使用 CloudWatch Application Signals 监控 Lambda 的 SLO
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
上个月,CloudWatch Application Signals 已支持 AWS Lambda。
CloudWatch Application Signals 于2023年作为预览版推出,并在今年正式发布,是一项全新的 APM(应用性能监控)功能。
此前只支持 EKS、ECS、EC2,但终于也支持 Lambda 了。
Application Signals 利用 OpenTelemetry 收集的指标,可直观地展示为仪表板和服务地图。
此外,它基于 SLO(服务水平目标)来衡量和管理系统目标达成度,从而支持从业务角度出发的合理运维改进。
本次我们将以 AWS 标准的 APM 工具为例,针对 Lambda 函数进行测试。
启用 Application Signals
#为了让 Application Signals 能够进行服务发现和 SLO 计算,首次使用时需要对日志和指标授予访问权限。
这里我们通过管理控制台启用了该功能。

Step 2 在各服务中分别启用,因此无需额外操作。
实现被监控的 Lambda 函数
#首先创建被监控的 Lambda 函数。
这里我们创建了如下 Lambda 事件处理器。
import type { APIGatewayProxyHandler } from 'aws-lambda';
import { PutObjectCommand, S3Client } from '@aws-sdk/client-s3';
const s3client = new S3Client();
const handler: APIGatewayProxyHandler = async () => {
await s3client.send(new PutObjectCommand({
Bucket: process.env.BUCKET_NAME ?? '',
Key: Date.now().toString() + '.txt',
Body: 'lambda-app-signal-test'
}))
const rand = Math.random();
// 以 5% 的概率失败
const success = rand > 0.05;
if (!success) {
throw new Error('oops!');
}
return {
statusCode: 200,
body: JSON.stringify({
message: 'ok!',
}),
};
}
// 当前在使用 ADOT 的 TypeScript 中存在无法使用 export 语句的限制
// https://github.com/aws-observability/aws-otel-lambda/issues/99#issuecomment-919993949
module.exports = { handler }
在向 S3 桶执行 PUT 后,会以 5% 的概率触发错误。
启用 Application Signals 并部署 Lambda 函数
#部署创建的 Lambda 函数。
这里我们使用 AWS CDK。
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import * as s3 from 'aws-cdk-lib/aws-s3';
import * as iam from 'aws-cdk-lib/aws-iam';
import * as nodejs from 'aws-cdk-lib/aws-lambda-nodejs';
import * as lambda from 'aws-cdk-lib/aws-lambda';
export class LambdaAppSignalStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const bucket = new s3.Bucket(this, 'SampleBucket');
const role = new iam.Role(this, 'LambdaRole', {
assumedBy: new iam.ServicePrincipal('lambda.amazonaws.com'),
managedPolicies: [
iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole'),
// 1. Application Signals 的 AWS 托管策略
iam.ManagedPolicy.fromAwsManagedPolicyName('CloudWatchLambdaApplicationSignalsExecutionRolePolicy')
],
inlinePolicies: {
s3policy: new iam.PolicyDocument({
statements: [
new iam.PolicyStatement({
actions: ['s3:PutObject'],
resources: [bucket.bucketArn + '/*']
})
]
})
}
});
// 从以下获取 ADOT Lambda Layer 的 ARN
// https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-Application-Signals-Enable-Lambda.html#Enable-Lambda-Layers
const awsOtelDistro = lambda.LayerVersion.fromLayerVersionArn(this, 'AWSOtelExtension',
'arn:aws:lambda:ap-northeast-1:615299751070:layer:AWSOpenTelemetryDistroJs:5');
const func = new nodejs.NodejsFunction(this, 'SampleFunction', {
role,
functionName: 'flaky-api-for-app-signals',
entry: './lambda/index.ts',
handler: 'handler',
// 启用 X-Ray 主动跟踪(可选)
tracing: lambda.Tracing.ACTIVE,
// 2. ADOT 层
layers: [awsOtelDistro],
runtime: lambda.Runtime.NODEJS_22_X,
timeout: cdk.Duration.seconds(10),
environment: {
BUCKET_NAME: bucket.bucketName,
// 3. 启用 Application Signals
AWS_LAMBDA_EXEC_WRAPPER: '/opt/otel-instrument'
}
});
const url = new lambda.FunctionUrl(this, 'SampleFunctionUrl', {
function: func,
authType: lambda.FunctionUrlAuthType.NONE
});
new cdk.CfnOutput(this, 'SampleFunctionUrlOutput', {
value: url.url
});
new cdk.CfnOutput(this, 'BucketNameOutput', {
value: bucket.bucketName
});
}
}
在 Lambda 中使用 Application Signals 的关键点如下:
- 在 Lambda 执行角色中指定以下 AWS 托管策略
- CloudWatchLambdaApplicationSignalsExecutionRolePolicy
- 将 AWS 提供的 ADOT(AWS Distro for OpenTelemetry)添加为 Lambda 层
- 在环境变量 AWS_LAMBDA_EXEC_WRAPPER 中指定
/opt/otel-instrument
AWS 的 ADOT Lambda 层使用的是官方文档中记载的版本。
这不是必须的,但官方文档还建议同时启用 X-Ray 的主动跟踪。
部署它。
cdk deploy
部署后可以在管理控制台中检查 Lambda 的状态。
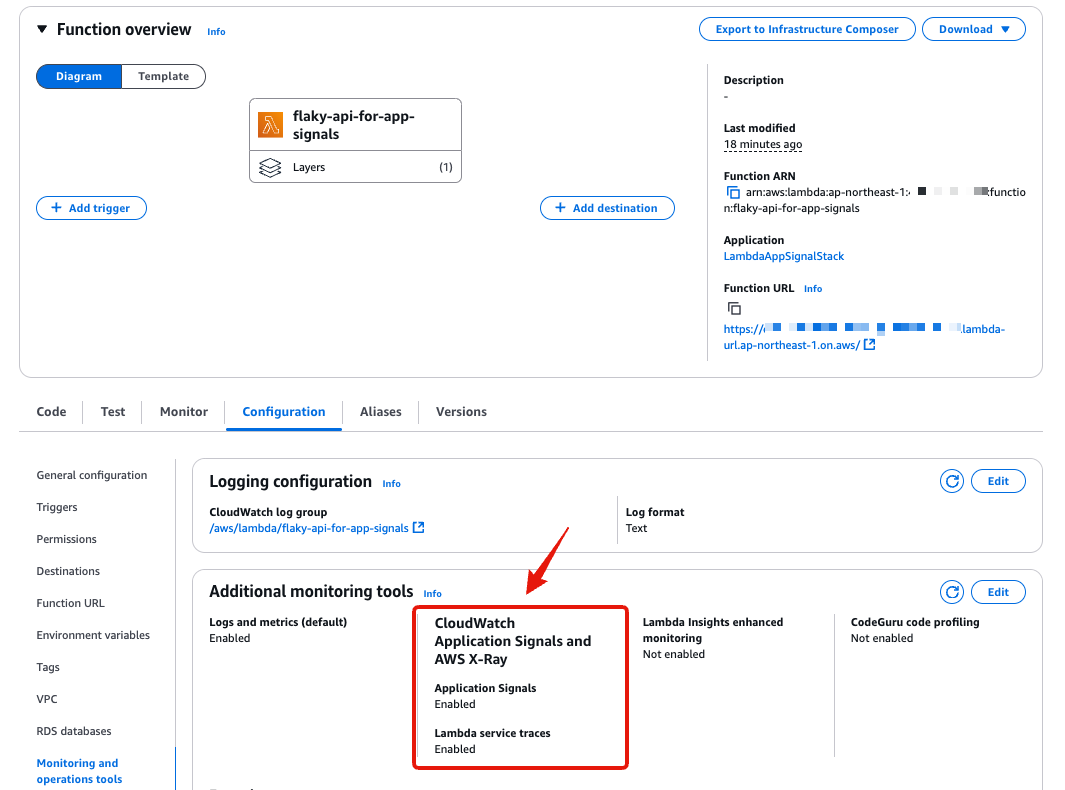
Application Signals 与 X-Ray 的跟踪均已启用。
由于启用了 Lambda Function URL,因此可以使用 curl 等工具访问。
curl https://xxxxxxxxxxxxxxxxxx.lambda-url.ap-northeast-1.on.aws/
# {"message":"ok!"}
查看 Application Signals 的服务和服务地图
#当目标服务产生流量时,Application Signals 会自动检测到服务的新增,并在 Application Signals 中显示(自动检测)。
这一过程需要一定时间(约 5 分钟)。
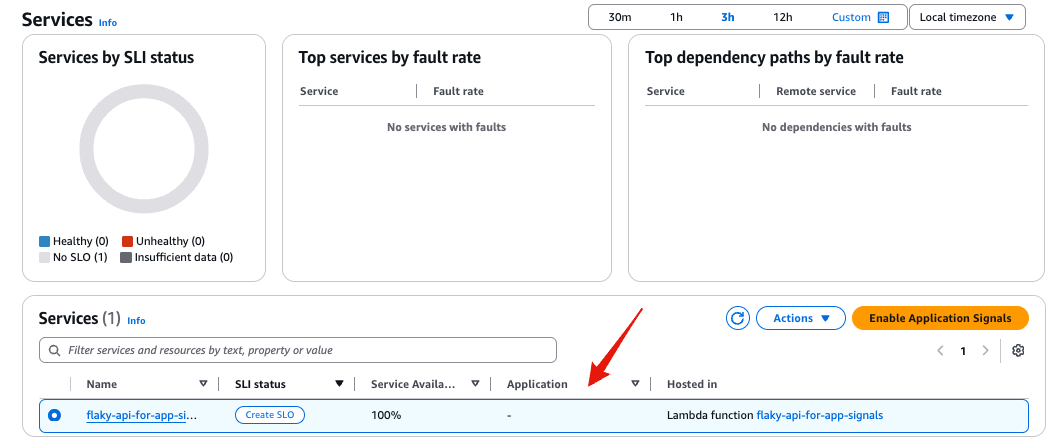
点击服务名称可以查看服务详情。
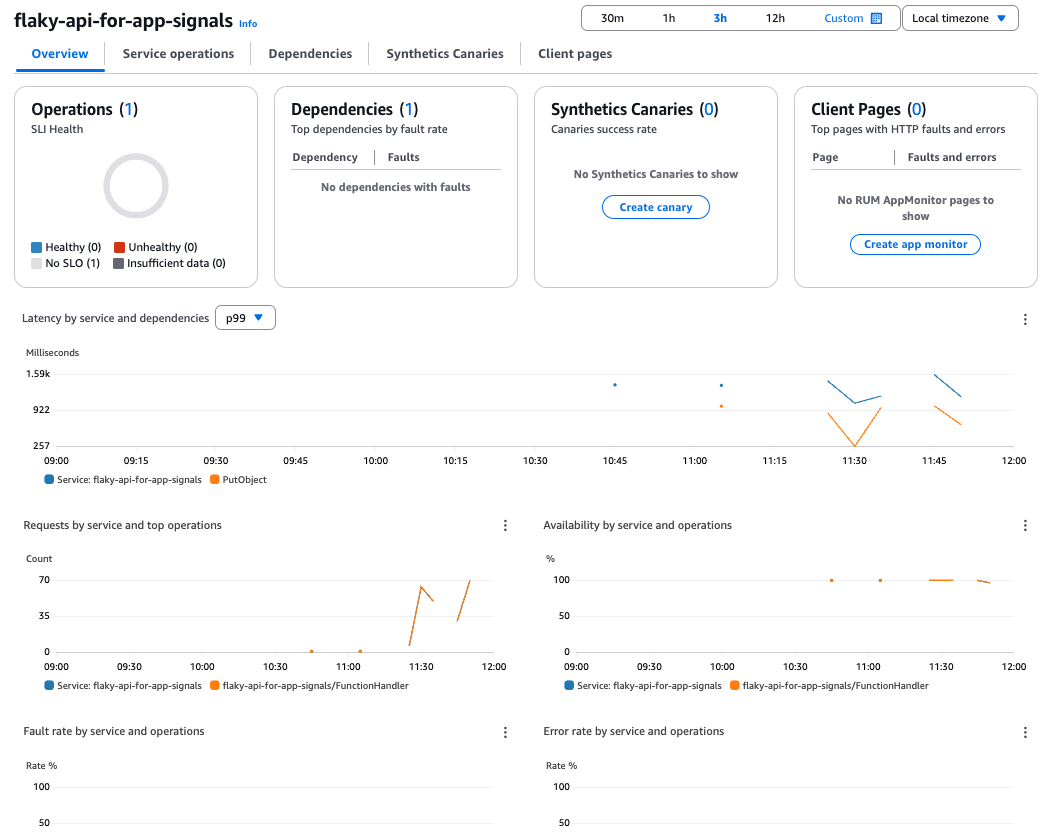
概览
服务操作
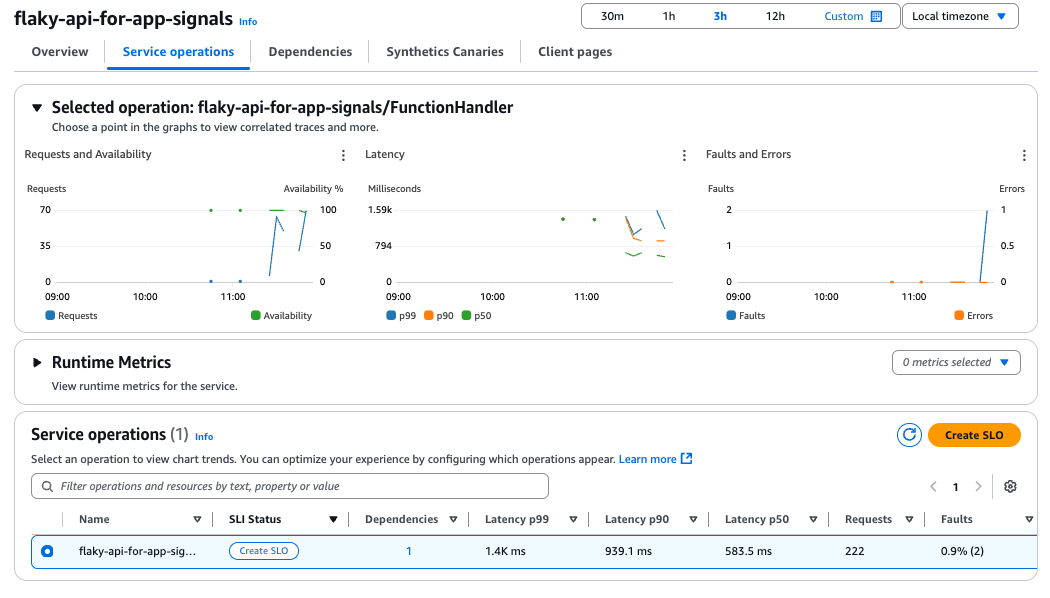
依赖关系
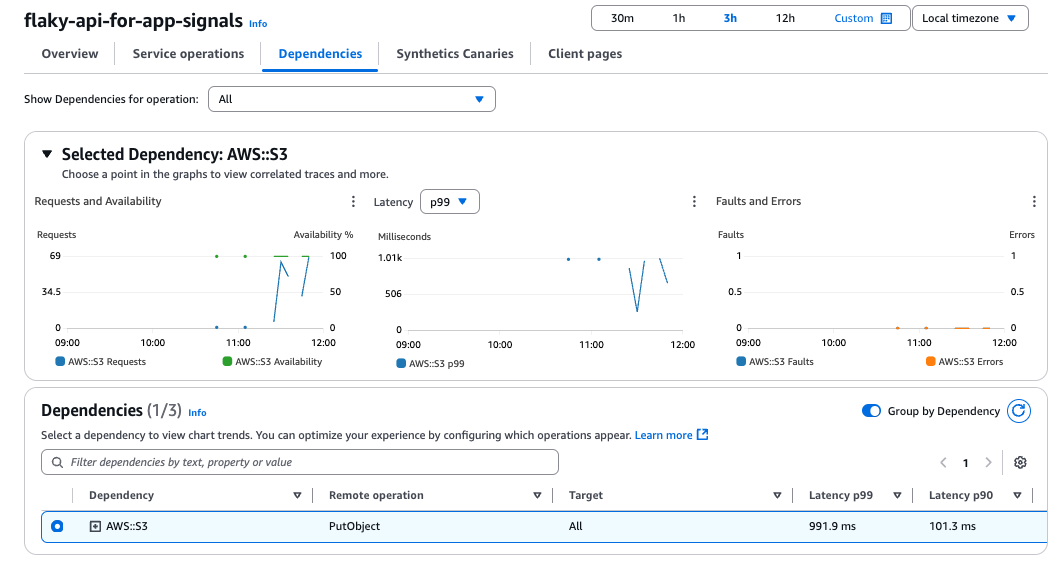
由于本次未使用 Synthetics Canaries 和 Client Pages,因此不会显示任何内容。
虽然样本数量较少、展示效果一般,但 Lambda 的指标和依赖关系(S3)已被可视化。
根据需要结合 X-Ray 分析,还能更容易地发现瓶颈。
接下来查看 Application Signals 的服务地图。
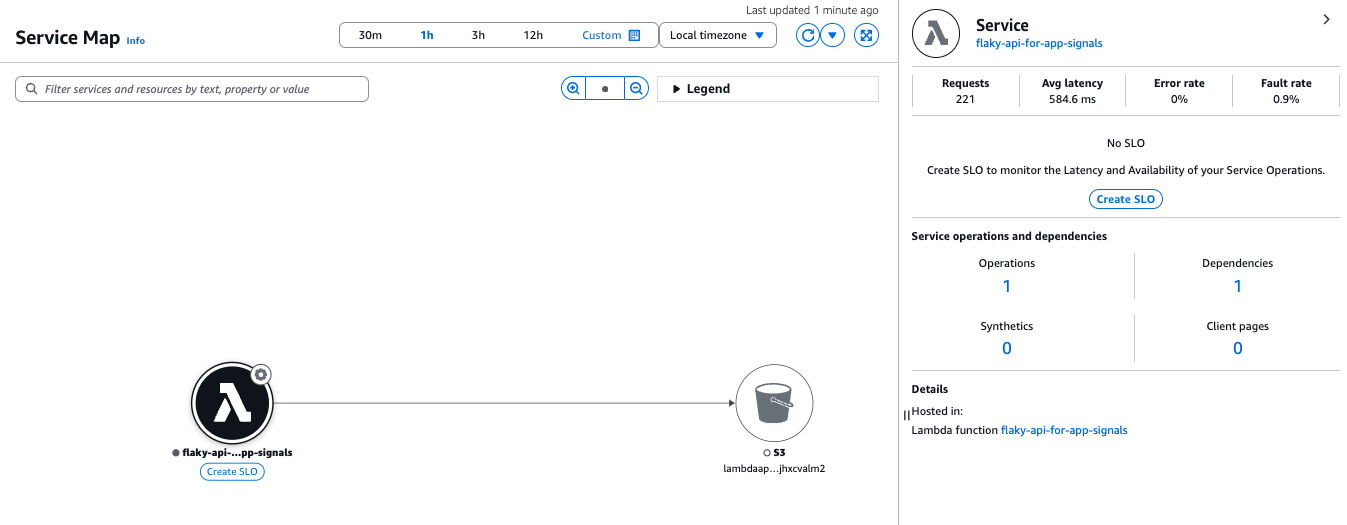
此次创建的 Lambda -> S3 桶关系已被可视化(类似于 X-Ray 的跟踪地图)。
点击各个节点或边缘,可以查看相应部分的指标。
定义 SLO
#在体验了 Application Signals 的自动检测和仪表板后,我们进一步定义 SLO,以业务视角进行监控。
虽然内容稍长,但可以参见以下文档:
这里同样使用 AWS CDK 来创建 SLO。
由于目前 Application Signals 只有 L1 构件,因此与直接使用 CloudFormation 描述类似。
if (this.node.tryGetContext('createSLO') === 'true') {
const availabilitySLO = new applicationsignals.CfnServiceLevelObjective(this, 'AvailabilityServiceLevelObjective', {
name: `${func.functionName}-availability`,
requestBasedSli: {
requestBasedSliMetric: {
metricType: 'AVAILABILITY',
keyAttributes: {
'Type': 'Service',
'Name': func.functionName,
'Environment': 'lambda:default'
},
operationName: `${func.functionName}/FunctionHandler`
}
},
goal: {
attainmentGoal: 95,
warningThreshold: 30,
interval: {
rollingInterval: {
duration: 1,
durationUnit: 'DAY' // DAY | MONTH
}
}
},
// 燃尽率(5 分钟、60 分钟的时间窗口)
burnRateConfigurations: [
{ lookBackWindowMinutes: 5 },
{ lookBackWindowMinutes: 60 }
]
});
}
这里的 SLO 定义如下:
SLI(服务级指标)
即用作 SLO 指标的度量数据。
默认可选的指标有可用性(AVAILABILITY)和延迟(LATENCY)。本次选择了 AVAILABILITY。
此外,还可以指定目标服务的任意 CloudWatch 指标。
另外,在指标计算方法上,可以选择按固定时间段评估或按请求数计算这两种方式。
本次采用了计算相对简单的基于请求的方式。
SLO 目标(goal)
之前创建的 Lambda 函数设置为有 5% 的失败概率。
因此 SLO 的目标值(attainmentGoal)设为 95%,有意制造出目标达成勉强及格的状态。
监控期间采用 1 天的滚动时间窗口(rollingInterval),即始终以当前时间为基准滑动查看最近的指标。
滚动时间窗口的优点在于能迅速检测到短期异常。
另一方面,如果使用日历时间窗口(calendarInterval),则可以在固定期间内进行监控。
日历时间窗口有助于从业务角度进行可视化以及便于向相关方解释,因此可根据实际情况灵活选用。
燃尽率配置(burnRateConfigurations)
这部分可能稍显复杂,但燃尽率(Burn Rate)[1]是一个指标,用于表示在指定期间内错误预算(允许的错误)被消耗的速度(详见下文专栏)。
燃尽率的概念由 Google 的 Site Reliability Workbook 提出,并指出结合长期与短期的回顾窗口(Look-back window)能够实现高可靠性的报警。
依照这一原理,这里设置了 5 分钟与 60 分钟的回顾窗口。
计算公式很简单,即定义为期间内实际错误率(%)除以错误预算(%)的值。
错误预算是指 1 减去 SLO 目标值(例如若为 99% 则为 1%),顾名思义,它表示在 SLO 期间允许的错误额度。
燃尽率的数值可按以下方式解读:
- 当值为 1:表示正好以使错误预算刚好耗尽的速度
- 当值大于 1:表示错误预算耗尽过快,可能在 SLO 期间结束前已用尽,需要立即采取措施
- 当值小于 1:表示错误预算尚在允许范围内,虽理想,但也可能被认为未充分承担风险
例如,考虑上述可用性 SLO 的燃尽率。如果在回顾窗口内有 1000 次请求,其中 200 次失败,则计算如下:
- 错误预算:100% - 95% = 5%
- 实际错误率:200 / 1000 * 100 = 20%
- 燃尽率:20% / 5% = 4
这表示错误预算的消耗速度是预期的 4 倍。
若此情况持续,错误预算将在 SLO 监控期间(1 天)的 1/4(即 6 小时)内耗尽,因此需要立即采取措施。
现在部署 SLO,这次通过将参数 createSLO 设置为 true 来执行。
cdk deploy --context createSLO=true
SLO 必须在 Application Signals 检测到服务之后才能创建。
也就是说,如果与 Lambda 同时创建 SLO,则可能因找不到目标服务而导致部署错误。
为避免此问题,需要像这里这样通过标志(createSLO)切换,或将堆栈拆分,从而调整执行时机。
在管理控制台中查看 Application Signals 的 SLO。
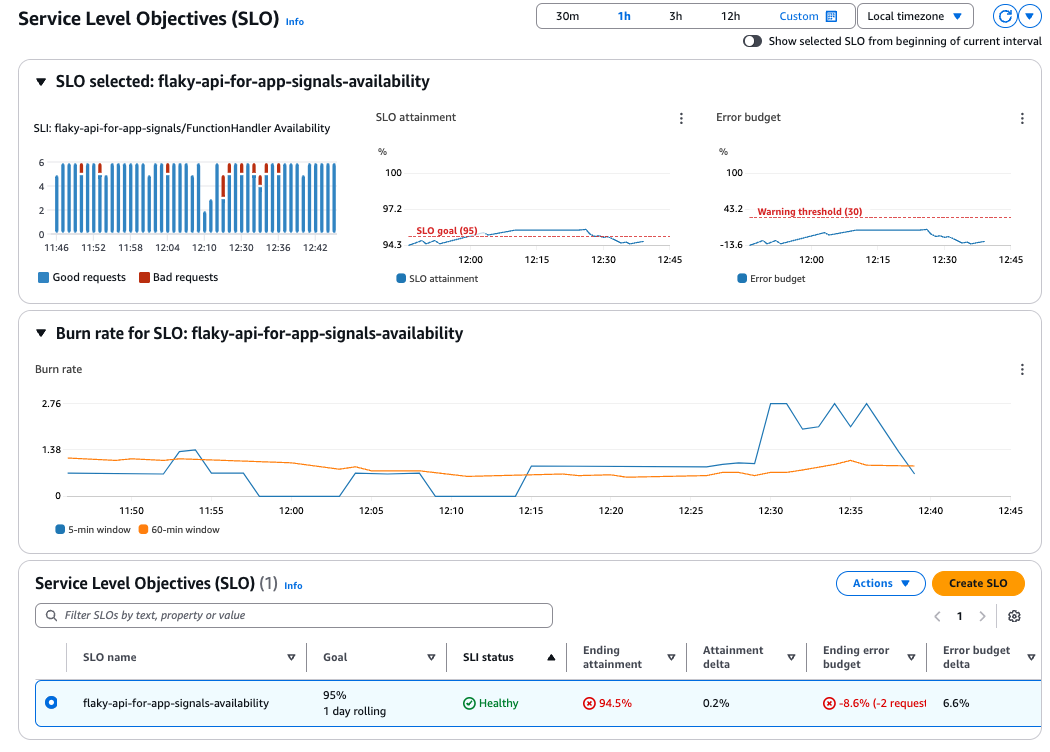
仅定义 SLO 即能自动生成效果不错的仪表板。
此次显示的可用性为 94.5%,未达到设定的 95% SLO(超出 2 次请求的错误预算)。
此外,从中间的燃尽率图可以看出,短期回顾窗口(5 分钟)对请求失败反应较为敏感,而长期回顾窗口(60 分钟)则较为平稳。
基于 SLO 创建 CloudWatch 报警
#虽然定义了 SLO并能可视化当前状态,但若没有通知机制,便毫无意义。
Application Signals 本身只负责将与 SLO 相关的指标发送到 CloudWatch,而监控与报警则需依靠 CloudWatch 报警来完成。
此次我们将创建以下三种报警:
- 错误预算剩余 30%
- 错误预算耗尽(=SLO 未达成)
- 短期及长期燃尽率
1. 错误预算剩余 30%
#const warningAlarm = new cloudwatch.Alarm(this, 'AvailabilityWarningAlarm', {
alarmName: `SLO-WarningAlarm-${availabilitySLO.name}`,
alarmDescription: 'SLO 警告(剩余 30%)的阈值超限报警',
actionsEnabled: true,
evaluationPeriods: 1,
datapointsToAlarm: 1,
threshold: 100 - (5 * (1 - 0.3)), // 96.5%
comparisonOperator: cloudwatch.ComparisonOperator.LESS_THAN_OR_EQUAL_TO_THRESHOLD,
metric: new cloudwatch.Metric({
metricName: 'AttainmentRate',
namespace: 'AWS/ApplicationSignals',
statistic: cloudwatch.Stats.AVERAGE,
dimensionsMap: {
SloName: availabilitySLO.name
},
unit: cloudwatch.Unit.PERCENT,
period: cdk.Duration.minutes(1)
})
});
warningAlarm.addAlarmAction(new actions.SnsAction(/* alarm action */));
Application Signals 会将相关数据发送到 AWS/ApplicationSignals 命名空间。
其中,指标 AttainmentRate 反映当前的 SLO 达成率。
这里设置为当 5% 错误预算中消耗了 70%(即 3.5%)时,也就是达成率低于 96.5%,则触发报警。
2. 错误预算耗尽(=SLO 未达成)
#const attainmentAlarm = new cloudwatch.Alarm(this, 'AvailabilityAttainmentGoalAlarm', {
alarmName: `SLO-AttainmentGoalAlarm-${availabilitySLO.name}`,
alarmDescription: 'SLO 目标阈值超限报警',
actionsEnabled: true,
evaluationPeriods: 1,
datapointsToAlarm: 1,
threshold: 95, // 与 SLO 的 goal.attainmentGoal 相同
comparisonOperator: cloudwatch.ComparisonOperator.LESS_THAN_OR_EQUAL_TO_THRESHOLD,
metric: new cloudwatch.Metric({
metricName: 'AttainmentRate',
namespace: 'AWS/ApplicationSignals',
statistic: cloudwatch.Stats.AVERAGE,
dimensionsMap: {
SloName: availabilitySLO.name
},
unit: cloudwatch.Unit.PERCENT,
period: cdk.Duration.minutes(1)
})
});
attainmentAlarm.addAlarmAction(new actions.SnsAction(/* alarm action */));
这里使用的指标与前一报警相同,但阈值设置为与 SLO 目标(95%)一致。
3. 短期及长期燃尽率
#单独针对单个回顾窗口的燃尽率报警也可以,但这里通过组合短期和长期燃尽率以提高报警的准确性与可靠性。
- 短期燃尽率(5 分钟):能迅速检测并确认错误当前是否发生。一旦错误停止,指标立即低于阈值,从而迅速解除报警。
- 长期燃尽率(1 小时):用于确认持续性错误趋势,可过滤掉短期燃尽率中误判的错误尖峰。
将这两种燃尽率通过 AND 条件组合后,仅在短期问题持续发生时触发报警,从而既抑制误报警,又能检测出真正的异常。
为了实现这一点,我们使用 Composite Alarm 将多个报警组合在一起。
const burnRateAlarm_5min = new cloudwatch.Alarm(this, 'AvailabilityBurnRateAlarm_5min', {
alarmName: `SLO-BurnRate-${availabilitySLO.name}-5`,
alarmDescription: '燃尽率(5 分钟)阈值超限报警',
actionsEnabled: true,
evaluationPeriods: 1,
datapointsToAlarm: 1,
// https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-ServiceLevelObjectives.html#CloudWatch-ServiceLevelObjectives-burn
threshold: 0.1 * (24 * 60) / 60, // 2.4:与长期回顾窗口(60 分钟)保持一致
comparisonOperator: cloudwatch.ComparisonOperator.GREATER_THAN_THRESHOLD,
metric: new cloudwatch.Metric({
metricName: 'BurnRate',
namespace: 'AWS/ApplicationSignals',
statistic: cloudwatch.Stats.MAXIMUM,
dimensionsMap: {
SloName: availabilitySLO.name,
BurnRateWindowMinutes: '5'
},
period: cdk.Duration.minutes(1)
})
});
const burnRateAlarm_60min = new cloudwatch.Alarm(this, 'AvailabilityBurnRateAlarm_60min', {
alarmName: `SLO-BurnRate-${availabilitySLO.name}-60`,
alarmDescription: '燃尽率(60 分钟)阈值超限报警',
actionsEnabled: true,
evaluationPeriods: 1,
datapointsToAlarm: 1,
threshold: 0.1 * (24 * 60) / 60, // 2.4:期间内消耗错误预算的 10%
comparisonOperator: cloudwatch.ComparisonOperator.GREATER_THAN_THRESHOLD,
metric: new cloudwatch.Metric({
metricName: 'BurnRate',
namespace: 'AWS/ApplicationSignals',
statistic: cloudwatch.Stats.MAXIMUM,
dimensionsMap: {
SloName: availabilitySLO.name,
BurnRateWindowMinutes: '60'
},
period: cdk.Duration.minutes(1)
})
});
const compositeAlarm = new cloudwatch.CompositeAlarm(this, 'AvailabilityBurnRateAlarm_Composite', {
compositeAlarmName: `SLO-BurnRate-${availabilitySLO.name}-CompositeAlarm`,
actionsEnabled: true,
alarmDescription: '短期和长期综合燃尽率报警',
alarmRule: cloudwatch.AlarmRule.allOf(burnRateAlarm_5min, burnRateAlarm_60min)
})
compositeAlarm.addAlarmAction(new actions.SnsAction(/* alarm action */));
之前我们监控了 SLO 达成率,但燃尽率作为 BurnRate 指标[2]被发送,因此将其作为监控目标。
这里报警阈值是按以下公式计算的:
此处设置为当在最近 60 分钟内消耗错误预算的 10%时触发报警,即 0.1*(24*60)/60,因此阈值为 2.4[3]。
总结
#本次我们试用了针对 Lambda 使用 Application Signals 进行监控。
多亏了 ADOT 提供的自动仪表功能,无需修改应用端源代码,而且标准化的仪表板将自动生成,无需依赖高手技能!
未来 Lambda 的监控很可能会逐步向基于 SLO 的、使用 Application Signals 的方法转变,加速这一趋势。
不过,监控中最难的部分在于“指标选择”和“报警定义”。
这始终是个令人头疼的问题,但首先制定一定的规则,并在短周期内定期回顾实际情况似乎是最佳方案。
在不断的运维过程中,通过不断的调整,我们将构建出更加精准的监控体系。
可从包含 SLO 名称和回顾窗口(BurnRateWindowMinutes)的维度中确认。 ↩︎
根据 Google SRE Workbook 中“6: Multiwindow, Multi-Burn-Rate Alerts”的建议,两个报警的阈值保持一致。 ↩︎