Strimzi - Kubernetes で Kafka を運用するための Operators
Back to TopApache Kafka は高速でスケーラブルな pub/sub 型の分散メッセージングシステムです。Kafka クラスターに配置された Topic に Consumer アプリが Subscribe し、Producer が送信するメッセージを順次処理していきます。
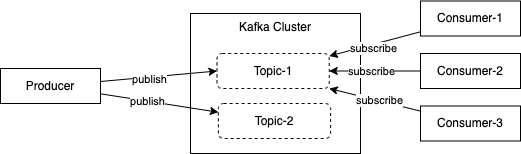
Kafka はコンテナや Kubernetes 以前からの歴史があり、近年 Kubernetes で運用する事例も増えてきています。この記事では Kafka を Kubernetes で運用するための OSS の Operator Strimzi についてご紹介します。
Kafka の構成
#Kafka のスケーラビリティはその構成により実現されています。メッセージが流れる Topic を Partition に分割し、多数の Consumer がメッセージを受信できるようにすると共に、Topic を管理する Broker を複数マシンからなるクラスターとし、異なる Broker で Partition を分散管理することで、冗長化を実現しています。
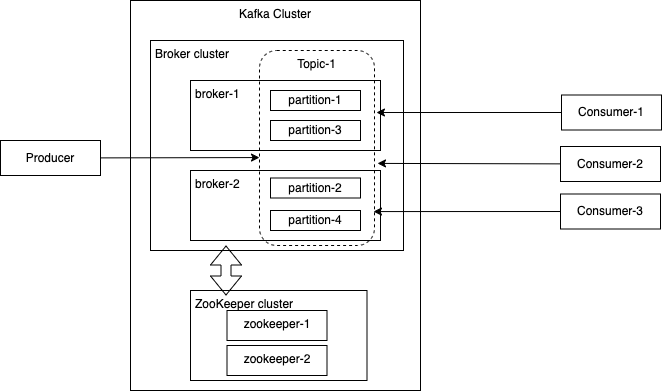
Broker クラスターを管理する ZooKeeper というサーバー(これもクラスター構成)があり、Broker の状態を監視し、1つの Broker が使えなくなった時に、他の Broker を割り当てるなどの制御を行っています。
Kafka はこのように、かなり複雑な分散システムです。Kubernetes は Web アプリケーションなどのステートレスなワークロードの運用は得意ですが、このような状態を持つ分散システムの運用は難易度が上がります。
bitnami の Helm Chart によるデプロイ構成
#bitnami から提供されている Helm Chart で Kubernetes 上の Kafka 構成を見てみましょう。
Helm Charts to deploy Apache Kafka in Kubernetes
Minikube に bitnami-kafka という namespace を作ってインストールしました。
helm repo add bitnami https://charts.bitnami.com/bitnami
kubectl create ns bitnami-kafka
helm install sample-cluster bitnami/kafka -n bitnami-kafka
作成されたオブジェクトを見てみます。
$ kubectl get sts,po,svc,pvc,sa -n bitnami-kafka
NAME READY AGE
statefulset.apps/sample-cluster-kafka 1/1 64m
statefulset.apps/sample-cluster-zookeeper 1/1 64m
NAME READY STATUS RESTARTS AGE
pod/sample-cluster-kafka-0 1/1 Running 2 (63m ago) 64m
pod/sample-cluster-zookeeper-0 1/1 Running 0 64m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/sample-cluster-kafka ClusterIP 10.109.112.100 <none> 9092/TCP 64m
service/sample-cluster-kafka-headless ClusterIP None <none> 9092/TCP,9093/TCP 64m
service/sample-cluster-zookeeper ClusterIP 10.99.14.27 <none> 2181/TCP,2888/TCP,3888/TCP 64m
service/sample-cluster-zookeeper-headless ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 64m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/data-sample-cluster-kafka-0 Bound pvc-a142bf96-fc0a-479d-b773-9f799e637c99 8Gi RWO hostpath 64m
persistentvolumeclaim/data-sample-cluster-zookeeper-0 Bound pvc-1d4d9ab9-a5ad-48cc-85b7-73cb52f2e8a0 8Gi RWO hostpath 64m
NAME SECRETS AGE
serviceaccount/default 1 66m
serviceaccount/sample-cluster-kafka 1 64m
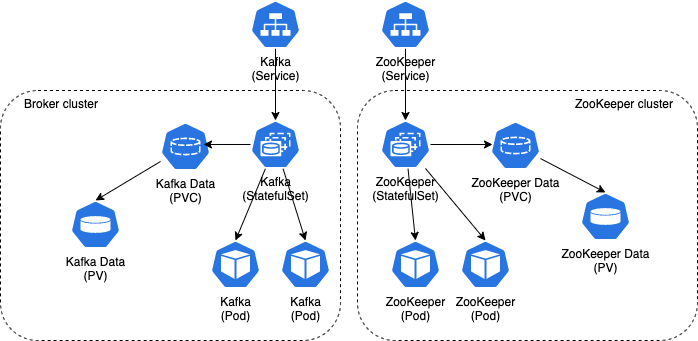
Broker クラスター、ZooKeeper クラスターは、Kubernetes の StatefulSet[1] として作成されます。Broker の Topic 及びメッセージや、ZooKeeper で管理される Broker クラスターの状態などのメタデータは、PV(Persistence Volume) に保存されます。
Topic を作成する(ややメンドウ)
#Helm Chart でデプロイされた Kubernetes 上の Kafka クラスターの操作について考えると、Kafka クラスターを構成する Broker などのオブジェクトは StatefulSet、Pod、Service などで表現されますが、Topic や Partition などについては Kafka 世界の登場人物であるため、Kubernetes のオブジェクトとして表現されず、kubectl などで操作することはできません。
Topic を作成するには、作業用の Kafka Pod を Kafka のクライアントとして起動して、提供されているシェルを使用する方法があります。まず、bitnami の Kafka のコンテナイメージを利用して、Pod を起動します。
kubectl -n kafka run kafka-client --restart='Never' --image docker.io/bitnami/kafka --command -- sleep infinity
Topic を新規作成するには、この Pod に入って、コマンドを叩くか、次のように here document でコマンドを実行します。
$ kubectl -n kafka exec -i kafka-client -- bash << 'EOS'
kafka-topics.sh --create --bootstrap-server=sample-cluster-kafka:9092 --replication-factor 1 --partitions 2 --topic topic-1
EOS
Created topic topic-1.
作成された Topic をリスト表示してみます。
$ kubectl -n kafka exec -i kafka-client -- bash << 'EOS'
kafka-topics.sh --list --bootstrap-server=sample-cluster-kafka:9092
EOS
topic-1
そんなに難しい操作ではありませんが、Pod を起動したりするところがやや面倒です。
Broker を増やしてリバランスする (かなりメンドウ)
#Kafka の通常運用としては、以下のようなオペレーションを実行する必要があります。
- Broker を増やす
- Topic を追加する
- Topic の partition を増やす
- Kafka のバージョンを上げる
Topic は自動作成もできて、Partition 数や replication-factor (Partition をいくつの Broker に分散配置するか) はデフォルト値を設定できるため、ある程度 Kafka にお任せできますが、スケールアウトのため Broker を追加したり、Topic の Partition を増やす場合は、偏りが発生するため、これを手動でリバランスする必要があります。Kafka 提供のシェルスクリプトを使ってリバランスするオペレーションはけっこう煩雑です。たとえば、Broker が3台で、topic-1 が3つの Partition で構成されていて、Topic の状態を出力すると以下のようになっているとします。
$ kafka-topics.sh --describe --bootstrap-server=sample-cluster-kafka:9092 --topic topic-1
Topic: topic-1 TopicId: _MgPr5IFSKK1XjaYlIkhnQ PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: topic-1 Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: topic-1 Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: topic-1 Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1,0
この出力は3つの Partition にそれぞれ、1台の Leader と 2台の Replica の Broker が割り当てられていることを表しています。Leader が何らかの原因で落ちると、Replica が Leader に昇格します。
Helm Chart の設定で、Broker を 3台から4台に増やして更新します。(values.yaml で replicas を 3 → 4に変更)
helm upgrade -n bitnami-kafka sample-cluster bitnami/kafka -f values.yaml
Broker は増えますが、再度 Topic の状態を見ても配置は変わっておらず、topic-1 にとっては新規追加された Broker は存在しないのと同じになっています。
$ kafka-topics.sh --describe --bootstrap-server=sample-cluster-kafka:9092 --topic topic-1
Topic: topic-1 TopicId: _MgPr5IFSKK1XjaYlIkhnQ PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: topic-1 Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: topic-1 Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: topic-1 Partition: 2 Leader: 1 Replicas: 1,0 Isr: 1,0
Partition を全ての Broker を使って最適配置するのは以下のような手順となります。
まず、再配置対象の Topic を指定した JSON ファイルを作成します。
cat <<EOF > topics-to-move.json
{
"topics": [{ "topic": "topic-1" }],
"version": 1
}
EOF
kafka-reassign-partitions.sh を実行して、再配置プランを提案してもらいます。--broker-list に列挙しているのが、使用したい broker の ID です。現状の配置に続いて、再配置の提案が出力されます。
$ kafka-reassign-partitions.sh --bootstrap-server=sample-cluster-kafka:9092 --topics-to-move-json-file topics-to-move.json --broker-list=0,1,2,3 --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"topic-1","partition":0,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"topic-1","partition":1,"replicas":[0,2],"log_dirs":["any","any"]},{"topic":"topic-1","partition":2,"replicas":[1,0],"log_dirs":["any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"topic-1","partition":0,"replicas":[2,3],"log_dirs":["any","any"]},{"topic":"topic-1","partition":1,"replicas":[3,0],"log_dirs":["any","any"]},{"topic":"topic-1","partition":2,"replicas":[0,1],"log_dirs":["any","any"]}]}
提案されたプランの JSON をコピーして、再配置用の JSON ファイルを作成します。
cat <<EOF > expand-cluster-reassignment.json
{"version":1,"partitions":[{"topic":"topic-1","partition":0,"replicas":[2,3],"log_dirs":["any","any"]},{"topic":"topic-1","partition":1,"replicas":[3,0],"log_dirs":["any","any"]},{"topic":"topic-1","partition":2,"replicas":[0,1],"log_dirs":["any","any"]}]}
EOF
上記の JSON ファイルを入力として、kafka-reassign-partitions.sh を実行し、再配置を実行します。
$ kafka-reassign-partitions.sh --bootstrap-server=sample-cluster-kafka:9092 --reassignment-json-file expand-cluster-reassignment.json --execute
:
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for topic-1-0,topic-1-1,topic-1-2
再配置結果を確認します。全ての Broker が各 Partirion の Leader と Replica に再配置されました。
$ kafka-topics.sh --describe --bootstrap-server=sample-cluster-kafka:9092 --topic topic-1
Topic: topic-1 TopicId: _MgPr5IFSKK1XjaYlIkhnQ PartitionCount: 3 ReplicationFactor: 2 Configs:
Topic: topic-1 Partition: 0 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: topic-1 Partition: 1 Leader: 3 Replicas: 3,0 Isr: 0,3
Topic: topic-1 Partition: 2 Leader: 1 Replicas: 0,1 Isr: 1,0
以上「読んでいただいてお疲れ様でした」って書きたくなるほど面倒です。それほど頻度は高くないとはいえ通常運用の範囲ですし、作業用の Pod に入ってコマンドをチマチマ叩くのは効率悪そうです。
Strimzi の導入
#とても 前置きが長くなってしまいましたが、やっとここで Strimzi を導入して使っていきます。
Strimzi - Apache Kafka on Kubernetes
Strimzi は Cloud Native Computing Foundation の Sandbox project としてホスティングされている Kafka の Operator です。OpenShift をサポートするため RedHat に所属する開発者もいますが、コミュニティベースの開発活動が続けられています。
Quick Start に従って記事執筆時点の最新バージョン(v0.29.0)を設定していきます。
Strimzi Quick Start guide (0.29.0)
Strimzi の GitHub Release ページからダウンロードして展開。ディレクトリには、各種 Strimzi を使用するための各種 Manifest が格納されています。
curl -LO https://github.com/strimzi/strimzi-kafka-operator/releases/download/0.29.0/strimzi-0.29.0.zip
unzip strimzi-0.29.0.zip
今回は、Strimzi を kafka namespace に作成するので、RoleBinding の Manifest に書かれている namespace を置換します。[2]
cd strimzi-0.29.0
sed -i '' 's/namespace: .*/namespace: kafka/' install/cluster-operator/*RoleBinding*.yaml
install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml を編集して、クラスター用の namespace (ここでは my-kafka-project) を直接指定します。
# ...
env:
- name: STRIMZI_NAMESPACE
value: my-kafka-project
# valueFrom:
# fieldRef:
# fieldPath: metadata.namespace
# ...
必要な namespace を作成します。
kubectl create ns kafka
kubectl create ns my-kafka-project
Strimzi の Cluster Operator が namespace my-kafka-project を監視できるよう RoleBinding を my-kafka-project に指定します。
$ kubectl create -f install/cluster-operator/020-RoleBinding-strimzi-cluster-operator.yaml -n my-kafka-project
rolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator created
$ kubectl create -f install/cluster-operator/031-RoleBinding-strimzi-cluster-operator-entity-operator-delegation.yaml -n my-kafka-project
rolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator-entity-operator-delegation created
Strimzi の CRD (Cusotm Resouce Definition) と RBAC を namespace kafka にデプロイします。
$ kubectl create -f install/cluster-operator/ -n kafka
serviceaccount/strimzi-cluster-operator created
clusterrole.rbac.authorization.k8s.io/strimzi-cluster-operator-namespaced created
rolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator created
clusterrole.rbac.authorization.k8s.io/strimzi-cluster-operator-global created
clusterrolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator created
clusterrole.rbac.authorization.k8s.io/strimzi-kafka-broker created
clusterrolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator-kafka-broker-delegation created
clusterrole.rbac.authorization.k8s.io/strimzi-entity-operator created
rolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator-entity-operator-delegation created
clusterrole.rbac.authorization.k8s.io/strimzi-kafka-client created
clusterrolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator-kafka-client-delegation created
customresourcedefinition.apiextensions.k8s.io/kafkas.kafka.strimzi.io created
customresourcedefinition.apiextensions.k8s.io/kafkaconnects.kafka.strimzi.io created
customresourcedefinition.apiextensions.k8s.io/strimzipodsets.core.strimzi.io created
customresourcedefinition.apiextensions.k8s.io/kafkatopics.kafka.strimzi.io created
customresourcedefinition.apiextensions.k8s.io/kafkausers.kafka.strimzi.io created
customresourcedefinition.apiextensions.k8s.io/kafkamirrormakers.kafka.strimzi.io created
customresourcedefinition.apiextensions.k8s.io/kafkabridges.kafka.strimzi.io created
customresourcedefinition.apiextensions.k8s.io/kafkaconnectors.kafka.strimzi.io created
customresourcedefinition.apiextensions.k8s.io/kafkamirrormaker2s.kafka.strimzi.io created
customresourcedefinition.apiextensions.k8s.io/kafkarebalances.kafka.strimzi.io created
configmap/strimzi-cluster-operator created
deployment.apps/strimzi-cluster-operator created
これで、Strimzi のインストールは終わりました。次に、CRD Kafka を使って Kafka クラスターを作ります。以下は公式ドキュメントに従って、here document により作成していますが、YAML ファイルを作成して適用しても同じです。
cat << EOF | kubectl create -n my-kafka-project -f -
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
replicas: 1
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: tls
- name: external
port: 9094
type: nodeport
tls: false
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
default.replication.factor: 1
min.insync.replicas: 1
zookeeper:
replicas: 1
storage:
type: persistent-claim
size: 100Gi
deleteClaim: false
entityOperator:
topicOperator: {}
userOperator: {}
EOF
クラスターが Ready になるまで wait しておくと1分ぐらいで Ready になります。
$ kubectl wait kafka/my-cluster --for=condition=Ready --timeout=300s -n my-kafka-project
kafka.kafka.strimzi.io/my-cluster condition met
Strimzi でデプロイされた Kafka クラスター構成
#my-kafka-project に作成されたオブジェクトを見てみます。bitnami の chart でデプロイされたものと同じような構成ですが、Strimzi の entity-operator の Deployment、Pod、ServiceAccount ができています。
$ strimzi-0.29.0 kubectl get deploy,sts,po,svc,pvc,sa -n my-kafka-project
NAME READY UP-TO-DATE AVAILABLE AGE
my-cluster-entity-operator 1/1 1 1 2m22s
NAME READY AGE
statefulset.apps/my-cluster-kafka 1/1 2m44s
statefulset.apps/my-cluster-zookeeper 1/1 3m46s
NAME READY STATUS RESTARTS AGE
pod/my-cluster-entity-operator-79d44dd6c-5q9hz 3/3 Running 0 2m22s
pod/my-cluster-kafka-0 1/1 Running 0 2m44s
pod/my-cluster-zookeeper-0 1/1 Running 0 3m46s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/my-cluster-kafka-0 NodePort 10.99.189.164 <none> 9094:31594/TCP 2m44s
service/my-cluster-kafka-bootstrap ClusterIP 10.96.101.128 <none> 9091/TCP,9092/TCP,9093/TCP 2m44s
service/my-cluster-kafka-brokers ClusterIP None <none> 9090/TCP,9091/TCP,9092/TCP,9093/TCP 2m44s
service/my-cluster-kafka-external-bootstrap NodePort 10.104.10.45 <none> 9094:31759/TCP 2m44s
service/my-cluster-zookeeper-client ClusterIP 10.111.188.223 <none> 2181/TCP 3m46s
service/my-cluster-zookeeper-nodes ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 3m46s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/data-0-my-cluster-kafka-0 Bound pvc-ca10ad68-fd23-4782-8ccf-22b87d355d5e 100Gi RWO hostpath 2m44s
persistentvolumeclaim/data-my-cluster-zookeeper-0 Bound pvc-81adf737-195d-4516-a750-047fe5cff30b 100Gi RWO hostpath 3m46s
NAME SECRETS AGE
serviceaccount/default 1 14m
serviceaccount/my-cluster-entity-operator 1 2m22s
serviceaccount/my-cluster-kafka 1 2m44s
serviceaccount/my-cluster-zookeeper 1 3m46s
CRD をデプロイした namespace kafka に作成されたオブジェクトです。
kubectl -n kafka get crd,sa,deploy,po
NAME CREATED AT
customresourcedefinition.apiextensions.k8s.io/kafkabridges.kafka.strimzi.io 2022-05-25T00:22:08Z
customresourcedefinition.apiextensions.k8s.io/kafkaconnectors.kafka.strimzi.io 2022-05-25T00:22:08Z
customresourcedefinition.apiextensions.k8s.io/kafkaconnects.kafka.strimzi.io 2022-05-25T00:22:08Z
customresourcedefinition.apiextensions.k8s.io/kafkamirrormaker2s.kafka.strimzi.io 2022-05-25T00:22:08Z
customresourcedefinition.apiextensions.k8s.io/kafkamirrormakers.kafka.strimzi.io 2022-05-25T00:22:08Z
customresourcedefinition.apiextensions.k8s.io/kafkarebalances.kafka.strimzi.io 2022-05-25T00:22:08Z
customresourcedefinition.apiextensions.k8s.io/kafkas.kafka.strimzi.io 2022-05-25T00:22:08Z
customresourcedefinition.apiextensions.k8s.io/kafkatopics.kafka.strimzi.io 2022-05-25T00:22:08Z
customresourcedefinition.apiextensions.k8s.io/kafkausers.kafka.strimzi.io 2022-05-25T00:22:08Z
customresourcedefinition.apiextensions.k8s.io/strimzipodsets.core.strimzi.io 2022-05-25T00:22:08Z
NAME SECRETS AGE
serviceaccount/default 1 6h8m
serviceaccount/strimzi-cluster-operator 1 5h41m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/strimzi-cluster-operator 1/1 1 1 5h41m
NAME READY STATUS RESTARTS AGE
pod/strimzi-cluster-operator-d5f95d997-nvpqm 1/1 Running 38 (6m4s ago) 5h41m
それぞれの namespace のオブジェクトを簡単に図示してみました。
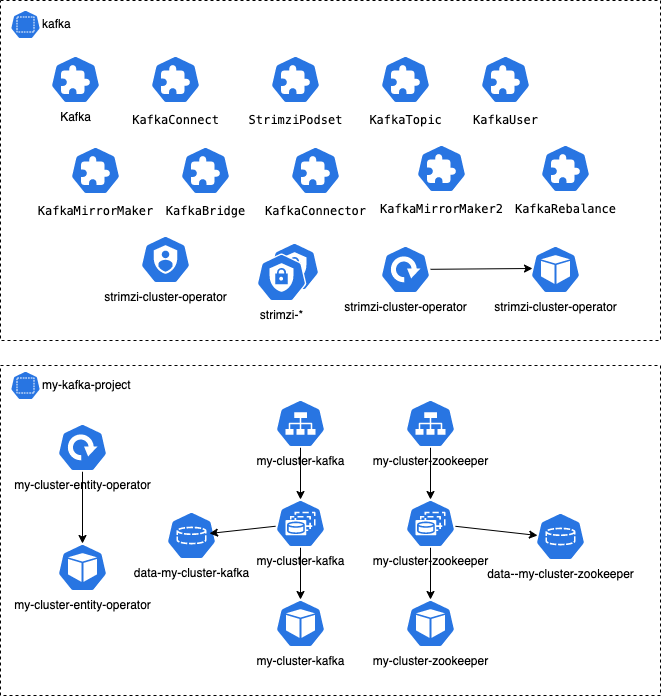
namespace kafka に配置された CRD でさまざまなオペレーションを Kuberenetes のインターフェースを通して操作できるようになります。
Topic を作成する (Strimzi 編)
#Strimzi では Kafka の Topic は KafkaTopic という CRD で定義されており、Manifest を適用するだけで作成できてしまいます。
$ cat << EOF | kubectl create -n my-kafka-project -f -
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: my-topic
labels:
strimzi.io/cluster: "my-cluster"
spec:
partitions: 3
replicas: 1
EOF
kafkatopic.kafka.strimzi.io/my-topic created
Kubernetes のオブジェクトとして、Topic を kubectl で確認できます。
$ kubectl -n my-kafka-project get kafkatopic my-topic
NAME CLUSTER PARTITIONS REPLICATION FACTOR READY
my-topic my-cluster 3 1 True
ここで、bitnami の Helm Chart の時と同様に Strimzi で使われている kafka イメージを使ってクライアント用の Pod を起動して確認していきます。
kubectl -n my-kafka-project run kafka-client --restart='Never' --image quay.io/strimzi/kafka:0.29.0-kafka-3.2.0 --command -- sleep infinity
Topic の Manifest を適用したことで実際に Kafka の Topic が作成されていることを here document を実行して確認してみました。
$ kubectl -n my-kafka-project exec -i kafka-client -- bash << 'EOS'
bin/kafka-topics.sh --describe --bootstrap-server my-cluster-kafka-bootstrap:9092 --topic my-topic
EOS
Topic: my-topic TopicId: Pan_0la7Q-m4QA8HFvKqWA PartitionCount: 3 ReplicationFactor: 1 Configs: min.insync.replicas=1,message.format.version=3.0-IV1
Topic: my-topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: my-topic Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: my-topic Partition: 2 Leader: 0 Replicas: 0 Isr: 0
Broker は1個なので、全ての Partition が 同じ Broker に作られ、Replica はない状態です。ついでに Kafka 付属の console-producer と console-consumer を使って my-topic でメッセージをやりとりしてみます。
Producer を起動してメッセージを入力。
$ kubectl -n my-kafka-project exec -it kafka-client -- bash
% bin/kafka-console-producer.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --topic my-topic
>hello
別のターミナルで、Consumer 受信を確認。
$ kubectl -n my-kafka-project exec -it kafka-client -- bash
% bin/kafka-console-consumer.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --topic my-topic --from-beginning
hello
Kafka Cluster としてちゃんと動作しているようです。
Topic の追加は Manifest を適用するだけでした。Topic の修正も Manifest を変更して適用するだけです。
kubectl edit で my-topic の partition を4に増やして適用します。
kubectl -n my-kafka-project edit kafkatopic my-topic
Topic を確認、Partition 数が変更されました。
$ kubectl -n my-kafka-project get kafkatopic my-topic
NAME CLUSTER PARTITIONS REPLICATION FACTOR READY
my-topic my-cluster 4 1 True
Broker を増やしてリバランスする (Strimzi + Cruise Control 編)
#あの面倒だったリバランスについては、Strimzi は Cruise Control を導入しており、オペレーションがかなり楽になっています。
Strimzi のドキュメントにはこのようにあります。
Cruise Control は、Kafka クラスター全体のデータ監視とバランシングを簡略化するためのオープンソースプロジェクトです。Cruise Controlは、Kafka クラスターと共にデプロイされて、トラフィックを監視し、よりバランスの取れた Partition 割り当てを提案し、それらの提案に基づいて Partition の再割り当てを実行します。
Cruise Control は、リソース使用率情報を収集して、Kafka クラスターのワークロードをモデル化および分析します。Cruise Control は、最適化目標に基づいて、クラスターを効果的にリバランスする最適化提案を生成します。最適化の提案が承認されると、Cruise Control はリバランスを適用します。
Prometheus は、最適化の提案やリバランス操作に関連するデータを含む、Cruise Control のためのメトリクスデータを抽出できます。Cruise Control 用のサンプル Manifest と Grafana ダッシュボードが Strimzi に付属しています。
Cruise Control は LinkedIn で開発されている Kafka オートメーションの OSS です。
Kafka 標準のリバランスと違い、Prometheus のメトリクスも利用できるため、より精度の高い提案が得られそうです。
Strimzi のドキュメントには概要しか書いてありませんが、以下のブログに Cruise Control を使ったリバランスの手順が書かれています。
Cluster balancing with Cruise Control
ということで、Cruise Control を使ったリバランスの手順を確認していきます。上記でデプロイした Kafka クラスターは Cruise Control がない構成だったので、これを破棄し、Cruise Controll を含む構成でデプロイします。Broker が複数必要なので、kafka の replicas を2にしています。Kafka の spec に cruiseControl: {} を追加しています。
cat << EOF | kubectl create -n my-kafka-project -f -
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
replicas: 2
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: tls
- name: external
port: 9094
type: nodeport
tls: false
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 100Gi
deleteClaim: false
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
default.replication.factor: 1
min.insync.replicas: 1
zookeeper:
replicas: 1
storage:
type: persistent-claim
size: 100Gi
deleteClaim: false
entityOperator:
topicOperator: {}
userOperator: {}
cruiseControl: {}
EOF
デプロイされたオブジェクトを確認。 Cruise Control の Deployment と Pod ができています。
$ kubectl get deploy,sts,po,svc -n my-kafka-project
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/my-cluster-cruise-control 1/1 1 1 2m5s
deployment.apps/my-cluster-entity-operator 1/1 1 1 2m27s
NAME READY AGE
statefulset.apps/my-cluster-kafka 2/2 3m2s
statefulset.apps/my-cluster-zookeeper 1/1 3m26s
NAME READY STATUS RESTARTS AGE
pod/my-cluster-cruise-control-857c6d665-4whmw 1/1 Running 0 2m5s
pod/my-cluster-entity-operator-79d44dd6c-tjj9n 3/3 Running 0 2m27s
pod/my-cluster-kafka-0 1/1 Running 0 3m2s
pod/my-cluster-kafka-1 1/1 Running 0 3m2s
pod/my-cluster-zookeeper-0 1/1 Running 0 3m26s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/my-cluster-cruise-control ClusterIP 10.98.47.144 <none> 9090/TCP 2m5s
service/my-cluster-kafka-0 NodePort 10.107.99.207 <none> 9094:30909/TCP 3m3s
service/my-cluster-kafka-1 NodePort 10.99.93.45 <none> 9094:31078/TCP 3m3s
service/my-cluster-kafka-bootstrap ClusterIP 10.107.191.25 <none> 9091/TCP,9092/TCP,9093/TCP 3m3s
service/my-cluster-kafka-brokers ClusterIP None <none> 9090/TCP,9091/TCP,9092/TCP,9093/TCP 3m3s
service/my-cluster-kafka-external-bootstrap NodePort 10.102.73.249 <none> 9094:32702/TCP 3m3s
service/my-cluster-zookeeper-client ClusterIP 10.98.8.86 <none> 2181/TCP 3m26s
service/my-cluster-zookeeper-nodes ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 3m26s
この状態から、リバランスを実行していきます。Strimzi の examples ディレクトリにリバランスのサンプルがいくつかあります。この中で、examples/cruise-control/kafka-rebalance-full.yaml を適用。リバランスも KafkaRebalance という CRD になっています。
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaRebalance
metadata:
name: my-rebalance
labels:
strimzi.io/cluster: my-cluster
# no goals specified, using the default goals from the Cruise Control configuration
spec: {}
この Manifest では、Goal を指定していないので、Goal については Cruise Control のデフォルト値が適用されることになります。
Manifest を適用します。
$ kubectl apply -f kafka-rebalance-full.yaml -n my-kafka-project
kafkarebalance.kafka.strimzi.io/my-rebalance created
適用した KafkaRebalance を describe すると Status/Optimization Result にリバランスの提案が出力されています。Status は ProposalReady です。
$ kubectl describe kafkarebalance my-rebalance -n my-kafka-project
Name: my-rebalance
Namespace: my-kafka-project
Labels: strimzi.io/cluster=my-cluster
Annotations: <none>
API Version: kafka.strimzi.io/v1beta2
Kind: KafkaRebalance
Metadata:
Creation Timestamp: 2022-05-25T09:04:02Z
Generation: 1
(..)
Status:
Conditions:
Last Transition Time: 2022-05-25T09:04:03.507351Z
Status: True
Type: ProposalReady
Observed Generation: 1
Optimization Result:
After Before Load Config Map: my-rebalance
Data To Move MB: 0
Excluded Brokers For Leadership:
Excluded Brokers For Replica Move:
Excluded Topics:
Intra Broker Data To Move MB: 0
Monitored Partitions Percentage: 100
Num Intra Broker Replica Movements: 0
Num Leader Movements: 17
Num Replica Movements: 42
On Demand Balancedness Score After: 83.92687872002556
On Demand Balancedness Score Before: 80.87946050436929
Provision Recommendation:
Provision Status: RIGHT_SIZED
Recent Windows: 1
Session Id: cc73d00a-0d49-41cb-b589-9b9efb042f6d
Events: <none>
この Kafka クラスターではまだ何のイベントも処理していませんので、Intra Broker Data To Move MB は 0MB ですが、42 の Replica の移動が提案されました。
リバランス提案を承認し、適用するには kubectl annotate で approve します。
$ kubectl annotate kafkarebalance my-rebalance strimzi.io/rebalance=approve -n my-kafka-project
kafkarebalance.kafka.strimzi.io/my-rebalance annotated
これで、実際にリバランスが開始されます。Status は Reblancing になります。
$ kubectl describe kafkarebalance my-rebalance -n my-kafka-project
(..)
Status:
Conditions:
Last Transition Time: 2022-05-25T09:12:36.842261Z
Status: True
Type: Rebalancing
完了すると Status が Ready になります。
$ kubectl describe kafkarebalance my-rebalance -n my-kafka-project
(..)
Status:
Conditions:
Last Transition Time: 2022-05-25T09:15:22.110294Z
Status: True
Type: Ready
以上のように、Strimzi に組み込まれた Cruise Control により、リバランスのオペレーションはかなり楽になっています。
この例では、デフォルトの Goal を使用しましたが、個別の Goal を設定するサンプルや Broker を追加・削除する際のサンプルなども提供されています。
Strimzi の様々な Operator や Configuration
#Strimzi の Kafka の運用に必要な様々な Operator や Configurationが実装されています。これらは namespace kafka にデプロイされた CRD により実現されています。
Operators
- Cluster Operator
- Entity Operator
- Topic Operator
- User Operator
Configuration
- Cluster configuration
- MirrorMaker configuration
- Kafka Connect configuration
以前紹介した Debezium も Kafka Connect であり、Configuration でインストール可能です。
詳細は、ドキュメントを参照してください。
Strimzi Overview guide (0.29.0)
まとめ
#以上のように、Strimzi は Kafka を Kubernetes で運用する上で必要になる様々な Operator や Configuration が実装されており、面倒なリバランス処理も自動化できる優れた OSS です。Kafka のような複雑な構成のアプリケーションもこういった Operator により、Kubernetes 上で運用でき、コンテナ化の恩恵を得ることができます。