将LangMem的长期记忆持久化到PostgreSQL(pgvector)中
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
上一次在这篇文章中,我们详细介绍了如何高效管理 AI 长期记忆的 LangMem 的概况和使用方法。
本文中虽然我们之前使用的是内存存储来作为长期记忆,但在 LangMem 中也可以使用基于 PostgreSQL(pgvector 扩展)的存储。本次,我们将使用这个基于 PostgreSQL 的存储,来尝试更实际的长期记忆应用。
这里,我们将尝试使用可实现零伸缩的 Aurora Serverless v2 作为 PostgreSQL 数据库。
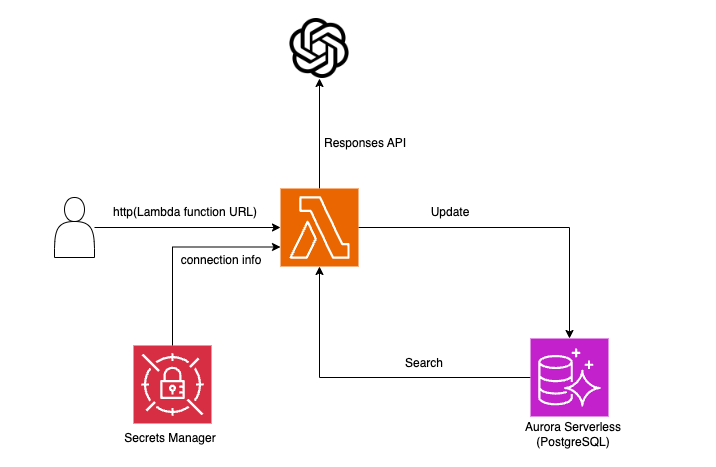
在 Lambda 函数上的 LangMem 会访问 OpenAI 的 Responses API,并将用户的偏好保存到 Aurora Serverless 的 PostgreSQL 中作为长期记忆。在后续的交互中,会利用这些保存的信息。
为了尽可能保持结构简洁,不使用连接池(RDS Proxy)或 API Gateway 等相关资源。
设置
#在负责 LangMem 持久化功能的 LangGraph 的 BaseStore 中,我们使用下面面向 PostgreSQL 的实现。
这个 PostgresStore 默认是不包含在内的。
需要另外安装 langgraph-checkpoint-postgres 与 LangMem 一起使用。
pip install langmem langgraph-checkpoint-postgres psycopg[binary]
在本次验证中,LangMem 的版本使用的是现阶段最新的 0.0.15。
Lambda函数
#我们马上开始实现 Lambda 函数。整个源码请见这里。
首先是 Lambda 的初始化部分。
用 Pydantic 的类定义保存为长期记忆数据的 schema。
class UserTechInterest(BaseModel):
"""用户的技术兴趣信息"""
topic: str = Field(..., description="技术主题(例如:编程语言、云服务等)")
category: str | None = Field(
None, description="技术领域(例如:前端、后端、网络等)"
)
interest_level: conint(ge=0, le=100) | None = Field(
None, description="兴趣程度(以0~100的分数表示)"
)
description: str | None = Field(
None, description="其他补充说明(例如:具体示例或详细知识)"
)
将用户的技术偏好进行 schema 化,并保存为长期记忆。
接下来创建 PostgreSQL 的连接 URL。
def create_conn_url():
secret_name = os.environ['SECRET_NAME']
session = boto3.session.Session()
sm_client = session.client(service_name='secretsmanager')
get_secret_value_response = sm_client.get_secret_value(SecretId=secret_name)
secret = json.loads(get_secret_value_response['SecretString'])
return f"postgresql://{secret["username"]}:{secret["password"]}@{secret["host"]}:{secret["port"]}/{secret["dbname"]}"
postgres_conn_url = create_conn_url()
按照惯例,数据库连接信息从 Secrets Manager 中获取并生成。
接着,初始化 LangMem 的 Store Manager 和将与用户交互的 OpenAI 客户端。
# LangMem的Store Manager
manager = create_memory_store_manager(
"openai:gpt-4o-2024-11-20",
namespace=("chat", "{user_id}"),
schemas=[UserTechInterest],
instructions="请详细提取用户的兴趣和技术背景",
enable_inserts=True,
enable_deletes=False,
)
# OpenAI客户端
client = OpenAI()
在 Store Manager 中设置了之前定义的 Pydantic schema (UserTechInterest),以强制长期记忆的 schema。
Store Manager 是 LangMem Storage API 的其中之一。
它利用 LLM 来抽取长期记忆以及更新现有信息,并通过 LangGraph 的持久化功能反映到实际存储中。
详情请参考上一篇文章。
接着,实现 Lambda 的事件处理器。
首先建立与 PostgreSQL 的连接。
def lambda_handler(event, context):
# 1. 创建 LangGraph 的 PostgreStore
with PostgresStore.from_conn_string(postgres_conn_url, index={
"dims": 1536,
"embed": "openai:text-embedding-3-small",
}) as store:
# 2. PostgreSQL 的 schema 迁移
store.setup()
首先为了建立与 PostgreSQL 的连接,使用 PostgresStore.from_conn_string 生成上下文管理器,这样连接的建立和结束操作会自动管理。
同时设置了数据的维度数(dims=1536)和所使用的嵌入模型(openai:text-embedding-3-small)。
连接建立后,通过 store.setup() 创建数据库内所需的表。
接着,使用 LangGraph 的 Functional API 定义工作流。
# 3. LangGraph Functional API 工作流
@entrypoint(store=store)
def app(params: dict):
message = params["message"]
user_id = params["user_id"]
# 从存储中搜索相关的长期记忆
memories = store.search(("chat", user_id))
developer_msg = ("You are a helpful assistant.\n"
f"## Memories\n <memories>\n{memories}\n</memories> ")
# 执行 OpenAI 的 Responses API
response = client.responses.create(
model="gpt-4o-2024-11-20",
input=[{"role": "developer", "content": developer_msg}, message],
tools=[{"type": "web_search_preview"}],
)
# 提取该用户的偏好并更新长期记忆
manager.invoke(
{"messages": [message]},
config={"configurable": {"user_id": user_id}}
)
return response.output_text
这里的流程如下:
- 从 PostgreSQL 中搜索用户的长期记忆;
- 将获取的信息反映到 OpenAI 的 Responses API 上下文中;
- 调用 OpenAI 的 API 生成合适的响应;
- 通过 LangMem 的 Store Manager 更新用户的偏好,形成长期记忆;
- 返回由 OpenAI API 生成的文本。
以下是剩余的源码。
body = json.loads(event["body"])
user_id = body["user_id"]
# 启动 LangGraph 工作流
output = app.invoke({
"message": {
"role": "user",
"content": body["prompt"]
},
"user_id": user_id
})
# 返回响应
return {
"statusCode": 200,
"headers": {"Content-Type": "plain/text"},
"body": output
}
从 HTTP 请求中获取用户 ID 和提示词,并启动之前定义的 LangGraph 工作流。
最后,将工作流生成的文本作为结果返回。
创建AWS资源
#在这里,我们创建 Aurora Serverless 和 Lambda 函数等 AWS 资源。
本次使用的 IaC 工具是 AWS CDK。
本文的主题是使用 PostgreSQL 实现 LangMem 长期记忆的持久化,因此省略了 AWS 资源详细构建步骤。
这里只摘录了关于 Aurora Serverless 和 Lambda 的部分进行介绍。
整个源码请见这里。
# Create Aurora Serverless v2 Cluster
dbname = "memory"
cluster = rds.DatabaseCluster(
self, "AuroraCluster",
engine=rds.DatabaseClusterEngine.aurora_postgres(
version=rds.AuroraPostgresEngineVersion.VER_16_6
),
writer=rds.ClusterInstance.serverless_v2("writer"),
readers=[
rds.ClusterInstance.serverless_v2(
"reader1", scale_with_writer=True),
],
vpc=vpc,
serverless_v2_min_capacity=0, # 零伸缩
serverless_v2_max_capacity=1,
vpc_subnets=ec2.SubnetSelection(
subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS
),
# Secrets Manager 的资源创建(RDS集成)
credentials=rds.Credentials.from_generated_secret(
username="langmem"),
security_groups=[aurora_sg],
default_database_name=dbname,
enable_data_api=True
)
这是一个简单支持零伸缩的 Aurora Serverless(v2) 集群。
利用 Secrets Manager 的 RDS 集成,在创建资源时同时生成连接信息条目。
Lambda 函数如下:
lambda_role = iam.Role(
self, "LambdaExecutionRole",
assumed_by=iam.ServicePrincipal("lambda.amazonaws.com"),
inline_policies={
"SecretsManagerAccessPolicy": iam.PolicyDocument(
statements=[
iam.PolicyStatement(
actions=["secretsmanager:GetSecretValue"],
resources=[cluster.secret.secret_arn]
)
]
)
},
managed_policies=[
iam.ManagedPolicy.from_aws_managed_policy_name(
"service-role/AWSLambdaBasicExecutionRole"),
# 用于VPC附加的Lambda
iam.ManagedPolicy.from_aws_managed_policy_name(
"service-role/AWSLambdaVPCAccessExecutionRole"),
]
)
lambda_function = _lambda.Function(
self, "LongTermMemHandler",
function_name="LongTermMemHandler",
runtime=_lambda.Runtime.PYTHON_3_12,
code=_lambda.Code.from_asset(
"path/to/deployment_package.zip"),
handler="lambda_function.lambda_handler",
security_groups=[lambda_sg],
vpc=vpc,
timeout=Duration.seconds(180),
memory_size=1024,
environment={
"SECRET_NAME": cluster.secret.secret_name,
"OPENAI_API_KEY": os.environ["OPENAI_API_KEY"],
},
role=lambda_role
)
lambda_url = lambda_function.add_function_url(
auth_type=_lambda.FunctionUrlAuthType.NONE
)
CfnOutput(self, "LongTermMemFunctionUrl", value=lambda_url.url)
Aurora 是 VPC 资源,因此用于访问它的 Lambda 也必须附加在 VPC 上。
另外,由于需要连接 OpenAI 的 API 和 PostgreSQL[1],所以超时时间设置较长。
默认内存大小会因内存不足而导致错误,因此进行了调整。
验证基于Aurora的长期记忆
#至此,验证环境已搭建完毕。
这里我们使用 curl,通过生成的 Lambda 函数 URL 测试向 Aurora Serverless 存储与应用长期记忆。
首先,发送以下请求来保存用户的兴趣信息。
LAMBDA_URL=$(aws lambda get-function-url-config --function-name LongTermMemHandler --query FunctionUrl --output text)
> https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.lambda-url.ap-northeast-1.on.aws/
curl -H 'Content-Type: application/json' "$LAMBDA_URL" -d @- <<'EOF'
{
"user_id": "MZ0001",
"prompt": "我对云服务整体感兴趣,特别希望逐步深入了解AWS和Azure的基础知识"
}
EOF
发送该请求后,AI 会生成适当的响应,并基于此将用户的兴趣保存为长期记忆。
虽然响应内容将省略,但内部实际上会将该信息存储在 Aurora Serverless 中。
接下来,再添加一条新的兴趣信息。
curl -H 'Content-Type: application/json' "$LAMBDA_URL" -d @- <<'EOF'
{
"user_id": "MZ0001",
"prompt": "作为一项引起我关注的新技术,我对利用AI代理进行的举措也产生了浓厚兴趣"
}
EOF
在此,我们使用 AWS 管理控制台的 RDS Query Editor 检查 Aurora Serverless 内的数据。
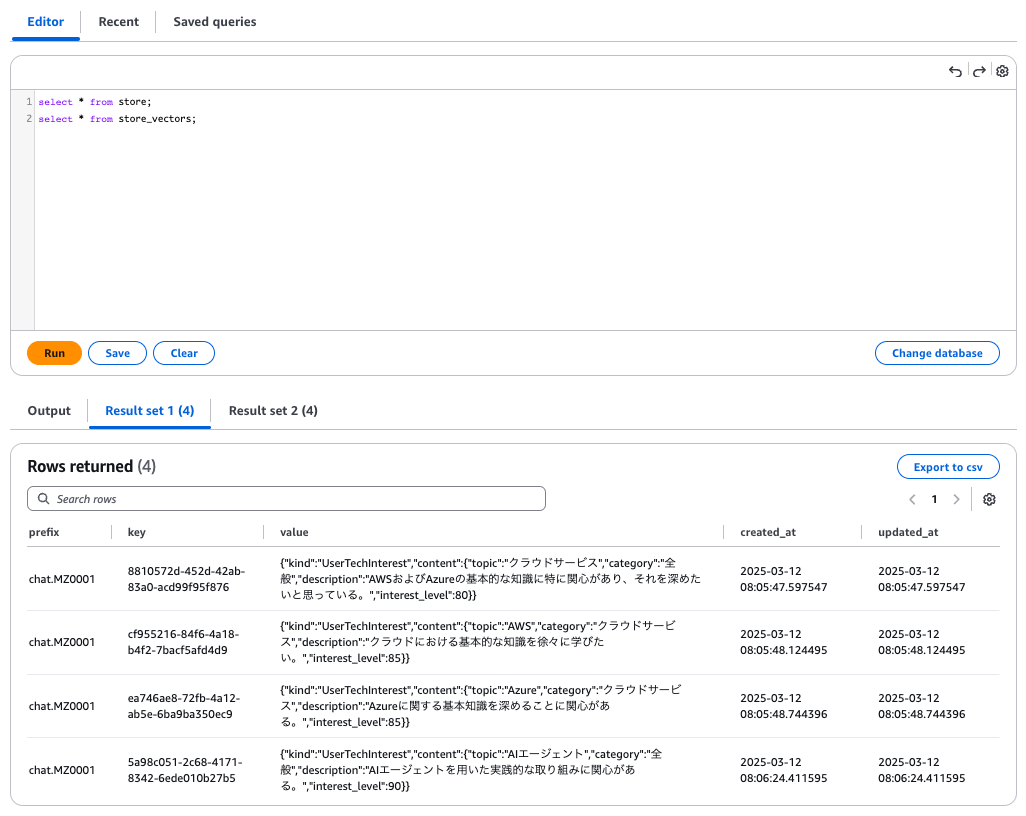
LangMem 的长期记忆以原始数据存储在 store 表中,并将向量化的信息存储在 store_vectors 表中。
store表
store_vectors表
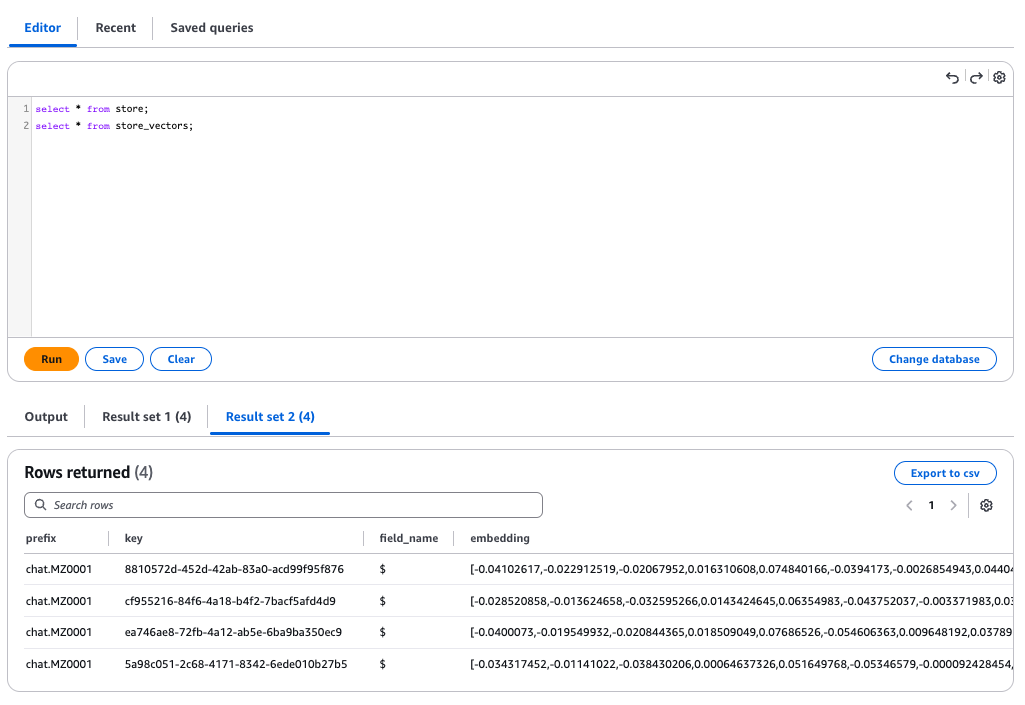
可以确认 PostgreSQL 中已正确存储用户的兴趣信息。
接下来,根据注册的信息,验证能否利用长期记忆生成响应。
我们不提供用户过去的发言,而询问一些通用的技术主题。
curl -H 'Content-Type: application/json' "$LAMBDA_URL" -d @- <<'EOF'
{
"user_id": "MZ0001",
"prompt": "请列举三个推荐的技术主题并简要总结!"
}
EOF
返回了如下响应:
推荐以下三个技术话题!这些话题是根据兴趣深度和相关性精选出来的。
1. **AI代理**
- 通过学习实践性的应用方法和开发手法,能够提升日常工作的效率并创新性地解决问题。尤其需要关注最新的AI工具和API的应用。
2. **Azure(云服务)**
- 掌握Microsoft Azure的基础知识,强化在云端进行应用开发和运维的技能。特别推荐与AI和数据分析结合紧密的服务。
3. **AWS(云服务)**
- 通过了解Amazon的云解决方案,可以学习到广泛的基础技术。建议重点关注无服务器架构和提升数据存储效率的实战经验。
这些话题在学习和实际工作中都有很大的帮助!
生成了既反映用户兴趣信息又能提出适当技术主题的响应。
对于没有长期记忆的新用户(user_id 改变),发送相同提示时,则会建议通用的技术主题。
### 1. **生成AI(Generative AI)**
- 正在迅速发展的 AI 技术,可生成文本、图像、音乐等。
- 特别是 ChatGPT 和 Stable Diffusion 之类的模型受到关注,在创意领域和效率提升方面得到应用。
- 技术进步对业务自动化到娱乐等领域都有广泛影响。
### 2. **量子计算**
- 下一代技术,可高速解决目前计算机难以处理的问题。
- 被期待在密码破解、分子模拟、金融优化等特定领域引发重大革命。
- 虽然需要专业知识,但从基础研究到应用实例正在不断增多。
### 3. **Web3及区块链**
- 旨在构建去中心化互联网的技术,核心为加密资产和智能合约。
- 在金融(DeFi)和数字资产(NFT)领域的应用持续推进,同时也在讨论监管及环境负荷问题。
- 正在形成全新的经济圈和所有权概念。
可以确认,拥有长期记忆的用户与没有长期记忆的用户生成了不同的响应。
总结
#此次,我们并非使用内存存储,而采用在实际运营中推荐的 PostgreSQL (pgvector) 来验证 LangMem 的长期记忆。
Aurora Serverless 的设置虽然稍显繁琐,但让我们切实体会到了在实际环境中运行长期记忆的效果。
如果能利用这一机制,可以积累每个用户的知识和偏好,从而构建更加个性化的 AI 系统。
期待借此尝试各种创意。
在零伸缩情况下,PostgreSQL 的连接可能需要超过10秒。 ↩︎