CCPM工具篇:现场运行!使用电子表格×Apps Script运转“真正CCPM”的方法
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
前言
#在上一篇文章「CCPM实战篇」中,介绍了通过CCPM进行现场变革的效果。这次将结合工具,介绍如何制作现实可行的CCPM计划。
1. 背景:为什么不是专用工具,而是电子表格+GAS?
#支持CCPM的商业工具确实很强大,但在尝试导入到现场时会碰到以下障碍:
- 授权费用高
- 功能过多,难以在现场推广
- 与公司内部信息系统部门的协调成本高
因此,我决定按照以下方针自制工具。
| 需求 | 实现手段 |
|---|---|
| 任何人都能立即使用 | Google 电子表格 |
| 希望实现自动排程 | Apps Script(GAS) |
| 在现场可进行反复试错 | 代码全部公开并可修改 |
通过这种方式,最初可以轻松尝试,熟悉后还可以根据现场需求进行定制,从而制作出了这种CCPM工具。
2. 实现的CCPM功能概要
#以下功能通过 Google 电子表格+Apps Script 来实现:
- 基于任务依赖关系的排程
- 基于“每个资源每天只能处理1个任务”的前提的资源约束
- 关键链的识别(包含资源约束)
- 分支缓冲区(Feeding Buffer)的计算
识别关键链时,需要注意考虑资源竞争这一点。
仅根据依赖关系计算关键路径,在现实中可能会出现“因资源不足而延迟”的情况。
3. 电子表格结构
#输入表
#工作表名称:Tasks
请使用上述名称创建工作表。
此工作表用于记录整个项目的任务信息,是CCPM调度器的基础数据。
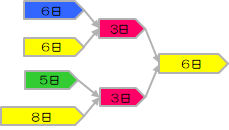
| 任务ID | 任务名称 | 持续天数 | 依赖任务 | 资源 |
|---|---|---|---|---|
| T1 | 实现〇〇功能 | 6 | Blue | |
| T2 | 编写〇〇功能测试规范 | 6 | Yellow | |
| T3 | 编写〇〇功能测试报告 | 3 | T1,T2 | Red |
| T4 | 实现✕✕功能 | 5 | Green | |
| T5 | 编写✕✕功能测试规范 | 8 | Yellow | |
| T6 | 编写✕✕功能测试报告 | 3 | T4,T5 | Red |
| T7 | 编写〇✕集成测试报告 | 6 | T3,T6 | Yellow |
- 任务ID:任务的标识符。用于引用依赖关系。
- 任务名称:任务名称。应使用相关人员易于理解的表达。
- 持续天数:所需工作天数(基于工作日)。
- 依赖任务:前置任务的ID(逗号分隔)。
- 资源:负责该任务的资源。受限于每天只能负责1个任务。
根据以下PERT图,展示了输入表的示例。
脚本
#可以通过 Google 电子表格的“扩展功能”菜单中选择“Apps Script”来编辑脚本。选择后会在新标签页打开 Apps Script 编辑界面,请复制并粘贴6. 脚本示例中的脚本。在 Apps Script 编辑界面点击“保存”按钮,然后点击“运行”按钮,即可生成输出工作表。
输出表
#工作表名称:CCPM_Schedule
| 任务ID | 开始日 | 结束日 | 是否关键 | 缓冲天数 | 缓冲类型 | 缓冲来源任务 |
|---|---|---|---|---|---|---|
| T1 | 1 | 6 | FALSE | |||
| T2 | 1 | 6 | TRUE | |||
| T3 | 7 | 9 | FALSE | |||
| T4 | 1 | 5 | FALSE | |||
| T5 | 7 | 14 | TRUE | |||
| T6 | 15 | 17 | TRUE | 2.5 | Feeding Buffer | T4 |
| T7 | 18 | 23 | TRUE | 1.5 | Feeding Buffer | T3 |
- 任务ID:在原 Tasks 工作表中定义的任务标识符。
- 开始日:日程安排的开始日(以项目开始日为第1天的连续编号)。
- 结束日:日程安排的结束日(StartDay + 持续天数 - 1)。
- 是否关键:如果此任务位于关键链上,则为 TRUE;否则为 FALSE。
- 缓冲天数:根据半缓冲规则,为此任务插入的缓冲天数。
- 缓冲类型:表示是否为 Feeding Buffer(合流缓冲)。项目缓冲暂未实现。
- 缓冲来源任务:表示该缓冲是为了从哪个任务的延迟中吸收设置的。
根据输出表示例,用PERT图表示如下。
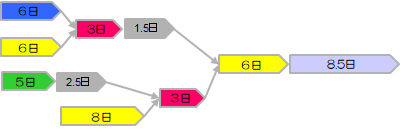
消除了多任务,在汇入关键链之前添加了合流缓冲(灰色任务)。这样可以吸收子链一侧的延迟,避免影响关键链。
4. 脚本要点解析
#此Apps Script通过以下处理步骤实现CCPM日程的自动生成:
步骤 1:读取和结构化任务信息
#const data = sheet.getDataRange().getValues();
- 从输入表 Tasks 获取数据,根据 TaskID、Duration、Dependencies、Resource,将各任务存储为对象。
- 同时,还加入了自依赖或依赖未定义任务时抛出错误的安全检查。
- 通过构建名为 dependents 的逆引用列表,可提高后续关键链搜索的效率。
步骤 2:循环引用检查
#function detectCycle() { ... }
- 因为依赖关系中存在循环(环路)会破坏CCPM的前提,所以使用栈进行遍历检查。
- 如有问题则通过明确的错误信息停止执行。
- 如果不是DAG(有向无环图),项目日程将无法成立。这是必需的校验。
步骤 3:考虑资源冲突的排程
#function getNextAvailableDay(resource, after) { ... }
- 为每个资源记录“已被占用的日期”,并查找下一个空闲日期。
- 从依赖已解决的任务开始,尽可能早地分配资源并进行排程。
- 这里的逻辑用于遵守“1个资源1天1任务”的约束。
- 通过自动化可以吸收在手动操作中容易出错的资源冲突。
步骤 4:识别关键链(依赖+资源)
#function markCriticalChain() { ... }
- 从日程中结束日最晚(最大EndDay)的任务开始,逆向追溯,确定“造成延迟的路径”。
- 不仅考虑依赖关系,还考虑因资源冲突导致的启动延迟,构建实际的延迟链(关键链)。
- 通常的关键路径往往忽略“因资源不足产生的等待时间”,而这里也予以考虑。
- 这就是CCPM中真正的“关键链”。
步骤 5:自动插入Feeding Buffer(合流缓冲)
#const bufferDays = Math.round(dep.duration * 0.5 * 10) / 10;
- 针对汇入关键链的非关键任务,设置合流缓冲,以免其延迟影响主路径。
- 缓冲时长采用“延迟任务时长的50%”的半缓冲规则。
- 通过“既防范最坏,又不过度”的缓冲设计,可维持切实可行的日程。
步骤 6:写入输出表
#resultSheet.getRange(1, 1, output.length, output[0].length).setValues(output);
- 将排程结果输出到CCPM_Schedule工作表。
- 因为包含了关键链信息、缓冲信息等,可直接用于绘制PERT图。
总结:此脚本能做什么?
#该脚本可完全自动执行以下操作:
- 计算满足依赖关系和资源约束的日程
- 识别实际的关键链
- 插入合流缓冲以保证交期
换言之,此工具不是“形式上的CCPM”,而是对现场有效的CCPM,作为一款可轻松试用的工具提供。
5. 结束语
#此工具尚处于发展阶段,但“无论如何都要在现场试用”非常重要。
- 在小项目中试用
- 根据现场情况调整规则和配置
- 积累成功经验
通过这样逐步扩大导入范围,就能让**不只是形式上的“活的CCPM”**落地生根。
6. 脚本示例
#以下是完整脚本。
function scheduleCCPM() {
const ss = SpreadsheetApp.getActiveSpreadsheet();
const sheet = ss.getSheetByName("Tasks");
const data = sheet.getDataRange().getValues();
const headers = data[0];
const rows = data.slice(1);
const taskIndex = Object.fromEntries(headers.map((h, i) => [h, i]));
const tasks = {};
// 读取任务定义 + 自依赖检查
rows.forEach(row => {
const id = row[taskIndex['TaskID']];
const duration = Number(row[taskIndex['Duration']]);
const deps = row[taskIndex['Dependencies']] ? row[taskIndex['Dependencies']].toString().split(',').map(s => s.trim()) : [];
const resources = row[taskIndex['Resource']] ? row[taskIndex['Resource']].toString().split(',').map(s => s.trim()) : [];
if (deps.includes(id)) {
throw new Error(`❌ タスク "${id}" は自身に依存しています。`);
}
tasks[id] = {
id,
duration,
deps,
dependents: [],
resources,
start: 0,
end: 0,
isCritical: false,
};
});
// 构建 dependents(反向引用列表)
for (const id in tasks) {
for (const depId of tasks[id].deps) {
if (tasks[depId]) {
tasks[depId].dependents.push(id);
}
}
}
// 循环引用检查
function detectCycle() {
const visited = new Set();
const stack = new Set();
function visit(id) {
if (stack.has(id)) {
throw new Error(`❌ 循環参照が検出されました: ${id}`);
}
if (visited.has(id)) return;
stack.add(id);
visited.add(id);
tasks[id].deps.forEach(visit);
stack.delete(id);
}
for (let id in tasks) {
visit(id);
}
}
detectCycle();
// 资源调度
const resourceSchedule = {};
function getNextAvailableDay(resource, after) {
const schedule = resourceSchedule[resource] || [];
let day = after;
while (schedule.some(([s, e]) => day >= s && day <= e)) day++;
return day;
}
function reserveResource(resource, start, end) {
if (!resourceSchedule[resource]) resourceSchedule[resource] = [];
resourceSchedule[resource].push([start, end]);
}
// 排程处理(考虑依赖关系 + 资源冲突)
const resolved = new Set();
while (resolved.size < Object.keys(tasks).length) {
for (let id in tasks) {
const task = tasks[id];
if (resolved.has(id)) continue;
if (task.deps.every(d => resolved.has(d))) {
const depEnd = Math.max(0, ...task.deps.map(d => tasks[d].end));
let start = depEnd + 1;
for (const r of task.resources) {
const available = getNextAvailableDay(r, start);
start = Math.max(start, available);
}
task.start = start;
task.end = start + task.duration - 1;
for (const r of task.resources) {
reserveResource(r, task.start, task.end);
}
resolved.add(id);
}
}
}
// 识别关键链(考虑依赖 + 资源冲突)
function markCriticalChain() {
const maxEnd = Math.max(...Object.values(tasks).map(t => t.end));
const endTasks = Object.values(tasks).filter(t => t.end === maxEnd);
const visited = new Set();
function visit(task) {
if (visited.has(task.id)) return;
task.isCritical = true;
visited.add(task.id);
// 由依赖导致的延迟
for (const depId of task.deps) {
const dep = tasks[depId];
if (!dep) continue;
if (dep.end + 1 === task.start) {
visit(dep);
}
}
// 确定因资源冲突造成的延迟(按资源检查前一个任务)
for (const r of task.resources) {
const intervals = (resourceSchedule[r] || []).filter(([s, e]) => e < task.start);
for (const [s, e] of intervals) {
for (const t of Object.values(tasks)) {
if (t.resources.includes(r) && t.start === s && t.end === e && !visited.has(t.id)) {
if (t.end >= Math.max(...task.deps.map(d => tasks[d]?.end || 0))) {
visit(t);
}
}
}
}
}
}
endTasks.forEach(visit);
}
markCriticalChain();
// Feeding Buffer(按任务时长的一半设置缓冲)
const feedingBuffers = [];
for (const t of Object.values(tasks)) {
if (!t.isCritical) continue;
for (const depId of t.deps) {
const dep = tasks[depId];
if (!dep || dep.isCritical) continue;
const bufferDays = Math.round(dep.duration * 0.5 * 10) / 10;
feedingBuffers.push({
mergeTaskId: t.id,
bufferDays: bufferDays,
fromTask: dep.id
});
}
}
// 生成输出
const output = [
["TaskID", "StartDay", "EndDay", "IsCritical", "BufferDays", "BufferType", "BufferFromTask"]
];
for (const t of Object.values(tasks)) {
const buffer = feedingBuffers.find(fb => fb.mergeTaskId === t.id && fb.fromTask === t.id) ||
feedingBuffers.find(fb => fb.mergeTaskId === t.id);
output.push([
t.id,
t.start,
t.end,
t.isCritical ? "TRUE" : "FALSE",
buffer ? buffer.bufferDays : "",
buffer ? "Feeding Buffer" : "",
buffer ? buffer.fromTask : ""
]);
}
// 写入输出表
const resultSheetName = "CCPM_Schedule";
let resultSheet = ss.getSheetByName(resultSheetName);
if (resultSheet) ss.deleteSheet(resultSheet);
resultSheet = ss.insertSheet(resultSheetName);
resultSheet.getRange(1, 1, output.length, output[0].length).setValues(output);
}