A Discussion on Machine Learning and Ethics
Back to TopTo reach a broader audience, this article has been translated from Japanese.
You can find the original version here.
This is the article for Day 25 of the Mamezou Developer Site Advent Calendar 2024.
My name is Egawa. I work as a software engineer in machine learning.
Mr. Takashi Egawa is a software engineer specializing in machine learning. As he is an alumnus of Mamezou, we have had the privilege of having him contribute to our Advent Calendar.
He is also known for his numerous writings and translations, and his most recent translation closely related to this article is "機械学習システムデザイン," published last year by O'Reilly Japan.
In machine learning, data is an indispensable and crucial element. However, data is extremely difficult to handle and carries potential risks, especially concerning ethics and privacy. Today, I would like to lightly introduce some incidents related to data in machine learning, and through them, provide an opportunity for everyone to think about data. Thank you for your attention.
By the way, it's Christmas today. How are you spending it? With only a few days left this year, how was this year for you? Did you challenge yourself with something new?
Challenges and Strava
#As for my own challenge, I started running around June. Thanks to continuing little by little at a comfortable pace, I can still keep it up now. As a result, I've returned to the weight I had 15 years ago and feel healthier both physically and mentally.
By the way, there is an indispensable app when running. That's Strava. Strava is an online service that allows you to record and share activities, visually recording on graphs and maps which routes you ran and at what pace each day. You can also share that data with other users on a timeline. Strava started its service in the United States in 2009 and is now used by about 100 million users worldwide.
Strava also provides a heatmap that shows which routes are used by many people by anonymizing the collected data. With this feature, you can find out popular running courses. The image below is the global heatmap around the Tokyo Metropolitan Government Office area where Mamezou is located.

By the way, Strava caused a global issue in 2018 and became a hot topic. Through the global heatmap, various confidential information was inadvertently exposed. Activities of the U.S. military overseas were revealed, such as the locations of forward bases in Afghanistan and patrol routes in Russian operational areas in Syria[1]. The image below is a post reporting that fact.
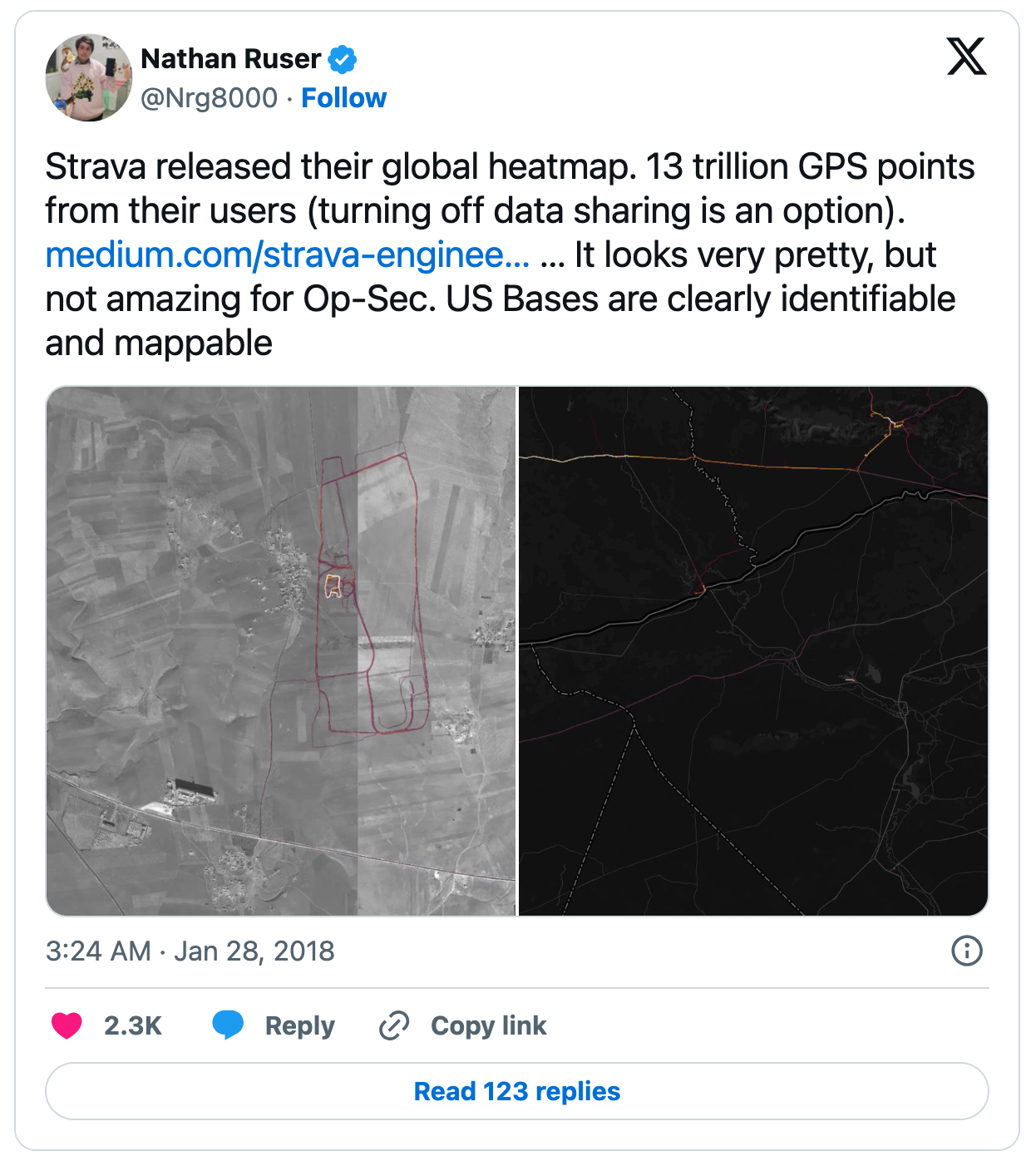
The reason such a situation occurred is that many military personnel routinely engaged in training and used Strava to record their activities. As a result, their activity data was inadvertently incorporated into the big data.
As a software engineer involved in machine learning, I can say that high-quality data is essential in machine learning. Since the development of machine learning systems heavily depends on data quality, collecting user data becomes extremely important. However, when collecting and sharing datasets, there is always a potential risk that users' privacy and security may be violated.
While Strava did not directly leak private information, and the collected data was anonymized so that individuals could not be identified, it still suggests that data collection carries various potential dangers.
Some people think that when training machine learning models, "quantity beats everything," meaning the more data, the better. While not being that extreme, assembling a certain scale of data is a common challenge faced by many people involved in machine learning. However, collecting data without issues in terms of ethics and privacy is a task of very high difficulty.
Bias Lurking Even in Large-Scale Datasets
#So, can we feel safe if we use prestigious and well-known datasets used by developers and researchers worldwide? It's not so simple.
Even the globally famous image dataset ImageNet has had its ethical issues pointed out[2].
The reason large-scale datasets like ImageNet are useful in machine learning is that they provide a set of massive images along with metadata such as categories or labels describing those images. There was a research project called ImageNet Roulette that cast a stone at ImageNet. ImageNet Roulette provided a website where, when you upload a person's image, it labels that image using a machine learning model trained on ImageNet.

Quoted from ImageNet Roulette
Labels included in ImageNet have been previously pointed out to contain problematic categories related to people's appearance, race, ethnic background, and gender. ImageNet Roulette was intended to help the general public understand "how such categories influence model judgments and reproduce biases" with actual experience, aiming for users to directly experience how easily and vividly inappropriate classifications and biases can manifest. Since uploading a photo of someone in a swimsuit resulted in labels like "slut," or uploading a picture of a child wearing sunglasses resulted in labels like "loser" or "non-starter," the site quickly sparked a significant debate after its release due to presenting offensive labels and discriminatory classification results.
However, it's not that someone with malicious intent arbitrarily labeled ImageNet. ImageNet was inspired by a project called WordNet, which aimed to provide a conceptual dictionary and has a structure that considers conceptual hierarchies and connections between words. However, concepts considered appropriate at the time of WordNet's creation in the 1980s may be completely unacceptable in today's society.
This incident reminds us once again that "just because a dataset is famous and widely used doesn't mean we can unconditionally feel safe," and highlights "the difficulty of collecting and organizing data neutrally."
Who Suffers Disadvantages?
#Using machine learning models trained on data that reflects human societal biases and preconceptions can cause disadvantages, and in most cases, it is those in socially weaker positions who suffer. It is especially necessary to be cautious when using them in areas like social security and public policy, and there have been significant problems repeatedly.
Example in Australia
#Australia's government agency Centrelink (similar to Japan's Ministry of Health, Labour and Welfare) faced the issue of overpayments in welfare benefits. However, lacking sufficient personnel to check this, they developed and began operating an AI-powered debt detection system called "Robodebt." However, this system led to many legitimately receiving beneficiaries being sent debt notices without any basis, especially during Christmas or the weeks just before[3].
Recipients were unilaterally notified of overpayments and demanded to repay benefits, despite having no idea why. When they inquired with Centrelink, they were told, "The system judged appropriately based on the information, and the debt has been handed over to debt collectors, so discuss it with them." Furthermore, they faced threatening collection practices from debt collectors, with no way to find a solution, pushing recipients into despair.
This "incorrect debt notice" caused many recipients to suffer mental anguish and financial burdens, sparking a major societal debate in the country. In 2020, a class-action lawsuit was carried out, and eventually, the government agreed to settle, refunding erroneously collected amounts and compensating the recipients.
Example in the United Kingdom
#In 2020, due to the spread of the novel coronavirus, the United Kingdom was forced to cancel the "A-level exams," a crucial standardized test recognized for university entrance qualifications. In response, the public agency involved in exam operations, Ofqual, decided to compute exam results automatically using AI, adopting these as students' grades. Ofqual kept all methods of data collection and algorithm details confidential, stating it was "to maintain fairness."
When revealed, the AI scoring depended more on the past performance of the schools students attended rather than the students' own abilities or past performances. As a result, cases occurred where students who were actually excellent but couldn't attend good schools due to not being from wealthy families were unfairly evaluated with low grades[4].
Students attending low-performing schools often came from disadvantaged backgrounds, while those at high-performing schools often had privileged family environments. This resulted in serious unfairness, with poor minority students being unfairly graded lower. In response, strong criticisms arose from students, parents, educators, and even the media, leading to protest activities. The following image is from an actual demonstration published in a WIRED article.

Faced with protests and public pressure, the government and Ofqual changed their policy, ultimately recalculating grades by placing greater emphasis on teacher evaluations.
In both cases, the methods of data collection, the procedures for processing, and even the details of the algorithms using that data were not disclosed publicly, and no examination or detailed explanation was provided. This seems to have been the cause of the problems. Of course, they may have feared that disclosing system details could lead to the system being analyzed and exploited. However, these events highlight once again how important transparency is when introducing machine learning into initiatives that directly impact the social lives of many people.
In Closing
#I have introduced some examples, some of which may have included vivid content. Ethical issues related to machine learning, especially concerning data, are extremely difficult to handle, and even as someone involved in machine learning, they are challenges that make me think daily.
Some argue that even if there are ethically unacceptable problems included, "the positive outweighs the negative," meaning that by treating biases and ethical problems as issues to address, and asserting that the benefits of machine learning and AI to the economy and society as a whole are overwhelmingly large, we should accept them because the positive aspects surpass the negative.
What do you think about this issue, and which direction do you think we should proceed in?
I would like to spend the New Year's holiday pondering over such issues. (But, in reality, I'll probably forget all about it and just eat and drink.)
I wish you a Happy New Year.
Mashable - Strava’s fitness heatmap has a major security problem for the military https://mashable.com/article/strava-fitbit-fitness-tracker-global-heatmap-threat ↩︎
WIRED.jp - To what extent is labeling of human photos by AI appropriate? An experiment highlights the deep-rooted problem of "bias" https://wired.jp/2019/11/27/viral-app-labels-you-isnt-what-you-think/ ↩︎
New Matilda - High Farce: The Turnbull Government’s Centrelink ‘Robo-Debt’ Debacle Continues To Grow https://newmatilda.com/2017/01/06/the-turnbull-governments-centrelink-robo-debt-debacle-continues-to-grow/ ↩︎
Ada Lovelace Institute - Can algorithms ever make the grade? https://www.adalovelaceinstitute.org/blog/can-algorithms-ever-make-the-grade/ ↩︎