用 AWS 视角解读 Google Cloud 入门
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
这是is开发者网站降临节日历2025的第12天的文章。
前言
#我是业务解决方案事业部的塚野。目前,在我负责的项目中,公共云使用的是 Google Cloud。
最初我在工作和个人开发中使用的是 AWS,无论是基础设施架构还是服务的选择,都以「AWS 的思路」为基础。然而在被分配到该项目后,我开始正式学习 Google Cloud,才发现它的设计理念和网络模型与 AWS 存在很大差异。
在跟进学习的过程中,我曾将 AWS 的常识照搬到 Google Cloud 上,结果陷入混乱,因此迫切希望能有一份能够并列对比两者的系统性资料。
因此,本文将以在 AWS 上搭建的简单演示应用为例,
从“用 Google Cloud 实现相同架构会如何?”的角度,
在与 AWS 对比的过程中介绍 Google Cloud 的产品与设计理念。
同时,本文面向 AWS 用户,旨在为 AWS 用户理解 Google Cloud 提供指引,因此不对 AWS 各服务进行讲解。
演示应用的构成
#本文考虑的演示应用是一个简单的 ToDo 应用。
它是在典型的三层 Web 应用中,加入用于保存非结构化数据的对象存储的架构。
前端采用 Next / Nuxt 的 SSR(Server-Side Rendering),
构建成前端和后端 API 可以在同一服务器上托管的架构。
- 前端:由 Next / Nuxt 等构建的 Web UI(通过 SSR 在服务器端渲染)
- 后端 API:提供任务 CRUD 的 REST API
- 持久化层:RDBMS(用户、任务、项目等数据)
- 文件存储:保存用户上传的头像图片或附件等
本文以非常简单的应用作为比较 AWS 与 Google Cloud 的题材。因此不包含高级机器学习(虽然这也是 Google Cloud 的优势之一)、消息服务、DNS、事件驱动架构等。
- 网络
- 计算
- 数据库
- 对象存储
聚焦于这些云平台的基本要素。
另外,实际生产环境中需要考虑的多 AZ(多可用区)和多地域的冗余架构也不在本文讨论范围内。
AWS 上的架构
#首先来看 AWS 上的演示应用架构。
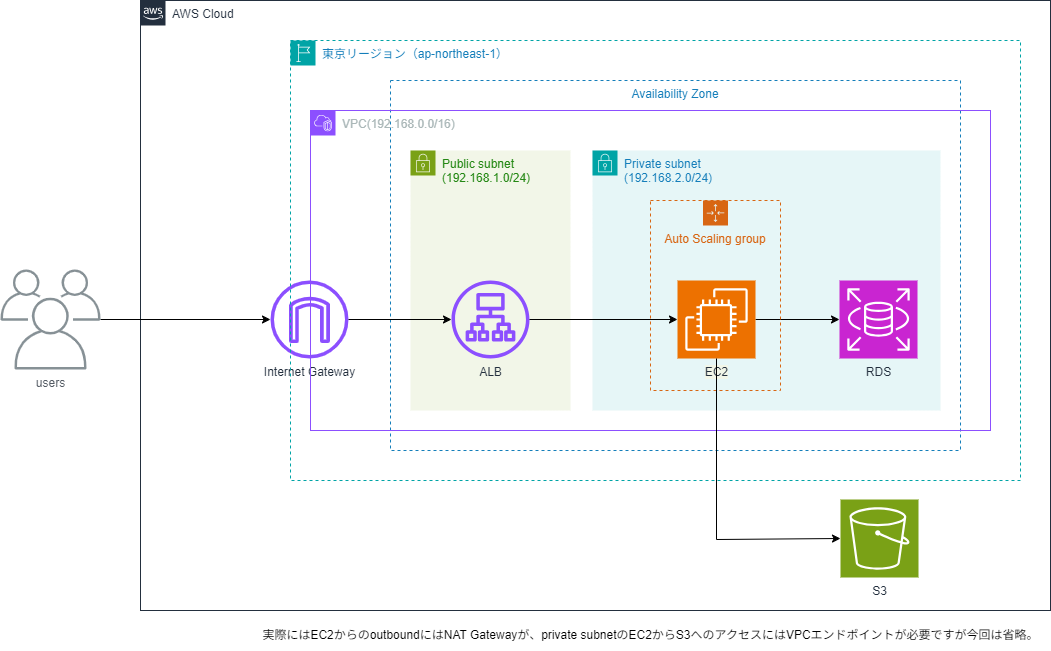
应用部署的区域为东京区域(ap-northeast-1)。
在该区域内创建一个 VPC,VPC 中包含一个可用区(AZ)。
在该可用区内分别配置公共子网和私有子网。
然后,将用于托管 Next / Nuxt SSR 和后端 API 的计算服务 EC2 部署在私有子网中,并配置 Auto Scaling 组。
在公共子网中部署 Application Load Balancer(ALB),
将来自互联网的流量路由到 Auto Scaling 组。
在持久化层,将 Amazon RDS(MySQL / PostgreSQL)部署在与 EC2 相同的私有子网内。
用户上传的文件保存在 Amazon S3 存储桶中,
私有子网内的 EC2 从 S3 访问。
需要说明的是,实际情况中需要以下网络配置:
- EC2 的外部(Outbound)通信需要 NAT Gateway
- 要安全地从 EC2 访问 S3,需要 VPC 端点(Gateway Endpoint for S3)
但为了保持架构简洁,上图中省略了这些内容。
另外,NAT Gateway 在个人使用场景下成本较高,因此将 EC2 放在公共子网也是一种现实可行的方式。但为了更清晰地对比 AWS 和 Google Cloud,本文中选择将 EC2 放在私有子网的架构。
Google Cloud 上的架构
#接下来,来看在 Google Cloud 上构建相同演示应用时的架构。
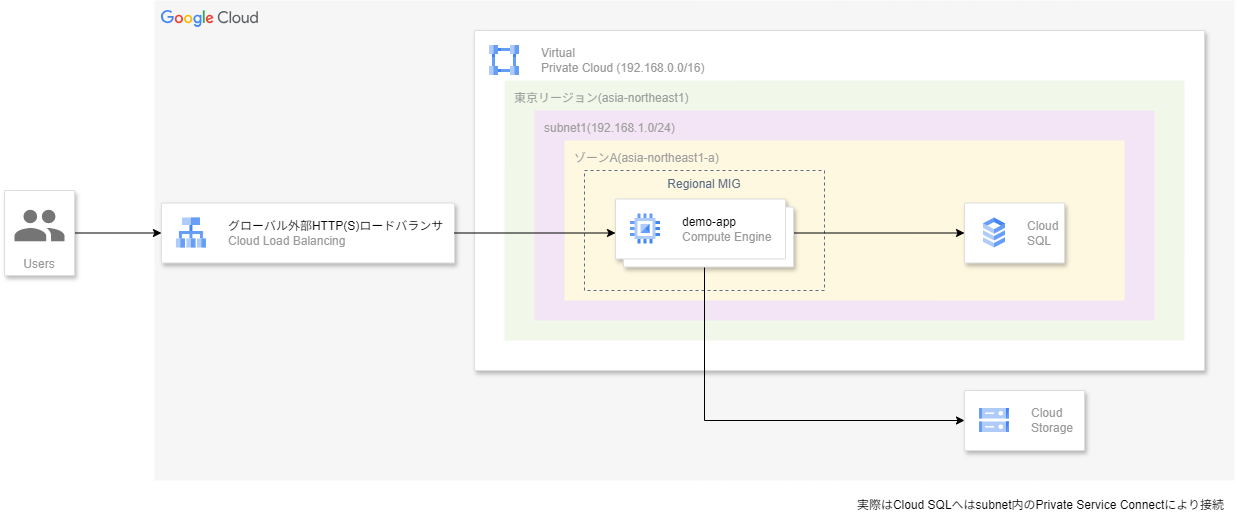
外观上比 AWS 更简洁。
虽然在 Google Cloud 中也有与 AWS 相似的资源名称,比如 VPC 和负载均衡(ロードバランサ),但看到它们的摆放方式时,可能会觉得“咦?”。
这种差异正是 AWS 与 Google Cloud 在理念上的不同,
在后续章节中将详细对比这些资源的作用及设计特点。
网络篇
#首先来看网络资源。
这里讨论以下资源:
- VPC
- 子网与可用区
- 负载均衡
VPC
#首先,AWS 与 Google Cloud 在 VPC 的作用域上有很大差异。
在 AWS 中,VPC 是绑定到区域(Region)的区域性资源。
虽然可以跨可用区(AZ)进行配置,但无法跨区域配置同一个 VPC。
而在 Google Cloud 中,VPC 是全局资源。
因此,单个 VPC 中可以包含多个区域,相比 AWS 更容易构建多区域网络。
与 AWS 相比,Google Cloud 的一大特点是基于全局资源的设计理念。
Google Cloud 首先创建全局 VPC,然后在其内部按区域和相当于 AWS 可用区(AZ)的“可用区”进行分区,这是自上而下的构建方式。
而 AWS 则是针对每个区域创建 VPC,必要时再跨区域连接以实现多区域配置,即以区域为基本单位的自下而上方式。
这种设计理念的差异,正是 AWS 用户接触 Google Cloud 时最先感到困惑的要点。
子网与可用区
#接下来,说明子网和可用区的处理方式。
在 Google Cloud 中,可以向已创建的 VPC 添加子网,但与 AWS 不同,子网是以区域为单位的资源。
并非像 AWS 那样子网 = AZ 单位。
此外,Google Cloud 的子网没有公有/私有之分,子网的公有/私有属性由分配给子网的路由(是否将默认路由指向 Internet Gateway)和防火墙规则决定。
另外,“可用区”(Zone)是 Google Cloud 中相当于 AWS AZ 的最小数据中心单元。它与 AWS 一样作为划分区域的单位,但子网的归属方式不同。
在 AWS 中,子网以 AZ 单位创建,而在 Google Cloud 中,则是在子网内部存在多个可用区。
综上所述,Google Cloud 的架构特点如下:
- 子网跨整个区域,可供区域内所有可用区使用
- 应用部署的可用区可在子网内选择
- 公有/私有属性由路由和防火墙规则控制
因此,与在 AWS 中按 AZ 划分子网并实现冗余的模型相比,
Google Cloud 的子网架构更简单,更容易实现可用区冗余。
负载均衡
#负载均衡(LB)的设计理念在 AWS 与 Google Cloud 中也有所不同。
这里仅论及 L7 层的 LB。在 AWS 中,L7 LB 为 ALB,但它是区域性资源,每个区域的端点不同。
因此,如果要进行全球发布,需要结合使用 Route 53 或 CloudFront。
而在 Google Cloud 中,L7 LB 为 外部 HTTP(S) 负载均衡。它也有多种类型[1],但默认情况下与 VPC 一样,属于全局资源。
在 AWS 中如果要构建全球 LB,需要组合多种服务,而在 Google Cloud 中,LB 本身即可实现全球发布,这是一个显著差异。
此外,AWS 与 Google Cloud 在互联网连接的处理方式上也略有不同。
在 AWS 中,为了将 VPC 公布到外部,需要显式创建 Internet Gateway(IGW)并将其关联到公共子网的路由表。
而在 Google Cloud 中,当用户创建相当于 IGW 的资源(如外部 HTTP(S) 负载均衡)时,无需直接感知 IGW,Google 的边缘网络会自动作为与互联网的入口。
因此,在 Google Cloud 中很少需要将“将哪个部分公开到互联网”作为细节网络配置进行指定,相比 AWS 抽象层级更高。
网络小结
#到目前为止,演示应用的网络架构如下:
- 创建一个 VPC 作为全局资源,在其中包含东京区域(asia-northeast1)。
- 在东京区域内创建区域子网。
- 在区域子网内的特定可用区(本例中为可用区 A)部署计算和数据库。
- 将 L7 LB 作为全局资源部署。
| 资源 | AWS 的作用域 | Google Cloud 的作用域 |
|---|---|---|
| VPC | 区域级别 | 全局资源 |
| 子网 | AZ 级别 | 区域级别 |
| 可用区(相当于 AZ) | 一个区域内有多个 AZ,子网与 AZ 一一对应 | 子网跨越多个可用区 |
| 负载均衡(LB) | ALB/NLB 为 区域级别 | 外部 HTTP(S) LB 默认为 全局 |
| 互联网连接 | 通过将 IGW 附加到 VPC 并在路由表中进行控制 | 利用 Google 的外部边缘网络(通过 LB)作为入口 |
计算篇
#接下来,看看计算服务。
如何对实际运行应用程序的服务器进行冗余和扩展,是 AWS 与 Google Cloud 的一个重要对比点。
在 AWS 中,通过 EC2 实例承载前端/后端服务器,并将 EC2 实例放入 Auto Scaling 组。
这样就可以在满足一定条件时自动增减实例数量。
在 Google Cloud 中,EC2 对应的计算服务是 Google Compute Engine(GCE)。
GCE 同样使用虚拟机承载应用程序,但其伸缩和冗余机制略有不同。在 Google Cloud 中,
可以将 GCE 实例归入 Managed Instance Group(MIG),
从而实现自动的扩缩容和自愈等功能。
与 AWS 相比,Google Cloud 的一个特点是可以按区域创建 MIG。
这与 AWS 的 Auto Scaling 组跨多个 AZ 实现高可用性类似,
但通过将 MIG 配置为“区域 MIG”,
计算资源会自动分布到区域内的多个可用区。
这也与上一章提到的 Google Cloud “子网为区域级”的网络设计有关。
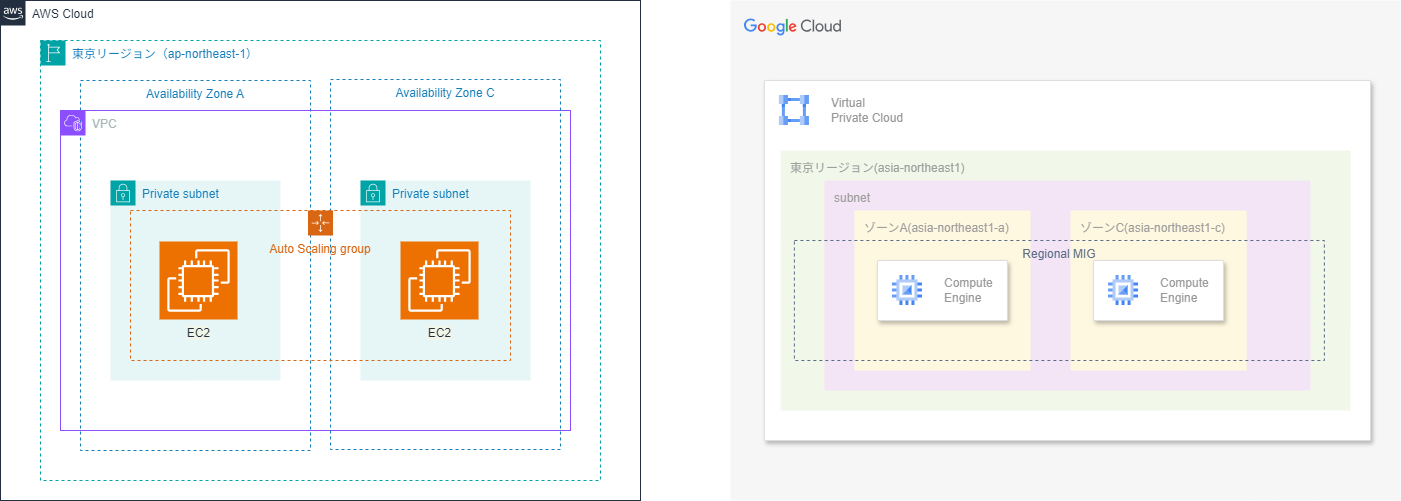
可跨可用区部署的 AWS Auto Scaling 组(左)与可按区域创建的 Google Cloud 区域 MIG(右)
在本次演示应用中,为了保持架构简洁,将 GCE 实例部署在 asia-northeast1 区域中的某个可用区(例如 asia-northeast1-a)。
但在实际生产环境中,常规做法是使用区域 MIG 跨多个可用区部署,
通过跨多个可用区来提高对单一区故障的容错能力。
另外,与 AWS 的 Auto Scaling 组不同,Google Cloud 的 MIG 标配实例模板的版本管理以及滚动更新等部署相关功能。
因此,MIG 不仅仅是一个扩缩容机制,还是基础设施管理抽象化的一部分。
数据库与存储篇
#接下来,看看演示应用所使用的数据库和存储。
在演示应用中,使用关系型数据库(RDB)保存用户和任务等数据,使用对象存储保存用户上传的图片文件等。
在 AWS 中,关系型数据库使用 Amazon RDS,存储使用 Amazon S3。
运行在 EC2 上的应用从私有子网内部连接 RDS,并将用户上传的文件存储到 S3。
另一方面,在 Google Cloud 上构建相同应用时,使用对应的产品 Cloud SQL 和 Cloud Storage。
Cloud SQL 是一个托管 MySQL 或 PostgreSQL 的服务[2],Cloud Storage 则可像 S3 一样作为对象存储使用。
到目前为止,与 AWS 并无太大差异,但深入到网络架构就能看到 Google Cloud 特有的特点。
首先比较 DB 服务。RDS 将实例部署在 VPC 内的子网中,
而 Cloud SQL 的实例并不实际存在于 VPC 内。Cloud SQL 位于 Google 管理的网络中,
当从 GCE 等访问时,通过 Private Service Connect(PSC) 进行私有连接。
Cloud SQL 本身不拥有子网,而是通过 PSC 在 VPC 内“仅创建供私有访问使用的入口”。
也就是说,它在表面上看似将实例放在子网中,实际上被隐藏起来。
即使要像 RDS 那样进行冗余配置,也无需进行如将副本放在哪个子网等细化网络设计,
只需指定区域,冗余和副本部署就由 Google 自动完成。
在内部结构被对用户隐藏、以及冗余方式抽象化方面,Cloud SQL 与 AWS 的 Amazon Aurora 有相似之处。
但考虑到个人开发或小规模应用从成本角度首先会选择 RDS,
而 Amazon Aurora 功能较多,作为纯粹关系型数据库服务的比较,本文以 RDS 为对象。
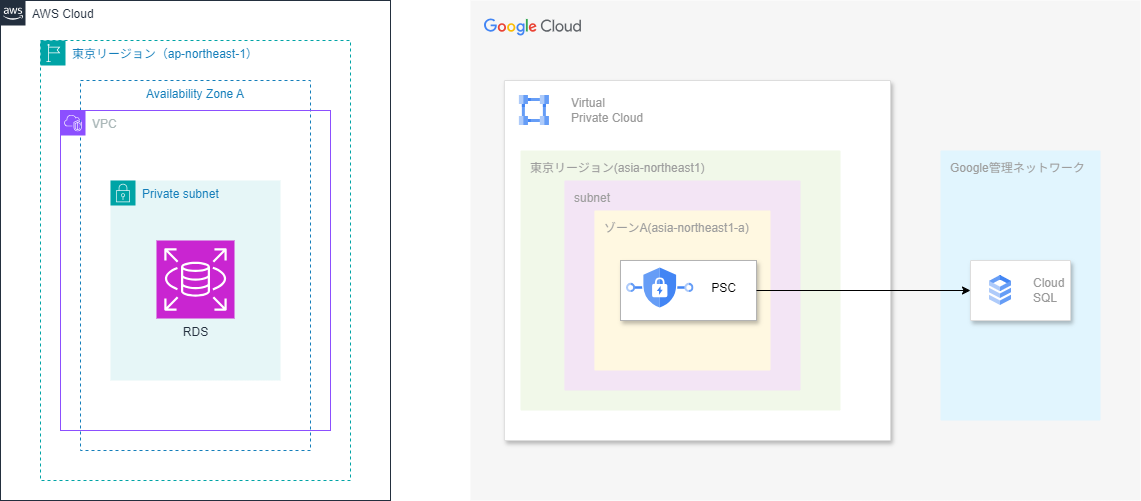
Amazon RDS 部署在子网中(左),Cloud SQL 实例的主体不在子网中,由 Google 管理(右)
对象存储也有类似特点。在 AWS 中,如果 EC2 位于私有子网,需要显式准备 NAT Gateway 或专用于 S3 的 VPC 端点(Gateway Endpoint),设计外部流量出站的路径。
而在 Google Cloud 的 Cloud Storage 中,即使不做特殊配置,也能从 VPC 内实现与 Cloud Storage 的私有连接。
内部通信通过 Google 的骨干网络完成,因此无需经过互联网即可进行安全且高速的访问。
从这些差异可以看出,AWS 与 Google Cloud 在网络设计上的思路不同。
在 AWS 中,假设用户需要相对细致地指定网络路径和安全性,
需要组合 VPC、子网、NAT、VPC 端点等多种资源。
而 Google Cloud 则以 Google 自身在全球范围运营的网络为前提,
将网络抽象化,使用户无需感知即可实现安全高效的通信。
结果是,应用开发者更容易专注于“使用哪些服务”而非“通过哪个网络路径”。
总结
#此次,我们以相同的演示应用为题材,对比了 AWS 与 Google Cloud 的架构。
Google Cloud 是一个以全局网络和抽象化为前提的云平台,如 VPC 和负载均衡都是全局资源。像 Cloud SQL 这样不向用户暴露内部结构、仅需简单设置即可安全使用的服务较多,因此架构比 AWS 更加简洁。但由于抽象层级高,有时难以直观理解“自己的设计范围包含哪些部分”。
另一方面,AWS 的网络边界如 VPC、子网、AZ 等都很明确,易于采用自下而上的架构方式。用户可明确选择互联网连接或私有访问,从而根据需求进行细粒度控制,这是一大优势。在我看来,这种“作用域清晰的结构”易于理解,也带来设计上的安全感。
并非哪一个更优,而是 Google Cloud 采用简洁且高度抽象化的模型,而 AWS 则以结构清晰且易于控制的模型为特点。两者各有优势,最佳解决方案会因应用规模和需求而异。希望本文能成为正在使用 AWS 的读者了解 Google Cloud 的契机。
根据是否作为全局或区域性资源部署、是否对来自公网上的流量进行负载分担或对 Google Cloud 内部流量进行分发等,存在多种类型。L3/4 层的 LB 也同样有多种类型,比较复杂。
这一段可能让人感觉“这是在说什么啊?”,但关于负载均衡的详细解说可参考这篇文章(从 AWS 视角理解 Google Cloud 负载均衡的世界)。究竟为什么会这样。 ↩︎作为 RDBMS 的托管服务,还有 Cloud Spanner,但对于个人开发或小规模开发而言有些大材小用,所以本次选择 Cloud SQL。此外,类似于 Amazon Aurora,Google Cloud 也有自研数据库 AlloyDB,该产品仅兼容 PostgreSQL。 ↩︎