AWSで自分だけのLLM環境を!EC2 GPUインスタンスとOllamaでAIを動かす実践ガイド
Back to Topはじめに
#「クラウドで手軽にGPUを借りて、最新のLLM(大規模言語モデル)を動かしてみたい!」
そんな思いつきから、AWSのEC2 GPUインスタンス+Ollamaを使って、オープンソースのLLM実行環境を構築する検証を行いました。本記事では、その際の手順や得られた知見を、備忘録も兼ねてご紹介します。
✔️ STEP 1: EC2インスタンスタイプの選定
#まずは、LLMを快適に動かすための「心臓部」となるEC2インスタンスを選びます。
Ollamaを使えばCPUだけでもLLMを実行することが可能ですが、十分なVRAM(ビデオメモリ)を持つGPUがあれば高速化の恩恵を得られます。
今回は最近OpenAIが公開してOllamaからも利用可能になっている gpt-oss を動かそうと思いますので、
20Bパラメタモデルの容量14GB以上のVRAMをもつEC2を選びます。
AWSマネコンから開けるEC2のインスタンスタイプ一覧画面が、リージョン別に利用可能なインスタンスタイプの性能や値段を一覧で比較しやすかったです。
フィルターに「GPU >= 1」と設定すればGPU搭載タイプが一覧されます。
表示例
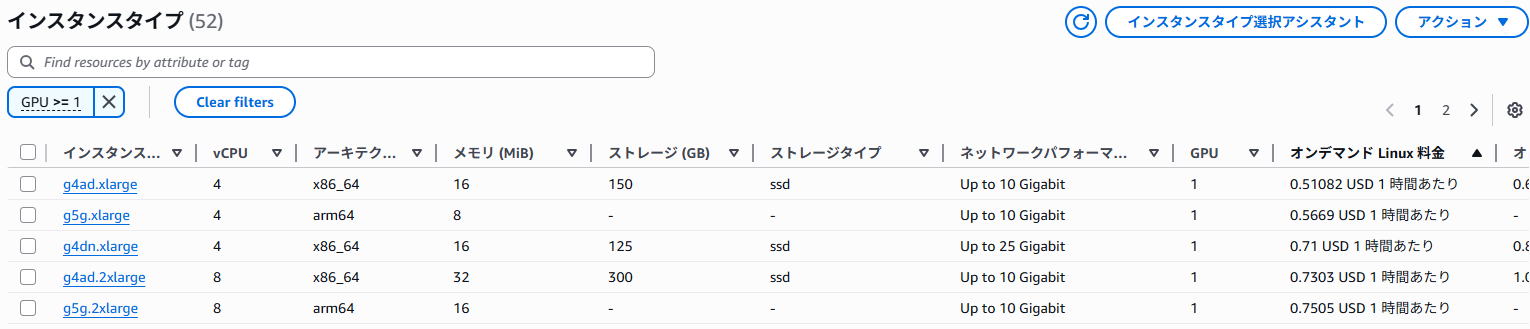
今回は、NVIDIA製GPU搭載でWindows対応しているタイプで一番価格が安いg4dn.xlargeがVRAMも十分あるので検証に使用したいと思います。
✔️ STEP 2: EC2インスタンスのセットアップ
#インスタンスタイプが決まったら、実際にEC2を起動していきます。
⚠️ 事前準備:サービス上限(クオータ)の引き上げ
#初めてGPUインスタンスを利用する場合、そのAWSアカウントで起動できる合計vCPU数の上限が0に設定されていることがあります。
そのままだとインスタンスを起動できないため、「Service Quotas」のページから、「Running On-Demand G and VT instances」のクオータ引き上げを申請しておきましょう。
私の場合申請から次の日には承認されました。
上限に達している場合、EC2インスタンス起動時に以下のようなエラーメッセージが表示され起動失敗します。
You have requested more vCPU capacity than your current vCPU limit of 0 allows for the instance bucket that the specified instance type belongs to. Please visit http://aws.amazon.com/contact-us/ec2-request to request an adjustment to this limit.
インスタンス作成
#以下の設定でEC2インスタンスを起動します。
- 名前:
gpu-demoなど、分かりやすい名前をつけます。 - AMI: Microsoft Windows Server 2025 Base を選択しました。
- 今回は検証のしやすさからWindowsを選択しましたが、もちろんLinuxでも構築可能です。
- インスタンスタイプ: g4dn.xlarge を選択。
- キーペア: ログイン用のキーペアを適宜指定します。
- セキュリティグループ:
- 適当な接続元からRDP(ポート3389)接続を許可するインバウンドルールを追加します。
- ストレージ: モデルのダウンロードも考慮し、60GBに設定します。
設定が完了したら、インスタンスを起動します。起動後、EC2のコンソールからキーペアを使ってWindowsの管理者パスワードを複合化し、リモートデスクトップで接続します。
OSの言語設定がデフォルトだと英語なので、日本語パックをインストールしておきます。
✔️ STEP 3: GPUドライバーのインストールと最適化
#Windows Serverに接続した直後の状態では、まだGPUはOSに認識されていません。NVIDIAの公式ドライバーをインストールして、GPUの性能を最大限に引き出せるように設定します。
ドライバーのインストール
#AWSのドキュメントの手順をもとにインストールを進めます。
ドライバの種類はいくつかりますが、今回は数値計算タスクに最適化されたTeslaドライバをインストールします。
- EC2インスタンス内のインターネットブラウザで、NVIDIAドライバーのダウンロードページにアクセスします。
g4dnインスタンスに搭載されているGPUは Tesla T4 なので、以下の通り検索します。- Product Category: Data Center / Tesla
- Product Series: T-Series
- Product: Tesla T4
- Operating System: Windows Server 2025
検索画面
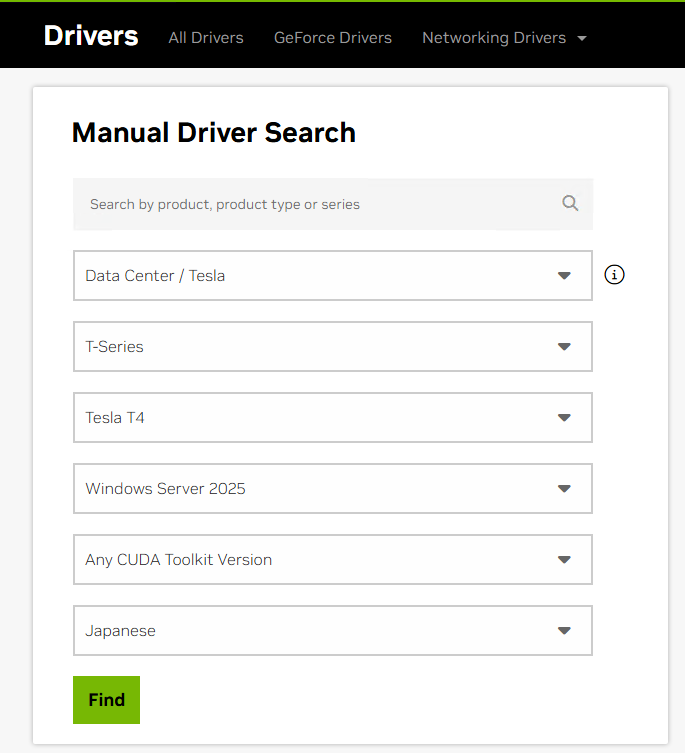
- 検索結果から最新のドライバーをダウンロードします。
- ダウンロードしたインストーラー(例:
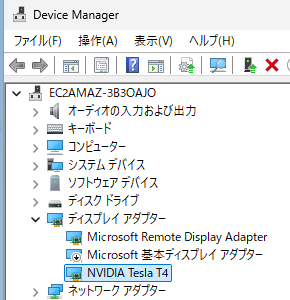
580.88-data-center-tesla-desktop-winserver-2022-2025-dch-international.exe)を実行し、「高速(推奨)」オプションでインストールを進めます。 - インストール後、デバイスマネージャーの「ディスプレイ アダプター」に「NVIDIA Tesla T4」が表示されていることを確認します。
- 元からあった「Microsoft 基本ディスプレイ アダプター」を無効化します。
- インスタンスを再起動します。
参考:デバイスマネージャ画面
動作確認と最適化
#PowerShellを開き、nvidia-smiコマンドを実行してGPUが正しく認識されているか確認します。
PS C:\> nvidia-smi
Mon Aug 18 18:12:55 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.88 Driver Version: 580.88 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 TCC | 00000000:00:1E.0 Off | 0 |
| N/A 27C P8 11W / 70W | 9MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
Tesla T4が表示され、メモリが15360MiB(約15GB)と認識されていれば成功です!
さらに、AWSのドキュメントに従い、GPUのクロック速度を最適化しておきます。
アプリケーション動作時の最大周波数をTesla T4のメモリ最大クロック数5001MHz, GPU最大クロック数1590MHzに設定します。
参考:Tesla T4仕様書(PDF)
PS C:\> nvidia-smi -ac "5001,1590"
Applications clocks set to "(MEM 5001, SM 1590)" for GPU 00000000:00:1E.0
All done.
WindowsだとGPU使用率などをタスクマネージャのパフォーマンス画面から確認できたらいいなと思うかもしれません。
しかし、TeslaドライバーはTCCモード(Tesla Compute Cluster)という数値計算タスク用に最適化されたモードで動作しており、タスクマネージャでは対応していないためモニター表示されません。
タスクマネージャはグラフィック描画用のWDDMモードで動作するGPUのモニター表示に対応しています。
✔️ STEP 4: Ollamaのセットアップとモデル実行
#いよいよLLMを動かすためのアプリケーション「Ollama」をセットアップします。
- Ollamaの公式サイトからWindows用インストーラーをダウンロードし、インストールします。
- OllamaのGUI画面が開かれますが、細かいオプションを指定して起動し直したいのでウィンドウを閉じて、タスクトレイからOllamaのアイコンをクリックして「Quit Ollama」をクリックして終了します。
Ollamaの起動設定
#Ollamaを外部マシンからREST API経由で利用したり、モデルを常にメモリにロードさせておくために、環境変数を設定して起動します。
OLLAMA_HOST="0.0.0.0:11434": Ollamaサーバーに外部から接続するためのアドレスをバインドします。OLLAMA_KEEP_ALIVE=-1: 一度読み込んだモデルをメモリ上に保持し続け、次回以降の応答を高速化します。(5mのように保持時間を指定することも可能です。デフォルトでは5分。)
以下のコマンドをPowerShellで実行します。
$Env:OLLAMA_HOST="0.0.0.0:11434"
$Env:OLLAMA_KEEP_ALIVE=-1
ollama serve
これでOllamaサーバーが起動します。リクエストを待ち受け、ログ出力する状態になります。
モデルの実行と確認
#gpt-ossモデルをダウンロードします。Powershell を別に起動し以下を実行します。
ollama pull gpt-oss
LLMにチャットリクエストを出してみます。
PS C:\> ollama run gpt-oss "こんにちは"
Thinking...
The user says "こんにちは" which is "Hello" in Japanese. We respond appropriately. Probably respond in Japanese: "こ
んにちは! 今日はどんなご用件でしょうか?" or something friendly. Use Japanese.
...done thinking.
こんにちは!
何かお手伝いできることがありますか?お気軽にどうぞ。
起動後一回目のリクエストではVRAMへのモデルのロードに時間がかかるようで、回答出力開始までに1分程かかりました。2回目以降は非常にレスポンス速く回答してくれます。
REST APIによるリクエストも確認してみます。
PS C:\> curl.exe http://localhost:11434/api/chat -d '{
>> ""model"": ""gpt-oss"",
>> ""messages"": [
>> { ""role"": ""user"", ""content"": ""こんにちは"" }
>> ]
>> }'
{"model":"gpt-oss","created_at":"2025-08-19T02:10:00.5615556Z","message":{"role":"assistant","content":"","thinking":"The"},"done":false}
{"model":"gpt-oss","created_at":"2025-08-19T02:10:00.6037637Z","message":{"role":"assistant","content":"","thinking":" user"},"done":false}
{"model":"gpt-oss","created_at":"2025-08-19T02:10:00.6455317Z","message":{"role":"assistant","content":"","thinking":" says"},"done":false}
...省略
{"model":"gpt-oss","created_at":"2025-08-19T02:10:03.2187345Z","message":{"role":"assistant","content":"こんにちは"},"done":false}
{"model":"gpt-oss","created_at":"2025-08-19T02:10:03.2632367Z","message":{"role":"assistant","content":"!"},"done":false}
{"model":"gpt-oss","created_at":"2025-08-19T02:10:03.3068154Z","message":{"role":"assistant","content":"今日は"},"done":false}
こちらも問題なく非常にレスポンス良く回答が返ってきます。20トークン/秒くらい出ています。
チャットリクエストの実行後にnvidia-smiでGPUの状態を確認すると、OllamaのプロセスがGPUメモリをしっかり使用していることが分かります。今回は約13.6GBを消費しており、GPUが有効に活用されています。
PS C:\> nvidia-smi
Wed Aug 20 15:01:18 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.88 Driver Version: 580.88 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 TCC | 00000000:00:1E.0 Off | 0 |
| N/A 32C P0 26W / 70W | 13699MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 4400 C ...al\Programs\Ollama\ollama.exe 13666MiB |
+-----------------------------------------------------------------------------------------+
✔️ STEP 5: ローカル端末からLLMにアクセスする
#最後に、セットアップしたLLM環境にローカル端末からアクセスしてみましょう。
サーバー側の設定
#Ollamaの起動設定時にOllamaサーバーに0.0.0.0:11434をバインドはしてあるので、サーバまでの通信経路を通す設定をします。
- EC2セキュリティグループ: インバウンドルールに、ローカル端末のIPアドレスからカスタムTCPポート
11434へのアクセスを許可するルールを追加します。 - Windowsファイアウォール: EC2インスタンス内でWindows Defenderファイアウォールの設定を開き、ポート
11434の受信を許可する新しい規則を追加します。
クライアントからの実行
#curlコマンドを使って、EC2インスタンスのパブリックIPアドレス宛にリクエストを送信します。
curl.exe http://EC2のパブリックIP:11434/api/chat -d '{
""model"": ""gpt-oss"",
""messages"": [
{ ""role"": ""user"", ""content"": ""こんにちは"" }
]
}'
無事に応答が返ってくれば、セットアップは完了です!
まとめ
#今回は、AWS EC2のg4dn.xlargeインスタンスとOllamaを使い、Windows環境で独自のLLM実行基盤を構築する手順をご紹介しました。
- 適切なインスタンス選定が重要(g4dnは高コスパ!)。
- GPUドライバーの手動インストールが必要。
- Ollamaを使えば、モデルの管理とAPI提供が非常に簡単。
- セキュリティグループとファイアウォールの設定を忘れずに。
GPUの効果もありとてもレスポンスの高い回答を得られたと思います。
最初のモデル読み込みには時間がかかりますが、一度ロードしてしまえば快適に動作します。この記事が、皆さんのLLM環境構築の参考になれば幸いです。