从复制粘贴开始:使用 Amazon Q Developer × Spec Kit 开启 AI 驱动开发
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
本文为在以下活动中演讲内容的文字记录版。
自 2025 年 11 月 17 日起,Q Developer CLI 的正式名称变更为「Kiro CLI」。本文中仍使用撰写时的名称「Q Developer CLI」进行说明,但命令和功能相同。未来更新中 q 命令可能会改为 kiro 命令。
前言
#目标读者
#本文针对以下人士:
- 对使用生成式 AI 进行开发感兴趣的开发者
- 曾因 AI 代码生成导致“非预期实现”而困扰的人
- 希望在保持质量的同时利用 AI 的人员
- 想尝试 Amazon Q Developer(Kiro CLI)或 Spec Kit 的人士
前提知识
#假设您具备以下基础知识:
- Git、GitHub 的基本操作
- Docker、Docker Compose 的基本概念
- Java/Spring Boot、React/TypeScript 的基础(将在示例项目中使用)
- AWS 的基本知识(部署部分)
本文可获得内容
#阅读本文后,您将能够:
- 理解从环境搭建到部署的全流程
- 获取可通过复制粘贴运行的实用提示示例
- 学习 AI 驱动开发中的质量保障方法
- 获取可实际运行的示例项目
背景知识:为什么要采用 SDD+TDD
#生成式 AI 驱动开发的现状
#自 2022 年底 ChatGPT 出现以来,AI 驱动开发迅速普及。目前,GitHub Copilot、Cursor、Claude Code、Windsurf、Amazon Q Developer[1]、Kiro 等多种编码助手可供使用。
AI 的发展正从“模型中心(GPT 时代)”向“代理网络中心”转变,并正从单纯的编码辅助发展为自主执行型代理。
AI 代码生成的“阴影”
#然而,在实际开发中,可能会面临以下挑战。

1. 过度实现
擅自添加未请求的功能。
示例:
- 只请求了登录功能,却连密码重置功能也实现了
- 请求了简单的 CRUD,却额外添加了搜索和排序功能
2. 假设
对需求规格中模糊的部分擅自补全,导致非预期设计。
示例:
- “保存用户信息” → AI 擅自将邮箱地址设为必填项
- “显示数据” → AI 擅自以 10 条为单位实现分页
3. 成功宣告
明明构建或测试失败,却报告“已完成”。
示例:
- 存在编译错误却报告“实现完成”
- 测试失败却报告“所有测试都成功”
4. 维护成本增加
根据最近的研究[2][3],即使借助 AI 辅助工具提升开发速度,维护、审查和质量管理成本仍有上升趋势。此外,还观察到经验丰富的开发者偏离新功能开发任务,转而专注于维护工作。
通过 SDD+TDD 的解决方法
#为了解决这些问题,将结合以下两种方法。
SDD(Specification-Driven Development:规范驱动开发)
在编写代码之前,将预期的行为、需求和约束明确定义为规范,并基于此推进开发的方法。
效果:有了明确的规范,AI 就能毫无歧义地生成准确的代码[4]。
TDD(Test-Driven Development:测试驱动开发)
在编写代码之前定义测试,以失败为出发点反复进行修正和改进的方法。
效果:将 TDD 框架引入基于 LLM 的代码生成后,生成成功率提高[5]。将测试明确为“规范·约束”能改善 AI 的生成精度[6]。
通过 SDD 固定规范,并通过 TDD 使正确行为标准化,从而提高 AI 的可控性。
环境搭建:以最小准备开始
#前提条件检查清单
#请确认已安装以下工具:
- Windows + WSL2(也可使用 Linux)
- Git
- VSCode
- Docker Desktop(或 Docker Engine)
- AWS Builder ID 或 AWS IAM Identity Center 账户(用于 Q Developer)
步骤 1:克隆 GitHub 仓库
#克隆此次讲演使用的公开示例仓库。
# 切换到工作目录
cd ~/workspace
# 克隆仓库
git clone https://github.com/mamezou-tech/aidd-demo.git
# 进入目录
cd aidd-demo
仓库内容:
backend/:Spring Boot 后端(Java 17,Spring Boot 3.x)frontend/:React 前端(React 18,TypeScript,Vite)specs/:规范文档.devcontainer/:DevContainer 配置.amazonq/:Amazon Q Developer 配置docker-compose.yml:开发环境配置
步骤 2:在 VSCode 中启动 DevContainer
## 在 VSCode 中打开
code .
VSCode 启动后,执行以下步骤:
- 点击左下角的绿色按钮(远程资源管理器)
- 选择“Reopen in Container”
- 首次可能需要几十分钟(构建 Docker 镜像)
- 容器内终端会自动打开
DevContainer 包含内容:
- Node.js、Java 17、Gradle
- AWS CLI
- Q Developer CLI 1.19.7
- 各类开发工具
步骤 3:Q Developer CLI(Kiro CLI)登录
#Free 计划(AWS Builder ID)
# 登录命令
q login
# 浏览器会打开,使用 AWS Builder ID 登录
# 登录完成后返回终端
Pro 计划(IAM Identity Center)[7]
# 登录命令
q login
# 按提示输入 IAM Identity Center 信息
# Start URL: https://[your-domain].awsapps.com/start
# Region: ap-northeast-1 等
# 浏览器会打开,完成认证
开始对话模式:
q chat
自 2025 年 11 月 17 日起,Q Developer CLI 的正式名称变更为「Kiro CLI」。本文中仍使用撰写时的名称「Q Developer CLI」进行说明,但命令和功能相同。未来更新中 q 命令可能会改为 kiro 命令。
步骤 4:启动应用并进行运行确认
#1. 启动数据库和后端
在 Dev Container 内的终端执行以下命令:
docker compose up -d
此命令会启动以下服务:
- MySQL 数据库(端口 3306)
- Spring Boot 应用(端口 8080)
确认容器已启动:
docker compose ps
# 期望输出:
# mysqldb 和 app 容器的 STATUS 为 Up (healthy)
2. 启动前端
执行以下命令:
cd frontend
npm run dev
※依赖包会在 Dev Container 启动时自动安装。
前端将在 http://localhost:3000 启动。
运行确认:
在浏览器中访问以下地址:
- 前端: http://localhost:3000
- 后端 API: http://localhost:8080/api/health
故障排除(环境搭建)
#Q1:DevContainer 无法启动
原因:Docker 未启动或资源不足。
解决方案:
# 确认 Docker 是否已启动
docker ps
# 检查资源设置(在 Docker Desktop 中,Settings > Resources)
Q2:找不到 q 命令
原因:DevContainer 构建不完整。
解决方案:
# 重新构建容器
# 在 VSCode 中按 Ctrl+Shift+P → "Dev Containers: Rebuild Container"
# 或通过命令行
docker compose down
docker compose up -d --build
Q3:端口 3000 或 8080 已被占用
原因:其他应用正在占用该端口。
解决方案:
# 查看占用该端口的进程
lsof -i :3000
lsof -i :8080
# 终止进程或修改 docker-compose.yml 中的端口
# ports:
# - "3001:3000" # 将 3000 改为 3001
实践①:规范制定 - specify → clarify 的迭代
#Spec Kit 命令一览
#Spec Kit 提供以下命令。
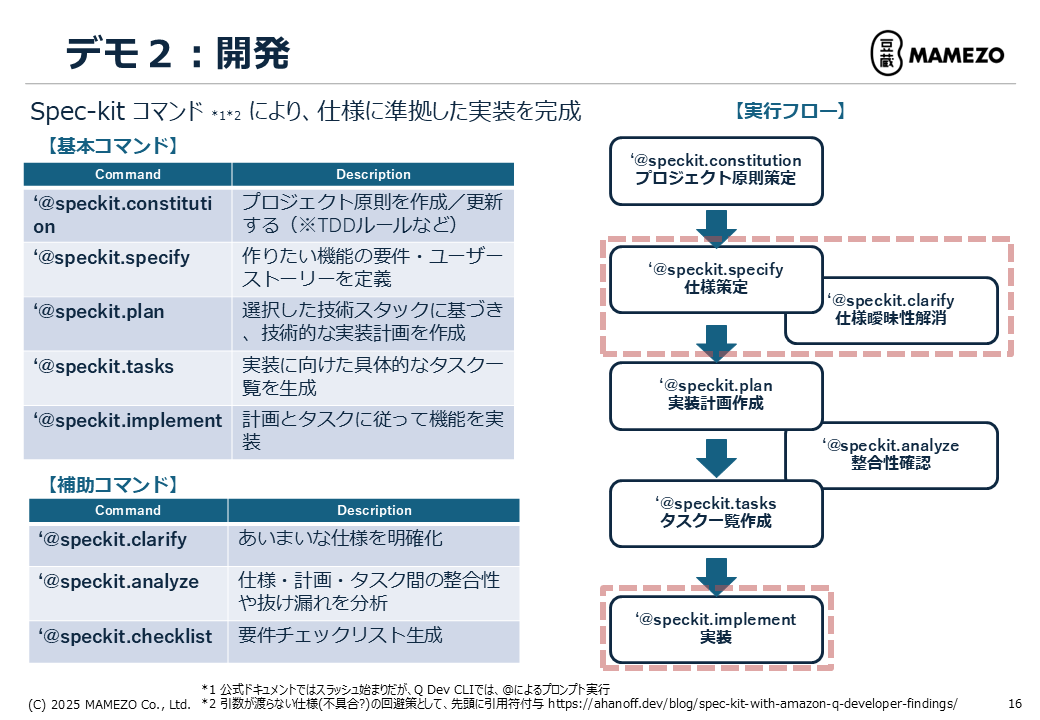
| 命令 | 说明 | 主要用途 |
|---|---|---|
@speckit.constitution |
创建/更新项目原则 | 定义 TDD 规则等 |
@speckit.specify |
定义功能需求/用户故事 | 制作规范文档 |
@speckit.clarify |
澄清模糊的规范 | 细化规范 |
@speckit.plan |
制定技术实施计划 | 架构设计 |
@speckit.analyze |
分析规范、计划与任务之间的连贯性 | 冲突检查 |
@speckit.tasks |
生成实施任务列表 | 任务拆分 |
@speckit.implement |
按计划和任务进行实施 | 生成代码 |
@speckit.checklist |
生成需求检查清单 | 进度管理 |
在 Q Developer CLI 中,用 @ 而非 / 来调用命令。为正确传递参数,请在命令开头添加引号(')[8]。
开始对话式会话
#首先,启动 Q Developer CLI 的对话式会话。之后的所有命令都在该会话内执行。
q chat
会话开始后,会显示提示符,即可输入命令。
步骤 1:确认项目原则
#确认项目中是否已定义 TDD 等原则。如需添加,可使用以下命令。
'@speckit.constitution <要添加到项目原则中的内容>'
示例:
# Project Constitution
## Test-First Imperative
始终在编写代码之前先编写测试。
- 先创建单元测试
- 确认测试失败(Red phase)后再进行实现
- 作为非协商事项严格执行
## Library-First Principle
所有功能均作为独立的库实现。
## Simplicity Gate
防止过度工程化。
- 初始实现最多支持 3 个项目
在公开仓库的 constitution.md 中记录了 Spec Kit 提示的 6 项原则。
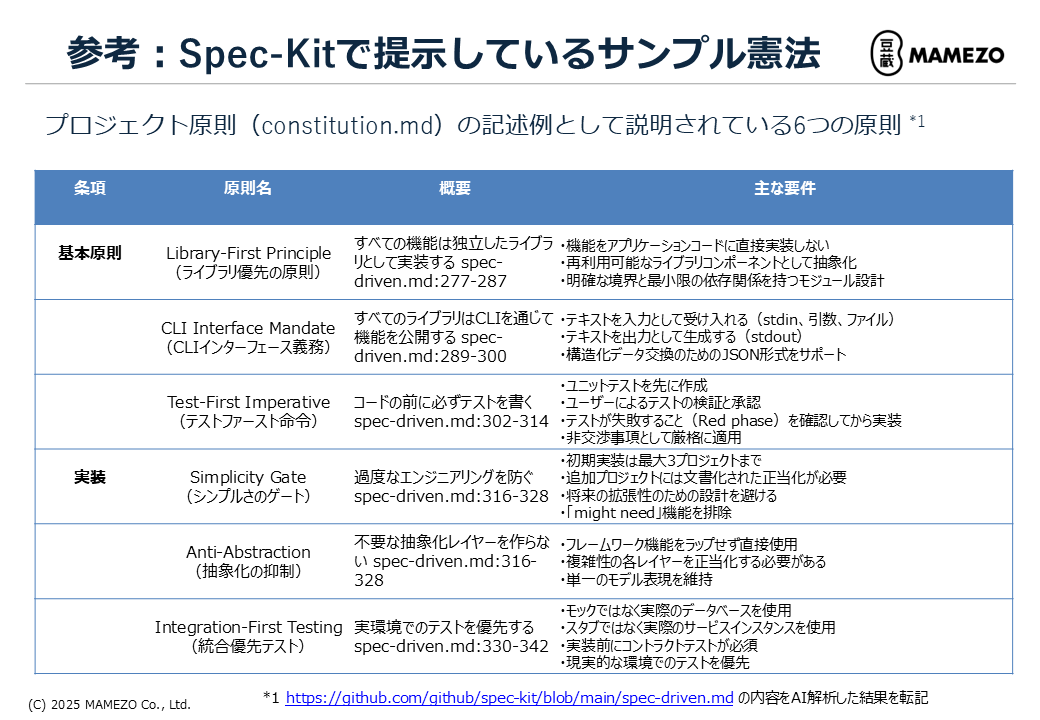
步骤 2:制定规范(@speckit.specify)
#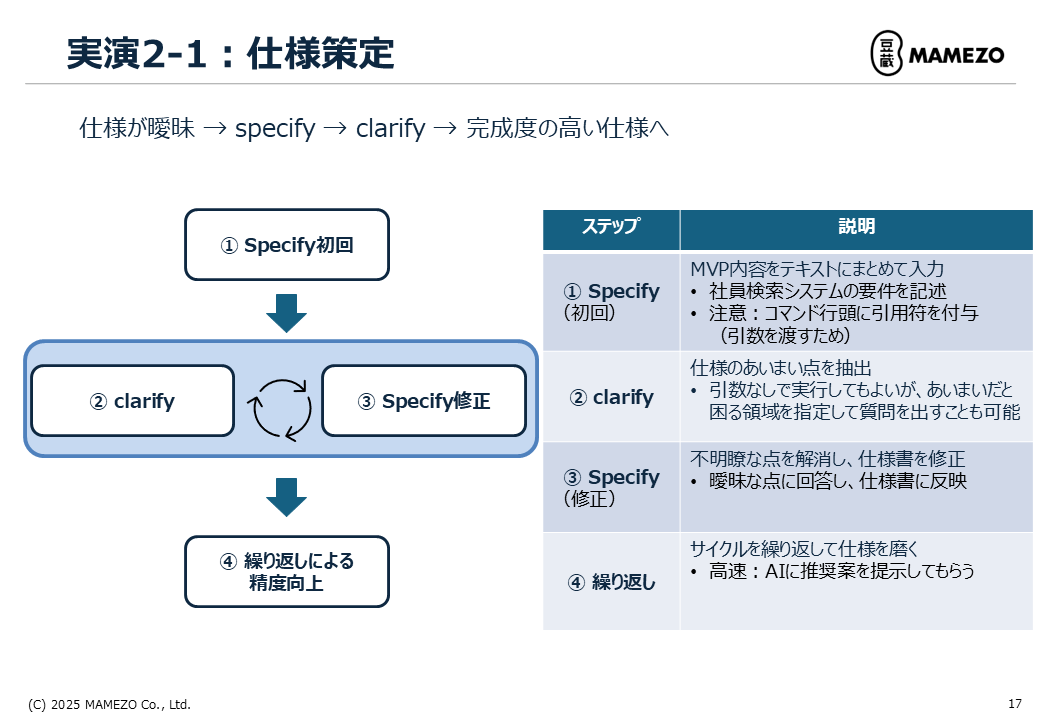
初次 specify
创建员工搜索系统 MVP 的规范。
示例提示:
'@speckit.specify
请为员工搜索系统(MVP)创建规范。
【目的】
统一管理员工信息,使人事能够快速了解“谁拥有哪些技能、属于哪个组织”。
【主要用户】
- 人事:整体概览公司员工、技能和组织信息,作为人员调配和招聘计划的输入。
【预期用例】
- 人事通过搜索具有特定技能(例如:Java、AWS)的员工,跨部门创建候选人列表。
- 在附带头像的员工列表和详细页面上,可视觉化识别人员。
【MVP 提供的功能范围】
- 登录功能(简单认证)
- 员工信息的注册、查看和搜索
- 基本属性(姓名、员工 ID、所属组织、职位、雇佣类型)
- 头像的上传和显示
- 技能信息查看
- 技能主数据管理
- 员工技能关联
- 组织层级管理(仅支持父子关系的简单树结构)
【MVP 范围外】
- 详细权限管理
- 审计日志
- 高级技能分析
- 组织重组历史管理
- 外部系统集成
【期望输出】
- 用例列表和简单流程
- 界面及 API 概要
- 数据模型概要
- 非功能需求(MVP 所需的最低限度)
- 明确标注 MVP 范围外功能
'
要点:
- 明确描述目的
- 定义用户角色
- 明确 MVP 范围(特别是明确“范围外”)
- 避免模糊表达
输出示例:
AI 会生成 spec.md 文件。内容可能包括以下内容。
# 员工搜索系统 MVP 规范书
## 1. 概要
...
## 2. 用例
### UC-001: 登录
- 执行者: 人事
- 前提条件: 用户账户已注册
- 基本流:
1. 用户在登录界面输入用户名和密码
2. 系统执行认证
3. 认证成功后重定向到主页
...
## 3. 界面设计
### 3.1 登录界面
- 输入项: 用户名、密码
- 按钮: 登录
...
## 4. 数据模型
### 4.1 员工(Employee)
- employee_id (PK): 员工 ID
- name: 姓名
- organization_id (FK): 所属组织
- photo_url: 头像 URL
...
步骤 3:澄清模糊点(@speckit.clarify)
#在生成的规范中仍有未明确定义的部分,可通过 clarify 命令进行澄清。
示例提示:
'@speckit.clarify
请针对员工搜索系统 MVP 规范,列出以下方面的模糊点,并生成问题列表:
- 登录/认证方式(MVP 的具体前提)
- 技能搜索和展示方式
- 头像上传方式
- 列表界面中的分页/排序处理
'
输出示例:
# 有关规范模糊点的问题
## 登录/认证方式
Q1: 密码加密方式使用哪种?(bcrypt、PBKDF2 等)
Q2: 如何进行会话管理?(Cookie、JWT、服务器端会话 等)
Q3: 是否需要登出功能?
Q4: 密码重置功能是否包含在 MVP 中?
## 技能搜索和展示方式
Q5: 技能搜索是完全匹配还是部分匹配?
Q6: 是否需要多技能的 AND 查询/OR 查询?
Q7: 如何处理技能等级(初级/中级/高级 等)?
## 头像上传方式
Q8: 头像文件大小上限是多少?
Q9: 允许的图片格式?(JPEG、PNG、GIF 等)
Q10: 如果没有头像,是否显示默认图片?
## 分页/排序
Q11: 列表界面每页显示的条目数是多少?
Q12: 排序字段有哪些?(姓名、员工 ID、组织 等)
Q13: 默认排序顺序是什么?
步骤 4:回答问题并修改规范(@speckit.specify)
#根据 AI 提出的问题进行回答,并修改规范。
示例提示:
'@speckit.specify
请根据以下回答更新员工搜索系统 MVP 规范。
【登录/认证方式】
A1: 使用 bcrypt
A2: 将 JWT 令牌保存在 Cookie 中
A3: 需要登出功能
A4: 密码重置功能不在 MVP 范围
【技能搜索和展示方式】
A5: 部分匹配(前缀匹配)
A6: 仅支持多技能的 AND 查询
A7: 技能等级分为三级(初级/中级/高级)
【头像上传方式】
A8: 小于 5MB
A9: 仅支持 JPEG、PNG
A10: 显示默认头像图片
【分页/排序】
A11: 20 条/页
A12: 可以按姓名、员工 ID、所属组织排序
A13: 默认按姓名升序
'
步骤 5:迭代
#重复 specify → clarify → specify 循环,可大幅减少模糊点。
迭代要点:
- 指定规范中容易引起混淆的部分,可更高效地澄清
- 让 AI 提供推荐方案可以加速流程
加速示例:
'@speckit.clarify
请针对员工信息的注册和更新,列出模糊点,并一并提供你的推荐方案。
'
成果文件:spec.md
#最终可获得如下高完成度的规范文档。
- 用例被具体描述
- 界面项和 API 规范明确
- 数据模型被详细定义
- 模糊点已被消除
- 明确标注了 MVP 范围外
实践②:实施 - TDD 循环的实践
#步骤 1:制定实施计划(@speckit.plan)
#@speckit.plan
输出示例:
# 实施计划
## 技术栈
- Backend: Java 17, Spring Boot 3.2.0, Spring Security, Spring Data JPA
- Frontend: React 18, TypeScript, Tailwind CSS
- Database: MySQL 8.0
- Test: JUnit 5, Testcontainers, Playwright
## 架构
### 后端
- 分层架构
- Controller 层: REST API 端点
- Service 层: 业务逻辑
- Repository 层: 数据访问
### 前端
- 基于组件的架构
- React Router 用于 SPA
- 使用 Context API 进行状态管理
## 安全
- JWT 认证
- 使用 bcrypt 进行密码哈希
- CORS 配置
此内容将保存为 plan.md。
步骤 2:生成任务列表(@speckit.tasks)
#'@speckit.tasks
请将人才管理系统 MVP 拆分为粒度为 2~3 天的实施任务。
'
输出示例:
# 实施任务列表
## Phase 1: 基础构建
- Task 1.1: 设置项目结构
- Task 1.2: 创建数据库模式
## Phase 2: 认证功能
- Task 2.1: 用户实体与 Repository
- Red: 创建 UserRepositoryTest 并确认失败
- Green: 实现 User.java、UserRepository.java 并使测试通过
- Refactor: 整理代码
- Task 2.2: 实现 JWT 认证
- Red: 创建 JwtUtilTest 并确认失败
- Green: 实现 JwtUtil.java、JwtAuthenticationFilter.java
- Refactor: 整理代码
- Task 2.3: 实现登录 API
- Red: 创建 AuthControllerTest 并确认失败
- Green: 实现 AuthController.java、AuthService.java
- Refactor: 整理代码
## Phase 3: 员工管理功能
- Task 3.1: 员工实体与 Repository
- Task 3.2: 员工注册 API
- Task 3.3: 员工搜索 API
- Task 3.4: 员工详情 API
...
此内容将保存为 tasks.md。
步骤 3:实施(@speckit.implement)
#终于进入实施阶段。基于 Spec Kit 的测试优先原则,使用 TDD 循环推进实现。
Task 2.1 实施示例:用户实体与 Repository
示例提示:
'@speckit.implement Task 2.1'
AI 的操作示例:
- 首先生成测试(Red 阶段)
UserRepositoryTest.java:
package com.example.demo.repository;
import com.example.demo.entity.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.jdbc.AutoConfigureTestDatabase;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
import org.testcontainers.containers.MySQLContainer;
import org.testcontainers.junit.jupiter.Container;
import org.testcontainers.junit.jupiter.Testcontainers;
import java.util.Optional;
import static org.assertj.core.api.Assertions.assertThat;
@DataJpaTest
@Testcontainers
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
class UserRepositoryTest {
@Container
static MySQLContainer<?> mysql = new MySQLContainer<>("mysql:8.0")
.withDatabaseName("testdb");
@Autowired
private UserRepository userRepository;
@Test
void 根据用户名搜索用户() {
// Arrange
User user = new User();
user.setUsername("testuser");
user.setPassword("hashedPassword");
userRepository.save(user);
// Act
Optional<User> found = userRepository.findByUsername("testuser");
// Assert
assertThat(found).isPresent();
assertThat(found.get().getUsername()).isEqualTo("testuser");
}
@Test
void 搜索不存在的用户名时返回空() {
// Act
Optional<User> found = userRepository.findByUsername("nonexistent");
// Assert
assertThat(found).isEmpty();
}
}
- 运行测试并确认失败
# AI 自动执行
./gradlew test --tests UserRepositoryTest
# 结果:FAILED(因为 User.java 和 UserRepository.java 尚不存在)
- 生成实现(Green 阶段)
User.java:
package com.example.demo.entity;
import jakarta.persistence.*;
import lombok.Data;
@Entity
@Table(name = "users")
@Data
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, unique = true, length = 50)
private String username;
@Column(nullable = false)
private String password;
@Column(length = 100)
private String email;
}
UserRepository.java:
package com.example.demo.repository;
import com.example.demo.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import java.util.Optional;
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
Optional<User> findByUsername(String username);
}
- 运行测试并确认成功
./gradlew test --tests UserRepositoryTest
# 结果:PASSED
- 重构(Refactor 阶段)
在测试通过的情况下,对代码进行改进。AI 会执行以下重构操作:
- 改进变量名和方法名
- 删除重复代码
- 提升可读性
在确认测试持续通过的前提下,安全地改进代码。
TDD 循环的迭代要点
#Red → Green → Refactor 循环:
- Red(编写会失败的测试)
- 使用测试表达期望的行为
- 由于尚未实现,测试会失败
- Green(使测试通过的最小实现)
- 编写能通过测试的代码
- 此阶段优先“可运行”而非“优雅”
- Refactor(重构)
- 在测试通过的状态下改进代码
- 删除重复并提升可读性
实践③:部署 - 仅用自然语言构建 AWS
#前提条件
#- 已安装 AWS CLI(包含在 DevContainer 中)
- 已配置 AWS 配置文件(认证信息)
- 拥有启动 EC2 权限的 IAM 用户/角色
此次部署用于测试目的,以下进行简化:
- 使用 HTTP 而非 HTTPS
- 单一 EC2 实例
- 无负载均衡器
- 数据库运行在容器中
步骤 1:创建 EC2 实例
#示例提示:
请使用 Amazon Linux 2023 和 t3.small 创建 EC2 实例。
安全组仅允许从您的 IP 地址访问 22 端口(SSH)和 3000 端口(应用)。
请创建名为 "aidd-demo-key" 的密钥对。
AI 的操作示例:
AI 会自动执行以下操作:
- 获取当前 IP 地址
- 创建安全组(SSH: 22,应用: 3000)
- 创建密钥对
- 启动 EC2 实例
- 输出实例 ID 和公共 IP
步骤 2:安装 Docker 与 Docker Compose
#示例提示:
请 SSH 连接到 EC2 实例((公共IP)),
安装 Docker 和 Docker Compose。
请将用户添加到 docker 组,并确保无需重新登录即可使用。
AI 的操作示例:
- SSH 连接到 EC2 实例
- 更新系统包
- 安装 Docker、启动并设置开机自启
- 将用户添加到 docker 组
- 安装 Docker Compose
- 确认安装完成
步骤 3:将整套应用传输到 EC2
#示例提示:
请将当前目录下的 docker-compose.yml 以及 backend、frontend、db 目录,
传输到 EC2 实例((公共IP))的 /home/ec2-user/aidd-demo 目录下。
AI 的操作示例:
- 在 EC2 实例上创建目标目录
- 使用 SCP 传输 docker-compose.yml、backend、frontend、db 目录
步骤 4:使用 Docker Compose 启动应用
#示例提示:
请在 EC2 实例中,进入已传输的目录,
执行 docker compose up -d。
请确认所有容器均以 Up(healthy) 状态启动。
AI 的操作示例:
- SSH 连接到 EC2 实例
- 进入已传输目录
- 使用
docker compose up -d启动容器 - 检查所有容器状态,并报告为 Up (healthy)
步骤 5:应用运行确认
#在浏览器中访问:
http://(公共IP):3000
API 通信确认:
curl http://(公共IP):8080/api/health
# 输出示例:
# {"status":"UP"}
登录确认:
在浏览器中访问登录界面,并使用以下测试用户信息登录:
- ID: test@example.com
- 密码: aiddTest
登录后会显示主页,通过该链接进入员工搜索系统。
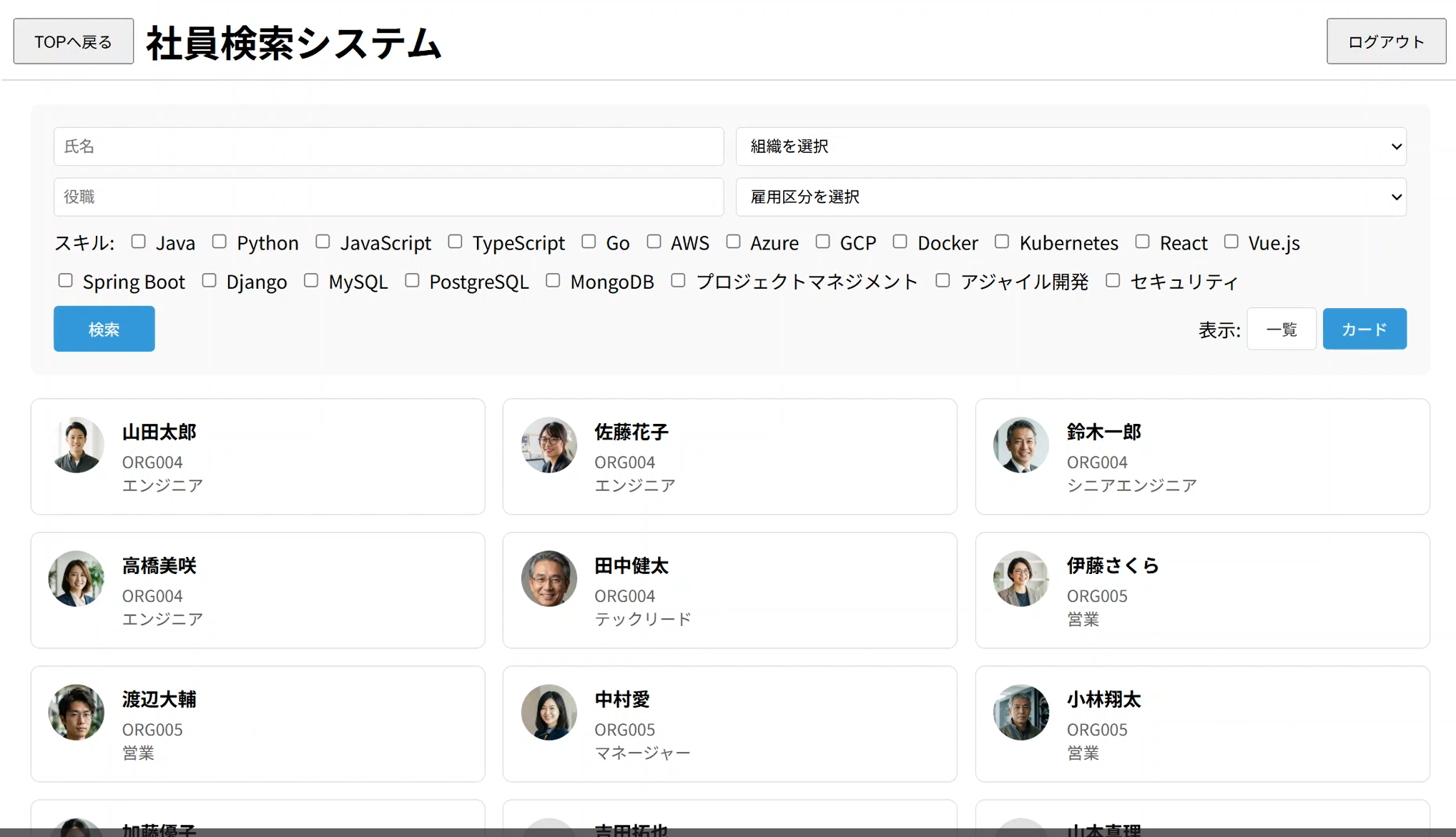
※注册数据及头像均由 AI 生成。
CORS 问题修复(如有需要)
#如果发生 CORS 错误,请执行以下操作。
示例提示:
请修复后端的 CORS 配置。
允许来自前端源(http://(公共IP):3000)的请求。
修复后,请在 EC2 上重启应用。
总结与参考资料
#本文要点
#本文介绍了使用 Amazon Q Developer × Spec Kit 进行 AI 驱动开发的全流程。
环境搭建:
- 仅需克隆 GitHub 仓库即可开始
- 通过 DevContainer 自动解决依赖
规范制定:
- 通过 specify → clarify 的迭代细化规范
- 消除模糊是 AI 应用的关键
实施:
- 实践 TDD 循环(Red → Green → Refactor)
- 通过测试优先原则提高 AI 的生成精度
部署:
- 使用自然语言构建 AWS 资源
重要收获
#- 人的角色不可或缺:在现阶段,上游流程和质量保障由人承担
- 规范与测试是资产:高质量成果可在下一次 AI 驱动开发中复用
Amazon Web Services. Amazon Q Developer. ↩︎
Xu et al. AI-assisted Programming and Maintenance Burden. arXiv, 2025. ↩︎
Amasanti & Jahić. The Impact of Generative AI-Generated Solutions on Software Maintainability. arXiv, 2025. ↩︎
GitHub. Spec-driven development with AI: Get started with a new open source toolkit. 2024. ↩︎
Mathews et al. Test-Driven Development for Code Generation. arXiv, 2024. ↩︎
Chen et al. TENET: Leveraging Tests Beyond Validation for Code Generation. arXiv, 2025. ↩︎
Classmethod. 在成员账户中尝试订阅使用 Amazon Q Developer Pro. 2024. ↩︎
Ahanoff. 使用 Amazon Q Developer 的 Spec Kit:发现事项与习性. 2024. ↩︎