テキストエディタ自作入門
Back to Topテキストエディタ難民
#皆さん、テキストエディタは何を使っているでしょうか。
最近だと、VS Code ですかね。猫も杓子も といった感じですし。
でもわたし、VS Code は好きになれないんですよね。ゴチャゴチャしていて。
なので Sublime text をメインに使っていましたが、日本語の扱いが微妙な所があったり、巨大なファイルを開くのが遅かったりと不満もあり、状況に応じて色々なテキストエディタを切り替えて使う難民生活を送っていました。
コーディングには IDE を使えばいいので、日常のテキスト編集をストレスなく行える、ただそれだけのシンプルなエディタがほしかったのです。
具体的には以下のような感じです。
- Markdown でメモ取り
- コードフェンスでシンタックスハイライトはほしい
- 表を Markdown テーブルとしてペーストしたい(特にペーストできないことで有名なパワポの表も貼り付けたい)
- 巨大なログ・ファイル確認
- 素早く開いてエラー箇所をフィルタリングしたい
- Grep して調査したい
- SQL や JSON の加工
- マルチカーソルで編集したい
- インデント整形したい
- 巨大 CSV ファイル編集
- カラム毎に揃ったインデントで操作したい
- マルチプラットフォーム
- 異なる環境でもキーバインドは同じにしたい
- 設定やプラグインをこねくりまわすことなくアウトオブボックスで使いたい
- 全角スペースやタブ表示
- キャレットのある行だけ表示したい
- セッションの保存
- 未保存で閉じても前回内容を復元したい
難民からの脱却
#難民生活にも疲れてきた折、自分でサクッと作ったほうが早いのではないか?
そう思い立ち、テキストエディタを自作して、現在は難民生活を抜け出すことができました。
しかし、全然「サクッと」とはいかず、思った以上に大変でした。
見返してみると、初回コミットは Sep 12, 2022 となっています。
単純なテキスト編集だけであれば割とすぐに動くのですが、普段使いできるレベルになるまでには1年以上かかった気がします。その上、未だに変更加えてます。
どうしても、夜に数十分だけ実装するという細切れの進め方になってしまうので、翌日には何をどこまで進めたかも忘れているという感じで、モチベーション維持を含め、ある程度まとまった時間で集中して作業しないと進まないなぁ というのが印象です。
学生のように時間のある時期ならまだしも、この年になってやるものではないなと思いますが、ほしい機能があればすぐに追加できるので、思い通りにカスタマイズ可能なエディタが手に入ったと思うことにしています。
ということで本稿では、テキストエディタの自作をはじめるにあたって、知っておきたかった事柄について記しておこうと思います。
テキストバッファ
#テキストエディタを自作するにあたり、最初に考えなければならないのが、文字シーケンスをどのようなデータ構造で扱うか になります。
世の中のテキストエディタは大抵、Gap Buffer、Linked List、Rope、Piece Table のいずれかのデータ構造を元にして、独自の工夫を施しているので、これらを見ていきましょう。
Array
#最初は、最も単純な例から始めます。文字シーケンスを配列として扱う方法です。
以下のように文字シーケンスを単にバイト配列として扱うことを考えます。
byte[] bytes = Files.readAllBytes(path);
この時、This is apple. という文字シーケンスは以下のような連続したメモリレイアウトとして確保されます。
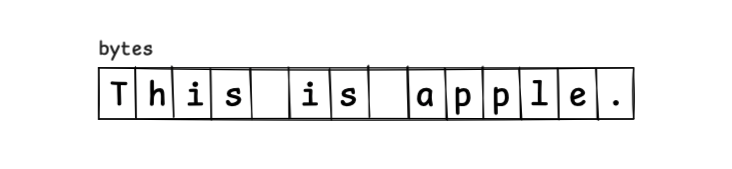
an という文字列を挿入するには、元のサイズより3大きい配列を再確保し、文字を新しい配列にコピーして設定する必要があります。
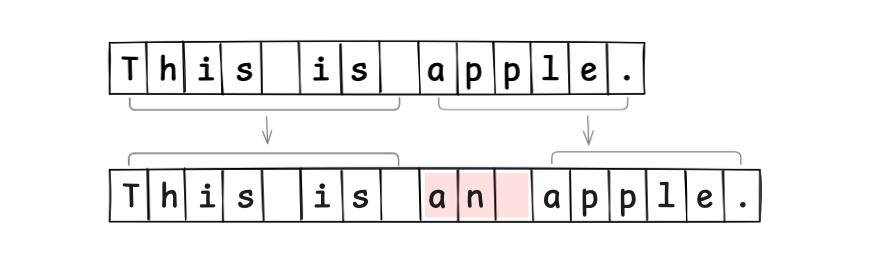
当たり前の話ですが、編集の度に新しいメモリ領域を確保しなおす必要があるため、非常に効率が悪いです。
そこで、メモリ領域を余分に確保しておき、バッファとして利用することを考えます。
Buffer
#テキスト編集の度にメモリ領域を再確保するのは明らかに非効率なため、メモリ領域中に未使用のバッファ領域を用意します。
概念的には、以下のような Buffer を考えることになります。
class Buffer {
byte[] bytes;
int length;
}
5要素分の未使用領域(網掛け部分)をバッファとして確保した場合は以下のようになります。
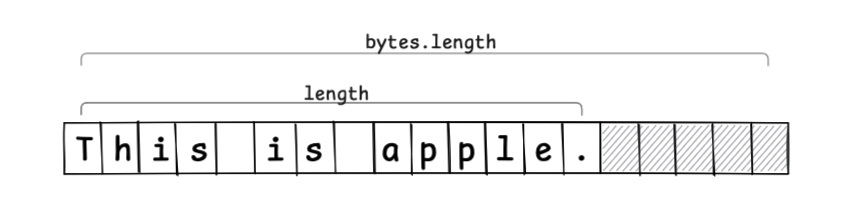
文字列の挿入時には、新しい配列を作成することなく、値の設定と移動で編集操作が完結します(バッファ領域が不足した場合には、新たなメモリ領域を確保してコピーする必要があります)。
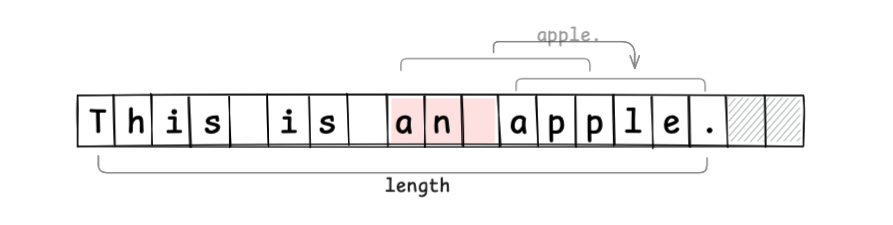
文字列の編集をバッファ領域で吸収することで、余計なメモリの確保が削減できました。
しかし、編集位置から末尾まで値を移動させる必要があり、もう少し工夫の余地がありそうです。
Gap Buffer
#多くのテキスト編集操作は、カーソル位置に対して行われる という事実を利用したものが Gap Buffer です。
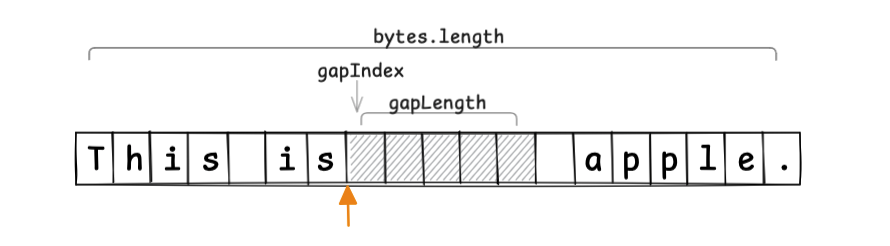
先程の例では、メモリの末尾にバッファを用意しましたが、 Gap Buffer では、カーソル位置(キャレット位置)にバッファを設けます。
概念的には、以下のような GapBuffer として考えます。
class GapBuffer {
byte[] bytes;
int gapIndex;
int gapLength;
}
現在のカーソル位置がオレンジの矢印にあり、Gap として5要素分の未使用領域を割り当てた場合は以下のようになります。
カーソルを移動する際、その移動に合わせてバッファ位置を移動させていきます。
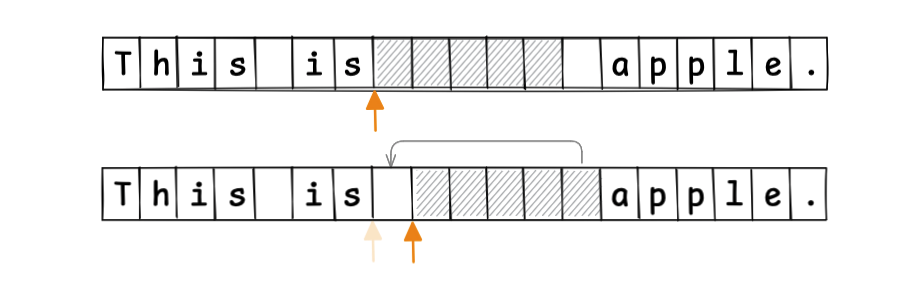
これにより、テキストの編集操作を常にバッファ位置で行うことができます。先の例で見た、編集点以降の値のシフトが不要になりました。

バッファの開始位置と長さがわかっているため、インデックスを指定したランダムアクセスも簡単に実現できます。
Gap Buffer は、Emacs でも使われている効率の良いテキストバッファの実現手法になります。
さて、ここまでは文字シーケンスを1つの塊として扱う例を見てきましたが、これらを複数の小さな塊として分割統治することも考えられそうです。
Linked List
#文字シーケンスを1つの連続した領域として管理するのではなく、小さな塊として分割統治できれば、編集操作を局在化して扱うことができます。
そこで真っ先に思いつくのは、文字シーケンスを特定サイズのチャンクに分割したノードとして扱い、連結リストとして管理する方法です。
概念的には、以下のようなクラスを考えることになるでしょう。
class LindedList {
Node head;
Node tail;
}
class Node {
byte[] chunk;
Node next;
Node prev;
}
例えば、先の例を、単語単位のチャンクとして扱った場合は以下のような構造になります。
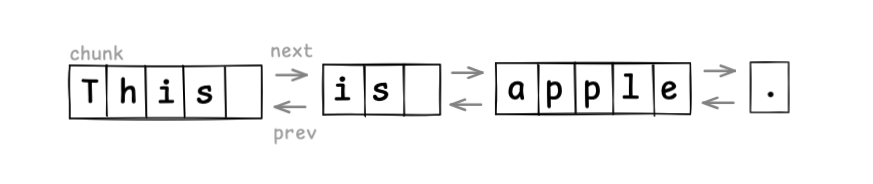
テキストの編集処理は、新しいノードを作成してリンクの張り替えを行うだけで済むため効率も良さそうです。

ここでは説明のため単語単位のチャンクとして扱いましたが、細かくし過ぎるとリンクポインタのメモリ使用量が多くなるため、通常は1行をチャンクとして扱う実装が現実的です(改行の挿入でノードの分割、行の削除でノードの結合)。
文字シーケンスを連結リストとして扱うのは、実装が簡単ですが、要素へのランダムアクセスが遅いという欠点があります。
インデックスアクセスを行う場合は、先頭からリストを辿る必要があり、大きなテキストファイルでは特に非効率です。通常は、キャレット位置をカーソルとして、カーソルベースで要素にアクセスするなどの工夫が必要です。
では、文字シーケンスをチャンクに分割した上で、インデックスによるランダムアクセスを効率的に行うことはできないでしょうか。
Rope
#文字シーケンスをチャンクに分割し、インデックスアクセスを二分木で追尾できるようにしたものが Rope です。紐(String)を強化した縄(Rope)というわけです。
概念的には、以下のようなクラスを考えます。
class Rope {
Node root;
}
interface Node {
int weight();
int totalLength();
}
record Branch(Node left, Node right, int weight) implements Node {
Branch(Node left, Node right) {
this(left, right, left.totalLength());
}
public int totalLength() {
return left.totalLength() + right.totalLength();
}
}
record Leaf(String text) implements Node {
public int weight() { return text.length(); }
public int totalLength() { return weight(); }
}
ここで、weight は、左側ノードの文字列長の合計を表します。
Leaf ノードには文字シーケンスのチャンクを保持し、Branch ノードで weight を管理します。
単語単位のチャンクとして扱った場合は以下のような二分木として管理します。
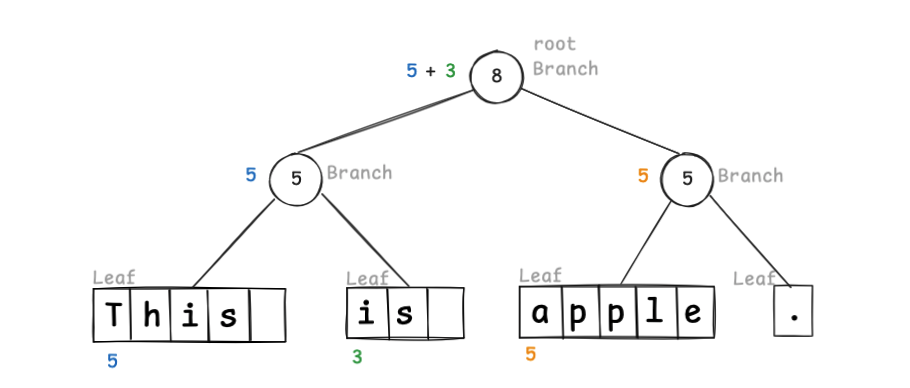
weight は、そのノードが分割する文字シーケンスの先頭からのインデックス位置となるため、例えばインデックス10の位置は、以下のように木を辿ることで到達できます。
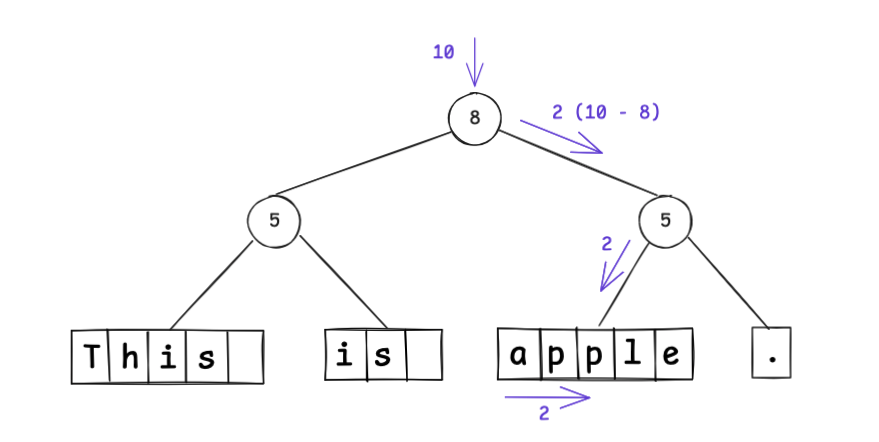
ルートノードは、左側のthis is と 右側のapple. に分割した中央部分のインデックスを表すため、10 のインデックス位置は右側木の 2 の位置に存在し、2 の位置は 5 より小さいため、その左側のノードに存在する といった具合です。
連結リストで問題だった、ランダムアクセスの効率が改善されていることがわかると思います。
前述までと同様に an を挿入する場合は以下のように木を更新することになります。
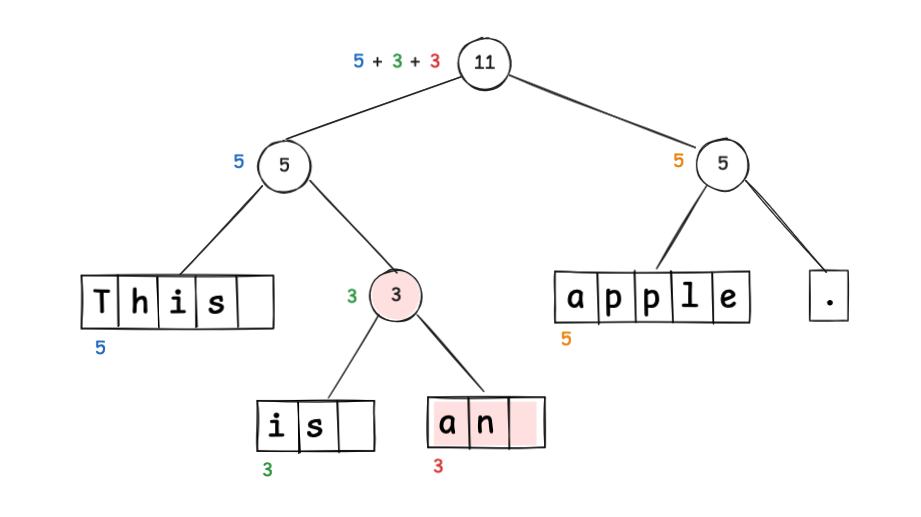
この更新による weight の更新範囲は、対象ノードを上に辿ったノードに対してのみに限定できる という点に注目してください。apple と . を含む右側のノードにはなんの影響も及ぼしません。
元の木構造はそのままに、テキストの更新後の木構造を更新箇所を上に辿ったノードに限定してリンクし直すことで、変更後の文字シーケンスを表現できるのです。つまり、以下のように、文字シーケンスの変更をイミュータブルに扱うことができる ということです。
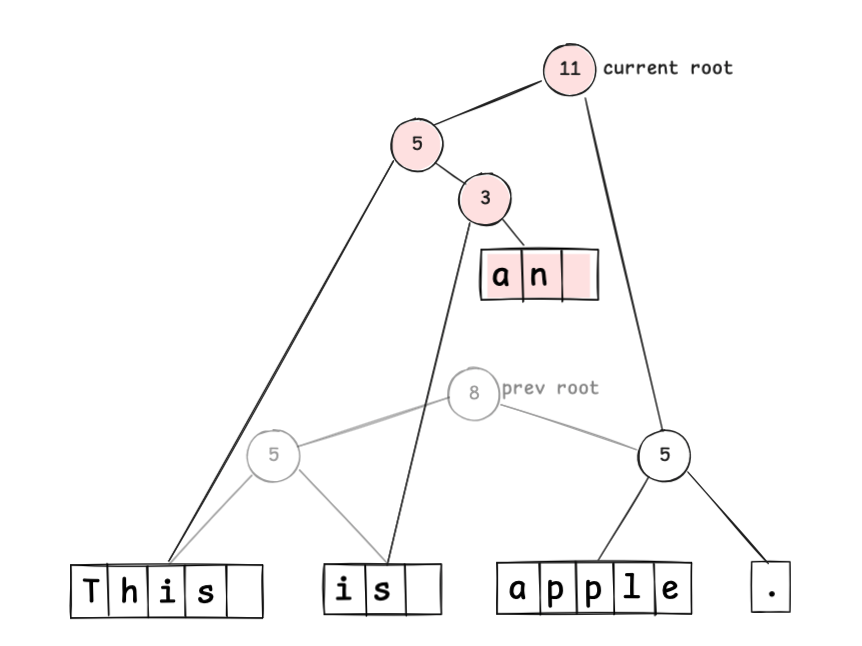
テキストエディタでのUndo操作は、1つ前のルートノードに戻すだけで実現できる点にも注目してください。
このように Rope は文字シーケンスを表現する強力なデータ構造ですが、木構造を維持するためのオーバーヘッドが必要であり、木のバランシング操作も必要です。
加えて、テキストファイルを開いた際に木を構築する必要があるため、巨大なファイルを開くのには時間を要します。
巨大なファイルを効率よく編集できるデータ構造は考えられないでしょうか。それが次に紹介する Piece Table です。
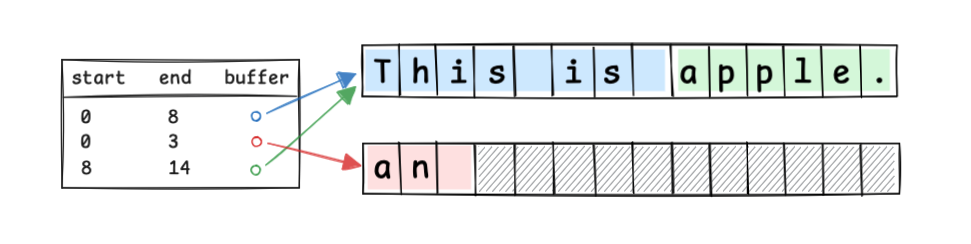
Piece Table
#Piece Table は、テキストの変更操作を追記管理するデータ構造です。
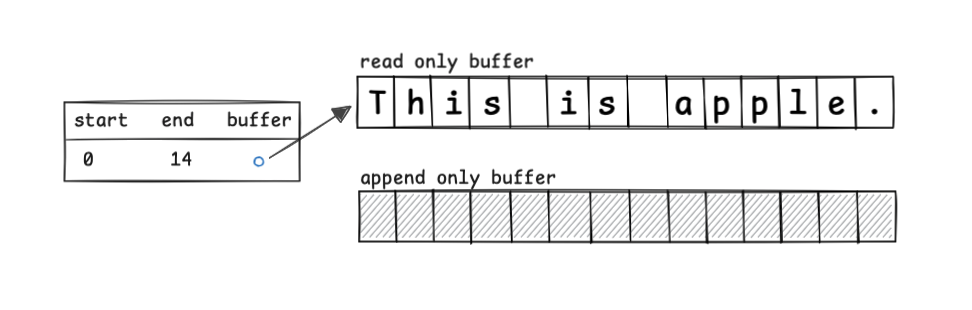
Piece Table では、元の文字シーケンスを read only なバッファで管理し、そこに加えられた変更を append only なバッファに配備し、それらのバッファのインデックス位置をテーブルで管理します。
This is apple. というファイルを開いた直後は以下のようになります。
インデックス8の位置に an を挿入する場合は、以下のようにテーブルのインデックスを更新することで変更を扱います。
概念的には、以下のようなクラスを考えることになるでしょう。
record Piece(Buffer target, int index, int length) {
int end() { return index + length; }
}
class PieceTable {
List<Piece> pieces;
Buffer appendBuffer;
PieceTable(Buffer readBuffer) {
this.pieces = new ArrayList<>();
this.pieces.add(new Piece(readBuffer, 0, readBuffer.length()));
this.appendBuffer = AppendBuffer.of();
}
}
元のファイルが巨大でも、 read only なバッファは直接ファイルやメモリマップドファイル として扱うことで、メモリ確保がほぼ不要になり、編集内容は変更分の Piece の管理だけで済みます。
ただし、変更を繰り返すと Piece の数が増加したり、append only なバッファが断片化するデメリットがあります。
テキストバッファのデータ構造まとめ
#これまで見てきたデータ構造をまとめると以下の様になります。
| データ構造 | 特徴 |
|---|---|
| Gap Buffer | 実装が非常にシンプル カーソル位置での入力が極めて高速( O(1))カーソル位置の大きな移動・マルチカーソル操作で遅延が生じる可能性がある バッファ領域の枯渇でメモリの再割り当てが必要 Emacs で利用されている |
| 連結リスト | 位置特定後の挿入や削除が一定時間で可能(O(1))ランダムアクセスが O(N)となるため、カーソルを利用するなどの工夫が必要実装が簡単なため、初期のエディタ実装で採用されることが多い |
| Rope | 挿入やランダムアクセスが O(log N)二分木の構築やバランシング処理によるオーバヘッドが発生 編集操作をイミュータブルにすることができる Zed Editor では Rope を基にしたデータ構造が利用されている |
| Piece Table | メモリ効率が良い 挿入や削除は追記型となるため高速( O(1))編集によりPieceの数が増加するとパフォーマンスが劣化する VS Code では Piece Table を基にしたデータ構造が利用されている(インデックスアクセスにはRopeのように二分木を使用) |
どれも一長一短があり、どんな状況においてもベスト という解はありません。
私の場合は、巨大ファイルを扱いたいため、Piece Table を採用することにしました。
それぞれの利用用途に応じてデータ構造を選んでください。
データ構造だけでは語れない
#データ構造が決まってテキストエディタを作り始めても、途中で迷うポイントが色々と発生します。
いくつか代表的なものに絞って以下に見てみましょう。
スクロール位置の特定
#テキストエディタには、通常、縦スクロールバーと横スクロールバーが表示されます。
縦スクロールバーを表示するには、ファイル全体の行数と、現在画面に表示されている行数を特定する必要があります。
横スクロールバーを表示するには、ファイル中の最長の行と現在の画面幅を特定する必要があります。
厄介なのは横スクロールバーの制御で、最長の行は、編集操作によって最長の行ではなくなる可能性があるので、編集の都度最長の行を探し出す必要があります。
私の場合は、横スクロールバーを完全にトラックすることは諦め、現在画面に表示している行に限定して最長行を見つける実装としました。
折り返し表示
#テキストエディタでは、1行をウインドウ幅で論理的に折り返して表示できるものがほとんどです。
しかし、この折り返し判定は厄介で、画面表示上のグリフに応じた文字の幅を計算する必要があります。
通常、文字の幅は文字毎に異なり、さらに面倒なのが、結合文字や合字(Ligature)という概念です。
これらは、複数の文字を繋げて一文字として表示するため、文字幅の計算が都度必要です。
厳密に対応しようとすると、全ての行に対して画面表示上の幅を計算し、適切な折り返し位置を見つける必要があり、非常に高価な処理になります。
折り返し計算は画面に表示されている部分だけ行う、という割り切りもできますが、そうすると先に述べたスクロールバーの長さと辻褄が合わなくなってしまいます。
ですので、折り返し表示は一定サイズ以下のファイルに制限したり、文字幅の計算はある程度割り切った近似値として扱うなどして、パフォーマンスとの折衷案を設けるのが現実的です。
文字シーケンスへのランダムアクセス
#データ構造のまとめでは、ランダムアクセスが O(1) で効率が良い などと書きましたが、現実的には難しい面があります。
全てASCII 文字で、1文字は1バイトという理想的な世界であれば話は簡単ですが、現実はそう上手くは出来ていません。
例えば UTF-8 は、1文字(コードポイント)で 1~4byte の可変エンコーディングとなるため、N文字目にアクセスしようとしてもインデックスアクセスはできず、1つずつバイト長を見ていく必要があります。
テキストファイルを全てメモリに読み込み、メモリ上でアクセスしたとしても、多くの言語ランタイムは、文字列を内部的に UTF-16 でエンコードされたバイト列として扱うため、結局可変エンコードを加味する必要があります。
固定長の UTF-32 としてテキストを保持すれば、ランダムアクセスは容易になりますが、メモリ使用量が増大します。
例えば、Piece Table で、UTF-8 のファイルを直接 read-only buffer として利用する場合を考えてみましょう。
画面上をクリックし、その位置が画面表示上のN文字目(Unicodeコードポイント)だった場合、言語ランタイム上の UTF-16(1〜2バイト) におけるインデックス位置に変換し、ファイル上のUTF-8(1〜4バイト)におけるインデックス位置にさらに変換し、そしてようやくファイルの当該位置にアクセスできる といった具合で、いかにも非効率になります。
先に述べたスクロールバーや折り返し表示のことも考え、行数や文字数といったメタ情報とテキストバッファとのマッピング、グリフ幅などの表示上の情報も合わせて文字シーケンスを扱わなければならず、これらをパフォーマンスとメモリ効率のバランスを取りながら実装を工夫する必要があります。
このあたりがテキストエディタ実装の奥深さになります。