CloudWatch Application Signals で Lambda のSLOをモニタリングする
Back to Top先月ですが、CloudWatch Application SignalsがAWS Lambdaに対応しました。
CloudWatch Application Signalsは2023年にプレビューとして登場し、今年GAになったばかりの新しいAPM(Application Performance Monitoring)機能です。
今まではEKS、ECS、EC2のみのサポートでしたが、ついにLambdaにも対応しました。
Application Signals は、OpenTelemetryを利用して収集したメトリクスを ダッシュボードやサービスマップ として直感的に可視化します。
さらに、SLO(Service Level Objective)に基づき、システムの目標達成度を測定・管理することで、ビジネス視点での合理的な運用改善をサポートします。
今回は、AWSの標準APMツールとして注目されるこの機能を、Lambda関数を対象に試してみます。
Application Signals有効化
#Application SignalsがサービスディスカバリやSLOを計測するためには、ログやメトリクスに対するアクセス許可が初回のみ必要です。
ここではマネジメントコンソールから有効にしました。

Step 2 は各サービスで有効にするので対応不要です。
モニタリング対象のLambda関数を実装する
#まずは、モニタリング対象のLambda関数を作成します。
ここでは以下のLambdaイベントハンドラを作成しました。
import type { APIGatewayProxyHandler } from 'aws-lambda';
import { PutObjectCommand, S3Client } from '@aws-sdk/client-s3';
const s3client = new S3Client();
const handler: APIGatewayProxyHandler = async () => {
await s3client.send(new PutObjectCommand({
Bucket: process.env.BUCKET_NAME ?? '',
Key: Date.now().toString() + '.txt',
Body: 'lambda-app-signal-test'
}))
const rand = Math.random();
// 5%の確率で失敗
const success = rand > 0.05;
if (!success) {
throw new Error('oops!');
}
return {
statusCode: 200,
body: JSON.stringify({
message: 'ok!',
}),
};
}
// 現状ADOTをTypeScriptで使う場合にexport文が利用できない制約あり
// https://github.com/aws-observability/aws-otel-lambda/issues/99#issuecomment-919993949
module.exports = { handler }
S3バケットへPUTした後に、5%の確率でエラーを発生させています。
Application Signalsを有効化してLambda関数をデプロイする
#作成したLambda関数をデプロイします。
ここではAWS CDKを使います。
import * as cdk from 'aws-cdk-lib';
import { Construct } from 'constructs';
import * as s3 from 'aws-cdk-lib/aws-s3';
import * as iam from 'aws-cdk-lib/aws-iam';
import * as nodejs from 'aws-cdk-lib/aws-lambda-nodejs';
import * as lambda from 'aws-cdk-lib/aws-lambda';
export class LambdaAppSignalStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const bucket = new s3.Bucket(this, 'SampleBucket');
const role = new iam.Role(this, 'LambdaRole', {
assumedBy: new iam.ServicePrincipal('lambda.amazonaws.com'),
managedPolicies: [
iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole'),
// 1. Application SignalsのAWSマネージドポリシー
iam.ManagedPolicy.fromAwsManagedPolicyName('CloudWatchLambdaApplicationSignalsExecutionRolePolicy')
],
inlinePolicies: {
s3policy: new iam.PolicyDocument({
statements: [
new iam.PolicyStatement({
actions: ['s3:PutObject'],
resources: [bucket.bucketArn + '/*']
})
]
})
}
});
// 以下よりADOT Lambda LayerのARN取得
// https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-Application-Signals-Enable-Lambda.html#Enable-Lambda-Layers
const awsOtelDistro = lambda.LayerVersion.fromLayerVersionArn(this, 'AWSOtelExtension',
'arn:aws:lambda:ap-northeast-1:615299751070:layer:AWSOpenTelemetryDistroJs:5');
const func = new nodejs.NodejsFunction(this, 'SampleFunction', {
role,
functionName: 'flaky-api-for-app-signals',
entry: './lambda/index.ts',
handler: 'handler',
// X-RayのActive Tracing有効化(任意)
tracing: lambda.Tracing.ACTIVE,
// 2. ADOTレイヤー
layers: [awsOtelDistro],
runtime: lambda.Runtime.NODEJS_22_X,
timeout: cdk.Duration.seconds(10),
environment: {
BUCKET_NAME: bucket.bucketName,
// 3. Application Signals有効化
AWS_LAMBDA_EXEC_WRAPPER: '/opt/otel-instrument'
}
});
const url = new lambda.FunctionUrl(this, 'SampleFunctionUrl', {
function: func,
authType: lambda.FunctionUrlAuthType.NONE
});
new cdk.CfnOutput(this, 'SampleFunctionUrlOutput', {
value: url.url
});
new cdk.CfnOutput(this, 'BucketNameOutput', {
value: bucket.bucketName
});
}
}
LambdaでApplication Signalsを利用するポイントは以下です。
- 以下AWSマネージドポリシーをLambdaの実行ロールに指定
CloudWatchLambdaApplicationSignalsExecutionRolePolicy
- AWSが提供するADOT(AWS Distro for OpenTelemetry)をLambdaレイヤーとして追加
- 環境変数
AWS_LAMBDA_EXEC_WRAPPERに/opt/otel-instrumentを指定
AWSのADOT Lambdaレイヤーは公式ドキュメントに記載されているものを使います。
必須ではありませんが、公式ドキュメントではこれに加えてX-RayのActive Tracingを有効にすることも推奨されています。
これをデプロイします。
cdk deploy
デプロイ後にマネジメントコンソールからLambdaの状態を確認します。
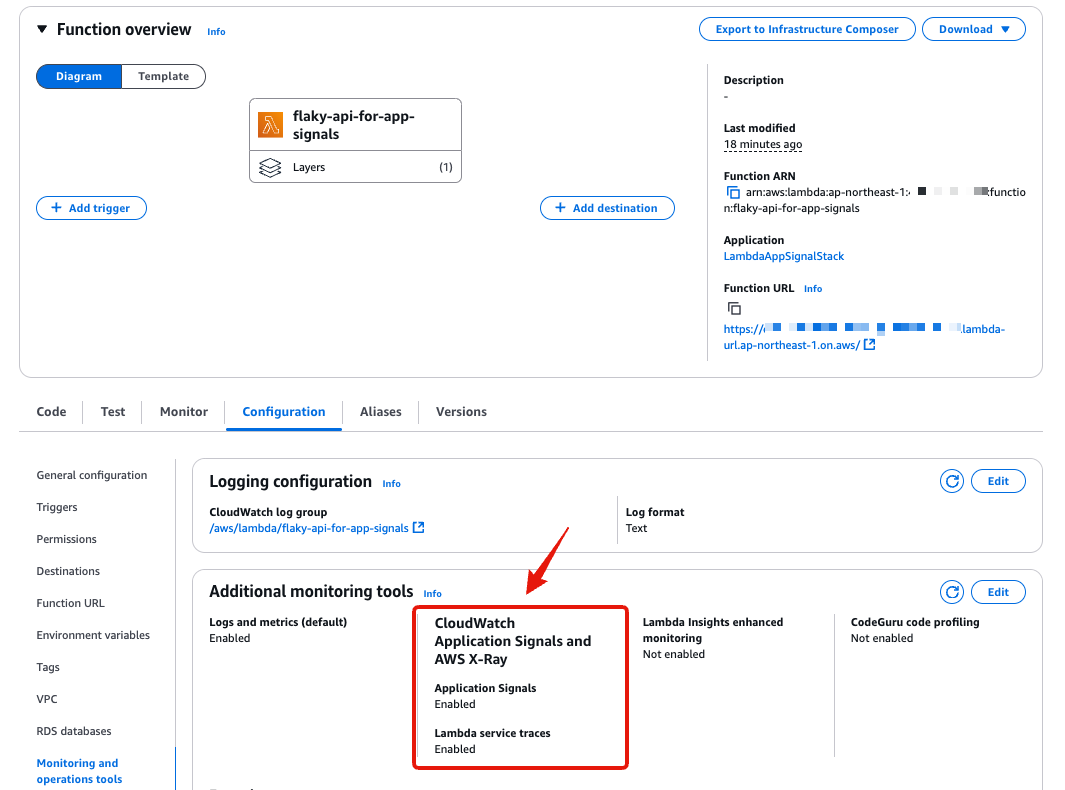
Application SignalsとX-Rayのトレーシングが有効になっています。
Lambda Function URLを有効にしていますので、curl等のツールからアクセスできます。
curl https://xxxxxxxxxxxxxxxxxx.lambda-url.ap-northeast-1.on.aws/
# {"message":"ok!"}
Application Signalsのサービス、サービスマップを確認する
#対象サービスでトラフィックが発生すると、Application Signalsはサービスの追加を検知し、Application Signalsから確認できるようになります(自動検知)。
このプロセスには一定時間(5分程度)かかります。
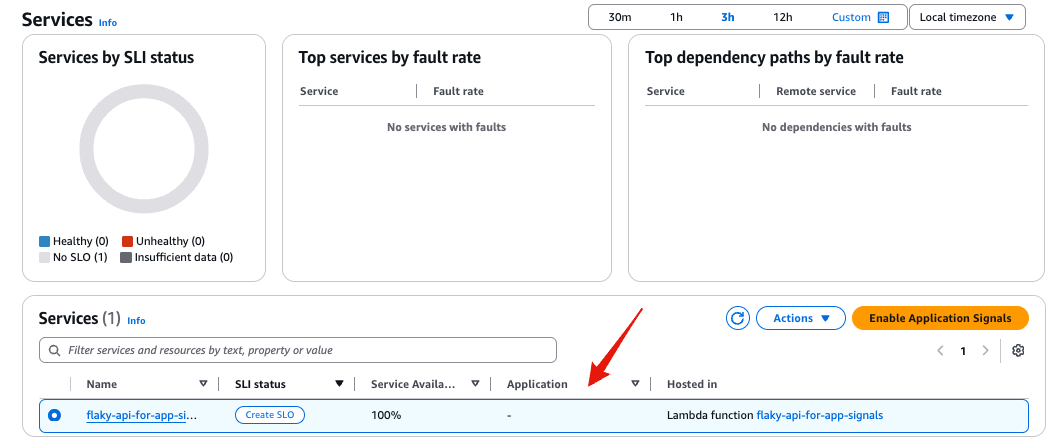
サービス名をクリックするとサービスの詳細も確認できます。
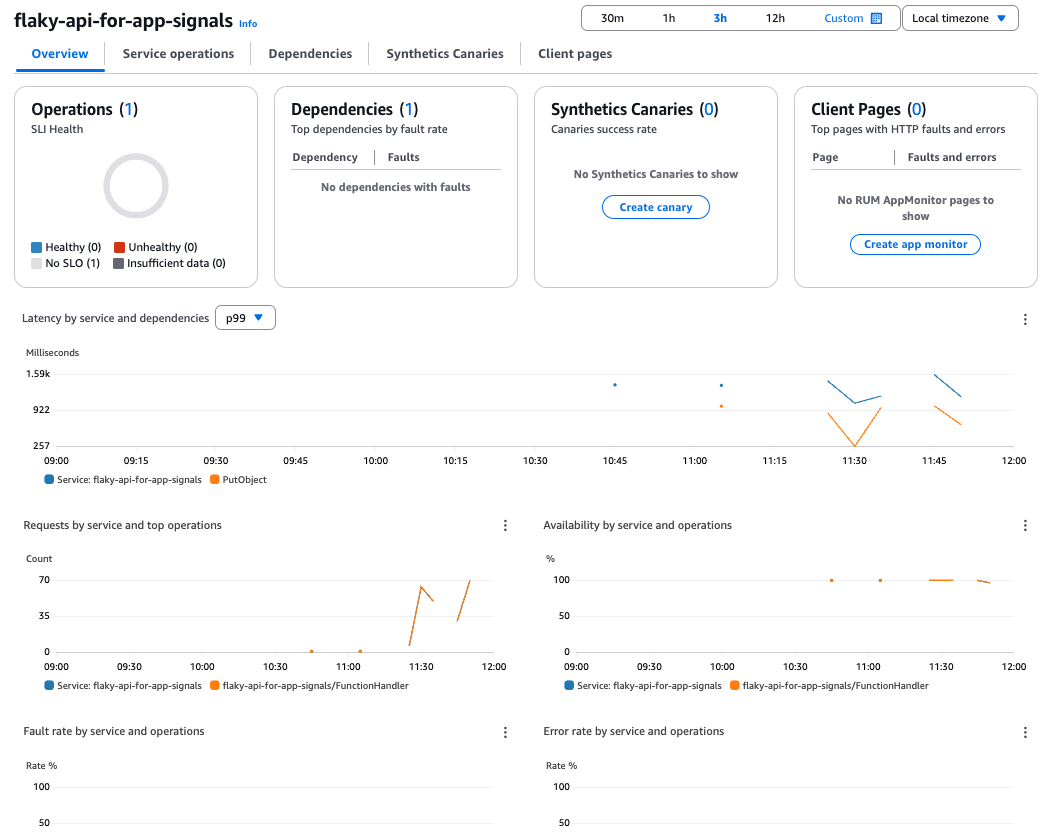
Overview
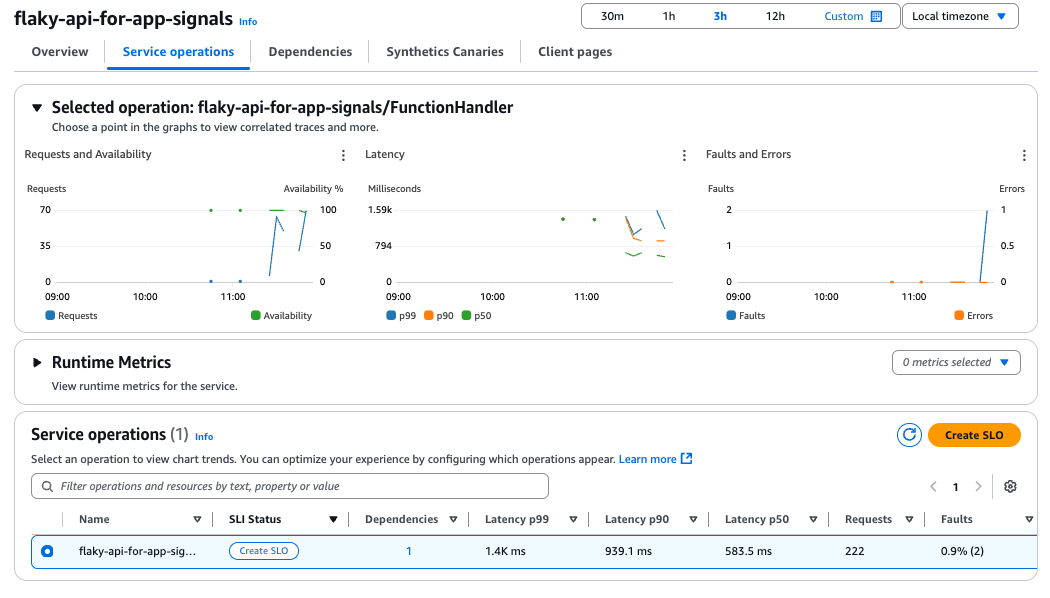
Service Operations
Dependencies
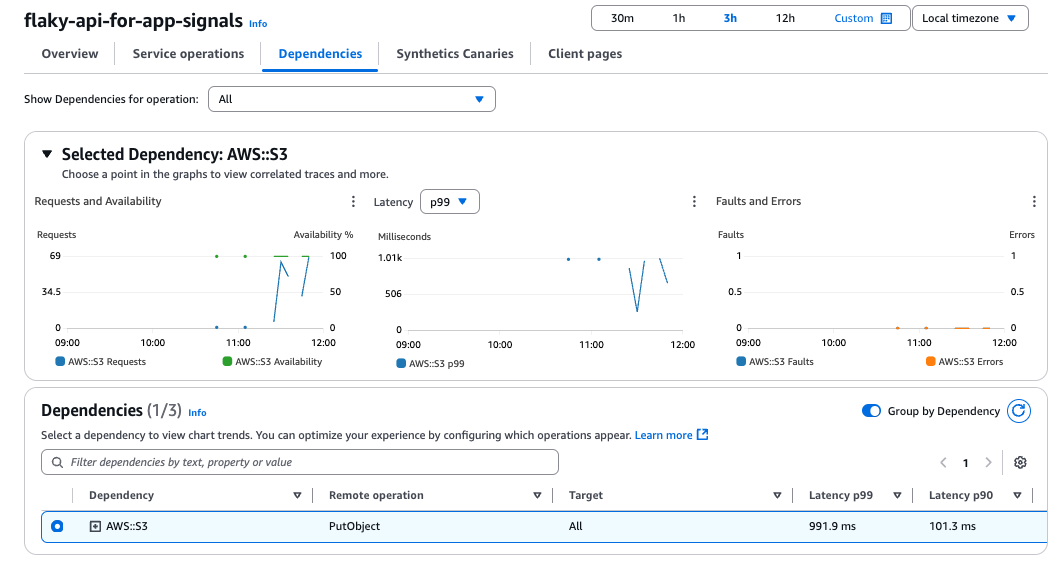
Synthetics CanariesとClient Pagesは今回利用していませんので何も表示されません。
サンプル数が少なく、あまり見栄えが良くないですが、Lambdaのメトリクスや依存関係(S3)が可視化されています。
必要に応じてX-Rayで分析すると、ボトルネックも見えやすくなるかと思います。
次にApplication Signalsのサービスマップを確認します。
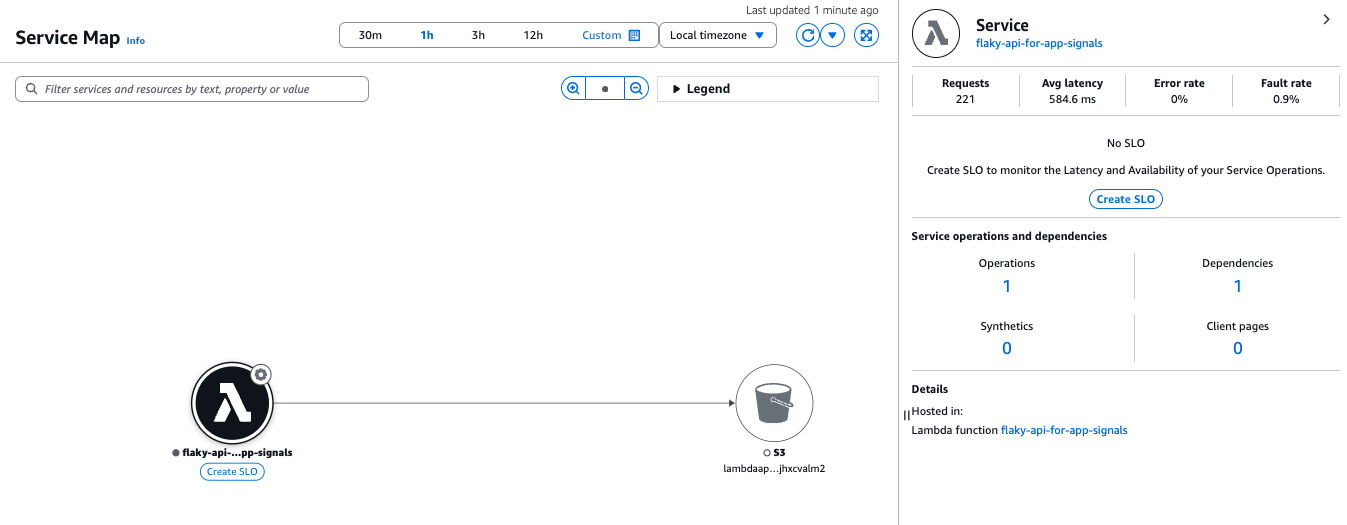
今回作成したLambda -> S3バケットの関係が可視化されています(X-Rayのトレースマップと似ているような)。
各ノードやエッジをクリックすると、該当部分のメトリクスを確認できます。
SLOを定義する
#Application Signalsによる自動検知やダッシュボードを見てきましたが、さらにSLOを定義してビジネス目線でのモニタリングをやってみます。
少し長いですが、以下ドキュメントで記述されています。
ここでも、AWS CDKを使ってSLOを作成します。
Application Signalsは現状L1コンストラクトしかありませんので、CloudFormationで記述するのと同等です。
if (this.node.tryGetContext('createSLO') === 'true') {
const availabilitySLO = new applicationsignals.CfnServiceLevelObjective(this, 'AvailabilityServiceLevelObjective', {
name: `${func.functionName}-availability`,
requestBasedSli: {
requestBasedSliMetric: {
metricType: 'AVAILABILITY',
keyAttributes: {
'Type': 'Service',
'Name': func.functionName,
'Environment': 'lambda:default'
},
operationName: `${func.functionName}/FunctionHandler`
}
},
goal: {
attainmentGoal: 95,
warningThreshold: 30,
interval: {
rollingInterval: {
duration: 1,
durationUnit: 'DAY' // DAY | MONTH
}
}
},
// バーンレート(5分、60分の時間枠)
burnRateConfigurations: [
{ lookBackWindowMinutes: 5 },
{ lookBackWindowMinutes: 60 }
]
});
}
ここでのSLO定義は以下です。
SLI(Service Level Indicator)
SLOの指標とするメトリクスです。
採用する指標は可用性(AVAILABILITY)とレイテンシ(LATENCY)がデフォルトで選択できます。今回はAVAILABILITYを指定しました。
これ以外にも監視対象サービスの任意CloudWatchメトリクスも指定可能です。
また指標の算出方法として、一定期間毎に評価する方式とリクエスト数で算出する方式の2種類が選択できます。
ここでは計算が単純なリクエストベースを採用しました。
SLO目標(goal)
先ほど作成したLambda関数は、5%の確率で失敗する設定にしました。
これに合わせて、SLOの目標値(attainmentGoal)は「95%」に設定し、目標達成がギリギリ超えるかどうかという状況を意図的に作り出しています。
監視期間は1日間のローリングインターバル(rollingInterval)を使用し、現在時刻から直近のメトリクスをスライドしながら常に監視する設定です。
ローリングインターバルは短期的な異常を素早く検知できるのが利点です。
一方で、カレンダーインターバル(calendarInterval)を使用すれば、固定された期間で監視できます。
カレンダーインターバルは、ビジネス視点での可視化やステークホルダーへの説明がしやすいため、状況に応じて使い分けるのが効果的です。
バーンレート(burnRateConfigurations)
少し難解に感じるかもしれませんが、バーンレート(Burn Rate)[1]は指定された期間内 にエラーバジェット(許容されるエラー)がどの程度の速さで消費されているかを示す指標です(詳細は後述のコラムを参照)。
バーンレートの概念は、GoogleのSite Reliability Workbookで提唱されており、長期と短期の振り返り期間(Look-back window)を組み合わせることで、信頼性の高いアラートを実現できると述べられています。
これに倣い、ここでは5分と60分の振り返り期間(Look-back window)を設定しました。
計算式はシンプルです。期間内に発生したエラー率(%)をエラーバジェット(%)で割った値として定義されます。
エラーバージェットは1からSLO目標値を差し引いた値です(99%であれば1%)。その名の通り、SLO期間内で許容されるエラーの予算を示します。
バーンレートはその値の大きさによって以下のように解釈されます。
- 1の場合: エラーバジェットをちょうど使い切るペース。
- 1以上の場合: エラーバジェットが枯渇するペース。SLO期間の終了前に予算が使い切られるため対処が必要。
- 1以下の場合: エラーバジェットの範囲内に収まっている状態。理想的だがリスクを取ってないと見做される可能性もある。
例えば、上記可用性SLOのバーンレートを考えてみます。
Look-back window内で1000リクエストがあり200リクエストでエラーが発生した場合は以下のように計算できます。
- エラーバジェット: 100% - 95% = 5%
- 実際のエラー率: 200 / 1000 * 100 = 20%
- バーンレート: 20% / 5% = 4
となり予定の4倍の速度でエラーバジェットを消費していることになります。
この状態が続けばSLO監視期間(1日)の1/4(6時間)でエラーバジェットが枯渇してしまうため、即時の対応が必要になります。
ではSLOをデプロイします。今回はパラメータとしてcreateSLOをtrueにして実行します。
cdk deploy --context createSLO=true
SLOはApplication Signalsがサービスを検知してからでないと作成できません。
つまり、Lambda作成と同タイミングでSLOも作成しようとすると、対象サービスが見つからずデプロイエラーになります。
これを回避するために、ここで対応しているようにフラグ(createSLO)で切り替えたり、スタック自体を分離する等、実行タイミングを調整する工夫が必要です。
マネジメントコンソールでApplication SignalsのSLOを確認します。
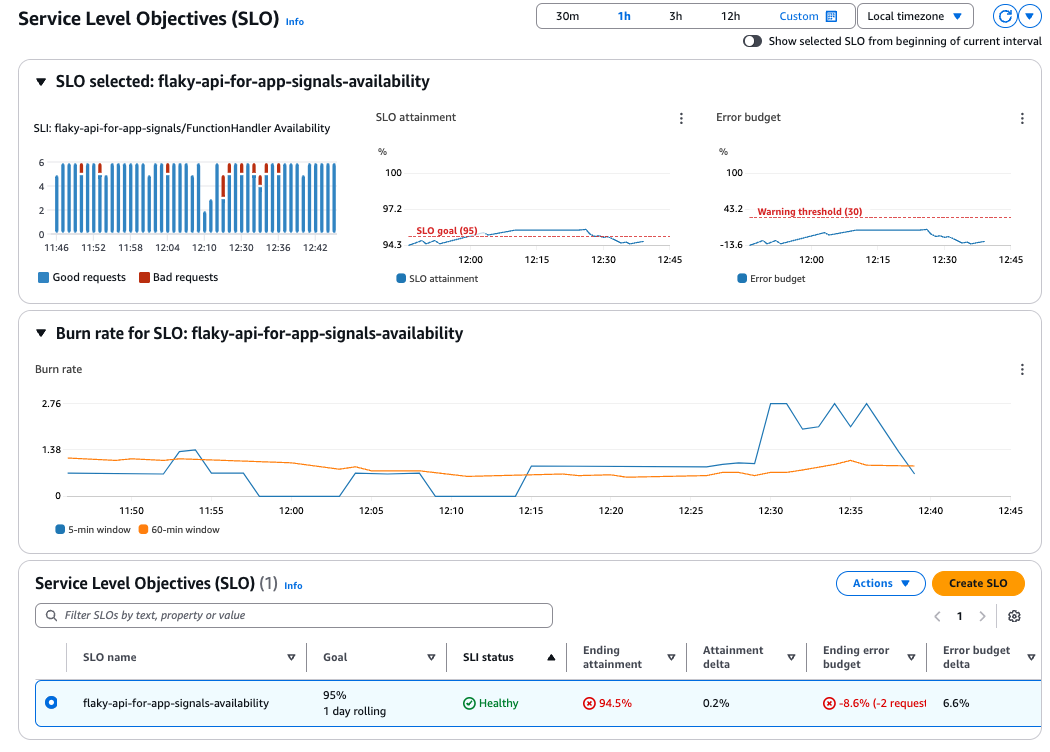
SLOを定義するだけで、いい感じのダッシュボードを作成してくれます。
今回は94.5%とSLOに指定した95%の可用性は達成できていない状態になっています(2リクエスト分のエラーバジェットを超過)。
また、中程のバーンレートのグラフ見ると短期のLook-back window(5分)がリクエストの失敗に敏感に反応している一方で、長期のLook-back window(60分)は平準化されている様子も確認できます。
SLOベースでCloudWatchアラームを作成する
#SLOは定義して現在の状態を可視化しましたが、通知メカニズムを構築しなければ意味がありません。
Application Signals自体はSLOに関連するメトリクスをCloudWatchに登録するまでで、これを監視してアラームを発報するのはCloudWatchアラームの役割です。
今回は以下の3つのアラートを作成します。
- エラーバジェットが残30%
- エラーバジェットが枯渇(=SLO未達成)
- 短期・長期のバーンレート
1. エラーバジェットが残30%
#const warningAlarm = new cloudwatch.Alarm(this, 'AvailabilityWarningAlarm', {
alarmName: `SLO-WarningAlarm-${availabilitySLO.name}`,
alarmDescription: 'SLO警告(残30%)の閾値超過アラーム',
actionsEnabled: true,
evaluationPeriods: 1,
datapointsToAlarm: 1,
threshold: 100 - (5 * (1 - 0.3)), // 96.5%
comparisonOperator: cloudwatch.ComparisonOperator.LESS_THAN_OR_EQUAL_TO_THRESHOLD,
metric: new cloudwatch.Metric({
metricName: 'AttainmentRate',
namespace: 'AWS/ApplicationSignals',
statistic: cloudwatch.Stats.AVERAGE,
dimensionsMap: {
SloName: availabilitySLO.name
},
unit: cloudwatch.Unit.PERCENT,
period: cdk.Duration.minutes(1)
})
});
warningAlarm.addAlarmAction(new actions.SnsAction(/* alarm action */));
Application SignalsはAWS/ApplicationSignalsネームスペースに送信されてます。
その中でメトリクス名AttainmentRateには、現在のSLO達成率が送信されています。
これを監視すれば良さそうです。
ここでは、5%のエラーバジェットのうち 70%(3.5%)を消費した時点、つまり 達成率が96.5%を下回った場合に通知するよう設定しています。
2. エラーバジェット枯渇(=SLO未達成)
#const attainmentAlarm = new cloudwatch.Alarm(this, 'AvailabilityAttainmentGoalAlarm', {
alarmName: `SLO-AttainmentGoalAlarm-${availabilitySLO.name}`,
alarmDescription: 'SLOゴールの閾値超過アラーム',
actionsEnabled: true,
evaluationPeriods: 1,
datapointsToAlarm: 1,
threshold: 95, // SLOのgoal.attainmentGoalと同値
comparisonOperator: cloudwatch.ComparisonOperator.LESS_THAN_OR_EQUAL_TO_THRESHOLD,
metric: new cloudwatch.Metric({
metricName: 'AttainmentRate',
namespace: 'AWS/ApplicationSignals',
statistic: cloudwatch.Stats.AVERAGE,
dimensionsMap: {
SloName: availabilitySLO.name
},
unit: cloudwatch.Unit.PERCENT,
period: cdk.Duration.minutes(1)
})
});
attainmentAlarm.addAlarmAction(new actions.SnsAction(/* alarm action */));
使用するメトリクスは警告通知と同じですが、閾値はSLOの目標値(95%)と同じになります。
3. 短期・長期バーンレート
#1つのLook-back windowのバーンレートに対するアラームのみでも良いのですが、ここでは短期・長期のバーンレートを組み合わせて使うことでアラートの精度と信頼性を向上させます。
- 短期バーンレート(5分):エラーが現在進行中であることを素早く検知・確認する。エラーが止まるとすぐに閾値を下回るため、アラートが速やかに解除される。
- 長期バーンレート(1時間):持続的なエラーの傾向を確認する。スパイク的なエラー等、短期バーンレートの誤検知をフィルタリングする。
この2つのバーンレートを AND条件 で組み合わせることで、短期的な問題が 持続的に発生している場合のみアラートが発報されるため、誤検知を抑えつつ本質的な異常を検出 できます。
これを実現するためにComposite Alarmを使って複数アラームを組み合わせます。
const burnRateAlarm_5min = new cloudwatch.Alarm(this, 'AvailabilityBurnRateAlarm_5min', {
alarmName: `SLO-BurnRate-${availabilitySLO.name}-5`,
alarmDescription: 'バーンレート(5分)の閾値超過アラーム',
actionsEnabled: true,
evaluationPeriods: 1,
datapointsToAlarm: 1,
// https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/CloudWatch-ServiceLevelObjectives.html#CloudWatch-ServiceLevelObjectives-burn
threshold: 0.1 * (24 * 60) / 60, // 2.4: 長期のLook-back window(60分)に合わせる
comparisonOperator: cloudwatch.ComparisonOperator.GREATER_THAN_THRESHOLD,
metric: new cloudwatch.Metric({
metricName: 'BurnRate',
namespace: 'AWS/ApplicationSignals',
statistic: cloudwatch.Stats.MAXIMUM,
dimensionsMap: {
SloName: availabilitySLO.name,
BurnRateWindowMinutes: '5'
},
period: cdk.Duration.minutes(1)
})
});
const burnRateAlarm_60min = new cloudwatch.Alarm(this, 'AvailabilityBurnRateAlarm_60min', {
alarmName: `SLO-BurnRate-${availabilitySLO.name}-60`,
alarmDescription: 'バーンレート(60分)の閾値超過アラーム',
actionsEnabled: true,
evaluationPeriods: 1,
datapointsToAlarm: 1,
threshold: 0.1 * (24 * 60) / 60, // 2.4: 期間内にエラーバージェットの10%消費
comparisonOperator: cloudwatch.ComparisonOperator.GREATER_THAN_THRESHOLD,
metric: new cloudwatch.Metric({
metricName: 'BurnRate',
namespace: 'AWS/ApplicationSignals',
statistic: cloudwatch.Stats.MAXIMUM,
dimensionsMap: {
SloName: availabilitySLO.name,
BurnRateWindowMinutes: '60'
},
period: cdk.Duration.minutes(1)
})
});
const compositeAlarm = new cloudwatch.CompositeAlarm(this, 'AvailabilityBurnRateAlarm_Composite', {
compositeAlarmName: `SLO-BurnRate-${availabilitySLO.name}-CompositeAlarm`,
actionsEnabled: true,
alarmDescription: '短期、長期の複合バーンレートアラーム',
alarmRule: cloudwatch.AlarmRule.allOf(burnRateAlarm_5min, burnRateAlarm_60min)
})
compositeAlarm.addAlarmAction(new actions.SnsAction(/* alarm action */));
先ほどはSLO達成率を監視対象にしましたが、バーンレートはBurnRateメトリクス[2]として送信されるため、これを監視対象にします。
ここでアラームの閾値は、以下の式で計算しました。
ここでは、直近60分間を対象にエラーバジェットの10%を消費した場合にアラートを発生する設定としています。つまり0.1*(24*60)/60となり、2.4が閾値になります[3]。
まとめ
#今回はLambdaを対象にApplication Signalsを使ったモニタリングを試してみました。
ADOTが提供する自動計装のおかげで、アプリケーション側のソースコードに手を入れる必要がありませんし、標準化されたダッシュボードも自動で作成してくれますので職人技も不要です!
今後のLambdaのモニタリングは、Application Signalsを使ったSLOベースのアプローチへと置き換わっていく流れが加速するのではないでしょうか。
とはいえ、モニタリングで最も難しいのは「メトリクスの選定」と「アラートの定義」 です。
これは毎回悩まされるポイントですが、まずは 一定のルールを決めて進め、短期的なサイクルで定期的に実績を見直すのが良さそうです。
運用を繰り返す中で調整を重ね、より精度の高い監視体制を構築していきたいですね。
SLO名+Look-back window(
BurnRateWindowMinutes)のディメンションから確認可能です。 ↩︎Google SRE Workbookの「6: Multiwindow, Multi-Burn-Rate Alerts」に合わせて、両アラームの閾値は同一に合わせました。 ↩︎