CRaCによるJavaの高速化
Back to Topこれは、豆蔵デベロッパーサイトアドベントカレンダー2022第2日目の記事です。
先日、JavaのLambda関数の起動を高速化するLambda SnapStartがAWSから発表されましたが、このLambda SnapStartにはJavaのCRaC(Coordinated Restore at Checkpoint)が使われています。
CRaCは起動の高速化と即時にピーク性能を発揮させる技術です。CRaCが登場した背景にはJavaの起動の遅さがあります。この弱点を補う技術としてはGraalVMによるネイティイメージが有名ですが、CRaCはこの弱点を補うもう一つの高速化手段として今注目を集めている技術です。今回はこのCRaCの概要や仕組み、その試し方などを紹介します。
はじめにいっておきますが、CRaCスゴイです。ホントに爆速になりますヨ!
CRaCとは
#最初にCRaCとはなにかですが、ごく簡単に説明すると、CRaCは起動中のある時点(チェックポイント)におけるJavaのプロセスイメージを丸々スナップショットとして取得し、そのスナップショットからJavaプロセスを復元開始する仕組みとなります。
Javaは起動時に多数のクラスローディングが行われることに加え、起動時はJITによるネイティブコンパイルが行われていないため処理に時間が掛かります。しかし、その後はコードが動作していくにつれ、多くのクラスがローディング済みとなり、かつJITも効いてくる[1]ことで、処理が高速化していく特性があります。
CRaCはJavaの弱点ともいえるこの特性を逆手に取った技術といえます。Javaは起動が遅い代わりにある程度動作すると高速化するため、その高速化した状態のプロセスイメージを使ってプロセスを再開することで、起動時のクラスローディングをショートカットし、JITが効いた美味しい状態から起動を開始しようというものとなります。
実際にCRaCの効果は強力です。特に起動時間の短縮効果はハッキリと表れます。下はCRaCプロジェクトで公表されているデータですが、モノによっては100倍近く起動が高速化されるのが分かります。
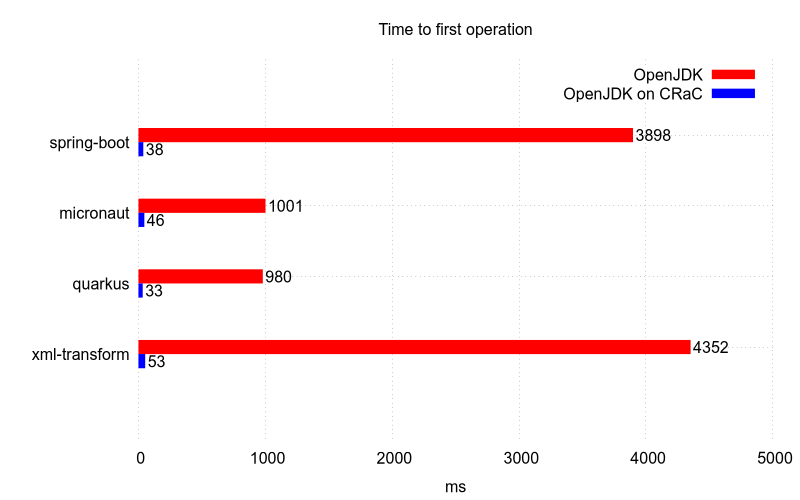
引用元: Github - CRaC/docs Time to first operation
グラフはSpring Boot, Micronaut, Quarkusを使ったサンプルアプリの起動時間と初回のxml変換処理(xml-transform)に掛かる時間を通常(OpenJDK)とCRaC(OpenJDK on CRaC)とで計測した結果となります。いずれも秒単位だったものが数十ミリ秒と劇的に速くなっています。また、xml変換処理時間は1回目の処理からピーク性能がでているため、起動直後からJITが効いている状態になっていると推測できます。
当事者から発表されるデータはある程度割り引いてみる必要がありますが、この結果は恐らく自分たちのアプリに適用した場合にもほぼそのまま当てはまると思っています。それは、後述のHelidonで効果を確認してみるで詳細は触れますが、筆者が実際に自分のサンプルアプリで試した結果、手間を掛けることなくほぼ同様な結果がでたからです。数秒掛かっていた起動が一瞬で起動するようになりました。
ここで説明したようなCRaCの詳細については、CRaCのプロジェクトページに分かりやすくまとめられています。
CRaCの実装
#CRaCはチェックポイント[2]の取得と復元を行うLinuxのCRIU(Checkpoint/Restore In Userspace)をベースにJava向けに使いやすくした、OpenJDKプロジェクトで開発が進められているJVM(HotSpot VM)の機能となります。
上述のとおり、その動作にはLinuxカーネルの機能を使っているためホストOSとしてLinuxが必要となります。また、開発中のため正式リリースのJDKには含まれていません。このため、試すにはCRaCプロジェクトのGitHubからEAビルド(Early-Access Builds)を入手する必要があります。(じゃ、Lambda SnapStartはなんなんだというのは後述)
CRaCがベースにしているCRUIはカーネルレベルのサポートが必要となるため、コンテナが利用するLinuxカーネルがCRUIをサポートしている必要があります。これはLinuxの動作環境が必要といった場合、多くはホストOSがなにかを気にすることはないですが、CRaCをコンテナで使う場合はこれを気にする必要があることを意味します。
実際に筆者は最初、WindowsのHyper-V + Docker Desktopで検証をしていましたが、この環境でCRaCはうまく動作しませんでした。恐らくHyper-V上で動作するDocker DesktopのLinuxカーネルがCRUIをサポートしていなかったためと思われます[3]。ですので、CRaCをコンテナ環境で試す場合はこの点に注意が必要です。また、この理屈からいくと、恐らくDocker Desktop for Macも動作しないのではないかと思います。
CRaCの利用例
#OpenJDKのCRaCは開発中のため商用環境で利用することはまだできませんが、ここではCRaCの技術が使われているプロダクトの例を2つ紹介します。この2つの例からCRaCが技術的にはプロダクションレディで今後色々なところで使われていく可能性を感じます。
AWS Lambda SnapStartの例
#1つ目は冒頭でも触れたAWSのLambda SnapStartの例です。Lambda SnapStartの具体的な仕組みは公式ページでもあまり触れられていませんが、こちらのブログで次のようにサラッとCRaCだということをいっています。(後段はGoogle機械翻訳)
The Java managed runtime uses the open-source Coordinated Restore at Checkpoint (CRaC) project to provide hook support.
Java マネージド ランタイムは、オープンソースのCoordinated Restore at Checkpoint (CRaC) プロジェクトを使用して、フック サポートを提供します。
AWSはLambdaで使われているJavaランタイム(Corretto11)に対し、AWSが独自にCRaCの成果をアドオンしてLambda SnapStartを実現しているものと思われます。ですので、このLambda SnapStartはCRaCをプロダクトレベルで使った初めての例になると思います。
細かい仕組みはさておき、AWSのブログの中ではコールドスタートの所要時間を6秒以上から200ミリ秒未満へ短縮したとの説明があるため、JavaによるAWS Lambdaの銀の弾丸になる感じがします。
Serverless Frameworkを使って実際にLambda SnapStartを試した記事を本サイトの以下で紹介しています。興味のある方は是非ご参照ください。
Open Liberty InstantOnの例
#Open LibertyはIBMがオープンソースで開発を行っているJakartaEEのアプリケーションサーバーです。アプリケーションサーバーの起動には時間が掛かるため、これをそのままクラウドネイティブな環境で使うには問題がありました。そこでIBMが考えたのがチェックポイントを使った起動の高速化です。
Open Liberty InstantOnを説明したこちらのブログでは次のように仕組みが説明されています。(後段はGoogle機械翻訳)
To enable InstantOn, Open Liberty uses new features of the OpenJ9 JVM and a Linux technology called Checkpoint/Restore In Userspace CRIU to take a checkpoint of the application process as it starts.
InstantOn を有効にするために、Open Liberty はOpenJ9 JVM の新機能と、Checkpoint/Restore In Userspace CRIUと呼ばれる Linux テクノロジーを使用して、アプリケーション プロセスの開始時にチェックポイントを取得します。
OpenJ9はIBMがオープンソースで開発を行っているJVMで語弊は少しありますが、一言でいうとIBM版のHotSpot VMです。ブログの説明からIBMはCRaCプロジェクトと同様な独自の機能を開発し、それをIBMがもつ独自のOpenJ9に搭載し、OpenLibertyと組み合わせることで登場したのがOpen Liberty InstantOnといえます。
なお、現時点でのOpen Liberty InstantOnの最新はベータ版でまだ正式リリースはされていません。また、先ほどのブログには動作環境としてカーネルのLinux CAP_CHECKPOINT_RESTORE機能が必須で、InstantOnのテストはまだRHEL 8.6 および RHEL 9.0でしかされていないことが書かれています。よって、商用環境で利用できるにようになるには未だ時間が掛かりそうですが、起動時間を最大90%削減可能とあるため、こちらも今後に期待したい機能といえます。
CRaCを試してみる
#ここからはCRaCを実際に使って、その仕組みや効果を確認していきます。それにはまずLinux環境とCRaCが組み込まれたOpenJDKのEAバイナリが必要です。今回はCRaCの実行環境としてAmazon Linux2(EC2)上でDockerコンテナを使っていきます。
CRaCを使う場合、カーネルがCRUIに対応している必要がありますが、この確認は難しいのでubuntuのようなホストOSでも利用されるメジャーなディストリビューションを使っておくのが無難です。ほぼホボ対応していると思います。
なお、記事はサンプルアプリの必要な部分の抜粋を記載します。全量を確認したい、または動作をさせてみたい方は説明に使用したコードを一式GitHubリポジトリにアップしていますので、そちらを参考にしてください。
Javaの実行環境の準備
#まずJavaの実行環境として次のDockerfileを用意します。
FROM ubuntu:18.04
RUN apt-get -y update
RUN apt-get -y upgrade
RUN apt-get -y install curl
RUN curl -sL \
https://github.com/CRaC/openjdk-builds/releases/download/17-crac%2B3/openjdk-17-crac+3_linux-x64.tar.gz | \
tar zx -C /opt
ENV JAVA_HOME /opt/openjdk-17-crac+3_linux-x64
ENV PATH $PATH:$JAVA_HOME/bin
コンテナに入って操作することが多いためubuntuをベースイメージに使っていますが、使われるカーネル機能はホストOS側でCRaCの動作には関係ないため、alpineなど好みで変えても問題ありません(試してはいませんが)
次にcurlコマンドで取得しているのが、CRaCが組み込まれたOpenJDKのEAビルド(CRaC-JDK)となります。とりあえず最新のビルドを使っておくのが無難です。
Dockerfileをビルドして準備は完了です。
sudo docker build -t jdk-crac .
基本的な動作を理解する
#CRaCの仕組みを理解するため、高速化の効果などはまずは置いておき、簡単なアプリを題材にチェックポイントの取得とリストアを行い状態が復元されることをみていきます。
題材として次のアプリを用意しました。内容は無限ループの中で1秒間スリープし、スリープした回数をコンソールに出力するといった簡単なものです。
public class LoopCounterMain {
public static void main(String[] args) throws Exception {
new LoopCounter().start();
}
private static class LoopCounter {
private int time;
private void start() throws Exception {
while (true) {
Thread.sleep(1000L);
System.out.println("count:" + ++time);
}
}
}
}
このコードをホストOS側でビルド[4]し、結果をjavaコマンドから実行可能なexecutable jar(loop-counter.jar)形式にしてtargetディレクトリに出力しています。
今回はホストOS側でビルドしたloop-counter.jarの格納ディレクトリ(target)をコンテナ側でマウントし、チェックポイントの取得と復元はコンテナ内で行うようにします。
ということで、まずはJavaの実行環境の準備で準備したコンテナイメージを使ってコンテナの中に入ります。この際、CRaCの利用には強い権限が必要なため--privilegedオプションが必要です。これを忘れるとまともに動かずハマるので注意しましょう。
sudo docker run \
-it --name jdk-crac --rm \
-v /path/to/your/target:/target \
--privileged \
jdk-crac bash
コンテナ内に入ったらjavaコマンドで題材のアプリを起動します。ここでのポイントは-XX:CRaCCheckpointTo=PATHオプションです。この指定によりCRaC機能が有効になります。またPATHにはチェックポイントのイメージを格納するディレクトリを指定します。次の例ではカレントのcrディレクトリを指定しています。
java -XX:CRaCCheckpointTo=cr -jar target/loop-counter.jar
count:1
count:2
count:3
...
アプリが起動すると上記のように1秒間ごとにカウントアップされた結果がコンソールに出力されていきます。
この出力が確認できたら次は別のコンソールから先ほどのコンテナに入りチェックポイントを取得します。
docker exec -it jdk-crac bash
コンテナに入ったら今度はjcmdコマンドでJVMにチェックポイントの取得を指示します。jcmdはJVMプロセスに対してイベントを送信するコマンドでこれはCRaCには関係なくJava標準のものとなります。そしてjcmdの第2引数で渡しているJDK.checkpointがCRaCが定義しているチェックポイントイベントになります。
jcmd target/loop-counter.jar JDK.checkpoint
11:
Command executed successfully
コマンドを実行すると起動していたJavaアプリは次のようなメッセージを出力し、crディレクトリにチェックポイントを出力した後、Javaプロセスを終了します。
count:3
...
count:64
CR: Checkpoint ...
Killed
crディレクトリには次のようにプロセスのイメージファイルが出力されているのが確認できます。
ls cr/
core-11.img core-15.img core-19.img core-23.img cppath fs-11.img pagemap-11.img seccomp.img
core-12.img core-16.img core-20.img core-24.img dump4.log ids-11.img pages-1.img stats-dump
core-13.img core-17.img core-21.img core-48.img fdinfo-2.img inventory.img perfdata timens-0.img
core-14.img core-18.img core-22.img core-49.img files.img mm-11.img pstree.img tty-info.img
これでチェックポイントが取得できました。今はJavaプロセスが終了している状態のため、このチェックポイントを使ってJavaプロセスを再開します。Javaプロセスの再開、つまりプロセスのリストアは-XX:CRaCRestoreFrom=PATHオプションで行います。これによりPATHで指定されたチェックポイントからJavaプロセスが再開します。
java -XX:CRaCRestoreFrom=cr
count:65
count:66
...
実行結果をみるとcountは65から始まっています。チェックポイント取得時は64だったのでJavaのプロセスが確かに復元されていることが分かります。
CRaCのAPIを使ってイベントをフックする
#CRaCの基本的な動作をみたところで今度はイベントフックの方法をみていきます。
チェックポイントを取得するとJavaプロセスが終了するため、アプリによっては終了する前に後処理を行いたい場合があります。また、これと同じようにリストアはアプリの起動に相当するため、アプリによっては初期処理を行いたい場合もあります。
このような場合はCRaCのResourceインタフェースを使ってイベントをフックすることができます。この実装は次のようになります。
import org.crac.Context;
import org.crac.Core;
import org.crac.Resource;
public class LoopCounterMain {
...
private static class LoopCounter implements Resource {
private int time;
private LoopCounter() {
Core.getGlobalContext().register(this);
}
private void start() throws Exception {
...
}
// --- implements Resource interface
@Override
public void beforeCheckpoint(Context<? extends Resource> context) throws Exception {
System.out.println("***** call beforeCheckpoint *****");
}
@Override
public void afterRestore(Context<? extends Resource> context) throws Exception {
System.out.println("***** call afterRestore *****");
}
}
}
CRaC APIを実装することで、チェックポイントイベントが発行された際にJVMからbeforeCheckpointメソッドにコールバックが掛かるようになります。同じようにチェックポイントのリストア終了後、つまり、Javaプロセス起動後にはafterRestoreメソッドにコールバックが掛けられます。よって、Resourceインタフェースを実装することで、それぞれのイベント時に任意のアプリ処理を実行させることが可能となります。ただし、JVMからのコールバックを受けるにはコード例のようにCRaCのグローバルコンテキストにResourceインスタンスを登録する必要があるので忘れずにこれも実装します。
このコードを先ほどの基本動作と同じ手順で動作させた場合、チェックポイント取得時とリストア時に次のコンソールメッセージが出力されるようになります。
(チェックポイント時)
...
count:64
***** call beforeCheckpoint *****
CR: Checkpoint ...
Killed
(リストア時)
...
count:65
***** call afterRestore *****
count:66
count:67
count:68
CRaC-JDKに組み込まれてるCRaC APIのパッケージはjdk.cracですが、コード例をみるとCoreクラスとResourceインタフェースのコード上のパッケージはorg.cracになっています。これはEAビルドにしか含まれていないjdk.cracパッケージにコードを直接依存させるとコンパイルできる環境が限定され不便なため、その代替として提供される下記のライブラリのパッケージとなります。
<dependency>
<groupId>io.github.crac</groupId>
<artifactId>org-crac</artifactId>
<version>0.1.3</version>
</dependency>
このライブラリはCRaC機能が有効なランタイム環境ではすべての呼び出しをjdk.cracへ委譲し、反対にCRaC機能が無効な環境ではなにも行わない実装となっています。これにより、CRaC機能がない環境でもCRaC APIへの呼び出しが無視されるだけで、その他は問題なく動作させることができるようになります。
Helidonで効果を確認してみる
#上の2つは簡単なごく小さいアプリのため、その速度の違いを感じることができませんでした。このため、最後にMicroProfileフレームワークのHelidonを使ってその高速化効果を確認してみます。
起動するサンプルには次の簡単なRESTアプリを使います。ただし、起動に時間が掛かるようにHelidonが持つすべての機能を有効化した重量級の設定で起動するようにしています。
@ApplicationScoped
@Path("persons")
public class PersonResource {
private Map<Long, Person> personMap = new ConcurrentHashMap<>();
@PostConstruct
public void init() {
personMap.put(1L, new Person(1L, "taro", 12));
personMap.put(2L, new Person(2L, "hanko", 9));
personMap.put(3L, new Person(3L, "bob", 15));
}
@GET
@Produces(MediaType.APPLICATION_JSON)
public List<Person> getAll(@Context SecurityContext context) {
return personMap.values().stream()
.collect(Collectors.toList());
}
}
基本動作で使ったサンプルでは問題にはなりませんでしたが、チェックポイントの取得には注意すべき点があります。それはファイルやソケットなどオープンされたシステムリソースはチェックポイントに含められないことです[5]。これは、これらのシステムリソースはリストアすることができないためです。
CRaCランタイムはチェックポイント取得時、オープン中のリソースがある場合、チェックポイントの取得を中断し例外を送出します。このため、Helidonのようなサーバーアプリケーションではチェックポイントが取得される前にソケットをcloseし、再開時にopenする処理が必要となります。
そこで登場するのが先ほどのResourceインタフェースです。beforeCheckpointメソッドでリソースのcloseや後処理をafterRestoreメソッドではリソースのopenや初期化処理などを行うようにします。
このResourceインタフェースをHelidonに適用してみた例を紹介します。
なお、Helidonには利用者側でサーバー機能だけを起動、停止する適当な拡張ポイントがないため、サーバー機能の起動、停止を行っているHelidonのServerCdiExtensionのコードを直接修正しています。したがって、ここで紹介する例はあまり行儀がよくないやり方ですので、良い子の皆さんはプロダクトコードで真似をしないでください。
ServerCdiExtensionの修正コードは次のようになります。
public class ServerCdiExtension implements Extension, Resource {
...
// ダミースレッドを保持するフィールドを追加
private Thread preventExitThread;
...
private void prepareRuntime(@Observes @RuntimeStart Config config) {
...
// 起動時に実行される既存のメソッドに↓のContext登録の処理を追加↓
System.out.println("***** Resource Regstered *****");
Core.getGlobalContext().register(this);
preventExitThread = new Thread(() -> {
while (true) {
try {
Thread.sleep(1_000_000);
} catch (InterruptedException e) {
}
}
});
preventExitThread.start();
}
// Resourceインタフェースの実装を追加
@Override
public void beforeCheckpoint(org.crac.Context<? extends Resource> context) throws Exception {
// 既存のサーバ停止メソッドを使ってサーバ機能のみ停止
System.out.println("***** invoke beforeCheckpoint *****");
this.stopServer(null);
}
// Resourceインタフェースの実装を追加
@Override
public void afterRestore(org.crac.Context<? extends Resource> context) throws Exception {
// 既存のサーバ起動処理をコピーして一部改変
System.out.println("***** invoke afterRestore *****");
var startTime = System.currentTimeMillis();
webserver = serverBuilder.build();
try {
webserver.start().toCompletableFuture().get();
started = true;
} catch (Exception e) {
throw new DeploymentException("Failed to start webserver", e);
}
this.port = webserver.port();
LOGGER.info(() -> "Server restored in "
+ (System.currentTimeMillis() - startTime) + " milliseconds (since JVM afterRestore).");
}
...
ServerCdiExtensionでResourceインタフェースをimplementsし、beforeCheckpointメソッドでサーバー機能(webserver)だけを停止し、afterRestoreメソッドで新たなサーバー機能を生成し起動するようにしています。
また、CRaCへのResourceインスタンスの登録はコンテナ起動時に呼び出されるprepareRuntimeメソッドで行っています。prepareRuntimeメソッドではこの他にもダミースレッドをフィールド(preventExitThread)に非保持しつづけることで、JVMがチェックポイントを取得する前にプロセス全体が終了することを防ぐようにしています。
この改造ServerCdiExtensionを使って、通常の方法で起動した場合とチェックポイントを使ってリストア起動した場合の実行結果が次のとおりです。
(通常起動時のコンソール出力) ※見やすいように一部改行を入れています
2022-12-01 23:13:31,541 [INFO ] [i.h.c.LogConfig] [main] - Logging at initialization configured using defaults
2022-12-01 23:13:31,633 [INFO ] [o.j.w.Version] [main] - WELD-000900: 4.0.2 (Final)
....
2022-12-01 23:13:37,921 [INFO ] [i.h.m.s.ServerCdiExtension] [main] -
Server started on http://localhost:7001 (and all other host addresses)
in 7517 milliseconds (since JVM startup).
2022-12-01 23:13:38,459 [INFO ] [i.h.c.HelidonFeatures] [features-thread] - Helidon MP 3.0.2 features: [CDI, Config, Fault Tolerance, Health, JAX-RS, Metrics, Open API, REST Client, Security, Server, Tracing]
Server started on ...のメッセージから起動に掛かった時間は7,517mミリ秒(約7.5秒)と分かります。
(リストア起動時のコンソール出力) ※見やすいように一部改行を入れています
java -XX:CRaCRestoreFrom=cr
***** invoke afterRestore *****
2022-12-01 23:16:51,066 [INFO ] [i.h.w.NettyWebServer] [nioEventLoopGroup-4-1] - Channel '@default' started: [id: 0xec206e04, L:/0.0.0.0:7001]
2022-12-01 23:16:51,074 [INFO ] [i.h.m.s.ServerCdiExtension] [Thread-2] -
Server restored in 42 milliseconds (since JVM afterRestore).
Server restored in ...のメッセージから起動に掛かった時間は42mミリ秒(約0.05秒)と分かります。
概ね7秒程度掛かっていた起動が数十ミリ秒とまさに一瞬で起動するようになりました。
さいごに - GraalVMとの比較
#起動を高速化するもう1つの技術としてGraalVMによるネイティブイメージがあります。HelidonもQuarkusと同様にネイティブイメージをかなり前からサポートしているため、筆者も何度かネイティブイメージにチャレンジしたことがあります。そこで最後のまとめとして、GraalVMとCRaCの比較をしてみたいと思います。なお、この比較は筆者の独断と偏見と私見が入った個人の感想に近いものとなるため、参考程度でみてください。
- 起動速度
- GraalVMのネイティブイメージとCRaCのリストア起動のどちらも1秒以下で起動するため体感的には同じ。どちらも十分速い!
- ただし、ネイティブイメージはモノによって起動時間が100~数10ミリ秒と変わるような感じがあるのに対して、CRaCのリストア起動はCRaCプロジェクトの公式データや今回の実験が示すようにモノによらず起動時間は数10ミリ秒と安定しているように思われる
- ピーク性能
- GraalVMのネイティブイメージは事前コンパイル(AOT)のため実行中にその特性に応じた最適化は行われない
- CRaCのリストア起動はJITが効いた状態でチェックチェックポイントを取得することで起動直後からAOTを上回る性能を発揮することが可能
- よって、上手く使えばCRaCの方がピーク性能が良いといえる
- しかし、ネイティブイメージは常に一定の性能を得られるのに対して、CRaCは例えばチェックポイントを取得した環境よりもメモリが少ない環境でリストア起動した場合、つまり実行時特性が変わった場合、どのような結果になるのかは不明(なんとなくマイナスに作用するが気がする)
- メモリ消費
- これは明らかにGraalVMのネイティブイメージの方が圧倒的に少ないメモリで動作させることが可能
- CRaCのリストア起動はプロセスを丸々復元する。元となるプロセスは通常のJavaプロセスのため、通常のJava vs GraalVMのネイティブイメージと全く同じとなる
- 制約
- GraalVM
- ネイティブ化する対象にリフレクションが使われている場合、基本ネイティブイメージ化は行えない。フィルターを使うなどの回避策はあるとしても難しくて使えるものではない(少なくとも筆者にはムリ)
- フレームワークによってはネイティブイメージ化をサポートするものがあるが、対象は原則そのフレームワークが検証、管理しているものだけ。よって、サポートされていない他のOSSライブラリを使っていて、それにリフレクションが使われていた場合、ネイティブイメージ化はできなくなる(と思った方がよい)
- よって、ネイティブイメージ化がサポートされているフレームワークを使っていれば常に問題なくネイティブイメージ化が出来るという訳ではなく、常に自分たちの依存ライブラリにネティブ化できないものがないかを気にする必要がある
- これとは別にビルドはターゲットCPUの環境で行う必要がある。つまり、Windowsのネイティブイメージを作るにはWindows環境がMacならMac環境をといったようにビルド環境を用意する必要がある
- さらに数十分レベルでビルドに時間が掛かる(なので、ビルドに失敗した場合やビルドのやり直しになった場合の絶望感がハンパない)
- CRaC
- 利用できる環境はLinuxのみ。WindowsやMacでは使えない
- チェックポイント取得時とリストア時に通常の起動/終了処理とは別にシステムリソースに対する処理が必要となる場合がある
- このシステムリソースに対する処理を行う適切な拡張ポイントが利用しているフレームワークやライブラリにない場合、実質的にCRaCを使うことはできないに等しい
- GraalVM
- 利用実績
- GraalVMによるネイティブイメージが大規模に商用利用されているケースは聞いたことがない
- CRaCは独自拡張したものがAWS Lambdaで商用利用されている。また、OpenLibertyにもInstantOnとして同様な機能が搭載される予定
- 標準化
- GraalVM
- CraalVMはOpenJDKプロジェクトに寄贈された。またOpenJDKプロジェクト内にはネイティブコンパイル化を検討するProject Leydenも既にある
- OpenJDKは実質的にJavaの標準化をリードするプロジェクトのため、GraalVMは今後、標準機能となる可能性もある
- CRaC
- OpenJDKの1プロジェクトでまだJEPも出されていない。まだまだコレから
- GraalVM
比較は以上となります。筆者個人としては制約の多いGaalVMによるネイティブコンパイルによる高速化よりも今回のCRaCによる高速化の方が現実的で今後への可能性を感じていることを述べて記事を終わりにします。
参照資料
- CRaC docs: https://github.com/CRaC/docs
- org.crac: https://github.com/CRaC/org.crac
- コンテナ環境でのJava技術の進化: https://speakerdeck.com/kazumura/kontenahuan-jing-denojavaji-shu-nojin-hua
起動直後はコードを逐次解釈していくインタープリタ方式でJavaは動作しますが、高頻度で行われるコードは適宜JITコンパイラによりネイティブコードに変換され、処理が高速化していきます。このようにJITコンパイラによりコードが最適化された状態をよく「JITが効いた状態」や「JITが掛かった状態」などといいます(もしかしたら筆者の周りだけかも知れませんが、、) ↩︎
CRaCのコンテキストでは任意のある時点のプロセスイメージを指します ↩︎
JavaプロセスにCheckpointイベントを送ると、Hyper-V + Docker Desktop上ではなぜか一緒にRestoreイベントも動いてしまい期待どおりに動作しませんでした。しかしこれと全く同じランタイム(jar)をAmazon Linux 2(EC2)のDockerに持って行くと問題なく動いたので、このことからの推測となります。 ↩︎
ホストOS側のビルドに利用するJDKはコンテナ内で動作させるCRaC-JDKでなくても構いません。筆者は別の正式リリース版を使っています。 ↩︎