Amazon Comprehend はアンケート分析に使えるのか試してみた
Back to Topはじめに
#こんにちは。教育グループの高です。ようやく新人研修も終わりましたので、久しぶりに記事を書いてみたいと思います。
今回は、アンケート集計に関するお話です。新人研修に限らず研修を実施した際、受講者のみなさまにはアンケートにご回答頂いています。私はざっくり以下の手順で、自由記述のアンケート集計、分析していました。
- アンケートの回答内容を形態素解析し、単語別(名詞のみ)の出現回数を求める
- 出現回数の上位の単語が含まれた回答を確認していき、報告書に添付する回答を抜粋するとともに全体的な傾向を掴む
この方法では、最初の手順については作業者による差異は少ないと思います。しかし、2つ目の手順では、作業者によって抜粋する回答は変わります。つまり、属人性の高い作業と考えられます。また、新人研修では、多い案件では数百名の受講者がいるため、回答に目を通すのも一苦労です。
そこで今回、Amazonのサービスの1つであるAmazon Comprehedを試験的に使ってみて、これまでのアンケート集計、分析に適用できるのかどうかを検討してみました。
Amazon Comprehendとは
#Amazon Comprehendとは、自然言語処理によりドキュメントを分析するAWSのサービスです。主に以下のような機能(インサイト)があります。
| 主要な機能 | 説明 |
|---|---|
| エンティティ | ドキュメント内の人物、場所、位置など実際に存在するものや日時、数量などの尺度を抽出 |
| キーフレーズ | ドキュメントに表れるキーフレーズを抽出 |
| PII(日本語未対応) | 個人を特定できる個人データを抽出 |
| センチメント | 文章の感情(センチメント)を判断 |
| 対象センチメント(日本語未対応) | 文章中の特定のエンティティに対する感情を判断 |
| 構文解析(日本語未対応) | ドキュメントに含まれる単語とその品詞を抽出 |
| トピックモデリング(日本語未対応) | ドキュメントを分析して、文章の主題を判断 |
私のこれまで実施してたアンケートの分析では、上記の表の構文解析をプログラムで実施し、対象センチメントとトピックモデリングを手作業でやっているような感覚に近いかと思います。
Amazon Comprehendでは対象センチメントとトピックモデリングを利用したかったのですが、日本語には非対応となっています…。
Amazon Comprehendで日本語に対応している機能を試す
#期待していた対象センチメントとトピックモデリングについては日本語非対応でしたが、折角の機会ですので日本語に対応している機能を利用してみました。
今回、リアルタイム分析とジョブ分析の2通りの方法を試してみました。
リアルタイム分析
#リアルタイム分析は、フォームに分析対象となるテキストを入力します。その名の通り、即座に分析結果を確認できます。
分析タイプとしては「Built-in」と「Custom」の2つを選択できますが、今回は簡単に利用できる「Built-in」を利用しました。「Built-in」はAWSが用意している分析モデルを利用する方式です。一方、「Custom」はユーザーが構築した分析モデルを利用する方法で、当然分析前にモデルを構築する必要があります(モデルの構築に関しては本記事では割愛します)。
利用方法は、Amazon Comprehendの左側ペインから「Real-time analysis」を選択肢、Analysis typeを「Built-in」、解析対象のテキストをテキストエリアに入力して「Analyze」ボタンをクリックすれば良いだけです。
なお、今回使用したデータは、実際の新人教育で実施したアンケートの回答を使用しました。具体的には「オンライン研修の良かった点についてご記入ください。」というアンケートの自由記述回答を利用しています。
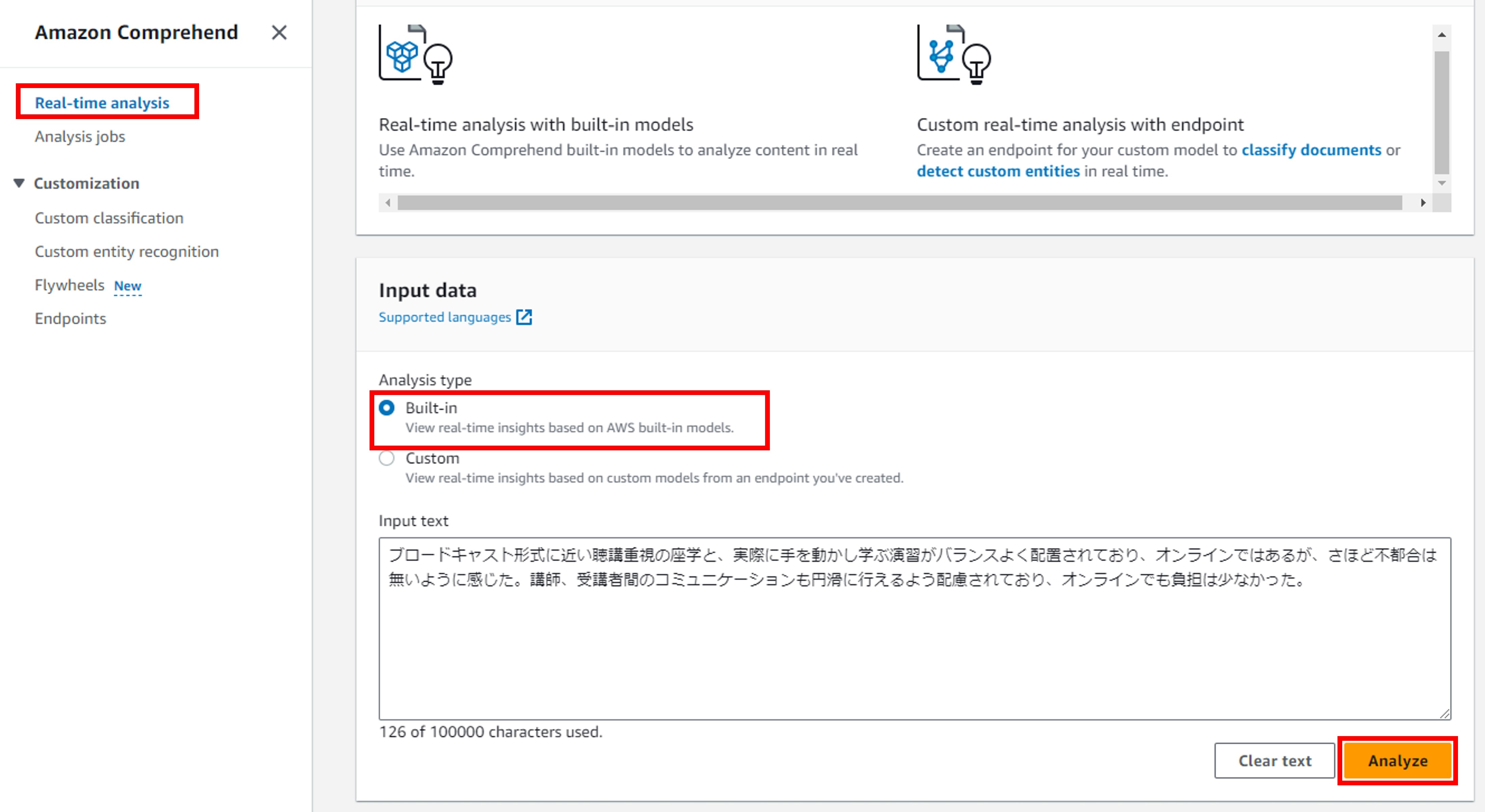
画像でも確認できますが、今回は以下の回答を分析しました
ブロードキャスト形式に近い聴講重視の座学と、実際に手を動かし学ぶ演習がバランスよく配置されており、
オンラインではあるが、さほど不都合は無いように感じた。講師、受講者間のコミュニケーションも円滑に
行えるよう配慮されており、オンラインでも負担は少なかった。
エンティティ
エンティティを分析してみたところ、回答にはエンティティが含まれていませんでした。これは、人の名前や場所、商品等の固有名詞、日付や数値の尺度というものが一切含まれていないためです。
ちなみに、ビデオ会議システムの「Zoom」は、エンティティとしては認識されませんでした。これは、ユーザーが独自に構築したカスタムモデルを使って分析する必要があるかもしれません。
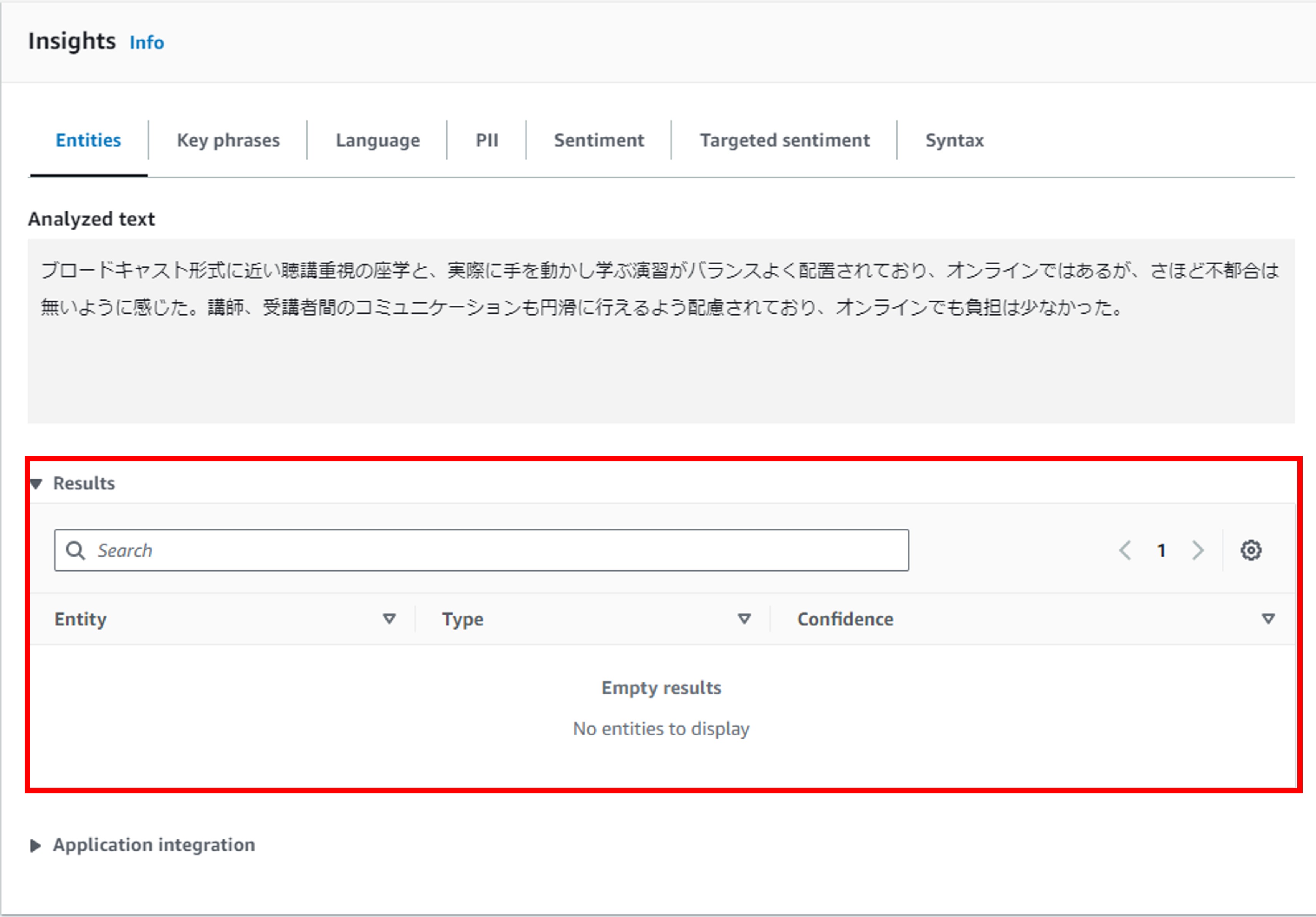
試しに、エンティティが含まれるケースを試してみました。このテキストでは、「十分」という単語を「Quantity(≒数量)」として認識しています。また、Amazon Comprehendでは、信頼度(Confidence)も表示されます。今回は0.98と高い信頼度となっています。個人的には、「十分」は具体的な数量を表しているとはあまり思いませんが、Amazon Comprehendではエンティティと解釈するようです(もしかすると「10分」と認識しているかも?)。
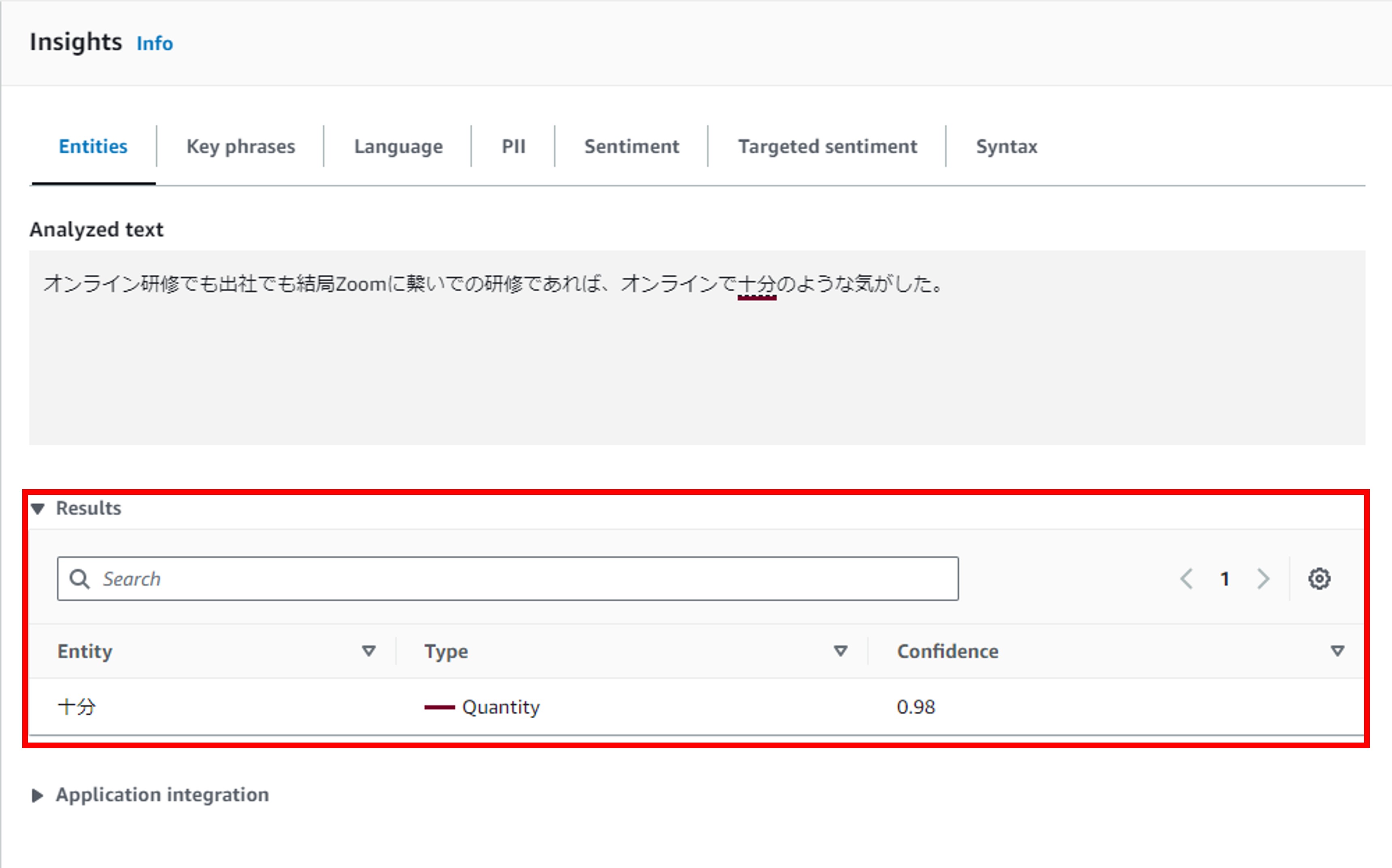
キーフレーズ
キーフレーズは、具体的には名詞句を抽出するようです。例えば、「仕事」、「演習」のように単なる名詞のみの場合や、「美しい日」のような名詞句が抽出されます。
実際にキーフレーズを抽出した結果は以下の通りです。今度はそれなりに結果が得られています。ちなみにAmazon Comprehendでは、信頼度(Confidence)も表示されます。今回の分析結果はそれなりに信頼度が高くなっています。
ただ、思ったよりもキーフレーズが多く抽出されます。回答の要約として利用するには使いにくいですね。
また、実際に利用する際には、信頼度が一定以下のキーフレーズは除くなどの工夫が必要そうです。
センチメント
センチメントは、文章の感情を「Neutral(中立)」「Positive(肯定的)」、「Negative(否定的)」、「Mixed(肯定的と否定的両方)」の4つの観点で判断します。
実際にセンチメント分析した結果は以下の通りです。GUI上では、前述の4つの観点それぞれの信頼度が表示されます。今回のテキストは「Positive」が最も高い信頼度となっています。
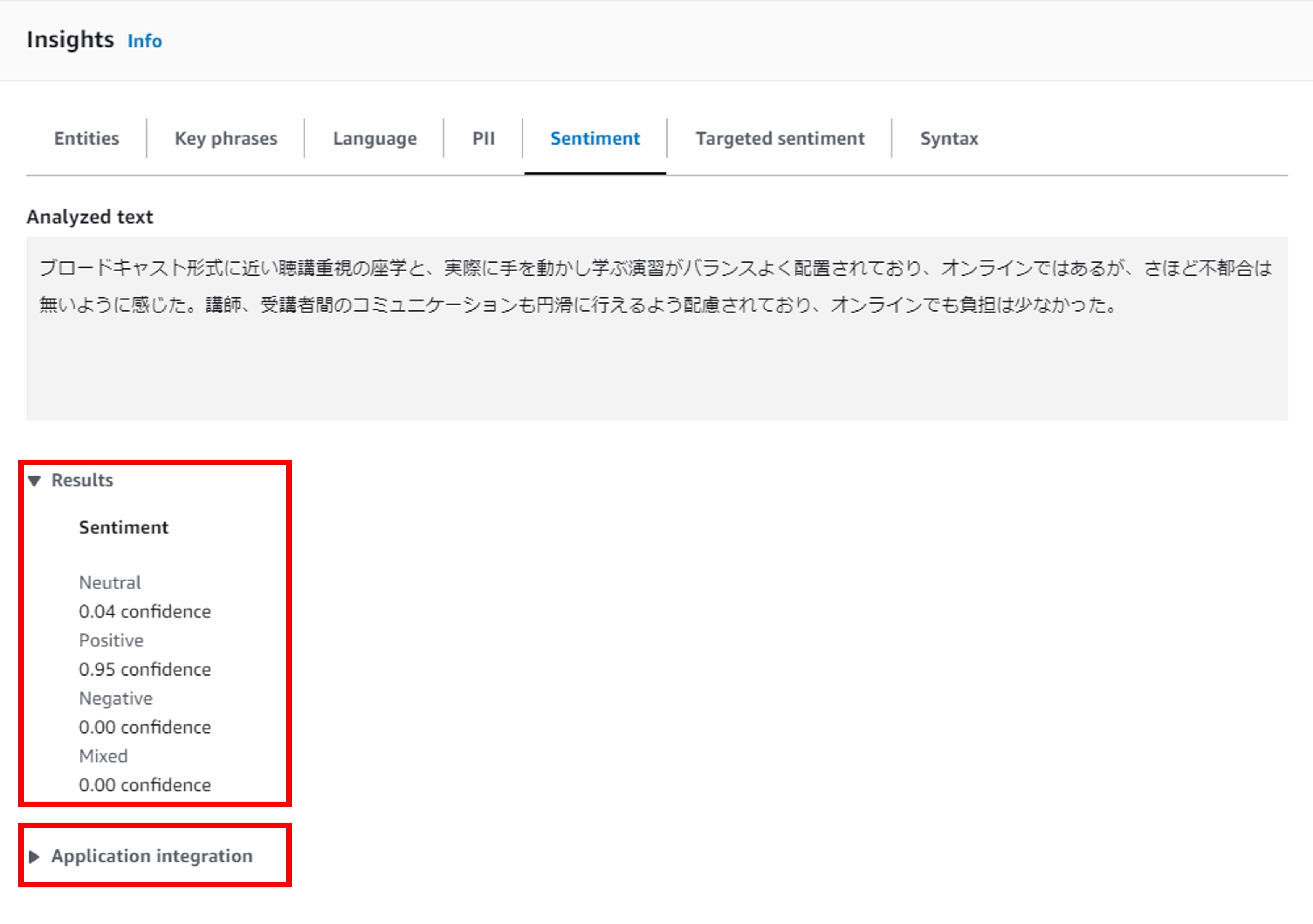
なお、Amazon Comprehendでは、Application Configurationの部分から、分析結果のAPI Responseを確認できます。以下が上記分析結果のAPI Responseです。API Responseでは文章の感情も返されており、4つの観点のうち最も高い信頼度のものを、そのテキストの感情としているようです。
{
"Sentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Positive": 0.9511463642120361,
"Negative": 0.0002689941902644932,
"Neutral": 0.047865722328424454,
"Mixed": 0.0007189100724644959
}
}
}
ジョブ分析
#次に、ジョブ分析を試してみたいと思います。
ジョブ分析は、S3のバケットにあるテキストを取得し、分析結果をS3バケットに吐き出す仕組みになっています。
また、一度に複数のテキストを非同期で分析可能です。つまり、分析結果が得られるまでに少々待ち時間が発生します。
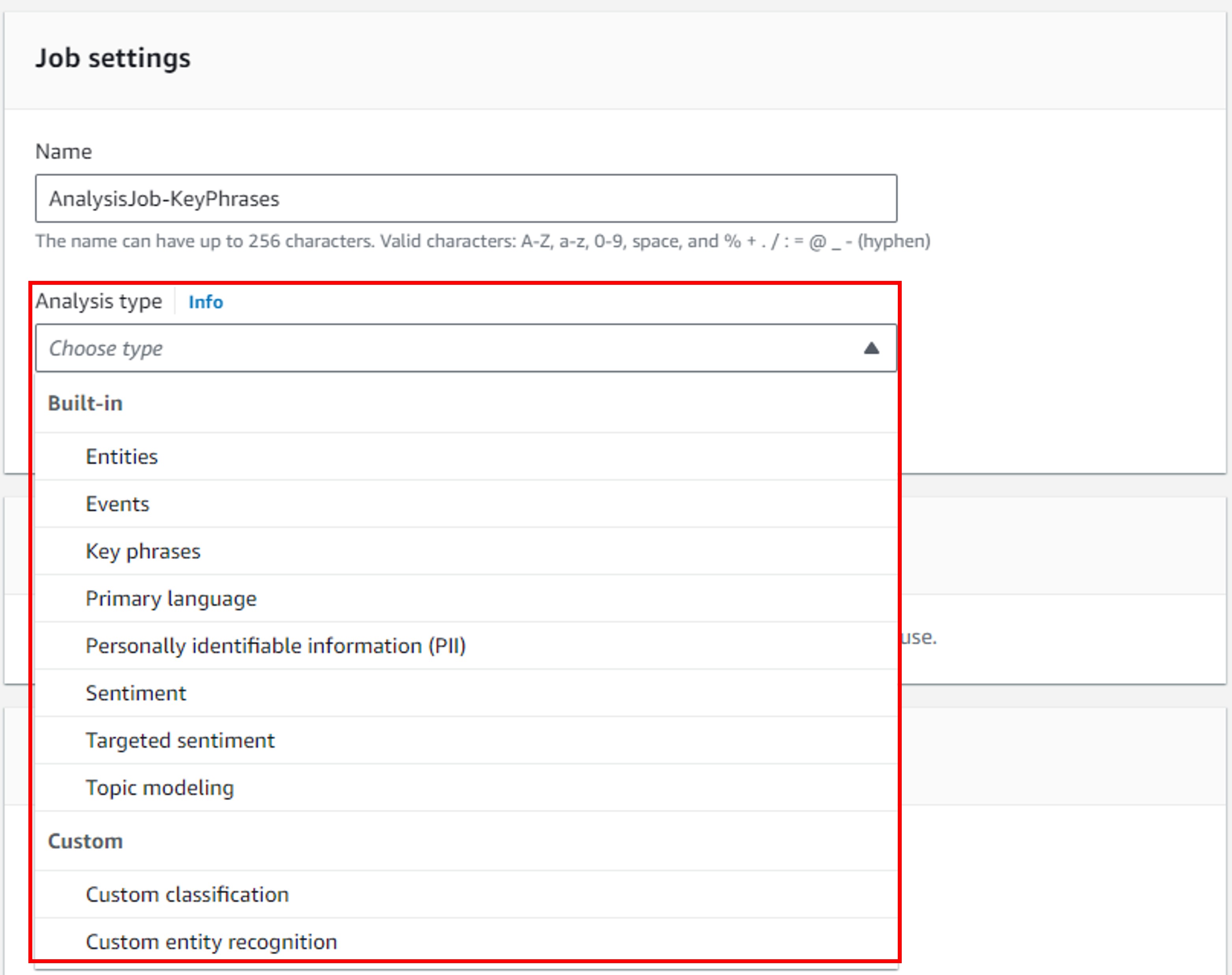
ジョブ分析にはまず、ジョブを作成する必要があります。最初にJobの名前と分析タイプ(=インサイト)を設定します。どうやら、ジョブ分析ではリアルタイム分析のように複数のインサイトを同時に分析はできず、単一のインサイト分析のみに対応しているようです。もし、複数のインサイトを分析する場合は、ジョブを複数用意する必要がありそうです。ちなみに、画像にはありませんが、分析タイプを選択した後は、言語を選択する必要があります。
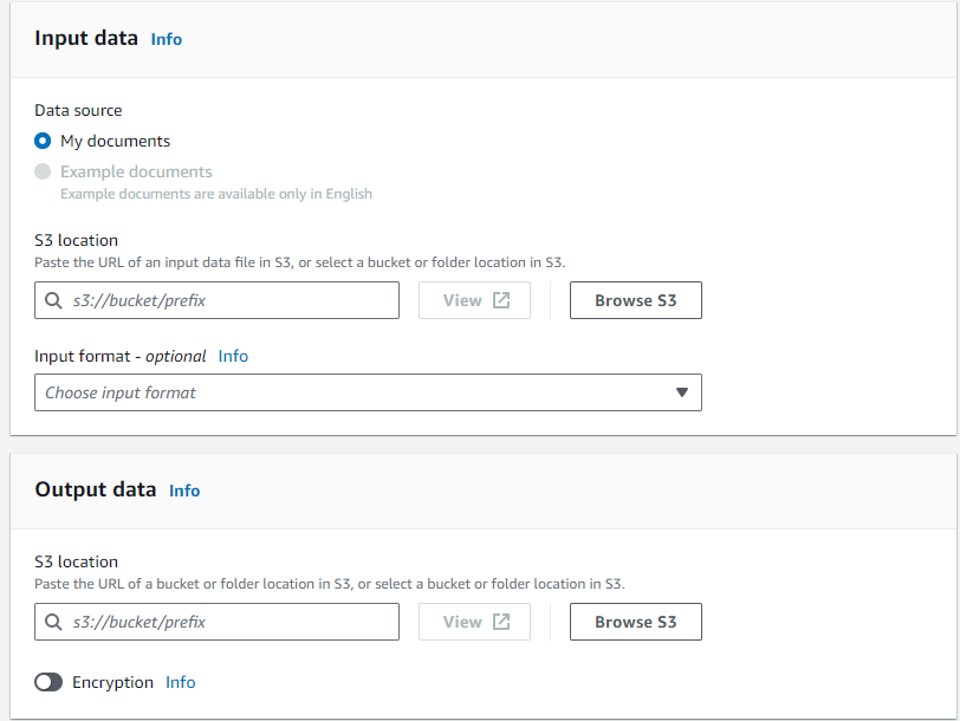
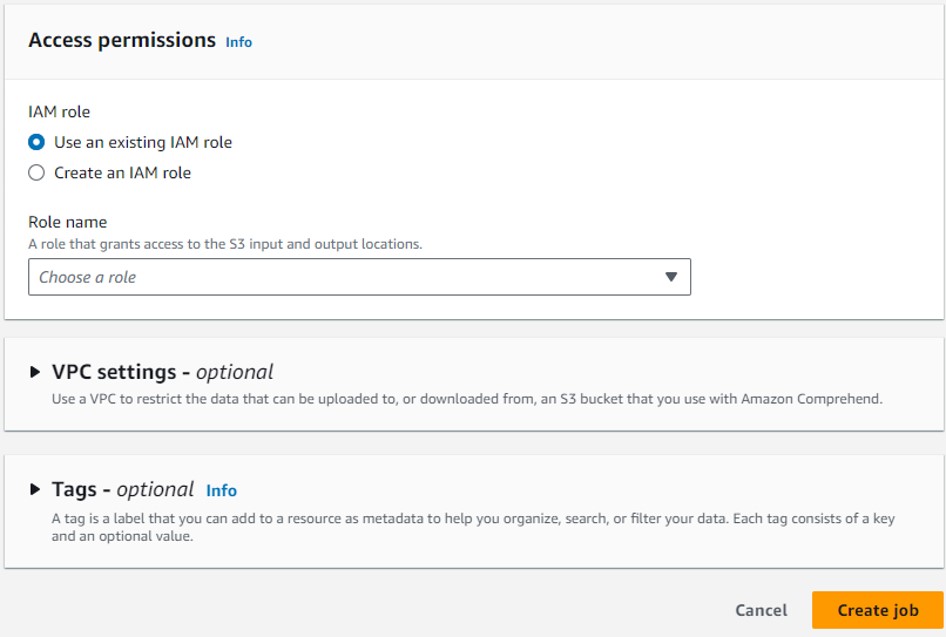
次に、入力データと出力データのS3バケットの場所、使用するIAMロールを設定します。IAMロールは、S3へのアクセス権が必要になります。諸々設定が終わって「Create job」をクリックすると、Jobが作成されて分析がスタートします。
ジョブ分析では、リアルタイム分析のときと同様に、実際の新人教育で実施した「オンライン研修の良かった点についてご記入ください。」というアンケートの自由記述回答を利用しました。ただし今回はジョブ分析で複数テキストの分析が可能なため、93名分の回答を利用しました。ちなみに、今回ジョブのインプットデータの設定で「One document per line」としました。言葉通り、ファイルの1行が1つのドキュメントとなり、今回のケースでは受講者のアンケート回答ということになります。以下にファイルの冒頭部分のみ示します。
オンライン研修でも出社でも結局zoomに繋いでの研修であれば、オンラインで十分のような気がした。
自分にとってもっとも研修の受けやすい環境で受講することができた。
通勤時間や昼休みの時間を自分の時間として活用できる点。
出社しなくてもクオリティの高い研修を受けられたため。満足です。
体力的な負担が少ない。休憩中に出社時よりリラックスできる。
(以下略)
エンティティ
エンティティ分析ですが、エンティティとして抽出されたものは件数としては少なかったです。以下に抽出されたすべてのエンティティ、エンティティの分類、信頼度[1]を示します。
| エンティティ | 分類 | 信頼度 |
|---|---|---|
| 十分 | QUANTITY | 0.988 |
| 朝 | DATE | 0.785 |
| 日経新聞 | TITLE | 0.842 |
| 毎日 | QUANTITY | 0.838 |
| 1対 | QUANTITY | 0.774 |
| 1 | QUANTITY | 0.395 |
| たくさんの講師の方 | QUANTITY | 0.790 |
| 少なく | QUANTITY | 0.559 |
| 一人 | QUANTITY | 0.995 |
| 多く | QUANTITY | 0.545 |
こうしてみると、「日経新聞」はまさにエンティティと言えそうです。それ以外のものは、数量(QUANTITY)として認識されるものが多かったようです。ちなみに、「1対」と「1」は元々は「1対1」だったのですが、2つのエンティティとして抽出されてしまっています。
エンティティの分析結果を見ても、アンケートの回答の傾向はまったく読めないですね。
キーフレーズ
次に、キーフレーズの分析結果です。
以下のように、各ドキュメントに対してのキーフレーズの抽出結果がjson形式で出力されます。件数が多いので、ここでは2件の回答に対するキーフレーズの分析結果を示しています。
{
"File": "online_merit.csv",
"KeyPhrases": [
{
"BeginOffset": 0,
"EndOffset": 2,
"Score": 0.999968291333751,
"Text": "自分"
},
{
"BeginOffset": 10,
"EndOffset": 12,
"Score": 0.9918037877845982,
"Text": "研修"
},
{
"BeginOffset": 18,
"EndOffset": 20,
"Score": 0.9935752743394948,
"Text": "環境"
}
],
"Line": 1
}
{
"File": "online_merit.csv",
"KeyPhrases": [
{
"BeginOffset": 4,
"EndOffset": 6,
"Score": 0.9998228863691635,
"Text": "負担"
},
{
"BeginOffset": 11,
"EndOffset": 14,
"Score": 0.9999080415884348,
"Text": "休憩中"
},
{
"BeginOffset": 15,
"EndOffset": 18,
"Score": 0.9760368805671474,
"Text": "出社時"
}
],
"Line": 4
}
1つ目の回答については、「自分」「研修」「環境」の3つを抽出しています。今回のアンケートの質問は「オンライン研修の良かった点についてご記入ください。」です。「環境」というキーフレーズがあるため環境面が良かったのかなと想像はできそうです。
2つ目の回答については、「負担」「休憩中」「出社時」の3つを抽出しています。こちらは、キーフレーズからはどのような回答だったかはちょっと推測しずらいです。この回答は「体力的な負担が少ない。休憩中に出社時よりリラックスできる。」でした。「体力的な」や「リラックス」もキーフレーズとして抽出されないとちょっと辛いものがあります。
ちなみに、先ほどのエンティティの分析もそうだったのですが、ジョブ分析の出力はjson形式ですが、tar.gz形式で圧縮されている上にファイル拡張子がなく、その上unicodeで出力されているため、結果を確認するには少々手間がかかります…。
センチメント
センチメント分析ですが、こちらは集計した結果のみ示します。
質問自体は「オンライン研修の良かった点についてご記入ください。」なので、ポジティブな面を回答してもらう想定の質問ですが、NeutralやNegativeと判断された回答がかなり多くなっています。
理由はよくわかりませんが、質問で良かった点を回答するように限定すると、単純に事実を列挙するような形の回答になりがちであること。また、回答が短すぎるためセンチメント分析が上手くできていないことが原因なのかもしれません。
| センチメント | 回答数 |
|---|---|
| Positive | 50(54%) |
| Neutral | 39(42%) |
| Negative | 4(4%) |
| Mixed | 0 |
おわりに
#結局のところ、Amazon Comprehendで日本語の自由記述アンケート分析はまだ難しいのかなという感じがしました。
理由としては、アンケート解析に有効であると考えられる機能が日本語非対応であることです。日本語に対応した機能のみでは、アンケート分析としてはイマイチな印象です。
AWSのドキュメント[2]の中に、日本語非対応の機能について「Doesn't support character-based languages such as Chinese, Japanese, and Korean.」という記述がありました。character-based languageは日本語では「表語文字[3]」というそうです。英語の場合は文字(アルファベット)は音素や音節を表しており語句の意味は表現しないのに対して、漢字の場合は、漢字そのものが語や意味を表すことになる点が、どうやら自然言語処理する上で難関となるようです。
AmazonにはAmazon Traslateという翻訳サービスもあり、日本語を英語に翻訳してAmazon Comprehendを利用する方法もあるかと思います。しかし、試してみたところ日本語の翻訳精度は微妙なので、Amazon Comprehendに翻訳結果を投入するのは得策ではありません(もし、英語に翻訳する場合はDeepLの方が高精度なので、DeepLで翻訳した結果をAmazon Comprehendに投入する方がまだ良さそうです)。
とはいえ、今後Amazon Comprehendが日本語にもフル対応ということになれば改めて検討する余地はありますし、AWSであれば別方法(例えば、自前で作ったアンケート分析用スクリプトを移植して、アンケート分析を半自動化する)も模索できそうです。余裕があればそちらにもトライしてみたいと思います。
桁数が多くなるため小数点第四位を四捨五入 ↩︎