文本编辑器自制入门
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
文本编辑器难民
#大家在用什么文本编辑器呢。
最近的话,是 VS Code 吧。可以说是人手一台。
但我就是无法喜欢 VS Code。感觉太杂乱了。
因此我主要使用 Sublime Text,但对日语支持有些微妙,打开大型文件也比较慢,对此颇有不满,所以一直过着根据情况切换各种文本编辑器的“难民”生活。
编码可用 IDE,所以我只想要一个能让日常文本编辑无压力的简单编辑器。具体需求大致如下:
- 使用 Markdown 做笔记
- 希望支持代码段的语法高亮
- 想将表格粘贴为 Markdown 表格(尤其是想粘贴著名的无法直接粘贴的 PowerPoint 表格)
- 查看大型日志/文件
- 希望快速打开并过滤错误位置
- 想用 Grep 进行调查
- 处理 SQL 和 JSON
- 希望支持多光标编辑
- 想进行缩进格式化
- 编辑大型 CSV 文件
- 想按列对齐缩进来操作
- 多平台支持
- 希望在不同环境下保持相同的键绑定
- 希望开箱即用,无需反复折腾设置或插件
- 显示全角空格和制表符
- 只在光标所在行显示
- 会话保存
- 即使未保存就关闭,也能恢复上次内容
摆脱难民状态
#厌倦了这种难民式的生活后,我开始想,是不是自己动手更快?
就这样决定自制一个文本编辑器,目前已成功摆脱难民状态。
然而,根本谈不上“轻而易举”,比我想象的要费劲得多。
回头一看,初次提交居然是在 2022 年 9 月 12 日。
如果只是简单的文本编辑,很快就能动起来;但要达到日常可用的水平,我感觉至少花了一年多。至今仍在不断调整改进。
由于往往只能在晚上抽出几十分钟来编码,第二天又常常忘记上次做到了哪一步,要保持进度和动力确实不容易。给我的印象是,如果不能拿出一段较为集中的时间,就很难推进下去。
这可不是像学生那样有大量空闲时间可以玩玩的东西,不过只要想要某个功能,就能立即添加,所以最终也算得到了一个能随心定制的编辑器。
因此,本文记录一下在开始自制文本编辑器时,我希望事先了解的一些内容。
文本缓冲区
#在自制文本编辑器时,必须先考虑使用何种数据结构来处理字符序列。
市面上的文本编辑器通常基于 Gap Buffer、Linked List、Rope、Piece Table 这几种数据结构之一,并在此基础上做出独特优化。下面我们来逐一了解。
Array
#首先从最简单的例子开始:将字符序列当作数组来处理。
可以这样将文件内容读入字节数组:
byte[] bytes = Files.readAllBytes(path);
此时,字符串 This is apple. 会被保存在如下连续的内存布局中。
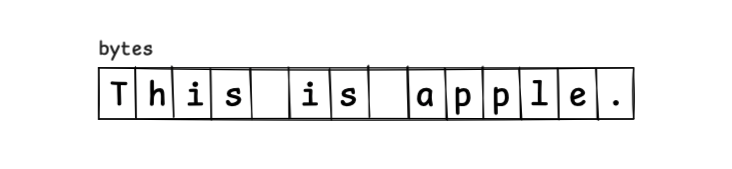
若要在索引 8 处插入 an ,就需重新分配一个比原数组大 3 个字节的新数组,并将内容复制过去。
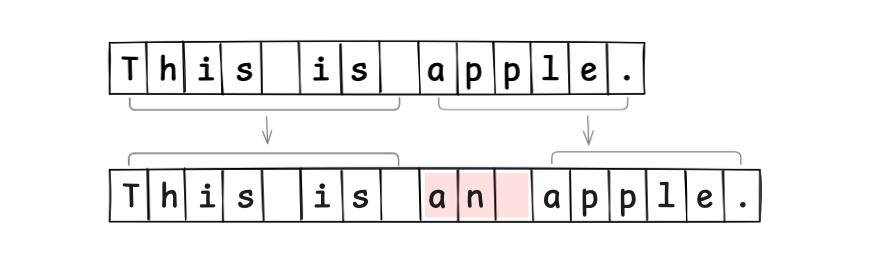
显而易见,每次编辑都要重新申请内存,效率极低。
于是我们考虑预留额外的内存区域,将其用作缓冲区。
Buffer
#由于每次编辑都重新分配内存效率太低,我们在内存中预留未使用区域作为缓冲。
概念上可以有如下的 Buffer 类:
class Buffer {
byte[] bytes;
int length;
}
如果预留 5 个元素的未使用区域(阴影部分)作为缓冲区,布局如下。
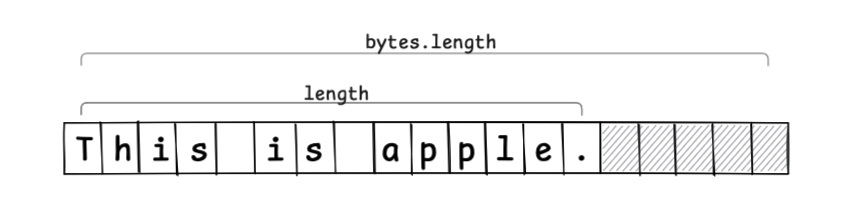
插入字符串时,无需新建数组,仅用赋值和移动即可完成(若缓冲不足则需重新分配并复制)。
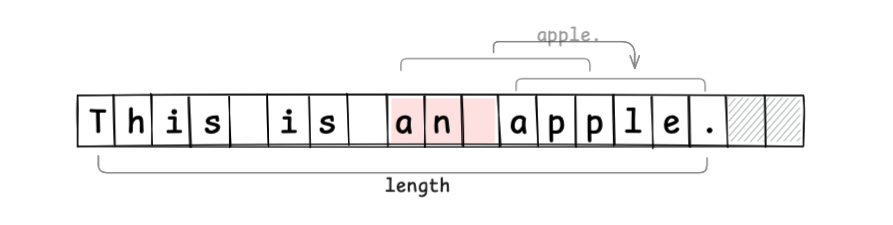
通过让缓冲区吸收编辑操作,减少了多余的内存分配。不过仍需将编辑点之后的内容向末尾移动,效率还有待提高。
Gap Buffer
#Gap Buffer 利用了大多数文本编辑操作都在光标位置进行的特点。
在前面的例子中,我们在数组末尾预留缓冲,而在 Gap Buffer 中,缓冲区就在光标位置(插入点)。
概念上如下定义:
class GapBuffer {
byte[] bytes;
int gapIndex;
int gapLength;
}
假设当前光标位置如图中橙色箭头所示,并分配 5 个字节的 Gap,布局如下。
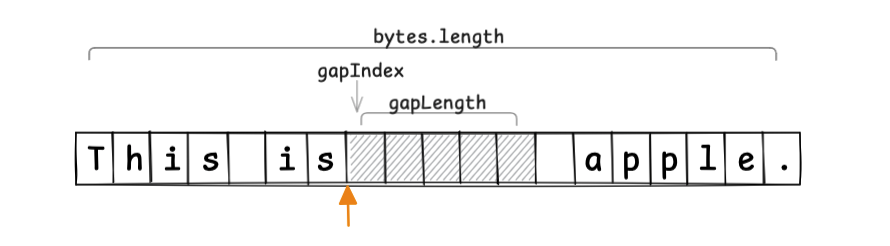
当光标移动时,缓冲区随之移动。
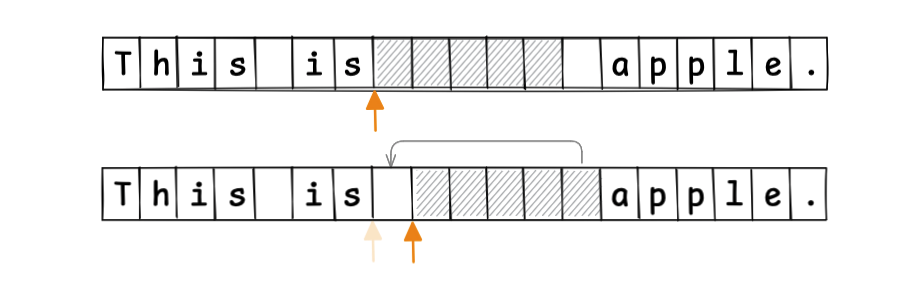
这样,所有编辑操作都在 Gap 处进行,无需移动编辑点之后的内容。

由于已知 Gap 的起始位置和长度,随机访问索引也很简单。
Gap Buffer 是一种高效的文本缓冲实现方法,Emacs 中就使用了它。
到这里,我们看到的都是将整个字符序列作为一个整体管理,下面介绍将其分块处理的方法。
链表
#若将字符序列分割成若干小块并用链表管理,就能将编辑操作局限在局部。
最直接的方案是,将字符分割成固定大小的块(chunk)作为节点,并用双向链表连接。
概念上如下:
class LindedList {
Node head;
Node tail;
}
class Node {
byte[] chunk;
Node next;
Node prev;
}
若以单词为单位分块,结构如下图所示。
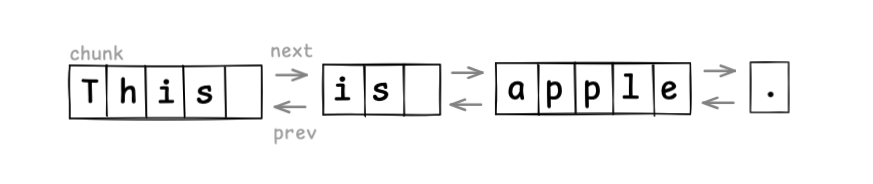
编辑时仅需创建新节点并调整链接,效率看起来不错。

但若分块过细,会增加指针的内存开销,实际中常以一行为一个块(插入换行时分割节点,删除行时合并节点)。
链表实现简单,但随机访问所需的遍历时间较长。索引访问时需从头开始遍历,在大文件中特别低效,通常需以光标为基准来访问元素。
Rope
#Rope 将字符分块后,用二叉树跟踪索引,实现高效随机访问。可以理解为对 String 强化后的 Rope(绳索)。
概念上如下:
class Rope {
Node root;
}
interface Node {
int weight();
int totalLength();
}
record Branch(Node left, Node right, int weight) implements Node {
Branch(Node left, Node right) {
this(left, right, left.totalLength());
}
public int totalLength() {
return left.totalLength() + right.totalLength();
}
}
record Leaf(String text) implements Node {
public int weight() { return text.length(); }
public int totalLength() { return weight(); }
}
其中 weight 表示左子树对应的字符串长度总和。Leaf 节点保存块内容,Branch 节点维护 weight。
若按单词分块,管理结构如下。
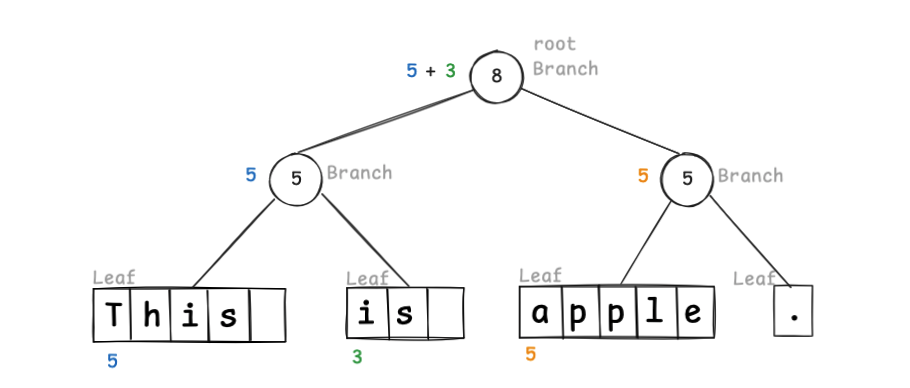
要访问索引 10,可按如下方式遍历。
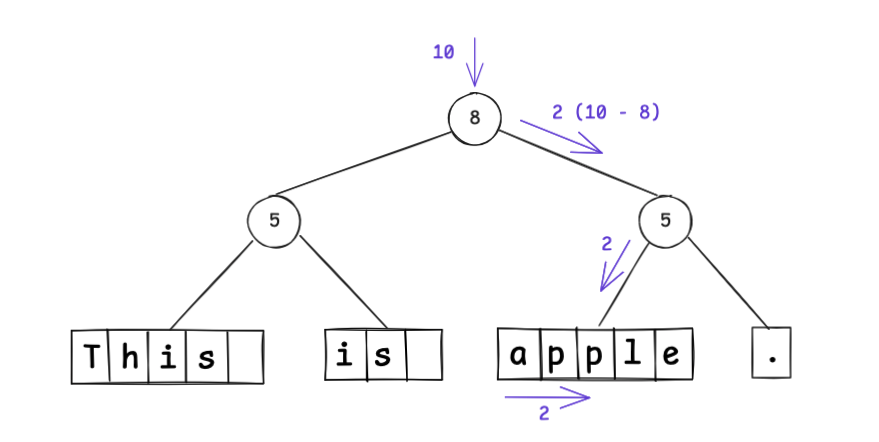
根节点的 weight 表示 left=this is 与 right=apple. 之间的位置,因此索引 10 位于右子树中的 2,而 2 < 5,确定在右子树的左节点。这就大大提升了随机访问效率。
插入 an 时,如下更新树结构。
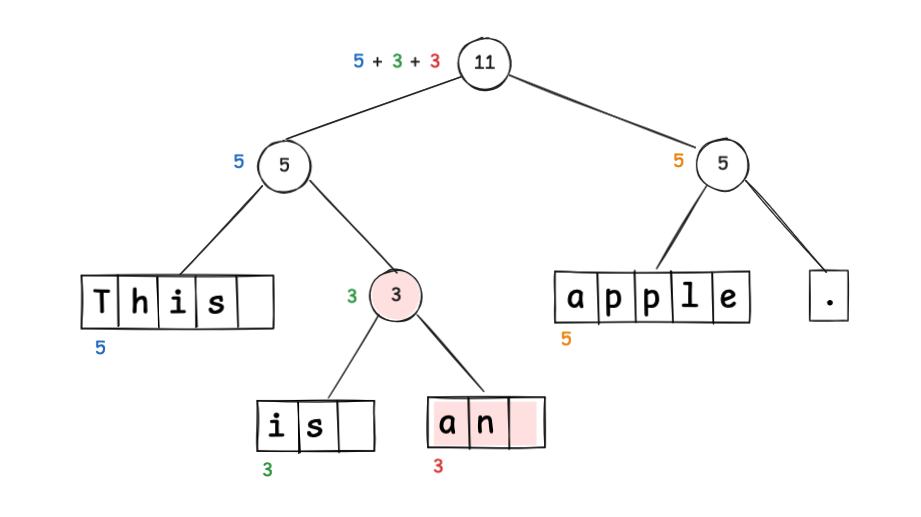
请注意,更新仅影响沿路径向上追溯的节点,包含 apple 和 . 的右侧节点不受影响。
原有树结构保持不变,只需将受影响节点向上追溯并重新链接,即可表达更新后的序列。这说明可以将编辑当作不可变(immutable)操作。
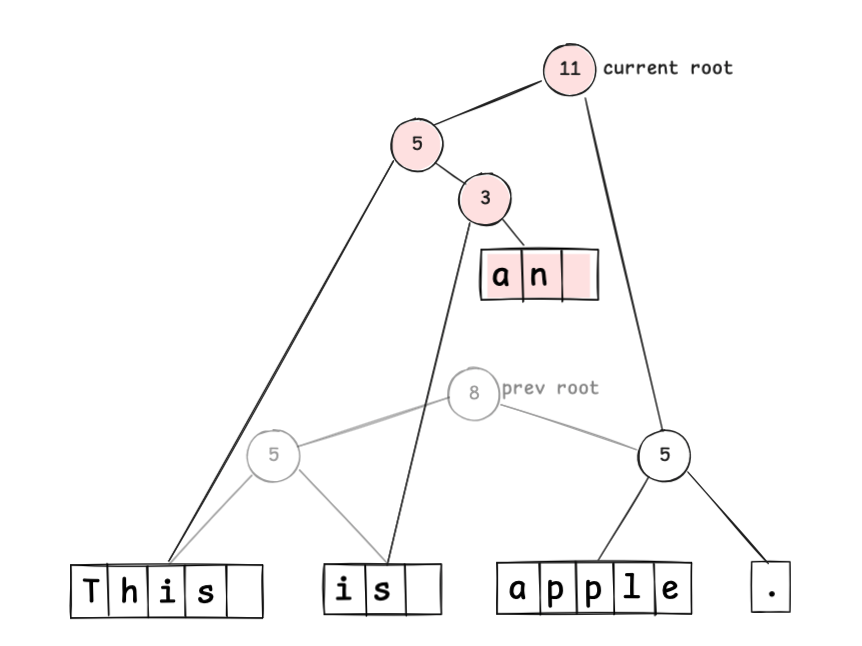
Undo 操作只需回退到上一个根节点即可。
Rope 很强大,但维护树结构及平衡需要额外开销,且打开文件时需构建树,对大型文件的打开耗时不菲。
Piece Table
#Piece Table 通过追加操作管理文本修改。
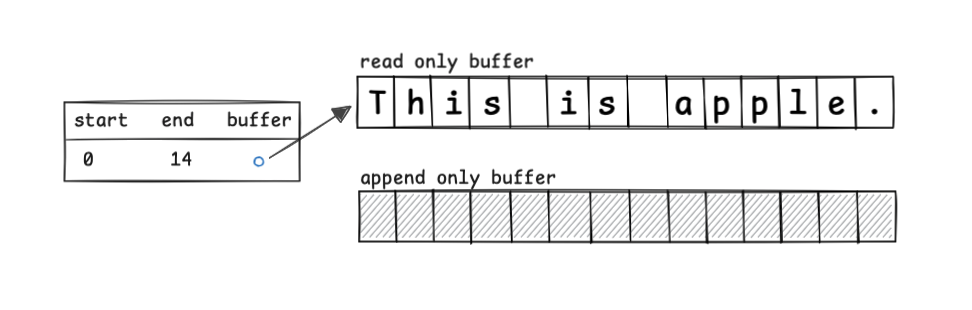
它将原始字符序列保存在只读(read-only)缓冲区,将新增修改保存在追加(append-only)缓冲区,并通过表格记录各块的源缓冲区、起始偏移和长度。
打开 This is apple. 后:
在索引 8 插入 an ,只需在表格中新增一个指向追加缓冲区的块,如下:
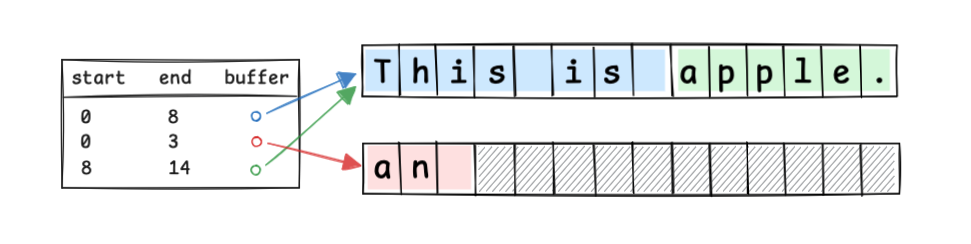
概念上如下:
record Piece(Buffer target, int index, int length) {
int end() { return index + length; }
}
class PieceTable {
List<Piece> pieces;
Buffer appendBuffer;
PieceTable(Buffer readBuffer) {
this.pieces = new ArrayList<>();
this.pieces.add(new Piece(readBuffer, 0, readBuffer.length()));
this.appendBuffer = AppendBuffer.of();
}
}
即使文件巨大,只读缓冲区可直接映射文件或使用内存映射,几乎无需额外内存,编辑时仅管理新增的 Piece。
但若频繁修改,Piece 数量增多且追加缓冲区会碎片化,这是其缺点。
文本缓冲区数据结构总结
#| 数据结构 | 特点 |
|---|---|
| Gap Buffer | 实现非常简单 在光标位置输入速度极快( O(1))光标位置的大幅移动和多光标操作时可能产生延迟 缓冲区耗尽时需要重新分配内存 被 Emacs 使用 |
| 链表 | 定位后插入或删除可在固定时间内完成(O(1))随机访问为 O(N),因此需要利用光标等优化实现简单,初期编辑器常采用此方法 |
| Rope | 插入和随机访问为 O(log N)二叉树的构建和平衡处理会产生开销 可将编辑操作视为不可变 Zed Editor 中使用了基于 Rope 的数据结构 |
| Piece Table | 内存效率高 插入和删除采用追加方式,因此速度快( O(1))修改多时 Piece 数量增加会导致性能下降 VS Code 中使用了基于 Piece Table 的数据结构(索引访问使用类似 Rope 的二叉树) |
各有优劣,没有放之四海而皆准的最佳方案。
就我而言,为了处理大型文件而选择 Piece Table。
请根据实际需求选择合适的数据结构。
不能仅凭数据结构
#即便数据结构决定后,开发文本编辑器过程中仍会遇到各种棘手问题。下面列举几个典型案例。
确定滚动位置
#文本编辑器通常会显示垂直滚动条和水平滚动条。
- 垂直滚动条:需知道文件总行数和当前屏幕可见的行数。
- 水平滚动条:需知道文件中最长的行长度和当前屏幕宽度。
其中,水平滚动条最棘手,因编辑可能改变最长行,每次编辑后都必须重新查找最长行。
我放弃了对整个文件的水平滚动完全追踪,仅在当前屏幕可见行中寻找最长行。
换行显示
#大多数文本编辑器支持根据窗口宽度对一行进行逻辑换行显示。
但换行判定很复杂,需要计算屏幕上字形对应的字符宽度。字符宽度各异,而且组合字符和字形连写(Ligature)会将多个字符合成一个显示,需实时重新计算宽度。
若要精确处理,必须对所有行进行宽度计算并查找换行点,开销巨大。
也可只对可见区域进行换行计算,但会导致滚动条长度与实际不符。
现实中通常对换行显示做策略性限制,例如仅对一定大小以下的文件启用,或将字符宽度计算简化为近似值,在性能和显示效果之间做折衷。
对字符序列的随机访问
#汇总中提到随机访问可达 O(1),但现实中有诸多挑战。
理想情况下若全为 ASCII 字符、每字符 1 字节,简单易行。但 UTF-8 是 1~4 字节的可变编码,访问第 N 个字符时无法直接在字节级索引定位,需逐字节统计。
即使将文件全部载入内存,许多语言运行时内部以 UTF-16 编码的字节序列处理字符串,依旧需考虑可变编码。若使用固定宽度的 UTF-32,可简化随机访问,但内存占用大幅增加。
以 Piece Table 为例,若直接将 UTF-8 文件作为只读缓冲区:
在屏幕上点击后,该位置对应第 N 个字符(Unicode 码点),需先转换到运行时内的 UTF-16(1~2 字节)索引,再转换到文件上的 UTF-8(1~4 字节)索引,最后才能访问目标位置,效率极低。
还需兼顾滚动条、换行显示等问题,需将行数、字符数等元信息与文本缓冲区映射,并结合字形宽度等显示信息共同处理字符序列。实现时必须在性能与内存效率间权衡,进行多方面的优化。
这就是文本编辑器实现的深奥之处。