自然言語処理初心者が「GPT2-japanese」で遊んでみた
Back to Topはじめに
#文章を楽に書きたい。
日常生活でそう思ったことはないでしょうか?
文章を書く機会は社会人だけでなく学生でも多いと思います。
報告書やメール、レポート課題、そして今読んでいるようなブログなどです。
その時に出だしは順調でも途中で詰まったり、表現がわからずにネットで調べたりして、ちっとも進まないということがよくあります。
そういった場合に続きの文章を書いてくれる、もしくは続きの候補を出してくれるシステムがあると非常に便利ですよね?
私もそういう楽をしたいために色々探ってみましたが、どうやら文章自動作成ツールを作るには「自然言語処理」というものを学ぶ必要がありそう……。
しかもそれを学ぶ上では数々の用語や知識が必要でなかなか難しそうでした。
楽になるためにはまずは勉強をしなくてはダメか、と諦めかけていたのですが、ネットの海を漂っていると事前学習済みのモデルがあることがわかりました。
そのひとつが「OpenAI GPT」。
加えてこのモデルには日本語に特化したモデルもあるというではありませんか。
これは利用してみたい!
というわけで今回は、自然言語処理のしの字も知らない素人が「GPT2-japanese」を使って遊んでみました。
詳細な理論や技術的なあれこれは原論文や参考文献に乗せたような他のブログでも記載されているので、
そういうのは他の方に任せて、今回のブログでは初心者を対象に環境構築から使い方とその結果までさらっと紹介します。
まずGPT-2の概略を紹介した後に、今回GPT-2を扱う環境であるGoogle Colaboratoryの新規作成方法と「GPT2-japanese」のインストールについて軽く説明します。
その後にGPT-2による文章作成とファインチューニングのやり方と結果をご紹介します。
「GPT2-japanese」の概要
#GPTとは
#OpenAI GPTとは2018年に下記論文で提案された自然言語処理モデルです。
原論文:Improving Language Understanding by Generative Pre-Training
基本的にはTransformerと呼ばれる自然言語処理の仕組みをベースにし、事前学習やファインチューニングをすることで非常に高い精度で文章を生成してくれます。
現時点ではすでにOpenAI GPT-3が発表されていますが、GPT-2でも高い精度がありフェイクニュースの生成など悪用の危険性が極めて高く、当初はリリースされないという話になるぐらいだったそうです。
GPTの日本語用モデル
#日本語に特化したGPT-2の大規模言語モデルとしてはrinna社が構築した以下のモデルがあります。
- japanese-gpt-1b
- japanese-gpt2-medium
- japanese-gpt2-small
- japanese-gpt2-xsmall
どれもGPT-2を対象に日本語の事前学習をしたモデルとなりますが、パラメータの量や学習したデータ量などが異なります。
特に一番新しいGPT-1bについては以下のデータセットを用いており、GPT2-mediumに使用したデータセットからJapanese C4というデータセットが追加されています。
- Japanese C4
- Japanese CC-100
- Japanese Wikipedia
またパラメータ数(params)もGPT2-mediumの3億強から13億に増えています。
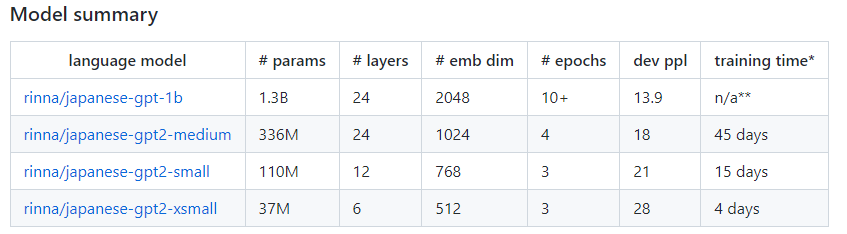
上の表は公式で説明されているModel Summaryです。
GPT-1bのトレーニング時間が「n/a**」となっているのは、データセットや環境が異なるためだそう。
GPT2-mediumとGPT-1bを比較すると、パラメータ量(params)、埋め込みの次元(dim)や学習するエポック数(epochs)がGPT-1bの方が大幅に大きくなっていますが、perplexity(dev ppl)がかなり減少しています。
perplexityは大雑把に言えば、言語モデルの複雑さを表現する指標のことです。
予測した単語が「人間」にとって正しい単語になっている、つまり日本語として自然な文章に近づいていれば、この指標は小さくなります。
GPT2-japaneseで遊んでみる
#実際にGPT2-japaneseを使って遊んでみましょう。
今回は文章生成にGPT-1bを、ファインチューニングにはGPT2-mediumを使用します。
ファインチューニングするにはGPT-1bだと学習時間がかかってしまうので、パラメータ数などがGPT-1bよりも低いGPT2-mediumを使用しています。
それでは環境構築から説明します。
環境構築
#Google Colaboratory上でGPT2-japaneseを使用するので、まずGoogle Colaboratoryの新規作成をします。
Google Colaboratoryの新規作成
#まず大前提ですが、Googleアカウントがないと使えないのでGoogleアカウントは事前に作成しておきましょう。
ここではマイドライブ > Colab上に諸々のフォルダやファイルを作成することを考えます。
(マイドライブでも構いませんが、GPT2をクローンするなどの関係上、フォルダを汚したくない場合は新しくフォルダを作成することをおすすめします。)
マイドライブ > Colab上で右クリックして、その他にカーソルを合わせると、「Google Colaboratory」が出てきますのでそれをクリックすると、新規作成できます。
左上部分にタイトルが記載されていますが、デフォルトでは「Untitled0.ipynb」のようなタイトルになっています。
お好みでタイトルを変更してください。

GPUの設定方法
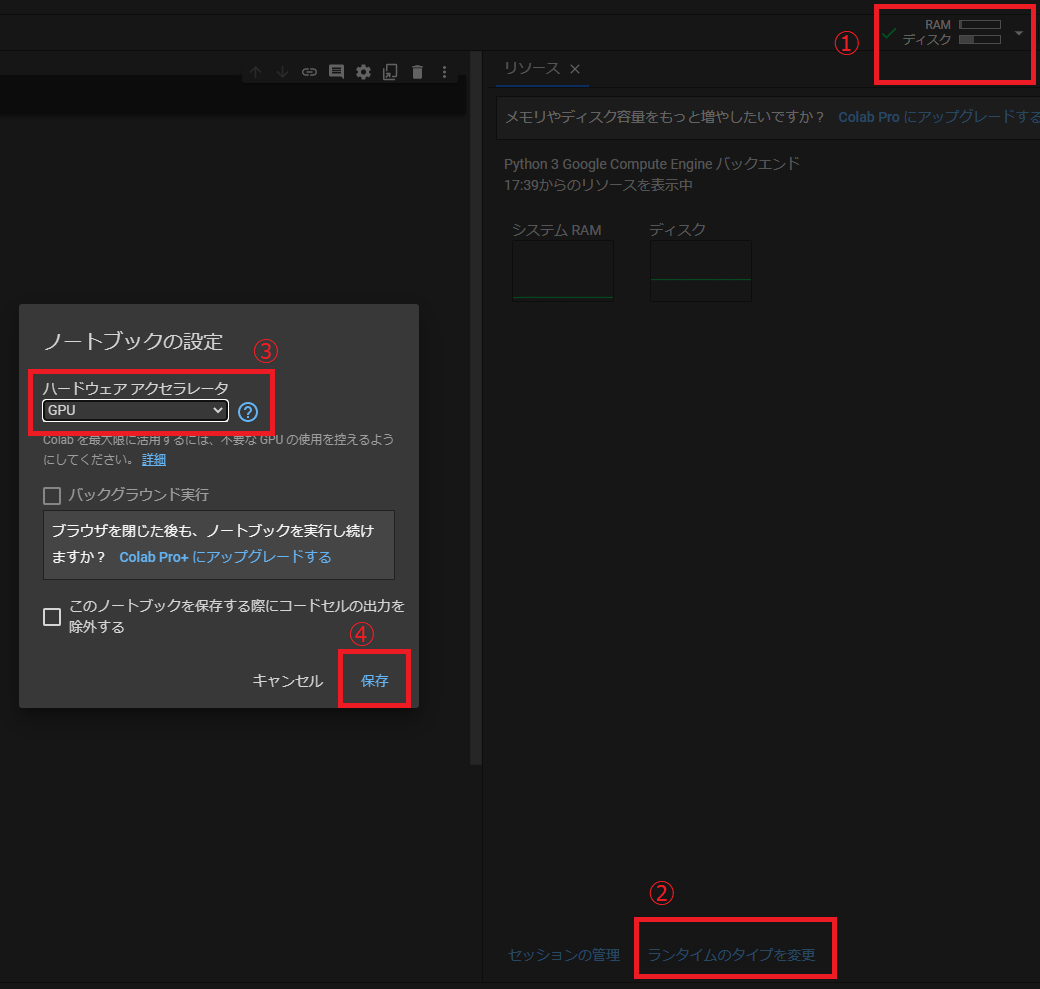
#次にGPUを設定します。
Google Colaboratoryの左上にあるリソースを開き、ランタイムのタイプを変更を選択します。
その後、ハードウェアアクセラレータをGPUにして保存してください。
こうすることでGoogleのGPU環境を無料で扱うことができます。
(下記、画像の①~④の順番でクリック)
Googleドライブのマウント
#gitのクローンなどを行いGPT2-japaneseをセットアップする関係上、Googleドライブをマウントするのが便利です。
以下のコマンドを実施して、Googleドライブをマウントしてください。
from google.colab import drive
drive.mount('/content/drive')
この際にGoogleドライブへの接続の許可を確認されるので、
「Googleドライブに接続」→ 「許可」
を選択するようにしてください。
その後、以下のコマンドを実行し、マイドライブ上の作成したファイルがある場所に移動します。
(※ここではColabフォルダに移動します)
cd /content/drive/MyDrive/Colab
GPT2-japaneseのクローン
#最後にGPT2-japaneseのクローンを実行します。
以下のコマンドを実行して、GPT2-japaneseをクローンしてください。
- GPT2-mediumの場合
!git clone https://github.com/tanreinama/gpt2-japanese
- GPT-1bの場合
!git clone https://github.com/rinnakk/japanese-pretrained-models
実行が完了していると、Googleドライブ上の指定したフォルダにクローンが出来ていることが確認できます。
文章生成 by GPT-1b
#それでは実際にGPT-2を使って文章を生成してみましょう。
文章生成の際にはパラメータ量が一番大きく、かつ、perplexityが低いGPT-1bを使います。
まずGPT-1bを使用するための必要なライブラリをインストールします。
以下のコマンドを実行して、クローンしたGPT-1bのフォルダに移動しライブラリをインストールしてください。
cd japanese-pretrained-models/
!pip install -r requirements.txt
以下のコードを実行してモデルをロードします。
import torch
from transformers import T5Tokenizer, AutoModelForCausalLM
# トークナイザーとモデルのロード
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt-1b")
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-1b")
# GPU使用(※GPUを使用しない場合、文章生成に時間がかかります)
if torch.cuda.is_available():
model = model.to("cuda")
モデルをロードしたら、以下のコードで文章を生成できます。
promptに文章を入力して実行すると、続きの文章を出力してくれます。
今回は遊んでみるということで、昔話のよくある冒頭を使って実行してみました。
# 初めの文章
prompt = "むかしむかしあるところにおじいさんとおばあさんがいました。おじいさんは"
# 生成する文章の数
num = 1
input_ids = tokenizer.encode(prompt, return_tensors="pt",add_special_tokens=False).to("cuda")
with torch.no_grad():
output = model.generate(
input_ids,
max_length=100, # 最長の文章長
min_length=100, # 最短の文章長
do_sample=True,
top_k=500, # 上位{top_k}個の文章を保持
top_p=0.95, # 上位{top_p}%の単語から選択する。例)上位95%の単語から選んでくる
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
bad_word_ids=[[tokenizer.unk_token_id]],
num_return_sequences=num # 生成する文章の数
)
decoded = tokenizer.batch_decode(output,skip_special_tokens=True)
for i in range(num):
print(decoded[i])
その結果が以下となります。
むかしむかしあるところにおじいさんとおばあさんがいました。おじいさんは山へ芝刈りに、おばあさんは川へ洗濯に出かけます。いつもは空になった樽が二つもあったのに、今日は一つしかありません。二人はおじいさんが芝刈りの間、川へ洗濯に来ないものかと楽しみにしていました。 川の方は随分増水しています。もう樽を持って上がれないし、増水しているのは川の中だけではありません。村の人達がお祭りの夜の準備で家の下敷きになって川の中へ
改行ができていないのが悩ましいですが、それでもかなり自然な文章が出来ています。
またちゃんと物語の冒頭であることも判断しているようで、物語的な文章になっています。
ブログ的な文章も試してみました。
- 入力:
prompt = "「文章を書きたいけど、上手く書けない」と悩んでいませんか? そんなあなたに"
- 出力結果:
「文章を書きたいけど、上手く書けない」と悩んでいませんか? そんなあなたに朗報です。 文章力を飛躍的に向上させ「記事をいっぱい書ける」ようになると、あなたの時間を2倍、3倍と取ることができますよ... 続きを読む »». 2人称単数って、どうやって決めるの? 2人称単数とは、2人以上のことを指します。英語では、2人称が複数か単数で表すことになることを覚えておきましょう。しかし、多くの英語サイトでは、2人称単数(または複数人称)
どこかのWebページで見たような文章になりました。
ご丁寧に「続きを読む」などが出力されてきました(笑)
以上のように日本語らしい、もしくはネットの記事にあるような文章を書いてくれました。
これだけでもある程度、日本語として成り立つ文章を書いてくれます。
ですが、例えば「〇〇先生らしい文章にしたい」とか「ちゃんとしたブログの記事を書いてほしい」など自分の好みや書きたいことに合わせた文章は生成してくれるわけではありません。
そういった〇〇に特化した文章を書きたいとするなら、GPT-2を微調整する必要があります。
その方法がファインチューニングです。
次ではGPT-2のファインチューニングのやり方とその結果をご紹介します。
ファインチューニング by GPT2-medium
#まずファインチューニングとは何かというと、学習済みモデルの一部と新たに追加したモデルの一部を活用して微調整するものです。
GPT-2においては、生成したい文章に合わせたデータを再学習させることで独自の文章を生成するようになります。
さっそくやってみようと思うのですが、GPT-1bだとメモリが足りないようなので、今回は3億パラメータのGPT2-mediumを使ってファインチューニングします。
学習データ
#今回は青空文庫の「銀河鉄道の夜」をテストデータとして使用します。
データのファイル形式はテキストファイルにしています。
また青空文庫からファイルをダウンロードすると文字コードがshift-JISになっていますのでUTF-8に直してください。
それ以外はほぼ無加工で学習させてみます。
ダウンロードしたファイルをGoogleドライブの任意の場所に置いてください。
私はMyDrive/Colab/train_data配下に置きました。
事前準備
#それではGPT2-mediumによるファインチューニングを行っていきます。
まずGoogle Colaboratoryを使用しているので、データを取得するためにドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')
またデータのあるフォルダ(このブログではColabフォルダ)に移動してください。
cd /content/drive/MyDrive/Colab
その次にファインチューニングを行うための事前準備として、ソースからtransformersをインストールします。
pip install git+https://github.com/huggingface/transformers
またTransformersのリポジトリにあるスクリプトを使用するのでクローンしてください。
!git clone https://github.com/huggingface/transformers
以下のコマンドを実行して必要なライブラリをインストールしてください。
pip install -r ./transformers/examples/pytorch/language-modeling/requirements.txt
ファインチューニング
#事前準備が完了したら、あとは以下のようにrum_clm.pyを使ってファインチューニングをすることができます。
!python ./transformers/examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path=rinna/japanese-gpt2-medium \
--train_file=train_data/gingatetsudono_yoru.txt \
--do_train \
--num_train_epochs=3 \
--save_steps=10000 \
--block_size 512 \
--save_total_limit=3 \
--per_device_train_batch_size=1 \
--output_dir=output/ \
--overwrite_output_dir \
--use_fast_tokenizer=False
上記に書かれているoutput_dir=...の部分にファインチューニングしたモデルが出力されます。
このモデルを利用することで、文章を自動生成できます。
実行結果
#ファインチューニングが完了したら、実際に文章を作成してみましょう。
学習したモデルを以下のコードで読み込ませます。
from transformers import T5Tokenizer, AutoModelForCausalLM
import torch
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-medium")
tokenizer.do_lower_case = True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 学習したモデルを読み込む
model = AutoModelForCausalLM.from_pretrained("output/")
model.to(device)
model.eval()
その後、銀河鉄道の夜に出てくる一文を最初の文章として設定して実行してみました。
# 初めの文章
prompt = "口笛を吹いているようなさびしい口付きで、"
# 生成する文章の数
num = 1
input_ids = tokenizer.encode(prompt, return_tensors="pt",add_special_tokens=False).to(device)
with torch.no_grad():
output = model.generate(
input_ids,
max_length=100, # 最長の文章長
min_length=100, # 最短の文章長
do_sample=True,
top_k=500, # 上位{top_k}個の文章を保持
top_p=0.95, # 上位{top_p}%の単語から選択する。例)上位95%の単語から選んでくる
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
bad_word_ids=[[tokenizer.unk_token_id]],
num_return_sequences=num # 生成する文章の数
)
decoded = tokenizer.batch_decode(output,skip_special_tokens=True)
for i in range(num):
print(decoded[i])
出力した結果が以下となります。
口笛を吹いているようなさびしい口付きで、白い大きな帽子をかぶって、のどかな小鳥のさえずりと、ジョバンニの笛の音を聞きながら、にぎやかな鐘の音とせわしない葉、かたちをこした土と、まっ黒な夜光りの中を散歩している。ジョバンニもまっ黒な顔つきになって、向う側には青い着物を来た男が腰掛かって、ぼん
少々日本語が不自然ですが、それなりに物語のような文章を生成しています。
また初めに自分で書いた文章では、銀河鉄道の夜の登場人物は敢えて書きませんでしたが、出力した文章には「ジョバンニ」の名前が表示されました。
銀河鉄道の夜を学習した結果ですね!
ファインチューニングしたことでモデルが調整されたことになります。
まとめ
#今回は日本語版GPT-2を使って遊んでみました。
自然言語処理の知識がそんなになくとも文章の自動生成やファインチューニングなどいろいろ試せたのはよかったです。
また本ブログでは紹介できませんでしたが、100万文字程度の小説もファインチューニングしてみました。
その場合では(学習に時間はかかりますが)今回の場合よりもその小説らしい文章で出力してくれました。
今後、学習を重ねることが出来ればより精度高く文章生成ができそうです。