機械学習と倫理の話
Back to Topこれは豆蔵デベロッパーサイトアドベントカレンダー2024第25日目の記事です。
江川と申します。機械学習のソフトウェアエンジニアをしています。
江川崇氏は、機械学習を専門とするソフトウェアエンジニアです。氏は豆蔵のOBでもあることから、そのご縁でアドベントカレンダーに寄稿いただけることになりました。
氏は多くの著作・翻訳でも知られますが、本記事に関係深い直近の翻訳にオライリー・ジャパンから昨年出版された「機械学習システムデザイン」があります。
機械学習において、データは切っても切り離せない重要な要素です。ただ、データは、取り扱いが非常に難しく、特に倫理やプライバシーの面で潜在的な危険性をはらんでいます。本日は、機械学習におけるデータに関するインシデントをいくつか軽くご紹介し、それを通じてデータについて考えるきっかけを皆さんにお届けできればと思っています。どうぞよろしくお願いいたします。
ところで、今日はクリスマスですね。いかがお過ごしでしょうか。今年も残りわずか数日となりましたが、皆さんにとってこの一年はどのような年だったでしょうか?何か新しいことにチャレンジされましたか?
チャレンジとStrava
#私自身のチャレンジとしては、6月頃からランニングを始めたことです。無理のないペースで少しずつ続けてきたおかげで、今も継続することができています。その結果、15年前の体重に戻り、心身ともに健康になったと感じています。
ところで、ランニングをする際に欠かせないアプリがあります。それが Strava です。Stravaはアクティビティを記録・共有できるオンラインサービスで、日々どのルートをどのくらいのペースで走ったのかをグラフやマップで視覚的に記録できます。また、そのデータをタイムラインで他のユーザーと共有することもできます。Stravaは2009年に米国でサービスを開始し、現在では全世界で約1億人のユーザーが利用しています。
Stravaでは収集したデータを匿名化して、どのルートが多くの人に利用されているかを示すヒートマップも提供しています。この機能により、人気のあるランニングコースを知ることもできます。以下の画像は、豆蔵のある都庁前付近のグローバルヒートマップです。

ところで、このStravaが2018年に世界的な問題を引き起こし、話題になったことがあります。それは、グローバルヒートマップを通じて、さまざまな機密情報が意図せずに暴露されたことです。アフガニスタンの前哨基地の場所や、シリアでのロシアの作戦地域におけるパトロール経路など、海外での米軍の活動が明らかになってしまいました[1]。以下の画像は、その事実を報告した投稿です。
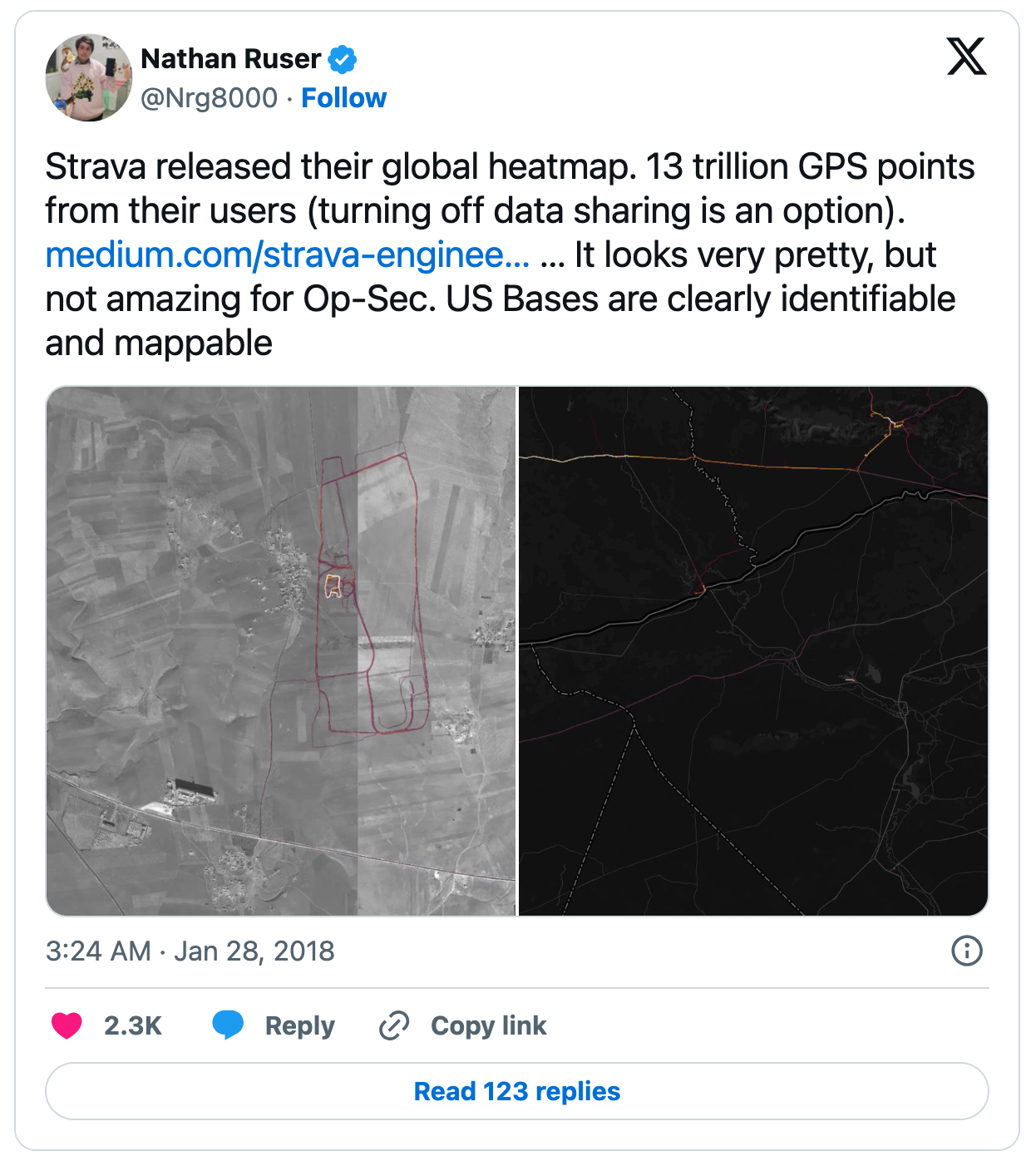
なぜこのような事態が発生したのかというと、多くの軍関係者が日常的にトレーニングを行っており、Stravaを利用してそのアクティビティを記録していたためです。その結果、彼らのアクティビティデータが意図せずビッグデータに取り込まれてしまいました。
私は機械学習に携わるソフトウェアエンジニアですが、その立場から言えることは、機械学習には良質なデータが不可欠だということです。機械学習システムの開発はデータの品質に大きく依存するため、ユーザーデータの収集が非常に重要になります。しかし、データセットを収集・共有する際には、その中に含まれるユーザーのプライバシーやセキュリティが侵害される危険性が常に伴います。
Stravaはプライベートな情報を直接的に漏洩させたわけではなく、収集されたデータは匿名化されており、個人を特定することはできません。それにもかかわらず、データ収集には様々な潜在的な危険性があることを示唆しています。
機械学習のモデルを訓練する際、「量が全てに勝る」、つまりデータは多ければ多いほどよいと考える人もいます。そこまで極端ではないにしても、ある程度の規模のデータを揃えることは、機械学習に携わる多くの人が直面する共通の課題です。しかし、データの倫理面やプライバシー面で問題がないようにデータを収集することは非常に難易度が高いものです。
大規模データセットにも潜む偏見
#では、世界中で多くの開発者や研究者が利用している、由緒ある有名なデータセットを使っていれば安心かというと、一概にそうとは言い切れないこともあります。
世界的に有名な画像データセットの ImageNet でさえ、倫理面の問題が指摘されたことがあります[2]。
ImageNetなどの大規模データセットが機械学習の役に立つ理由は、大量の画像に対して、その画像を説明するカテゴリーやラベルなどのメタデータがセットで提供されている点です。このImageNetに対して一石を投じる ImageNet Roulette という研究プロジェクトがありました。ImageNet Rouletteは、人物の画像をアップロードすると、ImageNetで訓練した機械学習モデルでその画像にラベリングするWEBサイトを提供していました。

ImageNet Rouletteより引用
ImageNetに含まれるラベルには、人の外見や人種、民族的背景、ジェンダーなどに問題のあるカテゴリが存在していることが以前から指摘されていました。ImageNet Rouletteは、そのようなカテゴリが「どのようにモデルの判断に影響し、偏見を再生産するのか」を一般の人々に実感を伴って理解してもらうためのもので、不適切な分類や偏りがどれほど容易かつ如実に現れるかを利用者に直接体験してもらう狙いがありました。なにせ、水着姿の写真をアップロードすると「ふしだらな女(slut)」とラベリングされたり、サングラスを掛けている子どもの写真をアップロードすると、「負け犬(loser)」や「何も成し遂げない人(non-starter)」などとラベリングされるのですから、このサイトは公開後すぐに、不快なラベルや差別的な分類結果を提示したことで大きな議論を呼びました。
しかし、悪意を持った誰かの手によってImageNetが恣意的にラベル付けされたというわけではないでしょう。ImageNetは、WordNetという概念的な辞書を提供することを目的としたプロジェクトから発想を得ており、言葉の概念的な階層関係や繋がりを意識した構造を持っています。ただし、WordNetが生まれた1980年代当時に適切だとされていた概念が、現在の社会では全く許容できないものもあるのです。
この一件は、 「有名で多くの人に利用されているデータだからといって無条件に安心できるわけではない」 こと、そして 「データを中立的に収集し整理することの難しさ」 を改めて認識させられる出来事です。
不利益を被るのは誰か
#人間社会の偏見や先入観が反映されたデータで訓練された機械学習モデルを活用することで不利益を被るのは、大抵の場合、社会的に弱い立場にある者です。社会保障や公共政策の分野で用いる際には特に注意が必要で、何度も大きな問題になっています。
オーストラリアでの例
#オーストラリアの政府機関であるCentrelink(日本で言う厚生労働省のようなものでしょうか)は、福祉給付の過剰支給という課題を抱えていました。しかし、それをチェックする人員が不足していたため、AIを活用した「Robodebt」という債務検出システムを開発し、運用を開始しました。ところが、このシステムにより、多くの正当に福祉給付を受けている受給者に対し、クリスマスやその直前の週に、全く心当たりのない債務通知が大量に送付される事態が発生しました[3]。
受給者は一方的に過剰支給があったと通告され、給付金の返還を求められる状況となりました。しかし、なぜ過剰支給と判断されたのか理由が不明なままで、Centrelinkに問い合わせても「情報を基にシステムが適切に判断したものであり、債務は債権回収業者に引き渡されたので、後は債権回収業者と話せ。」と対応されるのみでした。さらに、債権回収業者からは脅迫的な取り立てを受けるだけで、受給者は解決策を見いだせない状況に追い込まれました。
この「誤った債務通知」により、多くの受給者が精神的苦痛や経済的負担を抱えることになり、国内で大きな社会的議論を巻き起こしました。2020年には集団訴訟が行われ、最終的に政府側は和解に応じ、誤って徴収した金額を返還し、受給者への賠償を行うことになりました。
イギリスでの例
#2020年、英国では新型コロナウイルス感染拡大の影響で、大学入学資格として認められる重要な統一試験である「Aレベル試験」が中止に追い込まれました。これを受けて、試験運営に携わる公的機関であるOfqualは、AIを用いて自動的にAレベル試験の結果を算出し、それを生徒の成績として採用する方針を打ち出しました。Ofqualは「公平性を保つため」としてデータの収集方法やアルゴリズムの一切を秘匿しました。
蓋を開けてみると、AIによるスコアリングは、学生自身の能力や過去のパフォーマンスよりも、彼らが通う学校の過去の成績に大きく依存していました。そのため、「家庭が裕福ではなく良い学校に通うことができていないものの、実際には非常に優秀な生徒」の成績が不当に低く評価されるケースが発生しました[4]。
成績が低い学校に通う生徒は、恵まれない背景を持つことが多く、一方で成績が高い学校に通う生徒は、裕福な家庭環境に恵まれていることが多い傾向がありました。そのため、結果的に貧しいマイノリティの生徒が不当に低く評価されるという、深刻な不公平が生じました。この状況に対し、生徒や保護者、教育関係者、さらにはメディアから強い批判が巻き起こり、デモ活動にまで発展しました。以下の画像はWIREDの記事に掲載されていた実際のデモの様子です。

抗議や世論の圧力を受け、政府とOfqualは方針を転換し、最終的には教師による評価を重視する形で成績を再算定することになりました。
いずれのケースにおいても、データの収集方法、それを処理する手順、さらにそのデータを活用したアルゴリズムの詳細が一般に公開されておらず、審査や詳しい説明が提供されることがなかったことが問題の原因となっているように感じます。もちろん、仕組みの詳細を公表してしまったら、仕組みそのものを解析され、うまいように利用されてしまうかもしれないという懸念があったのかもしれません。しかし、これらの出来事は、機械学習を多くの人々の社会生活に直接影響を与えるような取り組みに導入する際、透明性がいかに重要であるかを改めて浮き彫りにしています。
最後に
#いくつか事例をご紹介しましたが、中には生々しい内容も含まれていたかもしれません。機械学習、特にデータに関する倫理的な問題は非常に取り扱いが難しく、機械学習に携わる当事者としても日々考えさせられる課題です。
たとえ倫理的に許容しがたい問題が含まれていたとしても、「ポジティブがネガティブを上回る」つまり、偏りや倫理の問題を課題として扱いつつ、経済・社会全体における機械学習・AIのメリットが圧倒的に大きいと主張することで、ネガティブな側面よりポジティブな側面が大きいのだから許容すべきとする意見もあります。
皆さんはこの問題についてどのように考え、どの方向に進むべきだと思いますか?
こうした問題に思いを巡らせながら、年越しを過ごしたいと思います。(と、そんなわけもなく、すべて忘れて飲み食いしていると思いますが)
よいお年をお迎えください。
Mashable - Strava’s fitness heatmap has a major security problem for the military https://mashable.com/article/strava-fitbit-fitness-tracker-global-heatmap-threat ↩︎
WIRED.jp - AIによる人物写真のラベリングは、どこまで適切なのか? ある実験が浮き彫りにした「偏見」の根深い問題 https://wired.jp/2019/11/27/viral-app-labels-you-isnt-what-you-think/ ↩︎
New Matilda - High Farce: The Turnbull Government’s Centrelink ‘Robo-Debt’ Debacle Continues To Grow https://newmatilda.com/2017/01/06/the-turnbull-governments-centrelink-robo-debt-debacle-continues-to-grow/ ↩︎
Ada Lovelace Institute - Can algorithms ever make the grade? https://www.adalovelaceinstitute.org/blog/can-algorithms-ever-make-the-grade/ ↩︎