Implementing an OpenAI Realtime API Voice Conversation App Using WebRTC
Back to TopTo reach a broader audience, this article has been translated from Japanese.
You can find the original version here.
The OpenAI Realtime API introduced in October 2024 is a groundbreaking API that enables real-time voice conversations with AI in any application.
Until now, the Realtime API only supported WebSocket, but recently support for WebRTC was announced.
Furthermore, updates such as significant price reductions and improved voice quality have made it an even more accessible API.
That’s it. That’s the tweet. The Realtime API now supports WebRTC—you can add Realtime capabilities with just a handful of lines of code.
— OpenAI Developers (@OpenAIDevs) December 17, 2024
We’ve also cut prices by 60%, added GPT-4o mini (10x cheaper than previous prices), improved voice quality, and made inputs more reliable. https://t.co/ggVAc5523K pic.twitter.com/07ep5rh0Kl
With this update, client applications running in browsers are now recommended to use WebRTC, which is low-latency and easy to implement.
In a previous article, we implemented a voice conversation app using WebSocket with Nuxt, but this time we'll try a version using the newly supported WebRTC.
Below is the configuration of the Realtime API WebRTC version.
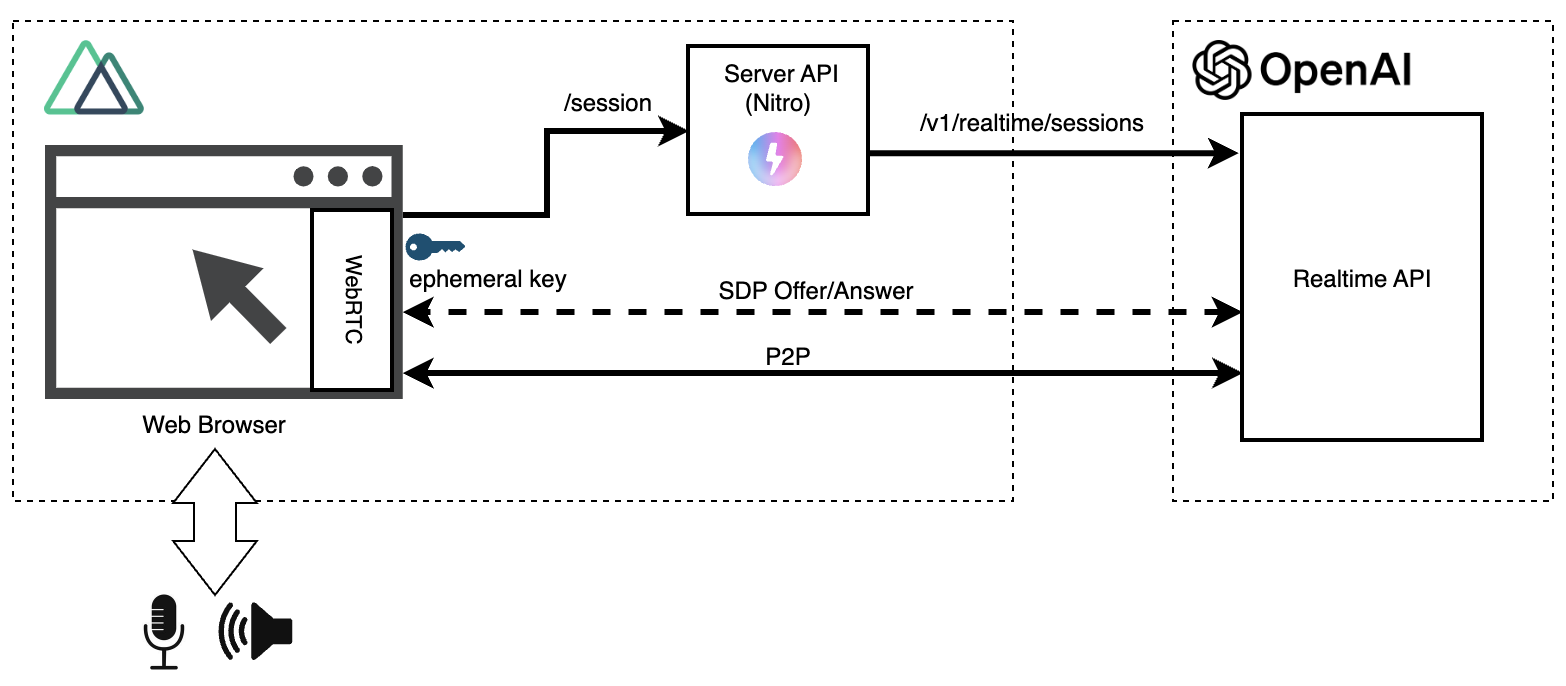
In the previous WebSocket version, to prevent exposing the OpenAI API key to the browser, we prepared a relay server between the browser and the Realtime API.
On the other hand, in the WebRTC version, except for the initial ephemeral key acquisition, the Realtime API and the browser communicate directly (P2P: Peer to Peer).
The source code is publicly available here. In addition to the WebSocket version, the WebRTC version has been added.
Below, I will focus on key points (not all source code is included).
Server API (Ephemeral Key Acquisition)
#To establish a session with the Realtime API, you need to obtain a temporary authentication key (Ephemeral Key) in advance. This operation requires a regular OpenAI API key.
Therefore, this part is implemented as a server-side API.
Here, I prepared an API in advance using Nuxt's server API[1].
export default defineEventHandler(async () => {
return await $fetch<{ client_secret: { value: string } }>('https://api.openai.com/v1/realtime/sessions', {
method: 'POST',
headers: {
'Authorization': `Bearer ${process.env.OPENAI_API_KEY}`,
'Content-Type': 'application/json'
},
body: {
model: 'gpt-4o-realtime-preview-2024-12-17',
voice: 'shimmer',
instructions: 'You are a cheerful assistant. Please speak in a friendly manner without using honorifics.',
input_audio_transcription: { model: 'whisper-1' },
turn_detection: { type: 'server_vad' }
}
});
});
Here, we are configuring various settings of the Realtime API in the request body, but you can also issue a session.update event after establishing the session to make changes, just like with WebSocket.
When you call the above endpoint, you receive a response like the following:
{
"id": "sess_xxxxxxxxxxxxxxxxxxxxx",
"object": "realtime.session",
"model": "gpt-4o-realtime-preview-2024-12-17",
// (omitted)
"client_secret": {
"value": "ek_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"expires_at": 1734673378
},
"tools": []
}
- client_secret.value: Ephemeral Key
- client_secret.expires_at: Auth key expiration time (1 minute after issuance)
From here, I will explain the client-side source code related to the Realtime API.
All source code can be found at the link below.
Obtaining the Auth Key
#When the user requests a connection, we call the server API we created earlier to obtain a temporary authentication key (Ephemeral Key) from the Realtime API.
// Obtain the ephemeral key
const tokenResponse = await $fetch('/session');
const ephemeralKey = tokenResponse.client_secret.value;
Using the ephemeralKey obtained here, we establish a session with the Realtime API.
Since this key has a short expiration time (1 minute after issuance), it's important to obtain it just before starting the session.
Obtaining Microphone Audio
#Next, we use the Media Streams API to obtain audio from the microphone.
// Obtain input audio (permission)
const mediaStream = await navigator.mediaDevices.getUserMedia({
audio: true
});
initAudioWaveFormCanvas(mediaStream); // Start waveform drawing
At the first execution, the browser asks the user for permission to use the microphone.
If permission is granted, we start drawing the audio waveform using the obtained audio stream (mediaStream).
The waveform drawing part is not the main topic here, so we'll omit the explanation (using the same one as in the WebSocket version).
Creating RTCPeerConnection
#We create an RTCPeerConnection object, which manages WebRTC connections.
peerConn = new RTCPeerConnection();
This object functions to establish and manage P2P communication with the Realtime API.
We add audio and data send/receive tracks to the RTCPeerConnection and configure the connection.
Audio Output Processing
#We set the audio track received from the Realtime API to an audio tag and play it.
const audioEl = document.createElement('audio');
audioEl.autoplay = true;
// When a track is received from the Realtime API
peerConn.ontrack = event => {
const remoteStream = event.streams[0];
connectStreamToAnalyser(remoteStream); // Display output audio waveform
audioEl.srcObject = remoteStream; // Connect audio to audio tag
};
In the WebSocket version, we needed to queue the output audio and convert the audio format.
However, in WebRTC, we can simply set the received audio track to the audio tag directly, and the AI-generated voice can be played on the local audio device. This greatly simplifies the processing.
Input Audio (Microphone) Processing
#We add the audio track obtained from the microphone to RTCPeerConnection and send it to the server.
peerConn.addTrack(mediaStream.getTracks()[0]);
In the WebSocket version, we made efforts such as buffering up to a certain size before sending to the Realtime API, but in the WebRTC version, it became just one line 😅
Creating Data Channel and Event Processing
#We create a WebRTC data channel and receive events from the Realtime API.
channel = peerConn.createDataChannel('oai-events');
channel.addEventListener('message', (e) => {
const event = JSON.parse(e.data);
switch (event.type) {
case 'response.audio_transcript.done':
// Output voice text. May be triggered before the user's voice, so display with a delay
setTimeout(() => logMessage(`🤖: ${event.transcript}`), 100);
break;
case 'conversation.item.input_audio_transcription.completed':
if (event.transcript) logMessage(`😄: ${event.transcript}`);
break;
case 'error':
logEvent(event.error);
if (event.code === 'session_expired') disconnect();
break;
}
});
Here, we receive the text of each input and output voice as well as error information, and render them in the UI.
The data channel is not only used for receiving server events like this but also for sending client events.
Below is an example of changing the Realtime API settings with a session.update event[2].
channel.onopen = () => {
channel.send(JSON.stringify({
type: 'session.update',
session: {
input_audio_transcription: { model: 'whisper-1' },
},
}))
}
SDP Exchange and Connection Establishment
#We exchange the WebRTC SDP (Session Description Protocol) and establish the connection.
const offer = await peerConn.createOffer();
await peerConn.setLocalDescription(offer);
const sdpResponse = await $fetch(
`https://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-12-17`, {
method: 'POST',
body: offer.sdp,
headers: {
Authorization: `Bearer ${ephemeralKey}`,
'Content-Type': 'application/sdp'
}
});
await peerConn.setRemoteDescription({
type: 'answer',
sdp: sdpResponse
});
First, we generate our own connection information (SDP offer) and register it as a local setting.
Next, we send that connection information to the Realtime API to generate the Realtime API's connection information (SDP answer). At this time, we also pass the ephemeral key obtained earlier.
The connection information returned from the Realtime API is registered as a remote setting as it is.
This ensures that the connection conditions on both sides match, and communication preparation is completed.
When debugging WebRTC in Chrome, you can access chrome://webrtc-internals/ to check the text information of the SDP offers/answers.
Operation Check
#That's all for the main source code. Below is an example of running it in a local environment.
npm run dev
Below is a video of running the WebRTC version of the web app (unmute to hear the AI voice. Please be mindful of your surroundings):
Conclusion
#In the WebSocket version, we struggled with audio processing, but in this WebRTC version, such complex processing is no longer necessary, and we were able to achieve a very simple implementation.
As it is also recommended by OpenAI, we would like to incorporate this WebRTC version when using the Realtime API in browser apps.
I used Nuxt's server feature for simplicity, but any server-side API is acceptable. ↩︎
I feel like this is a bug with the Realtime API, but at the time of writing, the settings when generating the auth key with the server API are not working. ↩︎