使用本地LLM进行Boid仿真(llama.cpp、llama-cpp-python)
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
这是isデベロッパーサイトアドベントカレンダー2024第19天的文章。
前言
#你好,我是大久保,延续了前回和前々回,使用 PyGame 进行娱乐……也就是仿真。这一次,我尝试结合近年来快速发展的生成型AI领域,对Boid模型进行仿真。
“使用生成AI是不是意味着要购买昂贵的GPU,或者花钱使用API呢?”你或许会这么认为,但实际上,即使在本地PC(CPU)上也能实现。 因此,这次我想介绍利用开源LLM在本地笔记本电脑(Windows11)上进行仿真的方法。
具体来说,我使用了名为llama-cpp-python的库,通过量化后的LLM来驱动Boid模型。
在本地LLM输出时可能会有些卡顿,但它会根据生成的指令进行动作。 这是经过反复尝试最终实现的方法,可能存在不尽完美之处,如果你感兴趣,请读到最后,我会很高兴。
本文中,首先我会选择本地LLM,寻找一种负载较低并在CPU上也能流畅运行的模型。 在此过程中,我采用了llama-cpp-python这个库,下面简单介绍一下。 其次,讨论一下这次仿真中使用的Boid模型的实现方法,最后总结结果。
源码也已在GitHub上公开,如果能去看看,我将非常感激。
本地LLM的选择
#模型候选
#那么,现在开始为在仿真中使用本地LLM选择模型吧。 这次考虑在笔记本电脑上进行仿真,因此我会寻找轻量且能在CPU上运行的模型。 只要能对输入给出动作指令即可,因此模型的精度要求也适中。
在这其中,我选定了以下模型作为候选。
・Gemma-2-2b-it
・Llama-3.2-1B-Instruct
Gemma2 是 Google 开发的轻量且高性能的开源LLM。 “2b”意味着该模型拥有20亿参数,是Gemma2中最轻量的,而“it”表示该模型经过指令学习。 指令学习模型就是指能够根据人类指令给出回答的模型,就像 ChatGPT 那样,在本文中这样理解即可!
另一方面,LLaMA3 是 Meta 公司开发的开源LLM。 这款模型同样是最新的,因此性能相当高。 在LLaMA3中,针对智能手机的使用目标,还提供了参数更少的轻量化模型,有1B和3B两个版本。 这次我将使用其中最轻量的1B版本。同样,“Instruct”与Gemma2中的含义一样,指指令学习模型。
现在来试用这些模型。 由于预期在CPU上使用,我从Hugging Face下载了目标模型并进行试用。
将下载的模型放在 model 目录中,然后执行以下源码。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import time
model_id = "model/google/gemma-2-2b-it"
# model_id = "model/meta-llama/Llama-3.2-1B-Instruct"
def main():
start_time_1 = time.time()
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map = "cpu",
)
end_time_1 = time.time()
print("------------------------------")
print("模型加载时间 ", end_time_1 - start_time_1)
print("------------------------------")
start_time_2 = time.time()
prompt = [
{
"role": "user",
"content": "Please explain machine learning."
}
]
inputs = tokenizer.apply_chat_template(
prompt,
return_tensors="pt",
add_generation_prompt=True,
return_dict=True
).to("cpu")
outputs = model.generate(
**inputs,
max_new_tokens=256)
generated_text = tokenizer.batch_decode(outputs[:, inputs['input_ids'].shape[1]:], skip_special_tokens=True)[0]
print(generated_text.strip())
end_time_2 = time.time()
print("------------------------------")
print("回答时间 ", end_time_2 - start_time_2)
print("------------------------------")
if __name__ == '__main__':
main()
执行结果
#------------------------------
模型加载时间 25.756981372833252
------------------------------
## Machine Learning: Teaching Computers to Learn
Imagine teaching a dog a new trick. You show them what to do, reward them when they get it right, and correct them when they make mistakes. Over time, the dog learns the trick.
Machine learning is similar. Instead of a dog, we have a computer, and instead of a trick, we have a task. We feed the computer a lot of data, and it learns to identify patterns and make predictions based on that data.
**Here's a breakdown:**
**1. Data:** The foundation of machine learning is data. This can be anything from images and text to numbers and sensor readings. The more data you have, the better your machine learning model will perform.
**2. Algorithms:** These are the "recipes" that tell the computer how to learn from the data. There are many different types of algorithms, each suited for different tasks. Some common ones include:
* **Supervised learning:** The algorithm is trained on labeled data, meaning each data point has a known outcome. It learns to predict the outcome for new, unseen data. Examples: image classification, spam detection.
* **Unsupervised learning:** The algorithm is trained on unlabeled data. It
------------------------------
回答时间 197.1345989704132
------------------------------
------------------------------
模型加载时间 5.21970796585083
------------------------------
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
Machine learning is a subfield of artificial intelligence (AI) that involves training algorithms to learn from data and make predictions or decisions without being explicitly programmed. The goal of machine learning is to enable computers to improve their performance on a task over time, based on the data they have been trained on.
There are several key concepts in machine learning:
1. **Data**: Machine learning requires a large amount of data to train the algorithms. This data can be in the form of images, text, audio, or other types of data.
2. **Algorithms**: Machine learning algorithms are the building blocks of machine learning. These algorithms can be used to classify data, make predictions, or take actions based on the data.
3. **Training**: Training is the process of feeding the data to the algorithm and adjusting its parameters to make it more accurate. The goal of training is to minimize the error between the predicted and actual outputs.
4. **Model**: A model is a mathematical representation of the algorithm that can be used to make predictions or decisions. The model is trained on the data and can be used to classify new data or make predictions.
5. **Evaluation**: Evaluation is the process of assessing the performance of the model. This can be done using metrics such as accuracy, precision
------------------------------
回答时间 38.5177276134491
------------------------------
由于输出令牌数设置为 max_new_tokens=256,因此两者的回答都在中途被截断,但在精度方面两者都毫无问题。 总体来说,Gemma的回答更富有幽默感,更有趣。
但将模型加载时间和回答时间汇总如下。
| 模型 | 加载时间 | 回答时间 |
|---|---|---|
| Gemma-2-2b-it | 约25.8秒 | 约197秒 |
| Llama-3.2-1B-Instruct | 约5.21秒 | 约38.5秒 |
唔……比预期的要慢……。 就连 LLaMA-3.2-1B 的回答时间也要约38.5秒,所以用它来进行仿真似乎相当吃力。 CPU负载也非常高,特别是在使用Gemma2时。
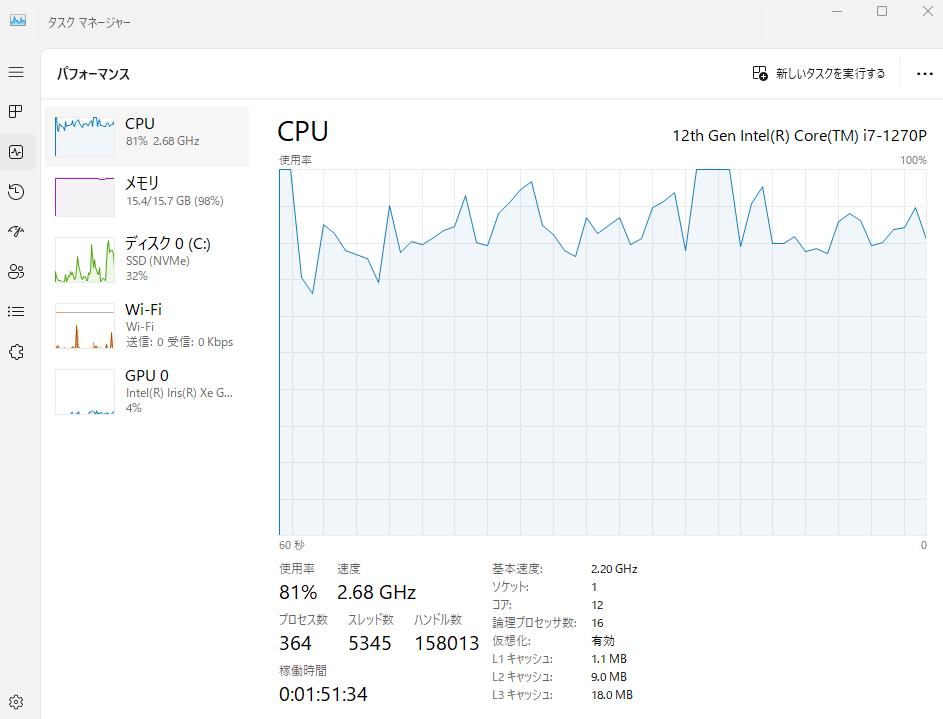
如果回答时间能更快一些,负载更低些,就能实现流畅的仿真了。
使用 llama.cpp
#因此,当我在寻找更轻量的模型时,发现了一个可以在本地运行LLM的库。 它的名字就叫「llama.cpp」。 这个库可以在CPU上运行经过2~8位整数量化的模型。 由于以「llama」命名,当然可以使用LLaMA模型,而且只要是GGUF格式,其他LLM也都能使用。
针对 Python 也有一个名为 llama-cpp-python 的库,接下来我们就安装并试用一下。
pip install llama-cpp-python
在 Hugging Face 上也有将 Gemma、LLaMA 等LLM量化并转换为GGUF格式的模型,可以从以下链接下载。
- Gemma2
- https://huggingface.co/mmnga/gemma-2b-it-gguf
- 使用模型:gemma-2-2b-it-Q4_K_M.gguf
- LLaMA3
- https://huggingface.co/bartowski/Llama-3.2-1B-Instruct-GGUF
- 使用模型:Llama-3.2-1B-Instruct-Q4_K_M.gguf
同样地,将下载的模型放在 model 目录中,并执行以下代码.
from llama_cpp import Llama
import time
model_path = "./model/mmnga/gemma-2-2b-it-gguf/gemma-2-2b-it-Q4_K_M.gguf"
chat_format = "gemma"
# model_path = "./model/bartowski/Llama-3.2-1B-Instruct-GGUF/Llama-3.2-1B-Instruct-Q4_K_M.gguf"
# chat_format = "llama-3"
def main():
start_time_1 = time.time()
# 加载模型和分词器
llm = Llama(
model_path=model_path,
chat_format=chat_format,
n_gpu_layers=-1,
n_ctx=512
)
end_time_1 = time.time()
print("------------------------------")
print("模型加载时间 ", end_time_1 - start_time_1)
print("------------------------------")
start_time_2 = time.time()
prompt = [
{
"role": "user",
"content": "Please explain machine learning."
}
]
outputs = llm.create_chat_completion(
messages=prompt,
max_tokens=256,
temperature=0.7
)
print("------------------------------")
print(outputs["choices"][0]["message"]["content"])
print("------------------------------")
end_time_2 = time.time()
print("------------------------------")
print("回答时间 ", end_time_2 - start_time_2)
print("------------------------------")
if __name__ == '__main__':
main()
执行结果
#~~~略~~~
------------------------------
模型加载时间 0.5315546989440918
------------------------------
llama_perf_context_print: load time = 451.43 ms
llama_perf_context_print: prompt eval time = 0.00 ms / 14 tokens ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: eval time = 0.00 ms / 255 runs ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: total time = 13714.50 ms / 269 tokens
------------------------------
Imagine you're teaching a dog a new trick. You show it what to do, reward it when it gets close, and correct it when it makes a mistake. Over time, the dog learns the trick.
Machine learning is a bit like that, but instead of a dog, we have a computer program.
**Here's the basic idea:**
* **Data is the key:** Machine learning algorithms learn from data. The more data they receive, the better they become at their tasks.
* **Algorithms learn patterns:** These algorithms are like mini-brains that process data and find patterns.
* **Predictions and improvement:** The algorithms use these patterns to make predictions about new, unseen data. They can also learn and improve their performance over time.
**Here's a breakdown of the main types of machine learning:**
**1. Supervised Learning:**
* **Humans provide labelled data:** Think of it like teaching the dog with pictures labeled "good dog" or "bad dog."
* **Algorithms learn the relationship:** The algorithm learns the relationship between input features (like the dog's posture) and the corresponding output (is it a good or bad dog).
* **Examples:** Predicting house
------------------------------
------------------------------
回答时间 13.719425916671753
------------------------------
~~~略~~~
------------------------------
模型加载时间 0.8961973190307617
------------------------------
llama_perf_context_print: load time = 223.75 ms
llama_perf_context_print: prompt eval time = 0.00 ms / 15 tokens ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: eval time = 0.00 ms / 255 runs ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: total time = 6303.49 ms / 270 tokens
------------------------------
Machine learning! It's a fascinating field that has revolutionized the way we approach data analysis, decision-making, and problem-solving. I'd be happy to explain machine learning in simple terms.
**What is Machine Learning?**
Machine learning is a subset of artificial intelligence (AI) that involves training algorithms to learn from data, make predictions, or take actions without being explicitly programmed. It's a type of statistical learning that enables computers to improve their performance on a task over time, based on data.
**Key Concepts:**
1. **Supervised Learning:** The goal is to teach a model to learn from labeled data, where the correct output is already known.
2. **Unsupervised Learning:** The goal is to identify patterns or structure in unlabeled data.
3. **Reinforcement Learning:** The goal is to train a model to make decisions based on feedback from rewards or penalties.
**How Machine Learning Works:**
1. **Data Collection:** Gather a large dataset, which can be in the form of images, text, audio, or any other type of data.
2. **Data Preprocessing:** Clean, transform, and normalize the data to prepare it for analysis.
3. **Model Selection:** Choose a suitable algorithm, such as linear regression, decision
------------------------------
------------------------------
回答时间 6.306737899780273
------------------------------
同样由于输出令牌数设定为 max_tokens=256,因此两者的回答都在中途被截断,但精度方面都毫无问题。 其实感觉两者差别不大!
另外,将模型加载时间和回答时间汇总如下。
| 模型 | 加载时间 | 回答时间 |
|---|---|---|
| Gemma-2-2b-it | 约0.531秒 | 约13.7秒 |
| Llama-3.2-1B-Instruct | 约0.896秒 | 约6.30秒 |
速度太快了! 理想情况下喜欢达到小数点后几秒的速度,负载低且精度尚可,这样的速度在仿真中使用应该没问题。 因此,这次我打算使用最快的「Llama-3.2-1B-Instruct」进行仿真。
仿真
#前期准备(创建 Boid、食物、敌人模型)
#那么,现在开始用 PyGame 创建仿真吧。 本次的目标是创建一个能够根据本地LLM生成指令进行动作的 Boid 模型。 仿真的流程预期如下:
- 仿真开始时,会布置食物、敌人和 Boid。
- Boid 将获取食物和敌人的位置信息。
- 将食物和敌人的位置信息输入本地LLM。
- 本地LLM基于这些信息生成 Boid 的动作。
- Boid 将按生成的指令行动。
- 通关条件:吃掉所有布置的食物。游戏失败条件:Boid 的HP降为0。
为了实现以上流程,作为前期准备,我将创建 Boid 模型(bird.py)和 main.py。
创建 Boid 模型
#import pygame
import random
import json
import numpy as np
BIRD_COLORS = [
'#FFA5CC', # 粉色
'#80FF25', # 绿色
'#A0D4FF', # 天蓝
]
# HP
HEALTH_POINT = 500
# 鸟模型
class Bird:
def __init__(self,
bird_id,
width,
height
):
self.bird_id = bird_id
self.width = width
self.height = height
# 位置
self.position = np.array([random.uniform(0, width), random.uniform(0, height)])
# 速度与角度
self.velocity = 0.0
self.angle = np.radians(0)
self.direction = np.array([np.cos(self.angle), np.sin(self.angle)])
# 鸟的HP
self.health_point = HEALTH_POINT
# 鸟的形状
self.polygon = np.array([(20, 0), (0, 5), (0, -5)])
self.type_id = self.bird_id % 3
self.color = BIRD_COLORS[self.type_id]
# 动作
def move(self):
self.direction = np.array([np.cos(self.angle), np.sin(self.angle)])
# 根据速度向量确定前进方向。
vector = self.velocity * (self.direction)
if np.linalg.norm(vector) != 0:
self.position += vector
# 当鸟撞到墙时,从对岸穿过
if self.position[0] > self.width or self.position[0] < 0:
self.position[0] = np.abs(self.position[0] - self.width)
if self.position[1] > self.height or self.position[1] < 0:
self.position[1] = np.abs(self.position[1] - self.height)
def display(self, screen):
# 构建旋转矩阵
rotation_matrix = np.array([[np.cos(self.angle), -np.sin(self.angle)],
[np.sin(self.angle), np.cos(self.angle)]])
# 旋转使头部朝向前进方向。
rotated_polygon = np.dot(self.polygon, rotation_matrix.T) + self.position
pygame.draw.polygon(screen, self.color, rotated_polygon, 0)
在 Boid 模型的初始值中,定义了HP、初始位置、初始速度和角度。 然后在 move() 方法中,Boid 根据速度和角度进行移动。
创建食物和敌人模型
#接下来创建食物和敌人的模型。
・食物(food.py):吃后,使 Boid 的HP增加的对象(不移动)
・敌人(enemy.py):碰撞时,使 Boid 的HP减少的对象(不移动)
这次为了简单,仿真中食物和敌人都不会移动。
import pygame
FOOD_POWER = 150
RADIUS_OF_FOOD = 10
# 食物
class Food:
def __init__(self, x, y, food_power=FOOD_POWER):
self.x = x
self.y = y
self.power = food_power
self.radius = RADIUS_OF_FOOD
self.eaten = False
def move(self):
pass
def display(self, screen):
pygame.draw.circle(screen, (0, 0, 255), (int(self.x), int(self.y)), self.radius)
import pygame
ENEMY_POWER = 250
RADIUS_OF_ENEMY = 10
# 敌人
class Enemy:
def __init__(self, x, y, enemy_power=ENEMY_POWER):
self.x = x
self.y = y
self.power = enemy_power
self.radius = RADIUS_OF_ENEMY
self.clashed = False
def move(self):
pass
def display(self, screen):
pygame.draw.rect(screen, (255, 0, 0), (int(self.x), int(self.y), self.radius * 2, self.radius * 2))
请理解食物和敌人中的 POWER 分别表示它们所具有的力量。 对于食物来说,当 Boid 碰到食物时,会按 POWER 的数值恢复HP; 对于敌人,则当 Boid 与敌人碰撞时,HP 会按 POWER 的数值减少。 RADIUS 表示食物或敌人的尺寸,即被判定为碰撞的半径。
基于以上内容,将为 Boid 模型增加搜索食物与敌人、进食等规则。
# 鸟模型
class Bird:
def __init__(self,
bird_id,
width,
height,
ai_model
):
#
# 省略
#
# 初始值
self.food_param = RADIUS_OF_FOOD
self.food_positions = []
self.enemy_param = RADIUS_OF_ENEMY
self.enemy_positions = []
#
# 省略
#
# 食物的搜索规则
def search_food(self, food_list):
# 搜索范围
radius = self.food_param
# 自己的位置
x = self.position[0]
y = self.position[1]
# 获取靠近鸟的食物。
near_food = [food for food in food_list
if np.linalg.norm(np.array([food.x, food.y]) - np.array([x, y])) < radius
and not food.eaten
]
# 计算鸟和食物的相对位置。
relative_food_positions = []
if len(near_food) > 0 :
for food in near_food:
food_position = np.array([food.x, food.y]) - np.array([x, y])
# 极坐标转换
r = np.linalg.norm(food_position)
theta = np.degrees(np.arctan2(food_position[1], food_position[0]))
relative_food_positions.append({
"angle" : theta,
"distance" : r
})
self.food_positions = relative_food_positions
# 进食规则
def eat_food(self, food_list):
# 吃食物
x = self.position[0]
y = self.position[1]
# 获取靠近鸟的食物。
near_foods = [food for food in food_list
if np.linalg.norm(np.array([food.x, food.y]) - np.array([x, y])) < food.radius
and not food.eaten
]
# 如果存在食物,则进食。
if len(near_foods) > 0:
first_near_food = near_foods[0]
self.health_point += first_near_food.power
first_near_food.eaten = True
print(f'餌を食べました。HP:{self.health_point}')
# 敌人的搜索规则
def search_enemy(self, enemy_list):
# 搜索范围
radius = self.enemy_param
# 自己的位置
x = self.position[0]
y = self.position[1]
# 获取靠近鸟的敌人。
near_enemy = [enemy for enemy in enemy_list
if np.linalg.norm(np.array([enemy.x, enemy.y]) - np.array([x, y])) < radius
]
# 计算鸟与敌人的相对位置。
relative_enemy_positions = []
if len(near_enemy) > 0 :
for enemy in near_enemy:
enemy_position = np.array([enemy.x, enemy.y]) - np.array([x, y])
# 极坐标转换
r = np.linalg.norm(enemy_position)
theta = np.degrees(np.arctan2(enemy_position[1], enemy_position[0]))
relative_enemy_positions.append({
"angle" : theta,
"distance" : r
})
self.enemy_positions = relative_enemy_positions
# 与敌人碰撞。
def clash_enemy(self, enemy_list):
x = self.position[0]
y = self.position[1]
# 获取靠近鸟的敌人。
near_enemies = [enemy for enemy in enemy_list
if np.linalg.norm(np.array([enemy.x, enemy.y]) - np.array([x, y])) < enemy.radius
]
# 若与敌人碰撞,则降低HP。
if len(near_enemies) > 0:
# 筛选出尚未发生碰撞的敌人。
not_clash_near_enemies = [enemy for enemy in near_enemies if not enemy.clashed]
if len(not_clash_near_enemies) > 0:
first_near_enemy = not_clash_near_enemies[0]
self.health_point -= first_near_enemy.power
first_near_enemy.clashed = True
print(f'敵に当たりました。HP:{self.health_point}')
else:
for enemy in enemy_list:
enemy.clashed = False
在 Boid 模型的初始值中会包含搜索范围以及存储搜索结果的列表。 在搜索食物或敌人时,会基于搜索范围查找附近的对象,并将搜索结果经过极坐标转换后以如下字典形式返回:
relative_food_positions.append({
"angle" : theta,
"distance" : r
})
这样做是为了将来将这些信息输入到本地LLM中。
main.py 的实现
#至此 Boid、食物、敌人模型的准备就绪,现在开始编写 main.py。 顺便,当所有食物被吃完后,会显示“通关”字样。
import pygame
import random
from model.bird import Bird
from model.food import Food
from model.enemy import Enemy
# 群体总数
BIRD_NUM = 1
# 食物总数
FOOD_NUM = 10
# 敌人总数
ENEMY_NUM = 10
# 颜色定义
WHITE = (255, 255, 255)
BLACK = (0, 0, 0)
RED = (255, 0, 0)
# 主程序执行
def main():
pygame.init()
# 设置屏幕尺寸
width, height = 800, 600
step = 0
screen = pygame.display.set_mode((width, height))
pygame.display.set_caption("Boid Simulation")
# 游戏状态
clear_flag = False # 显示通关画面的标志
# 初始化鸟的总数
bird_num = BIRD_NUM
# HP耗尽的鸟的数量
health_point_over_number = 0
# 生成鸟
bird_list = []
for i in range(bird_num):
# 随机生成初始参数。
bird_list.append(Bird(
bird_id=i,
width=width,
height=height,
ai_model=ai_model
))
# 生成食物
food_list = []
for i in range(FOOD_NUM):
food_list.append(
Food(
id=i,
x=random.uniform(0, width),
y=random.uniform(0, height)
)
)
# 生成敌人
enemy_list = []
for i in range(ENEMY_NUM):
enemy_list.append(
Enemy(
id=i,
x=random.uniform(0, width),
y=random.uniform(0, height)
)
)
clock = pygame.time.Clock()
# 执行
while True:
# 即将死亡的鸟的列表
over_bird_list = []
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
exit()
# 通关画面
if clear_flag:
game_clear(
screen=screen,
width=width,
height=height
)
continue # 停止仿真
# 各个鸟的动作
for bird in bird_list:
# 检查目标鸟是否在已死亡列表中
targets_in_over_bird_list = [over_bird for over_bird in over_bird_list if bird.bird_id == over_bird.bird_id]
# 搜索食物
bird.search_food(food_list)
# 搜索敌人
bird.search_enemy(enemy_list)
# 行动
bird.move()
# 进食
bird.eat_food(food_list)
# 与敌人碰撞
bird.clash_enemy(enemy_list)
# 当鸟的HP耗尽时死亡
if bird.health_point <= 0 and len(targets_in_over_bird_list) <= 0:
print("health point over: %s" % bird.bird_id)
over_bird_list.append(bird)
health_point_over_number += 1
screen.fill((0, 0, 0))
# 移除已死亡的鸟
for over_bird in over_bird_list:
bird_list = [bird for bird in bird_list if not bird.bird_id == over_bird.bird_id]
# 被吃掉的食物数量
eaten_food_num = 0
# 删除被吃掉的食物
for food in food_list:
if food.eaten:
food_list.remove(food)
eaten_food_num += 1
if len(food_list) == 0:
print("クリア! 餌を全て食べることができました!")
clear_flag = True
# pygame.quit()
# break
# 随机生成食物
if len(bird_list) == 0:
print("鳥が絶滅しましたので、プログラムを終了します。")
pygame.quit()
break
# 绘制鸟
for bird in bird_list:
bird.display(screen)
# 绘制食物
for food in food_list:
food.display(screen)
for enemy in enemy_list:
enemy.display(screen)
# 在屏幕上显示设定
display_rendered_text(
screen=screen,
bird_list=bird_list,
food_list=food_list,
enemy_list=enemy_list,
health_point_over_number=health_point_over_number)
pygame.display.flip()
clock.tick(30)
step +=1
# 在屏幕上显示设定
def display_rendered_text(
screen,
bird_list,
food_list,
enemy_list,
health_point_over_number
):
font = pygame.font.Font(None, 15)
text_lines = [
"bird number: %s" % len(bird_list),
"food number: %s" % len(food_list),
"enemy number: %s" % len(enemy_list),
"health point over: %s" % health_point_over_number,
]
rendered_lines = [font.render(line, True, (255, 255, 255)) for line in text_lines]
text_position = (10, 10)
for rendered_line in rendered_lines:
screen.blit(rendered_line, text_position)
text_position =(text_position[0], text_position[1] + rendered_line.get_height())
def game_clear(
screen,
width,
height
):
font = pygame.font.Font(None, 74)
# screen.fill(BLACK)
text = font.render("GAME CLEAR", True, RED)
screen.blit(text, (width // 2 - 200, height // 2))
pygame.display.flip()
if __name__ == '__main__':
main()
运行结果如下。

显示:Boid 为粉色三角形,食物为蓝色圆形,敌人为红色正方形。 Boid、食物和敌人的位置均随机显示。 此外,通过指定初始总数,可以增加 Boid 等的数量。
# 群体总数
BIRD_NUM = 1
# 食物总数
FOOD_NUM = 10
# 敌人总数
ENEMY_NUM = 10
不过目前 Boid 模型的初始速度为 0,因此不会移动。 它只是寻找食物和敌人的位置,无法做出其他动作。 需要将搜索结果输入到本地LLM,以获取动作指令。
带有本地LLM的 Boid 模型实现
#既然为仿真做好了准备,接下来就将在上述仿真中整合本地LLM。 正如之前讨论的那样,由于已知食物及敌人的位置信息,因此模型会根据这些信息请求本地LLM给出动作指令。
from llama_cpp import Llama
import json
import time
Gemma2 = {
"model_path" : "./ai_model/mmnga/gemma-2-2b-it-gguf/gemma-2-2b-it-Q4_K_M.gguf",
"chat_format" : "gemma"
}
Llama3 = {
"model_path" : "./ai_model/bartowski/Llama-3.2-1B-Instruct-GGUF/Llama-3.2-1B-Instruct-Q4_K_M.gguf",
"chat_format" : "llama-3"
}
# 使用的AI模型
# use_model = Gemma2
use_model = Llama3
prompts = [
# 内容稍后讨论。
]
class AiAgent:
def __init__(self):
start_time_1 = time.time()
llm = Llama(
model_path=use_model["model_path"],
chat_format=use_model["chat_format"],
n_gpu_layers=-1,
# n_ctx=512
n_ctx=2048
)
end_time_1 = time.time()
print("------------------------------")
print("模型加载时间 ", end_time_1 - start_time_1)
print("------------------------------")
self.model = llm
self.prompts = prompts
# 生成
def generate(self, prompt, is_add_prompts):
start_time_2 = time.time()
print("------------------------------")
print("プロンプト: ", prompt)
print("------------------------------")
if is_add_prompts:
messages = list(self.prompts)
else:
messages = []
messages.append(prompt)
outputs = self.model.create_chat_completion(
messages=messages,
max_tokens=100,
temperature=0.7
)
output = outputs["choices"][0]["message"]["content"]
end_time_2 = time.time()
print("------------------------------")
print("回答时间 ", end_time_2 - start_time_2)
print(output)
print("------------------------------")
return output
在初始化模型时加载指定的本地LLM,随后通过 generate() 方法根据给定的提示返回回答。 Boid 模型如下所示进行修改。
# 鸟模型
class Bird:
def __init__(self,
bird_id,
width,
height,
ai_model
):
#
# 省略
#
# 生成AI模型
self.ai_model = ai_model
#
# 省略
#
# 通过生成AI给出动作指令
def generate_ai_operation(self):
data = {
"enemies": list(self.enemy_positions),
"foods": list(self.food_positions)
}
prompt = {
"role" : "user",
"content" : f'{json.dumps(data)}'
}
output = self.ai_model.generate(
prompt=prompt,
is_add_prompts=True)
# 逐行处理
for line in output.splitlines():
if "angle" in line:
output = line
break
try:
output_json = json.loads(output)
angle_degrees = output_json["angle"] if "angle" in output_json else None
self.angle = np.radians(angle_degrees) if angle_degrees is not None else self.angle
self.velocity = output_json["velocity"] if "velocity" in output_json else self.velocity
print(f'angle: {angle_degrees}, velocity: {self.velocity}')
except json.JSONDecodeError as e:
return
在 Boid 模型初始化时注入本地LLM(AiAgent类),并利用它创建生成动作指令的方法 generate_ai_operation()。 在该方法中,将此前讨论的食物和敌人的位置信息转换为 JSON 格式,并构造出本地LLM 的提示。 稍后再讨论,从返回的信息中提取 Boid 的前进方向(angle)和速度(velocity),使 Boid 按照指令移动。
对 main.py 的修改有以下两点:
- 加载本地LLM,并在 Boid 模型初始化时注入加载的本地LLM。
- 在调用
bird.move()方法之前调用generate_ai_operation()方法。
# 主程序执行
def main():
#
# 省略
#
# 加载生成AI
ai_model = AiAgent()
# 生成鸟
bird_list = []
for i in range(bird_num):
# 随机生成初始参数。
bird_list.append(Bird(
bird_id=i,
width=width,
height=height,
ai_model=ai_model
))
#
# 省略
#
# 各个鸟的动作
for bird in bird_list:
# 检查目标鸟是否在已死亡列表中
targets_in_over_bird_list = [over_bird for over_bird in over_bird_list if bird.bird_id == over_bird.bird_id]
# 搜索食物
bird.search_food(food_list)
# 搜索敌人
bird.search_enemy(enemy_list)
# 通过AI给出动作指令
if step % 100 == 0:
bird.generate_ai_operation()
# 行动
bird.move()
# 进食
bird.eat_food(food_list)
# 与敌人碰撞
bird.clash_enemy(enemy_list)
# 当鸟的HP耗尽时死亡
if bird.health_point <= 0 and len(targets_in_over_bird_list) <= 0:
print("health point over: %s" % bird.bird_id)
over_bird_list.append(bird)
health_point_over_number += 1
screen.fill((0, 0, 0))
不过,由于本地LLM生成指令需要时间,如果每次都生成会导致动作冻结,因此改为每100次循环执行一次动作指令。
用于生成动作的提示
#至此大部分实现已完成。 接下来只需让它对输入信息生成动作指令,但这实际上归结为“生成什么样的提示可以让 Boid 模型运动?”的问题。 这里的关键是“怎样的指令能让 Boid 模型运动起来”。 在此次实现中,只要给出前进方向(angle)和速度(velocity),Boid 的运动就确定了。 也就是说,本地LLM需要输出的仅仅是这两项信息。
对于食物和敌人的位置信息,理想的输出是如下 JSON 格式:
{'angle': 45, 'velocity': 4.5}
换句话说,只需要在提示中指示,让其对输入的位置信息输出这样的结果即可。
prompts = [
{
"role": "system",
"content":
"I want to determine the angle and velocity of an agent on a 2D plane based on the following rules:\n" +
"・The agent moves away from enemies based on their relative distances.\n" +
"・The agent moves toward foods based on their relative distances.\n" +
"・The agent prioritizes the closest food. However, if a food is close to an enemy, the agent avoids that food and moves to another.\n" +
"・Based on these conditions, calculate the angle and velocity.\n" +
"・The distances and angles of enemies and foods will be provided in JSON format.\n" +
"・The agent's angle and velocity should also be returned in JSON format.\n" +
"・Do not include any extra text or explanations.\n" +
"Input example:{ 'enemies': [{'angle': 0, 'distance': 2}, {'angle': 10, 'distance': 10}], 'foods': [{'angle': 45, 'distance': 400}, {'angle': 5, 'distance': 500}] }\n"
"Output example:{'angle': 45, 'velocity': 4.5}"
},
{
"role": "user",
"content":'{ "enemies": [], "foods": [] }'
},
{
"role": "assistant",
"content": '{"angle": 10, "velocity": 2.5}'
},
{
"role": "user",
"content" : '{ "enemies": [{"angle": 45, "distance": 800}], "foods": [{"angle": -45, "distance": 210.5}] }'
},
{
"role": "assistant",
"content": '{"angle": -45, "velocity": 3.01}'
},
{
"role": "user",
"content": '{ "enemies": [{"angle": 0, "distance": 2}, {"angle": 10, "distance": 10}], "foods": [{"angle": 10, "distance": 40},{"angle": 5, "distance": 5}] }'
},
{
"role" : "assistant",
"content" : '{"angle": 5, "velocity": 1.5}'
},
]
于是就如上所述构造了初始提示。 首先向本地LLM传达了 Boid 模型应按照什么规则运动。 此时,所使用的模型是一款专注于英语的模型,因此为了提高精度,提示以英语编写。 将其翻译成日语的话,大致如下:
以下のルールに従って2次元平面上のAgentのangleとvelocityを求めたい。
・Agentとenemiesのそれぞれの相対距離(distance)から判断して、enemyから逃げる。
・Agentとfoodsのそれぞれの相対距離(distance)から判断して、foodに向かう。
・Agentは最も近いfoodに向かいます。ただしfoodとenemyが近い場合、enemyを避けて別のfoodに向かいます。
・上記の条件からangleとvelocityを求める。
・enemyとfoodのdistanceとangleはJSON形式で渡します。
・AgentのangleとvelocityもJSON形式で渡します。
・余計なテキストや説明を一切含めないでください。
入力例:{ 'enemies': [{'angle': 0, 'distance': 2}, {'angle': 10, 'distance': 10}], 'foods': [{'angle': 45, 'distance': 400}, {'angle': 5, 'distance': 500}] }
出力例:{'angle': 45, 'velocity': 4.5}
虽然也可以写得更抽象,但为了让 Boid 模型能够运动,还是详细列出了具体规则。 同时,我也示例性地说明了将食物和敌人的位置信息以 JSON 格式输入,以便用于 Boid 模型得到角度和相对距离。 之后还展示了具体交互的例子,并构造了能返回理想输出结果的提示。
接下来测试一下是否能用这个初始提示生成 JSON 格式的输出。 测试用源码如下。
from model.ai_agent import AiAgent
# 测试AI模型
def main():
# 加载生成AI
ai_model = AiAgent()
prompt = {
"role" : "user",
"content" : "{ 'enemies': [{'angle': 0, 'distance': 2}, {'angle': 10, 'distance': 10}], 'foods': [{'angle': 45, 'distance': 400}, {'angle': 5, 'distance': 500}] }"
}
# 使用生成AI生成输出
ai_model.generate(prompt=prompt, is_add_prompts=True)
if __name__ == '__main__':
main()
执行结果如下。
~~~略~~~
------------------------------
模型加载时间 0.845811128616333
------------------------------
------------------------------
プロンプト: {'role': 'user', 'content': "{ 'enemies': [{'angle': 0, 'distance': 2}, {'angle': 10, 'distance': 10}], 'foods': [{'angle': 45, 'distance': 400}, {'angle': 5, 'distance': 500}] }"}
------------------------------
llama_perf_context_print: load time = 3083.65 ms
llama_perf_context_print: prompt eval time = 0.00 ms / 448 tokens ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: eval time = 0.00 ms / 14 runs ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: total time = 3419.58 ms / 462 tokens
------------------------------
回答时间 3.4229013919830322
{"angle": 45, "velocity": 2.2}
------------------------------
正如预期,输出中以 JSON 格式给出了前进方向和速度。 从输出的前进方向(angle)可以看出,它正试图向提示中较近的食物靠拢。 因此,提示看来也没问题。
执行结果
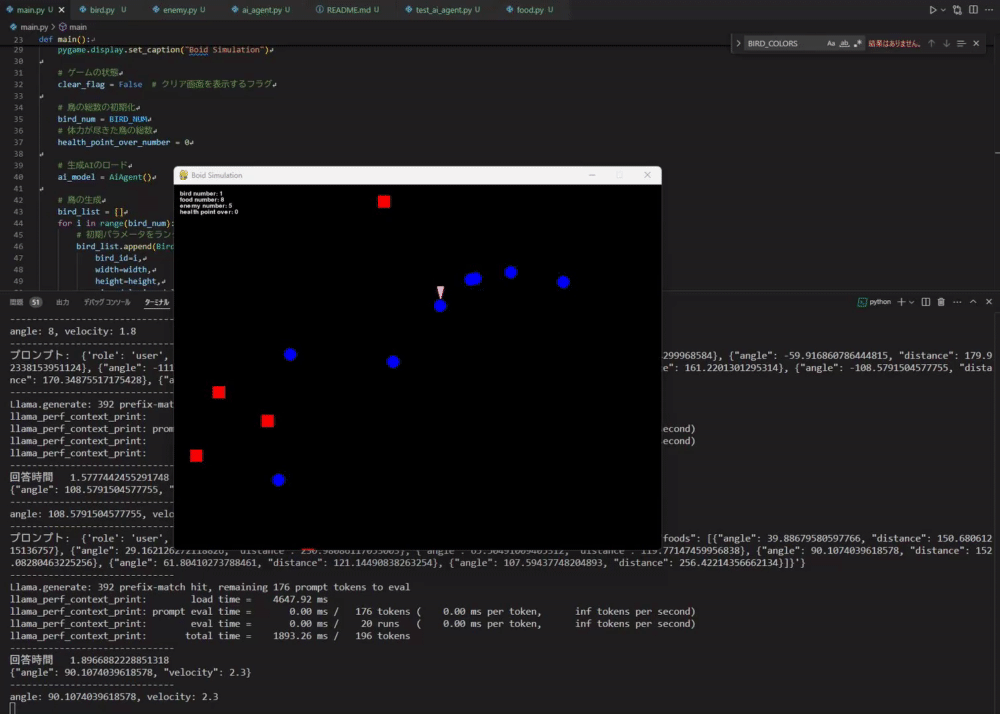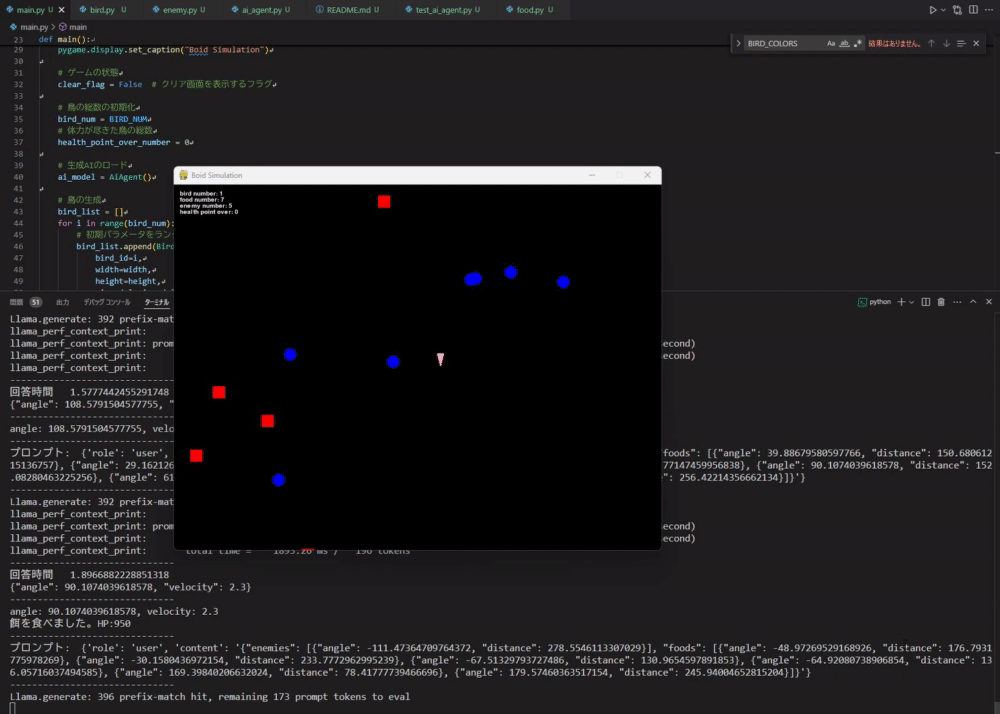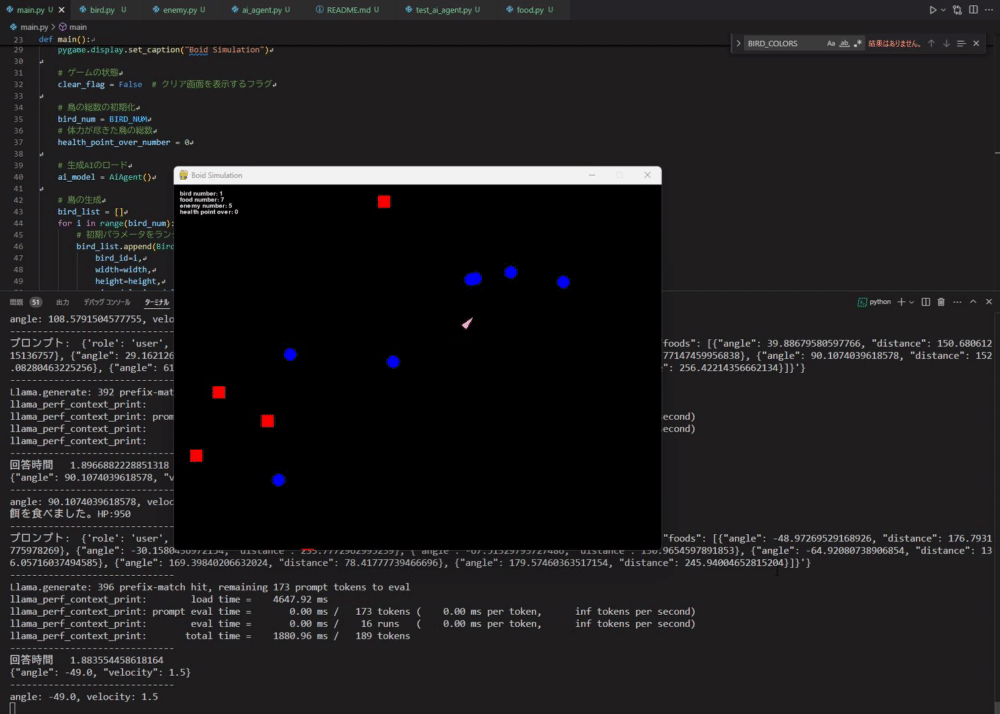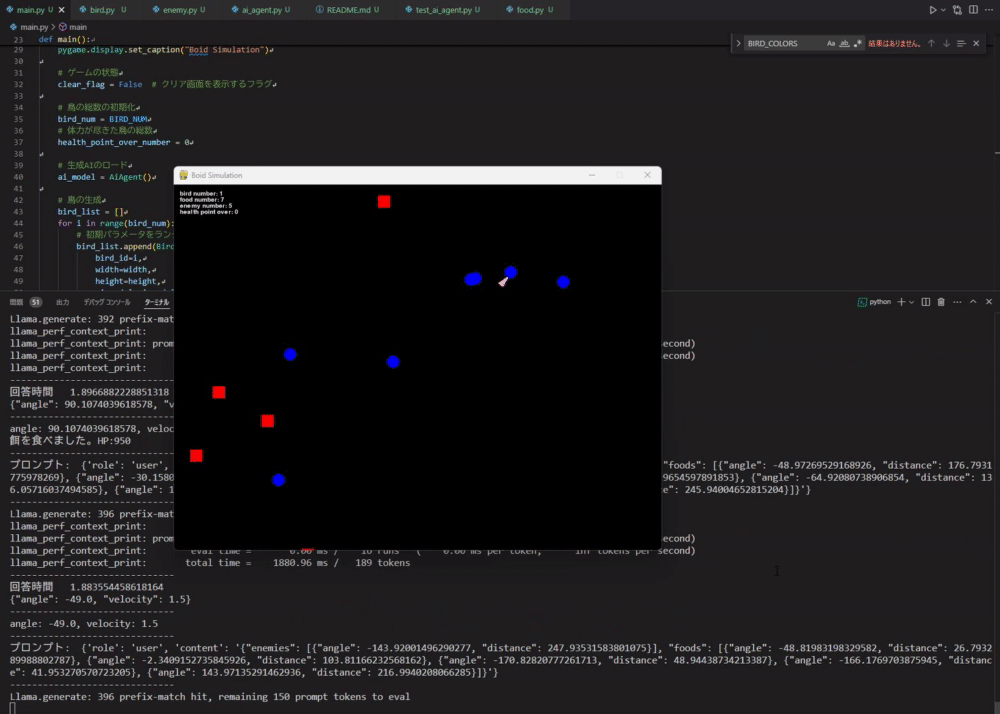
#那么,运行 main.py 看看效果吧。 这次为了简单,仿真中设定了 1 个 Boid、10 个食物、5 个敌人。
可能有点难以看出,但它确实能按照本地LLM生成的指令运动了。 它能正确地朝向食物运动,但有时也会朝向敌人,导致自我毁灭,整体表现非常有趣。 不过当周围没有食物和敌人时,它会停止运动,因此相关规则还需补充。
总结
#这次尝试利用本地LLM进行 Boid 模型仿真,即便实现简单,但能在本地PC上如此高精度地运行LLM,实在太有趣了。 今后可以尝试使用更轻量的模型,或使用负载更低的库来进行测试。 毕竟生成过程耗时较长,因此若用于游戏或仿真时,动作必然会显得迟缓。 例如,如果生成大量 Boid 并同时使其运动,负载将会相当高。 如果能解决这些问题,未来可能实现非常有趣的仿真。
另外,在这次仿真中引入类似于前回的进化式编程也非常有趣。 如何在仿真过程中让各个模型学习,可能会成为未来的课题。