使用OpenAI的Realtime API实现AI语音对话的Web应用
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
到目前为止,我已经使用OpenAI的Realtime API创建了基于CLI的语音对话脚本。
得益于音频转换工具SoX(Sound eXchange),这个脚本得以简单实现,但我仍然想尝试制作Web应用。
在这里,我们将使用Vue框架的Nuxt来创建一个可以在Web浏览器上与Realtime API进行语音对话的应用。
2024年12月18日,WebRTC版的Realtime API被引入。
由于此更新,推荐浏览器应用使用WebRTC而不是WebSocket。
有关WebRTC版的更多信息,请参见以下文章。
Web应用的构成如下所示。
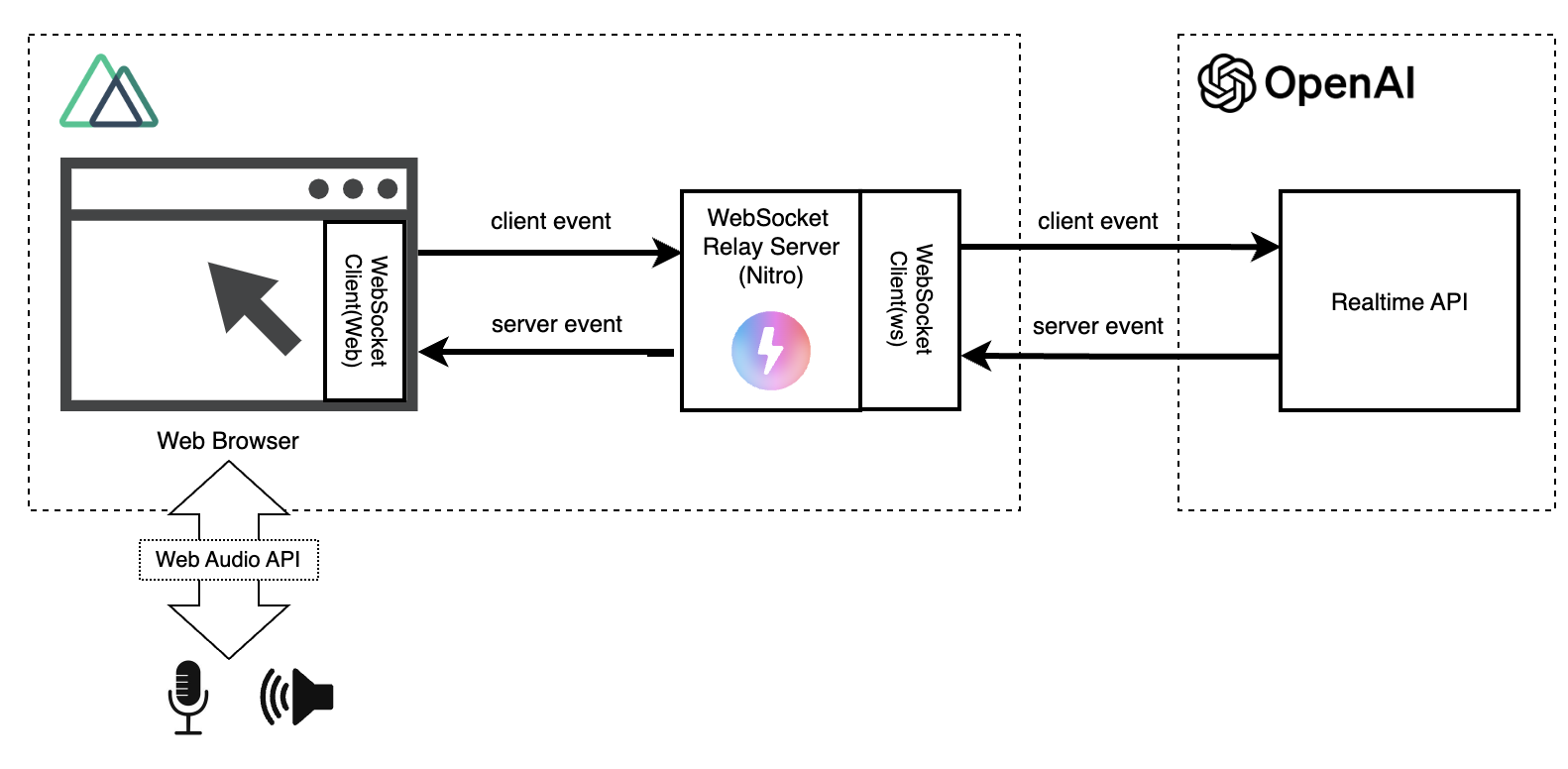
如果直接从浏览器访问Realtime API,则会暴露OpenAI的API密钥给用户。
为了避免这种情况,我们使用Nuxt的服务器功能(Nitro)来中介访问Realtime API。
以下是该Web应用运行的视频(解除静音后会发出AI的声音。请注意周围环境)。
在这段视频中(不知道为什么)我的输入声音没有被录音,但实际上我根据文本信息和声音波形进行了对话。
本文将重点放在重要部分,因此不提供所有源代码的详细说明。
源代码已在GitHub上公开,想要实际尝试的朋友可以自己运行一下(不过,由于Realtime API相对昂贵,请注意不要过度使用)。
本示例旨在实验使用Realtime API进行应用开发,重视简洁性,属于简单实现。
仅实现了最低限度的功能,没有考虑可扩展性和容错性等,不能用于实际运营。
设置
#仅简要说明一下。
首先从Nuxt的CLI创建应用程序。
npx nuxi@latest init <nuxt-app-name>
cd <nuxt-app-name>
这里安装了当前最新版本的v3.13.2的Nuxt。
接下来,安装必要的库。
# WebSocket客户端(Nitro)
npm install ws
# 开发相关库、Nuxt模块等(eslint, tailwindcss...)
npm install -D @types/ws eslint @nuxt/eslint @nuxtjs/tailwindcss
从浏览器访问时,将使用浏览器内置的Web API,即WebSocket API,而与服务器端的Realtime API的交互将使用ws。
nuxt.config.ts如下所示。
export default defineNuxtConfig({
compatibilityDate: '2024-04-03',
devtools: { enabled: true },
modules: ['@nuxtjs/tailwindcss', '@nuxt/eslint'],
// Nitro对WebSocket的支持
nitro: {
experimental: {
websocket: true,
},
},
eslint: {
config: {
stylistic: {
semi: true,
braceStyle: '1tbs',
},
},
},
});
关键是nitro.experimental.websocket的设置。
为了中介Realtime API,服务器端也需要WebSocket通信,但Nuxt使用的Nitro的WebSocket目前处于实验性质。
如上所述,如需使用,必须显式启用。
应用程序结构
#应用程序的主要组件如下。
.
├── server
│ └── routes
│ └── ws.ts // Realtime API请求的中继服务器
├── composables
│ ├── audio.ts // 音频录制/播放
│ ├── audioVisualizer.ts // 音频波形可视化
│ └── realtimeApi.ts // Realtime API通信
├── public
│ └── audio-processor.js // 录音后的音频转换处理(音频线程处理)
├── utils
│ └── index.ts // 汇总公共函数的入口点(仅音频格式转换,因此省略)
├── pages
│ └── websocket.vue // UI组件
├── app.vue // 入口点
├── nuxt.config.ts
└── package.json
这是一个普通的Nuxt SSR应用程序,但在server目录下准备了一个用于中介Realtime API的中继服务器。
接下来,将简要介绍每个组件的概述。
中继服务器
#在Nuxt中,只需将源代码放在server/routes目录下即可创建服务器端API。
在这里,我们将利用这个功能创建Realtime API的中继服务器。
但是,这将作为WebSocket服务器而非常规API实现。
实现如下所示。
import { WebSocket } from 'ws';
// 按连接用户(peer)管理Realtime API的会话
const connections: { [id: string]: WebSocket } = {};
export default defineWebSocketHandler({
open(peer) {
if (!connections[peer.id]) {
// 与OpenAI的Realtime API连接
const url = 'wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-10-01';
connections[peer.id] = new WebSocket(url, {
headers: {
'Authorization': 'Bearer ' + process.env.OPENAI_API_KEY,
'OpenAI-Beta': 'realtime=v1',
},
});
}
const instructions = '请以明亮、活泼的语气交谈。像亲密朋友一样行动,请不要使用敬语。输出请用中文。';
connections[peer.id].on('open', () => {
// Realtime API会话设置
connections[peer.id].send(JSON.stringify({
type: 'session.update',
session: {
voice: 'shimmer',
instructions: instructions,
input_audio_transcription: { model: 'whisper-1' },
turn_detection: { type: 'server_vad' },
},
}));
});
connections[peer.id].on('message', (message) => {
// Realtime API的服务器事件原样返回给客户端
peer.send(message.toString());
});
},
message(peer, message) {
// 将客户端事件直接中继给Realtime API
connections[peer.id].send(message.text());
},
close(peer) {
connections[peer.id].close();
connections[peer.id] = undefined;
console.log('关闭WebSocket');
},
error(peer, error) {
console.log('错误', { error, id: peer.id });
},
});
WebSocket的服务器API(Nitro)使用defineWebSocketHandler来定义。参数中实现了WebSocket的各种事件钩子。
这里的主要实现内容如下。
- 与Realtime API的连接和断开
- 会话设置(session.update)
- 客户端事件通过中继发送到Realtime API
- 服务器事件通过中继发送到客户端(Web浏览器)
通过这种方式,除了与Realtime API的连接外,其他只是将客户端(Web浏览器)和Realtime API的事件原样中继。
如果将其改造为不仅仅是中继服务器,而是特定于应用程序用途的API,那么客户端的实现将显得更加简洁。
在Nuxt的服务器引擎Nitro中,WebSocket服务器的实现使用了crossws这一跨平台支持的WebSocket库。
有关使用crossws实现的详细信息,请参见以下官方文档。
虽然这里没有使用,但它也支持发布/订阅模式,可以轻松实现多个用户之间的对话等功能。
客户端功能(Composables)
#这次准备的Composable有三个。
Realtime API客户端(realtimeApi.ts)
#虽然叫做Realtime API客户端,但并不是直接访问Realtime API,而是通过中继服务器进行访问。
type Params = {
url: string;
logMessage: (string) => void;
onMessageCallback?: (message: MessageEvent) => void;
};
export const useRealtimeApi = ({ url, logMessage, onMessageCallback }: Params) => {
let ws: WebSocket | null = null;
const isConnected = ref(false);
function connect() {
if (isConnected.value) return;
ws = new WebSocket(url);
ws.onopen = () => {
logMessage('连接到服务器🍻');
isConnected.value = true;
};
ws.onclose = () => {
logMessage('已断开连接👋');
isConnected.value = false;
};
ws.onerror = (error) => {
logMessage('发生错误😭');
};
ws.onmessage = (message: MessageEvent) => {
if (onMessageCallback) onMessageCallback(message); // Realtime API的服务器事件
};
}
function disconnect() {
ws?.close();
}
function sendMessage(data: unknown) {
if (isConnected.value) {
ws?.send(JSON.stringify(data)); // Realtime API的客户端事件
}
}
return {
connect,
disconnect,
sendMessage,
isConnected,
};
};
如前所述,这里使用浏览器内置的WebSocket API与中继服务器进行交互。
对Realtime API的服务器事件的处理需要音频播放等音频相关处理,因此没有在这里实现,而是通过参数接收回调。
音频处理(audio.ts)
#提供了从麦克风输入音频并从Realtime API输出音频通过扬声器播放的功能。
由于全部代码过长,因此主要摘录接口部分。
const BUFFER_SIZE = 8192;
const BUFFER_INTERVAL = 1000;
type Params = {
audioCanvas: Ref<HTMLCanvasElement>;
logMessage: (string) => void;
onFlushCallback: (buffer: ArrayBuffer) => void;
};
export function useAudio({ audioCanvas, logMessage, onFlushCallback }: Params) {
const isRecording = ref(false);
const isPlaying = ref(false);
// 省略
/**
* 开始录音的函数
* 音频缓冲后,在超出一定大小或经过一定时间后执行回调
*/
async function startRecording() {
isRecording.value = true;
try {
// 准备麦克风(请求权限)
const mediaStream = await navigator.mediaDevices.getUserMedia({ audio: true });
audioContext = new window.AudioContext({ sampleRate: 24000 });
// 省略(音频输入转换和回调处理执行)
} catch (e) {
// 省略
}
}
/**
* 停止录音的函数
*/
function stopRecording() {
// 省略
}
/**
* 将要播放的音频入队 -> 按顺序播放
*/
function enqueueAudio(buffer: ArrayBuffer) {
audioQueue.push(arrayBufferToAudioData(buffer));
if (!isPlaying.value) {
playFromQueue();
}
}
return {
startRecording,
stopRecording,
enqueueAudio,
isPlaying,
isRecording,
};
}
使用浏览器标准实现的Web Audio API进行音频录制和播放。
需要注意的是,Web Audio API采用的是32bit-float音频格式,而Realtime API目前不支持。
因此,必须以默认格式PCM16进行录音,并在播放时进行相互转换[1]。
此外,由于音频是比播放速度更快地作为流响应返回,因此如果不实现排队处理,可能会出现音频重叠输出的问题。
这部分虽与Realtime API没有直接关系,但这是我花费最多精力的部分😂
尽管如此,音频处理是基于声音的编程中的UI部分,因此我认为自己还需要更加努力。
音频可视化(audioVisualizer.ts)
#提供在Canvas元素上以波形显示音频信号的功能。
使用作为Web API在浏览器中提供的音频分析工具AnalyserNode实时可视化音频信号。
由于此功能不是文章的重点,因此省略源代码的展示。
UI组件(websocket.vue)
#最后是应用程序的UI。
各种功能作为Composable提取成组件,因此页面组件变得简单。
UI渲染偏离主题,所以以下摘录语音录制和与Realtime API的联动部分进行说明。
语音录制
#主要处理在音频处理(audio.ts)的Composable中实现。
该页面组件的职责是实现录制音频的刷新[2]时的处理(回调函数)。
// 播放音频时的刷新回调
function handleAudioFlush(buffer: ArrayBuffer) {
// 将麦克风输入的音频发送到Realtime API
sendMessage({ type: 'input_audio_buffer.append', audio: arrayBufferToBase64(buffer) });
}
const { startRecording, stopRecording, enqueueAudio, isRecording } = useAudio({
audioCanvas, // 用于波形显示的Canvas
logMessage, // 日志追加回调
onFlushCallback: handleAudioFlush, // 音频刷新时的回调
});
这里将缓冲的音频数据进行Base64编码后,发送input_audio_buffer.append事件到Realtime API。
Realtime API
#有关Realtime API的WebSocket客户端的实现也被提炼为Composable,因此这里只需实现并传递服务器事件发生时的事件处理程序即可。
// RealtimeAPI的服务器事件处理程序
function handleWebSocketMessage(message: MessageEvent) {
const event = JSON.parse(message.data);
logEvent(event.type);
switch (event.type) {
case 'response.audio.delta': {
enqueueAudio(base64ToArrayBuffer(event.delta));
break;
}
case 'response.audio_transcript.done':
// 输出的音频文本。用户音频可能先发出,因此延迟显示
setTimeout(() => logMessage(`🤖: ${event.transcript}`), 100);
break;
case 'conversation.item.input_audio_transcription.completed':
logMessage(`😄: ${event.transcript}`);
break;
case 'error':
logEvent(event.error);
if (isRecording.value) stopRecording();
// Realtime API在15分钟后会话超时
if (event.code === 'session_expired') disconnect();
break;
default:
break;
}
}
// Realtime API
const { connect, isConnected, disconnect, sendMessage } = useRealtimeApi({
url: 'ws://localhost:3000/ws',
logMessage,
onMessageCallback: handleWebSocketMessage,
});
在这里,回调函数的主要处理有以下两点(省略错误处理)。
音频数据的播放
Realtime API的音频输出在response.audio.delta事件的有效载荷中设置。音频数据不会一次性返回,而是以流的形式逐步返回增量(delta)。
将其排入音频处理的队列(enqueueAudio)。该队列将依次从扬声器播放。
文本消息绘制
Realtime API不仅可以输出音频数据,还可以输出输入音频和输出音频的文本消息。
在这里,钩住该事件并将其存储在响应式变量中。结果,这以聊天的形式实时显示。
总结
#以上是概要级别,但解释了尝试使用Realtime API进行Web应用开发的要点。
尤其是音频相关的处理存在很多难点,让我非常苦恼。
尽管如此,Web应用更易于多用户使用,并且可以考虑很多应用场景。
希望能找到时间改善可扩展性等部分。
OpenAI官方的示例中,输入和输出的转换处理都使用AudioWorklet在音频线程中异步执行,而本示例仅用于输入。在实际运营级别上,建议按照官方示例输出也在音频线程中执行。 ↩︎
在默认状态下,每256字节处理一次音频数据,音频会高频率发送。音频处理的Composable会将音频数据进行缓冲,在超过8192字节或1秒时进行刷新。 ↩︎