Persisting LangMem's Long-Term Memory to PostgreSQL (pgvector)
Back to TopTo reach a broader audience, this article has been translated from Japanese.
You can find the original version here.
In our previous article, we explained an overview and usage of LangMem, which efficiently manages the AI's long-term memory.
In that article, we used an in-memory store for long-term memory, but LangMem also supports a PostgreSQL (pgvector extension) based store.
This time, we will explore a more practical utilization of long-term memory using the PostgreSQL-based store.
Here, we will try using Aurora Serverless v2, which supports zero scaling, as our PostgreSQL instance.
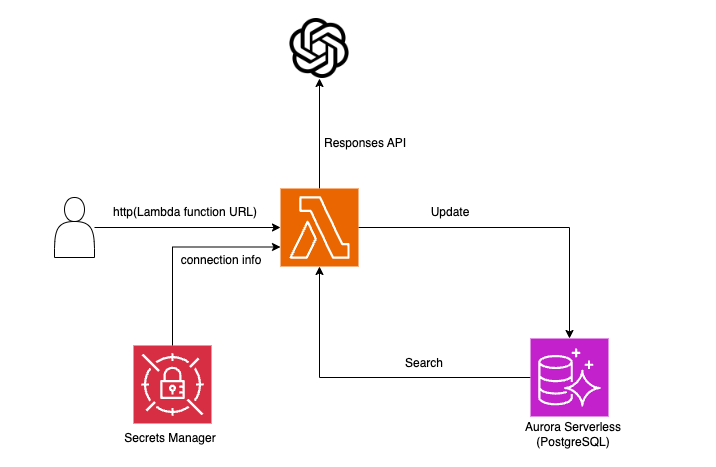
Running on a Lambda function, LangMem accesses OpenAI's Responses API and saves the user's preferences as long-term memory in Aurora Serverless's PostgreSQL. In subsequent interactions, this stored information will be utilized.
To keep the configuration as simple as possible, we are not using additional related resources such as a connection pool (RDS Proxy) or API Gateway.
Setup
#For the BaseStore of LangGraph, which provides LangMem's persistence functionality, we use the following PostgreSQL-specific implementation:
This PostgresStore is not included by default.
In conjunction with LangMem, you must install langgraph-checkpoint-postgres separately.
pip install langmem langgraph-checkpoint-postgres psycopg[binary]
In this test, we are using LangMem version 0.0.15, which is currently the latest.
Lambda Functions
#Let's proceed with the implementation of the Lambda function. The complete source code can be found here.
First, here is the initialization part of the Lambda function.
We define the schema for the data to be stored in long-term memory using a Pydantic class.
class UserTechInterest(BaseModel):
"""User's technology-related interest information"""
topic: str = Field(..., description="Technology topic (e.g., programming languages, cloud services, etc.)")
category: str | None = Field(
None, description="Field of technology (e.g., frontend, backend, network, etc.)"
)
interest_level: conint(ge=0, le=100) | None = Field(
None, description="Interest level (expressed as a score between 0 and 100)"
)
description: str | None = Field(
None, description="Additional explanation (such as specific examples or detailed knowledge)"
)
We use this schema to structure the user's technical preferences and store them as long-term memory.
Next, we create the PostgreSQL connection URL.
def create_conn_url():
secret_name = os.environ['SECRET_NAME']
session = boto3.session.Session()
sm_client = session.client(service_name='secretsmanager')
get_secret_value_response = sm_client.get_secret_value(SecretId=secret_name)
secret = json.loads(get_secret_value_response['SecretString'])
return f"postgresql://{secret["username"]}:{secret["password"]}@{secret["host"]}:{secret["port"]}/{secret["dbname"]}"
postgres_conn_url = create_conn_url()
As is customary, the DB connection information is retrieved from Secrets Manager to generate the connection.
Next, we initialize LangMem's Store Manager and the OpenAI client that will interact with the user.
# LangMem's Store Manager
manager = create_memory_store_manager(
"openai:gpt-4o-2024-11-20",
namespace=("chat", "{user_id}"),
schemas=[UserTechInterest],
instructions="Extract the user's interests and technical background in detail",
enable_inserts=True,
enable_deletes=False,
)
# OpenAI client
client = OpenAI()
We configure the Store Manager with the previously defined Pydantic schema (UserTechInterest), thereby enforcing the long-term memory schema.
The Store Manager is one of LangMem's Storage APIs.
It leverages LLMs to extract long-term memory and update existing information, ultimately reflecting changes to actual storage through LangGraph's persistence functionality.
For more details, please refer to the previous article.
Next, we implement the Lambda event handler.
First, we establish a connection to PostgreSQL.
def lambda_handler(event, context):
# 1. Create LangGraph's PostgresStore
with PostgresStore.from_conn_string(postgres_conn_url, index={
"dims": 1536,
"embed": "openai:text-embedding-3-small",
}) as store:
# 2. PostgreSQL schema migration
store.setup()
To establish the connection to PostgreSQL, we generate a context manager using PostgresStore.from_conn_string. This automatically manages both connection acquisition and termination.
We also specify the data dimensionality (dims=1536) and the embedding model to use (openai:text-embedding-3-small).
Once the connection is established, calling store.setup() creates the necessary tables in the database.
Next, we define a workflow using LangGraph's Functional API.
# 3. LangGraph Functional API workflow
@entrypoint(store=store)
def app(params: dict):
message = params["message"]
user_id = params["user_id"]
# Search for related long-term memory from the store
memories = store.search(("chat", user_id))
developer_msg = ("You are a helpful assistant.\n"
f"## Memories\n <memories>\n{memories}\n</memories> ")
# Execute OpenAI's Responses API
response = client.responses.create(
model="gpt-4o-2024-11-20",
input=[{"role": "developer", "content": developer_msg}, message],
tools=[{"type": "web_search_preview"}],
)
# Extract the relevant user's preferences and update long-term memory
manager.invoke(
{"messages": [message]},
config={"configurable": {"user_id": user_id}}
)
return response.output_text
The workflow proceeds as follows:
- Search for the user's long-term memory from PostgreSQL.
- Incorporate the retrieved information into the context for OpenAI's Responses API.
- Invoke OpenAI's API to generate an appropriate response.
- Update the user's preferences in long-term memory via the LangMem Store Manager.
- Return the text generated by the OpenAI API.
Below is the remainder of the source code.
body = json.loads(event["body"])
user_id = body["user_id"]
# Launch the LangGraph workflow
output = app.invoke({
"message": {
"role": "user",
"content": body["prompt"]
},
"user_id": user_id
})
# Return the response
return {
"statusCode": 200,
"headers": {"Content-Type": "plain/text"},
"body": output
}
We retrieve the user ID and prompt from the HTTP request and launch the previously defined LangGraph workflow.
Finally, we return the text generated by the workflow as the result.
Creating AWS Resources
#Here, we create AWS resources such as Aurora Serverless and the Lambda function.
For this example, we used AWS CDK as our IaC tool.
The primary focus of this article is persisting LangMem's long-term memory using PostgreSQL, so detailed instructions for constructing AWS resources will be omitted.
Below, we excerpt only the portions related to Aurora Serverless and Lambda.
The complete source code can be found here.
# Create Aurora Serverless v2 Cluster
dbname = "memory"
cluster = rds.DatabaseCluster(
self, "AuroraCluster",
engine=rds.DatabaseClusterEngine.aurora_postgres(
version=rds.AuroraPostgresEngineVersion.VER_16_6
),
writer=rds.ClusterInstance.serverless_v2("writer"),
readers=[
rds.ClusterInstance.serverless_v2(
"reader1", scale_with_writer=True),
],
vpc=vpc,
serverless_v2_min_capacity=0, # Zero scale
serverless_v2_max_capacity=1,
vpc_subnets=ec2.SubnetSelection(
subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS
),
# Creating Secrets Manager resource (RDS integration)
credentials=rds.Credentials.from_generated_secret(
username="langmem"),
security_groups=[aurora_sg],
default_database_name=dbname,
enable_data_api=True
)
This is a simple, zero-scale-compliant Aurora Serverless (v2) cluster.
It utilizes Secrets Manager integration with RDS, which creates an entry for connection information during resource provisioning.
The Lambda function is defined as follows.
lambda_role = iam.Role(
self, "LambdaExecutionRole",
assumed_by=iam.ServicePrincipal("lambda.amazonaws.com"),
inline_policies={
"SecretsManagerAccessPolicy": iam.PolicyDocument(
statements=[
iam.PolicyStatement(
actions=["secretsmanager:GetSecretValue"],
resources=[cluster.secret.secret_arn]
)
]
)
},
managed_policies=[
iam.ManagedPolicy.from_aws_managed_policy_name(
"service-role/AWSLambdaBasicExecutionRole"),
# for VPC attached Lambda
iam.ManagedPolicy.from_aws_managed_policy_name(
"service-role/AWSLambdaVPCAccessExecutionRole"),
]
)
lambda_function = _lambda.Function(
self, "LongTermMemHandler",
function_name="LongTermMemHandler",
runtime=_lambda.Runtime.PYTHON_3_12,
code=_lambda.Code.from_asset(
"path/to/deployment_package.zip"),
handler="lambda_function.lambda_handler",
security_groups=[lambda_sg],
vpc=vpc,
timeout=Duration.seconds(180),
memory_size=1024,
environment={
"SECRET_NAME": cluster.secret.secret_name,
"OPENAI_API_KEY": os.environ["OPENAI_API_KEY"],
},
role=lambda_role
)
lambda_url = lambda_function.add_function_url(
auth_type=_lambda.FunctionUrlAuthType.NONE
)
CfnOutput(self, "LongTermMemFunctionUrl", value=lambda_url.url)
Since Aurora is a VPC resource, the Lambda function accessing it is also attached to the VPC.
Additionally, because it connects to OpenAI's API and PostgreSQL [1], a longer timeout is necessary.
The memory size was also adjusted, as the default setting resulted in errors due to insufficient memory.
Verifying Aurora-based Long-Term Memory
#With the testing environment now ready, we use curl to test the saving and utilization of long-term memory in Aurora Serverless via the generated Lambda function URL.
First, send the following request to store the user's interest information.
LAMBDA_URL=$(aws lambda get-function-url-config --function-name LongTermMemHandler --query FunctionUrl --output text)
> https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.lambda-url.ap-northeast-1.on.aws/
curl -H 'Content-Type: application/json' "$LAMBDA_URL" -d @- <<'EOF'
{
"user_id": "MZ0001",
"prompt": "I am interested in cloud services in general, and I specifically want to gradually deepen my basic knowledge of AWS and Azure"
}
EOF
When you send this request, the AI generates an appropriate response and, based on it, saves the user's interests as long-term memory.
Although the response content itself is omitted, internally this information is accumulated in Aurora Serverless.
Next, let's add some additional interest information.
curl -H 'Content-Type: application/json' "$LAMBDA_URL" -d @- <<'EOF'
{
"user_id": "MZ0001",
"prompt": "I have recently developed a strong interest in initiatives that leverage AI agents as an emerging technology that has caught my attention."
}
EOF
At this point, using the AWS Management Console's RDS Query Editor, you can check the data within Aurora Serverless.
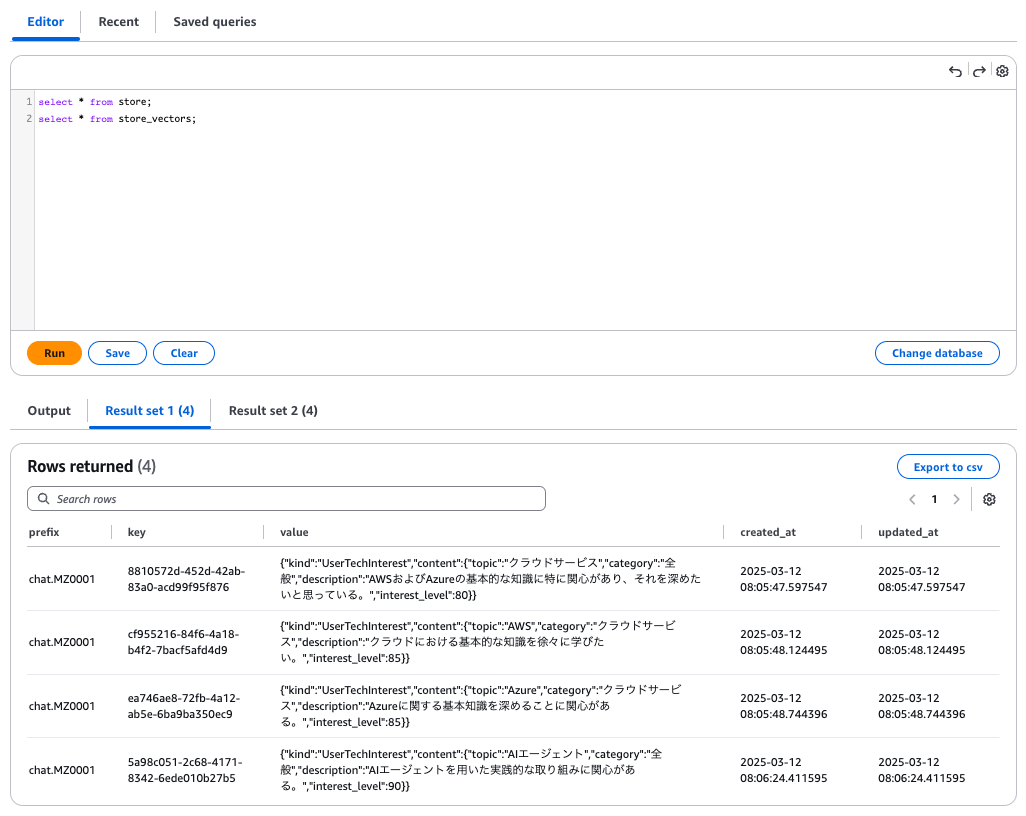
LangMem's long-term memory stores raw data in the store table and vectorized information in the store_vectors table.
store table
store_vectors table
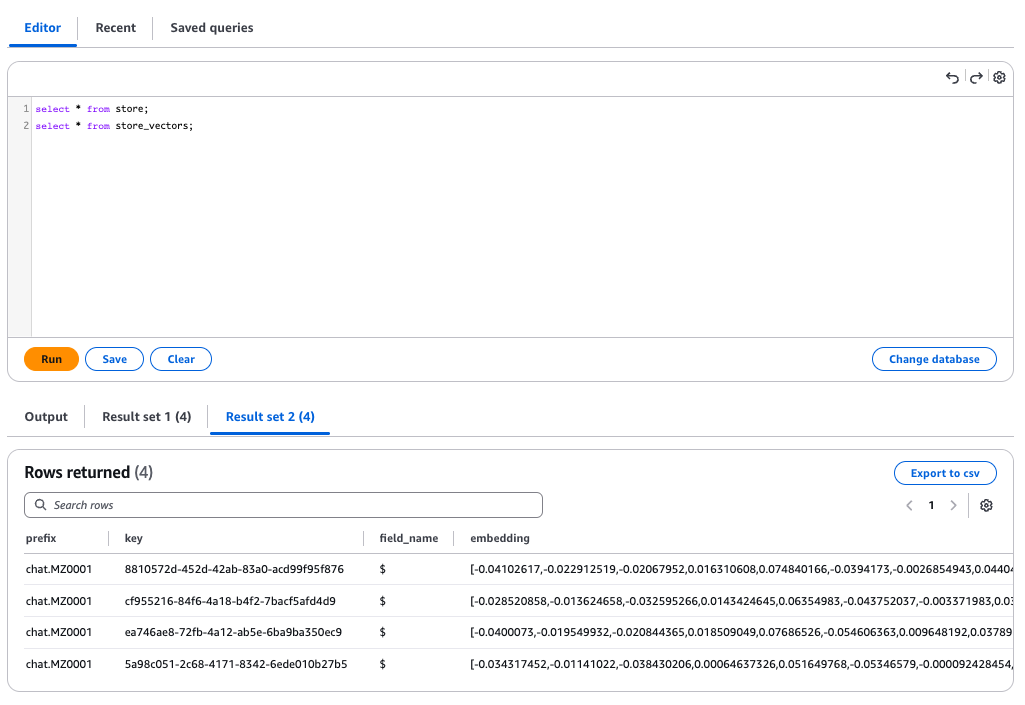
It has been confirmed that the user's interest information is properly stored in PostgreSQL.
Next, we verify whether a response that leverages the stored information as long-term memory can be generated.
Without providing the user's previous remarks, we ask for general technology topics.
curl -H 'Content-Type: application/json' "$LAMBDA_URL" -d @- <<'EOF'
{
"user_id": "MZ0001",
"prompt": "Please list three recommended technology topics and summarize them concisely!"
}
EOF
The following response was returned.
I recommend the following three technology topics! They were chosen based on depth of interest and relevance.
1. **AI Agents**
- Learn practical applications and development methods, which can enhance daily operational efficiency and enable innovative problem-solving.
The latest AI tools and API usage are especially noteworthy.
2. **Azure (Cloud Services)**
- Acquire fundamental knowledge of Microsoft Azure and strengthen your skills in cloud-based application development and operations.
Services that integrate with AI or data analytics are particularly recommended.
3. **AWS (Cloud Services)**
- Engage with Amazon's cloud solutions to learn a broad range of foundational technologies.
It is especially advisable to focus on serverless architectures and techniques for streamlining data storage.
These topics are beneficial for both learning and practical applications!
A response that reflects the user's interest information while suggesting appropriate technology topics has been generated.
When the same prompt is sent by a new user (with a different user_id) who does not have long-term memory, generic technology topics are suggested:
### 1. **Generative AI**
- AI technology that generates text, images, music, and more is rapidly advancing.
- Models such as ChatGPT and Stable Diffusion are especially notable and are applied in creative fields and efficiency improvements.
- The evolution of this technology impacts a wide range of areas, from business automation to entertainment.
### 2. **Quantum Computing**
- A next-generation technology that can solve problems that are challenging for current computers at high speed.
- It is expected to revolutionize fields such as cryptography, molecular simulation, and financial optimization.
- Although it requires specialized knowledge, there is an increasing number of applications from basic research to practical deployment.
### 3. **Web3 and Blockchain**
- Aiming to create a decentralized internet, this technology centers on cryptocurrencies and smart contracts.
- Its applications in areas like finance (DeFi) and digital assets (NFTs) are progressing, though issues such as regulation and environmental impact are also debated.
- It is shaping new economic models and concepts of ownership.
It was confirmed that different responses are generated for users with long-term memory and those without.
Summary
#In this trial, we tested LangMem's long-term memory using PostgreSQL (pgvector)—the approach recommended for production—instead of using an in-memory store.
Although setting up Aurora Serverless required some effort, it provided a clear impression of how long-term memory can be operated in a real-world environment.
By leveraging this mechanism, we can accumulate each user's knowledge and preferences to build more personalized AI systems.
I look forward to exploring various innovative ideas with this approach.
When zero-scaling, establishing a connection to PostgreSQL may take over 10 seconds. ↩︎