在 AWS 上打造专属于你的 LLM 环境!EC2 GPU 实例与 Ollama 运行 AI 的实战指南
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
简介
#“想在云端轻松借用 GPU,运行最新的 LLM(大规模语言模型)!”
带着这样的想法,我尝试使用 AWS 的 EC2 GPU 实例 + Ollama,搭建开源 LLM 运行环境。本文将结合笔记,介绍当时的操作步骤及收获的经验。
✔️ STEP 1:EC2 实例类型的选择
#首先,要选择作为 LLM 舒适运行的“核心”EC2 实例。
使用 Ollama 即使只有 CPU 也能运行 LLM,但若有足够 VRAM(显存)的 GPU,则可享受到加速带来的优势。
这次我打算运行最近由 OpenAI 开源且可通过 Ollama 使用的 gpt-oss 模型,其 20B 参数模型至少需要 14GB 的 VRAM,因此选择满足此条件的 EC2。
从 AWS 管理控制台打开 EC2 实例类型列表,可按区域查看各实例类型的性能和价格,便于比较。
在过滤器中设置“GPU >= 1”即可列出搭载 GPU 的类型。
显示示例
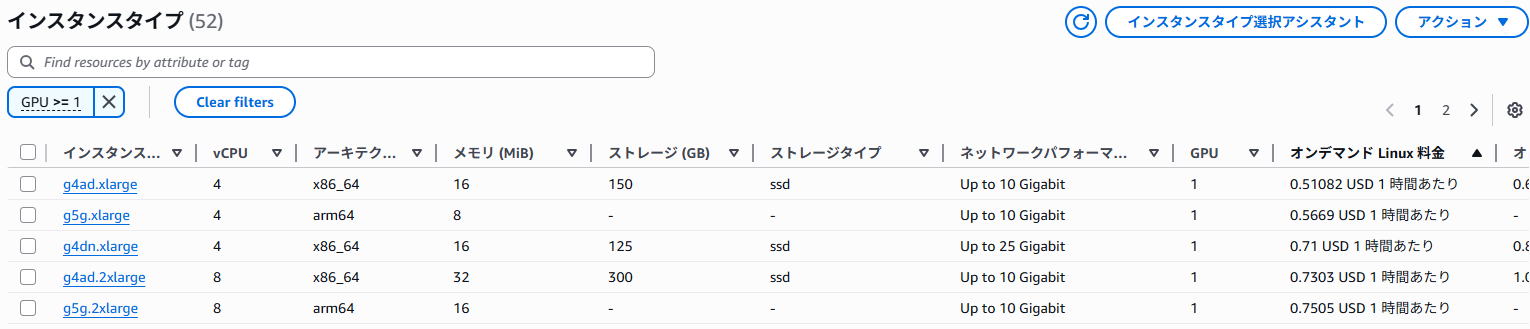
这次我选择了 NVIDIA GPU 且支持 Windows 的、价格最便宜且拥有足够 VRAM 的 g4dn.xlarge 进行验证。
✔️ STEP 2:设置 EC2 实例
#确定实例类型后,开始实际启动 EC2。
⚠️ 事前准备:提高服务配额
#首次使用 GPU 实例时,AWS 账户可启动的 vCPU 总数上限可能为 0,此时无法启动实例。
请在“Service Quotas”页面申请提高“Running On-Demand G and VT instances”的配额。我申请后次日即获批准。
若达到配额上限,启动 EC2 实例时会出现如下错误并启动失败:
You have requested more vCPU capacity than your current vCPU limit of 0 allows for the instance bucket that the specified instance type belongs to. Please visit http://aws.amazon.com/contact-us/ec2-request to request an adjustment to this limit.
创建实例
#按以下配置启动 EC2 实例:
- 名称:如
gpu-demo,便于识别。 - AMI:选择 Microsoft Windows Server 2025 Base。
- 本次为了方便测试选择了 Windows,当然也可以在 Linux 上构建。
- 实例类型:选择 g4dn.xlarge。
- 密钥对:根据需要指定登录用密钥对。
- 安全组:
- 添加入站规则,允许从合适的来源通过 RDP(端口 3389)连接。
- 存储:考虑到模型下载,设置为 60GB。
设置完成后,启动实例。启动后,从 EC2 控制台用密钥对解密 Windows 管理员密码,通过远程桌面连接。
由于操作系统语言默认为英文,请安装日语语言包。
✔️ STEP 3:安装和优化 GPU 驱动
#刚连接到 Windows Server 时,操作系统尚未识别 GPU。需要安装 NVIDIA 官方驱动,并进行设置以最大限度发挥 GPU 性能。
安装驱动
#按照 AWS 文档 的步骤进行安装。驱动类型有多种,本次选用针对数值计算任务优化的 Tesla 驱动。
- 在 EC2 实例内的浏览器中访问 NVIDIA 驱动下载页面。
- 由于
g4dn实例搭载的 GPU 为 Tesla T4,按照以下条件搜索:- Product Category: Data Center / Tesla
- Product Series: T-Series
- Product: Tesla T4
- Operating System: Windows Server 2025
搜索界面
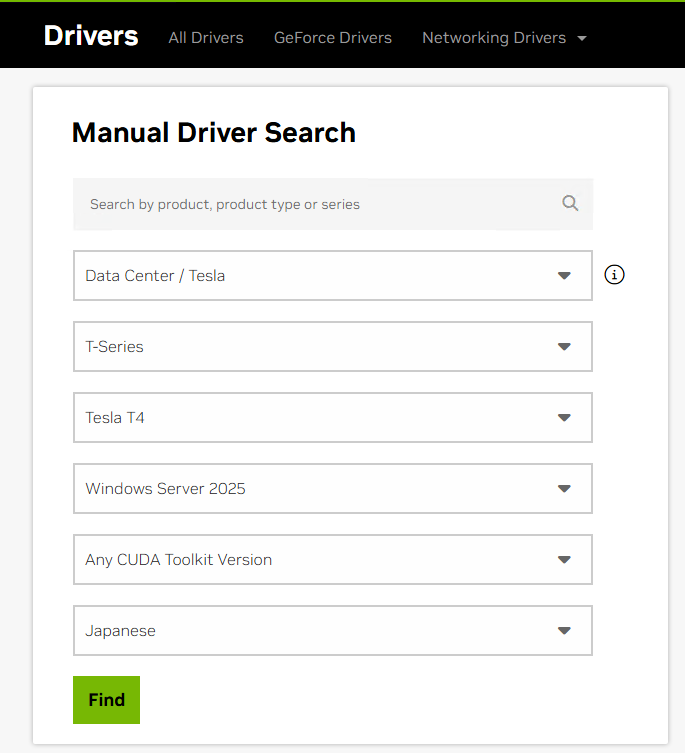
- 从搜索结果中下载最新驱动。
- 运行下载的安装程序(例如:
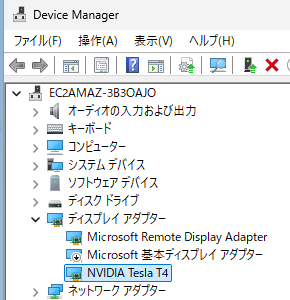
580.88-data-center-tesla-desktop-winserver-2022-2025-dch-international.exe),并选择“快速(推荐)”选项进行安装。 - 安装后,打开设备管理器,确认“显示适配器”下已显示“NVIDIA Tesla T4”。
- 禁用原有的“Microsoft 基本显示适配器”。
- 重启实例。
参考:设备管理器界面
验证运行与优化
#打开 PowerShell,执行 nvidia-smi 命令,确认 GPU 是否被正确识别。
PS C:\> nvidia-smi
Mon Aug 18 18:12:55 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.88 Driver Version: 580.88 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 TCC | 00000000:00:1E.0 Off | 0 |
| N/A 27C P8 11W / 70W | 9MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
如果能看到 Tesla T4 并且内存显示为 15360MiB(约 15GB),则表示成功!
此外,按照 AWS 文档,优化 GPU 的时钟频率。将应用程序运行时的内存最高时钟频率设置为 Tesla T4 的内存最大频率 5001MHz,GPU 最大频率 1590MHz。
参考:Tesla T4 规格书(PDF)
PS C:\> nvidia-smi -ac "5001,1590"
Applications clocks set to "(MEM 5001, SM 1590)" for GPU 00000000:00:1E.0
All done.
在 Windows 下,你可能希望在任务管理器的性能界面查看 GPU 使用率等信息。然而,Tesla 驱动以 TCC 模式(Tesla Compute Cluster)运行,该模式针对数值计算任务进行了优化,任务管理器不支持监控显示。
任务管理器支持在 WDDM 模式(Windows 显示驱动模型)下运行的 GPU 的监控显示。
✔️ STEP 4:设置 Ollama 并运行模型
#终于开始设置用于运行 LLM 的应用程序 Ollama。
- 从 Ollama 官方网站 下载 Windows 安装程序并进行安装。
- 安装完成后会打开 Ollama 的 GUI 界面,由于我们需要指定更多选项重新启动,先关闭该窗口,右下角托盘中点击 Ollama 图标,选择“Quit Ollama”退出。
配置 Ollama 启动
#为了从外部机器通过 REST API 使用 Ollama,并使模型常驻内存以加快后续响应,需要设置环境变量后启动。
OLLAMA_HOST="0.0.0.0:11434":绑定 Ollama 服务器对外提供服务的地址。OLLAMA_KEEP_ALIVE=-1:将加载的模型常驻内存,以加快后续响应。(也可以指定保持时间,如5m。默认值为 5 分钟。)
在 PowerShell 中执行以下命令:
$Env:OLLAMA_HOST="0.0.0.0:11434"
$Env:OLLAMA_KEEP_ALIVE=-1
ollama serve
这样便启动了 Ollama 服务器,开始等待请求并输出日志。
运行并验证模型
#下载 gpt-oss 模型。在另一个 Powershell 中执行以下命令:
ollama pull gpt-oss
向 LLM 发送一次聊天请求试试。
PS C:\> ollama run gpt-oss "你好"
Thinking...
The user says "こんにちは" which is "Hello" in Japanese. We respond appropriately. Probably respond in Japanese: "こ
んにちは! 今日はどんなご用件でしょうか?" or something friendly. Use Japanese.
...done thinking.
你好!
有什么可以帮忙的吗?请随时告诉我。
首次请求由于需要将模型加载到 VRAM,开始输出回答大约耗时 1 分钟左右。第二次及以后响应速度非常快。
再来测试一下通过 REST API 发送请求。
PS C:\> curl.exe http://localhost:11434/api/chat -d '{
>> ""model"": ""gpt-oss"",
>> ""messages"": [
>> { ""role"": ""user"", ""content"": ""你好"" }
>> ]
>> }'
{"model":"gpt-oss","created_at":"2025-08-19T02:10:00.5615556Z","message":{"role":"assistant","content":"","thinking":"The"},"done":false}
{"model":"gpt-oss","created_at":"2025-08-19T02:10:00.6037637Z","message":{"role":"assistant","content":"","thinking":" user"},"done":false}
{"model":"gpt-oss","created_at":"2025-08-19T02:10:00.6455317Z","message":{"role":"assistant","content":"","thinking":" says"},"done":false}
...省略
{"model":"gpt-oss","created_at":"2025-08-19T02:10:03.2187345Z","message":{"role":"assistant","content":"你好"},"done":false}
{"model":"gpt-oss","created_at":"2025-08-19T02:10:03.2632367Z","message":{"role":"assistant","content":"!"},"done":false}
{"model":"gpt-oss","created_at":"2025-08-19T02:10:03.3068154Z","message":{"role":"assistant","content":"今天"},"done":false}
同样响应正常且非常迅速,大约达到 20 个 token/秒。
执行聊天请求后,通过 nvidia-smi 检查 GPU 状态,可以看到 Ollama 的进程占用了大量 GPU 内存。本次约消耗 13.6GB,GPU 得到充分利用。
PS C:\> nvidia-smi
Wed Aug 20 15:01:18 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.88 Driver Version: 580.88 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 TCC | 00000000:00:1E.0 Off | 0 |
| N/A 32C P0 26W / 70W | 13699MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 4400 C ...al\Programs\Ollama\ollama.exe 13666MiB |
+-----------------------------------------------------------------------------------------+
✔️ STEP 5:从本地终端访问 LLM
#最后,让我们尝试从本地终端访问已搭建的 LLM 环境。
服务器端设置
#在配置 Ollama 启动时已将服务器绑定到 0.0.0.0:11434,现在需要配置通信路径。
- EC2 安全组:在入站规则中添加允许来自本地终端 IP 地址访问 自定义 TCP 端口
11434的规则。 - Windows 防火墙:在 EC2 实例内打开 Windows Defender 防火墙设置,添加允许
11434端口入站的新规则。
客户端执行
#使用 curl 命令,向 EC2 的公有 IP 地址发送请求。
curl.exe http://EC2 的公有 IP 地址:11434/api/chat -d '{
""model"": ""gpt-oss"",
""messages"": [
{ ""role"": ""user"", ""content"": ""你好"" }
]
}'
如果能成功收到响应,则说明设置完成!
总结
#本次介绍了使用 AWS EC2 g4dn.xlarge 实例和 Ollama,在 Windows 环境下构建自有 LLM 运行平台的步骤。
- 合理选择实例非常重要(g4dn 性价比高!)。
- 需要手动安装 GPU 驱动。
- 使用 Ollama,模型管理和提供 API 非常简单。
- 不要忘记配置安全组和防火墙。
借助 GPU 的加速,能够获得非常快速的响应。首次加载模型需要一定时间,但加载完成后即可流畅运行。希望本文能为大家构建 LLM 环境提供参考。