea86', 37.3903, -122.0643);
INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('4ab5cbad', 37.3952, -122.0813);
INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('8b6eae59', 37.3944, -122.0813);
INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('4a7c7b41', 37.4049, -122.0822);
INSERT INTO riderLocations (profileId, latitude, longitude) VALUES ('4ddad000', 37.7857, -122.4011);
push query 実行中の(待ち状態の) ksql シェルでは、マウンテンビューから5マイル以内の位置データが出力されます。
+---------------------------+---------------------------+---------------------------+
|PROFILEID |LATITUDE |LONGITUDE |
+---------------------------+---------------------------+---------------------------+
|4ab5cbad |37.3952 |-122.0813 |
|8b6eae59 |37.3944 |-122.0813 |
|4a7c7b41 |37.4049 |-122.0822 |
Table (マテリアライズド・ビュー)の利用
#Stream "riderLocations" をベースに、ライダーの最新の位置を表示するマテリアライズド・ビュー "currentLocation" を作成します。ビューの SQL では riderLocations から最新の位置情報を取得して格納します。LATEST_BY_OFFSET 関数によりライダー毎の最新の位置情報が取得できます。
CREATE TABLE currentLocation AS
SELECT profileId,
LATEST_BY_OFFSET(latitude) AS la,
LATEST_BY_OFFSET(longitude) AS lo
FROM riderlocations
GROUP BY profileId
EMIT CHANGES;
この currentLocation から派生する別のマテリアライズド・ビューを作成します。以下は各ライダーがマウンテンビューからどのぐらいの距離にいるのかを GEO_DISTANCE 関数を使って集計する例です。COLLECT_LIST は条件に一致するカラムのデータを配列形式に纏めて取得する関数です。
CREATE TABLE ridersNearMountainView AS
SELECT ROUND(GEO_DISTANCE(la, lo, 37.4133, -122.1162), -1) AS distanceInMiles,
COLLECT_LIST(profileId) AS riders,
COUNT(*) AS count
FROM currentLocation
GROUP BY ROUND(GEO_DISTANCE(la, lo, 37.4133, -122.1162), -1);
マテリアライズド・ビュー ridersNearMountainView に対してマウンテンビューから10マイル以内にいるライダーを問い合わせる pull query の例です。
SELECT * from ridersNearMountainView WHERE distanceInMiles <= 10;
実行すると、次の2行が出力されて完了しました。RIDERS カラムには、各距離に位置するすべてのライダーが配列で取得されています。
+------------------------+-------------------------------+-------------------------+
|DISTANCEINMILES |RIDERS |COUNT |
+------------------------+-------------------------------+-------------------------+
|0.0 |[4ab5cbad, 8b6eae59, 4a7c7b41] |3 |
|10.0 |[18f4ea86] |1 |
Query terminated
connector の作成
#ライダーの Stream サンプルでは、INSERT 文を用いて、Stream にデータを投入しましたが、実際の業務ではアプリのデータベースを起点とするパイプラインを組むため、データベースに対して Source connector で接続する必要があります。ksqlDB では、CREATE SOURCE CONNECTOR 文で Source connector を作成できます。
以下は、JDBC で PostgreSQL に接続してデータを取得する Source connector を作る例です。table.whitelist に取得対象のテーブルを列挙します。Source connector は jdbc_<table_name> という規約でテーブル毎に Topic が作成されますので Stream を作成する際にそれら Topic を参照します。
-- Stream the contents of each table in the include list
-- into a corresponding topic named "jdbc_<table name>"
CREATE SOURCE CONNECTOR jdbc_source WITH (
'connector.class' = 'io.confluent.connect.jdbc.JdbcSourceConnector',
'connection.url' = 'jdbc:postgresql://localhost:5432/postgres',
'connection.user' = 'user',
'topic.prefix' = 'jdbc_',
'table.whitelist' = 'include_this_table',
'mode' = 'incrementing',
'numeric.mapping' = 'best_fit',
'incrementing.column.name' = 'id',
'key' = 'id');
通常 Kafka で Source connector を構築する場合は、Kafka connect というフレームワークで作られたモジュールをデプロイして利用します。データベースの変更をキャプチャーする Kafka connect としては Debezium が有名です。Debezium については以下の記事で紹介しています。
ksqlDB では DDL を実行するだけで Source connector を作成できるため、他システムからのデータ取得が非常に簡単にできると言えます。
Sink connector も CREATE SINK CONNECTOR 文で作成できます。以下は、Elasticsearch 用の Sink connector を作成する例です。
-- Send data from all of the given topics into Elasticsearch
CREATE SINK CONNECTOR elasticsearch_sink WITH (
'connector.class' = 'io.confluent.connect.elasticsearch.ElasticsearchSinkConnector',
'key.converter' = 'org.apache.kafka.connect.storage.StringConverter',
'topics' = 'send_these_topics_to_elasticsearch',
'key.ignore' = 'true',
'schema.ignore' = 'true',
'type.name' = '',
'connection.url' = 'http://localhost:9200');
最後に
#ksqlDB の環境を構築してストリーム処理作成を体験してみました。ksqlDB 単体で Stream 処理、connector、マテリアライズド・ビューを、しかもすべて DDL で作成できるため、構築・運用は非常にシンプルです。Stream 処理もほぼ普通の SQL なので、Kafka Streams API で Spring Boot アプリを作るのに比べ、開発・デプロイのサイクルが格段に短く、迅速にパイプラインを構築できそうです。
ksqlDB のドキュメントサイトで色々なユースケースのチュートリアルやサンプルが参照可能です。
ksqlDB Overview - ksqlDB Documentation
先日の記事「Spring Boot で作る Kafka Streams アプリケーション」で紹介したパイプラインもこの構成でした。 ↩︎
Confluent Cloud / Confluent Platform での構築方法も記載されています。 ↩︎
Topic は残ります。また、Topic は DROP 文では削除できませんでした。 ↩︎
アメリカ合衆国カリフォルニア州の都市 ↩︎