コピペで始める:Amazon Q Developer × Spec Kitで始めるAI駆動開発
Back to Top本記事は、以下イベントで講演した内容の文字起こし版です。
2025年11月17日より、Q Developer CLIは正式名称「Kiro CLI」となりました。本記事では執筆時点の名称「Q Developer CLI」で説明していますが、コマンドや機能は同じです。今後のアップデートで q コマンドが kiro コマンドに変更される可能性があります。
目次
#- はじめに
- 背景知識:なぜSDD+TDDなのか
- 環境構築:最小限の準備で始める
- 実践①:仕様策定 - specify → clarify の反復
- 実践②:実装 - TDDサイクルの実践
- 実践③:デプロイ - 自然言語だけでAWS構築
- よくある質問とトラブルシューティング
- まとめと参考資料
はじめに
#対象読者
#本記事は以下のような方を対象としています。
- 生成AIを使った開発に興味がある開発者
- AIコード生成で「意図しない実装」に困った経験がある方
- 品質を保ちながらAIを活用したい方
- Amazon Q Developer(Kiro CLI)やSpec Kitを試したい方
前提知識
#以下の基礎知識があることを前提としています。
- Git、GitHubの基本操作
- Docker、Docker Composeの基本概念
- Java/Spring Boot、React/TypeScriptの基礎(サンプルプロジェクトで使用)
- AWSの基本知識(デプロイセクション)
本記事で得られること
#本記事を読むことで、以下ができるようになります。
- 環境構築からデプロイまでの工程を理解できる
- コピペで動く実践的なプロンプト例を入手できる
- AI駆動開発における品質確保の方法を学べる
- 実際に動くサンプルプロジェクトを手に入れられる
背景知識:なぜSDD+TDDなのか
#生成AI駆動開発の現状
#2022年末のChatGPT登場以降、AIを活用した開発は急速に普及しました。現在、GitHub Copilot、Cursor、Claude Code、Windsurf、Amazon Q Developer[1]、Kiroなど、多くのコーディングアシスタントが利用可能です。
AIの進化は「モデル中心(GPT時代)」から「エージェントネットワーク中心」へと移行しつつあり、単なるコーディング支援から自律実行型エージェントへと発展しています。
AIコード生成の「影」
#しかし、実際の開発現場では以下のような課題に直面することがあります。

1. 過剰実装
要求していない機能を勝手に追加してしまう。
例:
- ログイン機能だけ依頼したのに、パスワードリセット機能まで実装される
- シンプルなCRUDを依頼したのに、検索機能や並び替えまで追加される
2. 仮定
要求仕様の曖昧な部分を勝手に補完し、意図しない設計になる。
例:
- 「ユーザー情報を保存」→ AIが勝手にメールアドレスを必須項目にする
- 「データを表示」→ AIが勝手にページングを10件単位で実装する
3. 成功宣言
ビルドやテストが失敗しているのに「完了しました」と報告する。
例:
- コンパイルエラーがあるのに「実装完了」
- テストが落ちているのに「全てのテストが成功」と報告
4. 保守コストの増大
最近の研究[2][3]によると、AI支援ツールで開発スピードを上げても、保守やレビュー、品質管理コストは上昇する傾向にあります。また、経験豊富な開発者が本来の新規開発業務から外れ、保守業務に偏るパターンも観察されています。
SDD+TDDによる解決アプローチ
#これらの課題を解決するために、以下2つの手法を組み合わせます。
SDD(Specification-Driven Development:仕様駆動開発)
コードを書く前に、期待する動作・要件・制約を明確に仕様化し、それをもとに開発を進める手法。
効果:明確な仕様があると、AIが曖昧さなく正確にコードを生成可能になる[4]。
TDD(Test-Driven Development:テスト駆動開発)
コードを書く前にテストを定義し、失敗を起点に修正・改善を繰り返す手法。
効果:LLMによるコード生成にTDDの枠組みを導入すると生成成功率が向上[5]。テストを「仕様・制約」として明示することで、AIの生成精度が改善[6]。
SDDで仕様を固め、TDDで正しい振る舞いを基準化することで、AIの制御可能性を高めます。
環境構築:最小限の準備で始める
#前提条件チェックリスト
#以下がインストール済みであることを確認してください。
- Windows + WSL2(Linuxでも可)
- Git
- VSCode
- Docker Desktop(または Docker Engine)
- AWS Builder ID または AWS IAM Identity Center アカウント(Q Developer用)
ステップ1:GitHubリポジトリのクローン
#今回講演用に作成した公開サンプルリポジトリをクローンします。
# 作業ディレクトリに移動
cd ~/workspace
# リポジトリをクローン
git clone https://github.com/mamezou-tech/aidd-demo.git
# ディレクトリに移動
cd aidd-demo
リポジトリの内容:
backend/: Spring Boot バックエンド(Java 17, Spring Boot 3.x)frontend/: React フロントエンド(React 18, TypeScript, Vite)specs/: 仕様書ドキュメント.devcontainer/: DevContainer設定.amazonq/: Amazon Q Developer設定docker-compose.yml: 開発環境構成
ステップ2:VSCodeでDevContainerを起動
## VSCodeで開く
code .
VSCodeが起動したら、以下の手順を実行します。
- 左下の緑色のボタン(リモートエクスプローラー)をクリック
- 「Reopen in Container」を選択
- 初回は数十分かかります(Dockerイメージのビルド)
- コンテナ内のターミナルが自動的に開く
DevContainerに含まれるもの:
- Node.js、Java 17、Gradle
- AWS CLI
- Q Developer CLI 1.19.7
- 各種開発ツール
ステップ3:Q Developer CLI(Kiro CLI)のログイン
#Free プランの場合(AWS Builder ID)
# ログインコマンド
q login
# ブラウザが開くので、AWS Builder IDでログイン
# ログイン完了後、ターミナルに戻る
Pro プランの場合(IAM Identity Center)[7]
# ログインコマンド
q login
# プロンプトに従ってIAM Identity Centerの情報を入力
# Start URL: https://[your-domain].awsapps.com/start
# Region: ap-northeast-1 など
# ブラウザが開くので、認証を完了
対話モード開始:
q chat
2025年11月17日以降、Q Developer CLIは正式名称「Kiro CLI」となりました。本記事では旧名称「Q Developer CLI」で説明していますが、機能は同じです。今後のアップデートで q コマンドが kiro コマンドに変更される可能性があります。
ステップ4:アプリケーションの起動と動作確認
#1. データベースとバックエンドの起動
Dev Container内のターミナルで以下を実行します。
docker compose up -d
このコマンドで以下が起動します。
- MySQLデータベース(ポート3306)
- Spring Bootアプリケーション(ポート8080)
コンテナが起動していることを確認します。
docker compose ps
# 期待される出力:
# mysqldbとappコンテナのSTATUSがUp (healthy)
2. フロントエンドの起動
以下を実行します。
cd frontend
npm run dev
※依存パッケージはDev Container起動時に自動インストールされます。
フロントエンドは http://localhost:3000 で起動します。
動作確認:
ブラウザで以下にアクセスします。
- フロントエンド: http://localhost:3000
- バックエンドAPI: http://localhost:8080/api/health
トラブルシューティング(環境構築)
#Q1: DevContainerが起動しない
原因: Dockerが起動していない、またはリソース不足。
解決策:
# Dockerが起動しているか確認
docker ps
# リソース設定を確認(Docker Desktopの場合、Settings > Resources)
Q2: q コマンドが見つからない
原因: DevContainerのビルドが不完全。
解決策:
# コンテナを再ビルド
# VSCodeで Ctrl+Shift+P → "Dev Containers: Rebuild Container"
# または、コマンドラインから
docker compose down
docker compose up -d --build
Q3: ポート3000や8080が既に使用されている
原因: 他のアプリケーションがポートを使用中。
解決策:
# 使用中のプロセスを確認
lsof -i :3000
lsof -i :8080
# プロセスを終了するか、docker-compose.ymlのポートを変更
# ports:
# - "3001:3000" # 3000 → 3001に変更
実践①:仕様策定 - specify → clarify の反復
#Spec Kitコマンド一覧
#Spec Kitは以下のコマンドを提供します。
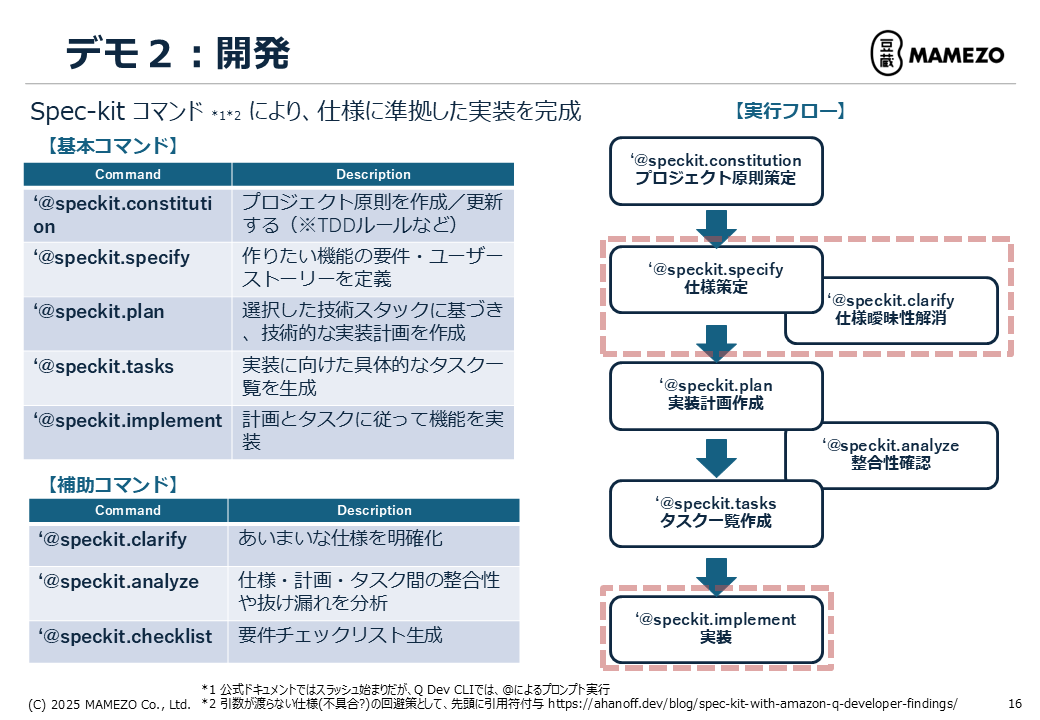
| コマンド | 説明 | 主な用途 |
|---|---|---|
@speckit.constitution |
プロジェクト原則を作成・更新 | TDDルールなどの定義 |
@speckit.specify |
機能の要件・ユーザーストーリーを定義 | 仕様書作成 |
@speckit.clarify |
曖昧な仕様を明確化 | 仕様の精緻化 |
@speckit.plan |
技術的な実装計画を作成 | アーキテクチャ設計 |
@speckit.analyze |
仕様・計画・タスク間の整合性分析 | 矛盾チェック |
@speckit.tasks |
実装タスク一覧を生成 | タスク分解 |
@speckit.implement |
計画とタスクに従って実装 | コード生成 |
@speckit.checklist |
要件チェックリスト生成 | 進捗管理 |
Q Developer CLIでは、スラッシュ(/)ではなくアットマーク(@)でプロンプトを呼び出します。引数を正しく渡すため、コマンドの先頭に引用符(')を付けます[8]。
対話型セッションの開始
#まず、Q Developer CLIの対話型セッションを開始します。以降のコマンドはすべてこのセッション内で実行します。
q chat
セッションが開始されると、プロンプトが表示され、コマンドを入力できるようになります。
ステップ1:プロジェクト原則の確認
#プロジェクトにTDDなどの原則が定義されているか確認します。
追加が必要な場合は、以下のコマンドで追加が可能です。
'@speckit.constitution <プロジェクト原則に追加したい内容>'
記載例:
# Project Constitution
## Test-First Imperative
コードの前に必ずテストを書く。
- ユニットテストを先に作成
- テストが失敗すること(Red phase)を確認してから実装
- 非交渉事項として厳格に適用
## Library-First Principle
すべての機能は独立したライブラリとして実装する。
## Simplicity Gate
過度なエンジニアリングを防ぐ。
- 初期実装は最大3プロジェクトまで
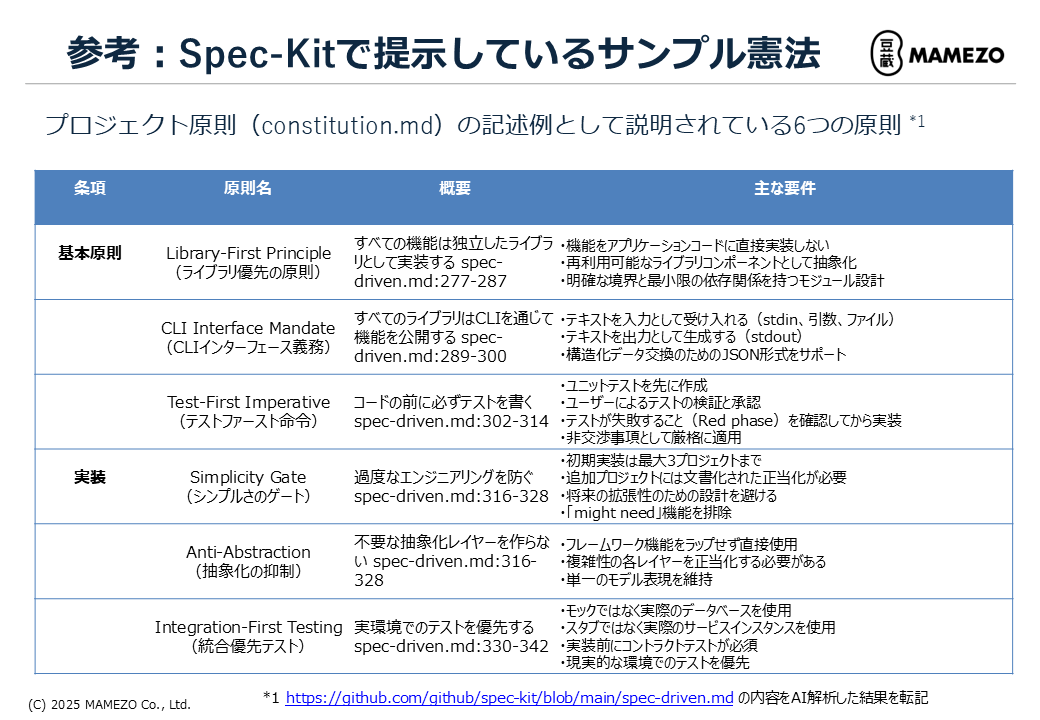
公開リポジトリのconstitution.mdには、Spec Kitで提示されている6つの原則を記述しています。
ステップ2:仕様を策定する(@speckit.specify)
#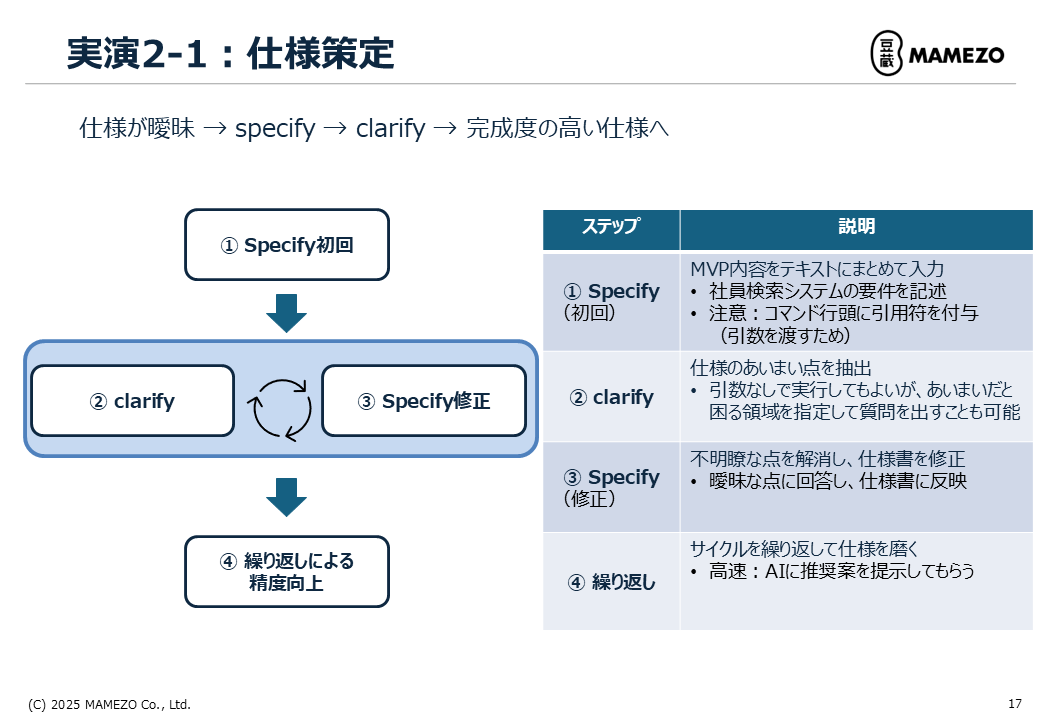
初回のspecify
社員検索システムMVPの仕様を作成します。
プロンプト例:
'@speckit.specify
社員検索システム(MVP)の仕様を作成してください。
【目的】
社員情報を一元管理し、人事が「誰がどのスキルを持ち、どの組織に所属しているか」をすばやく把握できるようにすること。
【主な利用者】
- 人事:全社の社員・スキル・組織情報を俯瞰し、配置検討や採用計画のインプットに利用する。
【想定ユースケース】
- 人事が、特定スキル(例:Java、AWS)を持つ社員を検索し、部署横断で候補者リストを作成する。
- 顔写真付きの社員一覧・詳細画面で、人物を視覚的に識別できる。
【MVPで提供したい機能範囲】
- ログイン機能(シンプルな認証)
- 社員情報の登録・閲覧・検索
- 基本属性(氏名、社員ID、所属組織、役職、雇用区分)
- 顔写真の登録・表示
- スキル情報の閲覧
- スキルマスタの管理
- 社員ごとの保有スキルの紐づけ
- 組織の階層管理(親子関係のみのシンプルなツリー構造)
【MVP対象外】
- 詳細な権限管理
- 監査ログ
- 高度なスキル分析
- 組織改編の履歴管理
- 外部システム連携
【アウトプットの期待】
- ユースケース一覧と簡単なフロー
- 画面・APIの概要
- データモデルの概要
- 非機能要件(MVP に必要な最低限)
- MVP対象外機能の明示
'
ポイント:
- 目的を明確に記述する
- 利用者のペルソナを定義する
- MVPの範囲を明確にする(特に「対象外」を明示)
- 曖昧な表現を避ける
出力例:
AIが spec.md ファイルを生成します。内容には以下のような内容が含まれます。
# 社員検索システムMVP 仕様書
## 1. 概要
...
## 2. ユースケース
### UC-001: ログイン
- アクター: 人事担当者
- 前提条件: ユーザーアカウントが登録されている
- 基本フロー:
1. ユーザーがログイン画面でユーザー名とパスワードを入力
2. システムが認証を実行
3. 認証成功時、ホーム画面にリダイレクト
...
## 3. 画面設計
### 3.1 ログイン画面
- 入力項目: ユーザー名、パスワード
- ボタン: ログイン
...
## 4. データモデル
### 4.1 社員(Employee)
- employee_id (PK): 社員ID
- name: 氏名
- organization_id (FK): 所属組織
- photo_url: 顔写真URL
...
ステップ3:曖昧な点を明確化する(@speckit.clarify)
#生成された仕様書には、まだ曖昧な点が残っています。clarifyコマンドで明確化します。
プロンプト例:
'@speckit.clarify
社員検索システムMVP仕様書に対して、以下の点について曖昧な点を洗い出し、質問リストを作成してください:
- ログイン/認証方式(MVPでの具体的な前提)
- スキル検索と表示方法
- 顔写真の登録方法
- 一覧画面におけるページング/ソートの扱い
'
出力例:
AIが以下のような質問リストを生成します。
# 仕様の曖昧点に関する質問
## ログイン/認証方式
Q1: パスワードの暗号化方式は何を使用しますか?(bcrypt、PBKDF2など)
Q2: セッション管理はどうしますか?(Cookie、JWT、サーバーサイドセッションなど)
Q3: ログアウト機能は必要ですか?
Q4: パスワードリセット機能はMVPに含まれますか?
## スキル検索と表示方法
Q5: スキル検索は完全一致ですか、部分一致ですか?
Q6: 複数スキルのAND検索/OR検索は必要ですか?
Q7: スキルレベル(初級/中級/上級など)の扱いはどうしますか?
## 顔写真の登録方法
Q8: 顔写真のファイルサイズ上限は?
Q9: 許可する画像形式は?(JPEG、PNG、GIFなど)
Q10: 顔写真がない場合、デフォルト画像を表示しますか?
## ページング/ソート
Q11: 一覧画面の1ページあたりの表示件数は?
Q12: ソート項目は何ですか?(氏名、社員ID、組織など)
Q13: デフォルトのソート順は?
ステップ4:質問に回答して仕様を修正(@speckit.specify)
#AIからの質問に回答し、仕様を修正します。
プロンプト例:
'@speckit.specify
社員検索システムMVP仕様書を、以下の回答に基づいて更新してください。
【ログイン/認証方式】
A1: bcryptを使用
A2: JWTトークンをCookieに保存
A3: ログアウト機能は必要
A4: パスワードリセット機能はMVP対象外
【スキル検索と表示方法】
A5: 部分一致(前方一致)
A6: 複数スキルのAND検索のみ
A7: スキルレベルは3段階(初級/中級/上級)
【顔写真の登録方法】
A8: 5MB以下
A9: JPEG、PNGのみ
A10: デフォルトアバター画像を表示
【ページング/ソート】
A11: 20件/ページ
A12: 氏名、社員ID、所属組織でソート可能
A13: 氏名の昇順
'
ステップ5:反復
#specify → clarify → specify のサイクルを繰り返すと、曖昧な点がかなり減少します。
反復のポイント:
- 仕様が曖昧だと困る点を指定すると効果的
- AIに推奨案を提示してもらうことで高速化できる
高速化の例:
'@speckit.clarify
社員情報の登録と更新について、曖昧な点を洗い出し、
あなたの推奨案も合わせて提示してください。
'
成果物:spec.md
#最終的に以下のような完成度の高い仕様書が得られます。
- ユースケースが具体的に記述されている
- 画面項目・API仕様が明確
- データモデルが詳細に定義されている
- 曖昧な点が解消されている
- MVP対象外が明確
実践②:実装 - TDDサイクルの実践
#ステップ1:実装計画を作成(@speckit.plan)
#@speckit.plan
出力例:
# 実装計画
## 技術スタック
- Backend: Java 17, Spring Boot 3.2.0, Spring Security, Spring Data JPA
- Frontend: React 18, TypeScript, Tailwind CSS
- Database: MySQL 8.0
- Test: JUnit 5, Testcontainers, Playwright
## アーキテクチャ
### バックエンド
- レイヤードアーキテクチャ
- Controller層: REST APIエンドポイント
- Service層: ビジネスロジック
- Repository層: データアクセス
### フロントエンド
- コンポーネントベースアーキテクチャ
- React Router for SPA
- Context API for 状態管理
## セキュリティ
- JWT認証
- bcryptによるパスワードハッシュ化
- CORS設定
この内容が plan.md として保存されます。
ステップ2:タスク一覧を生成(@speckit.tasks)
#'@speckit.tasks
タレントマネジメントシステムMVPを、2〜3日の粒度の実装タスクに分解してください。
'
出力例:
# 実装タスク一覧
## Phase 1: 基盤構築
- Task 1.1: プロジェクト構造のセットアップ
- Task 1.2: データベーススキーマの作成
## Phase 2: 認証機能
- Task 2.1: ユーザーエンティティとRepository
- Red: UserRepositoryTestを作成し、失敗を確認
- Green: User.java, UserRepository.javaを実装し、テスト成功
- Refactor: コードの整理
- Task 2.2: JWT認証の実装
- Red: JwtUtilTestを作成し、失敗を確認
- Green: JwtUtil.java, JwtAuthenticationFilter.javaを実装
- Refactor: コードの整理
- Task 2.3: ログインAPIの実装
- Red: AuthControllerTestを作成し、失敗を確認
- Green: AuthController.java, AuthService.javaを実装
- Refactor: コードの整理
## Phase 3: 社員管理機能
- Task 3.1: 社員エンティティとRepository
- Task 3.2: 社員登録API
- Task 3.3: 社員検索API
- Task 3.4: 社員詳細API
...
この内容が tasks.md として保存されます。
ステップ3:実装(@speckit.implement)
#いよいよ実装です。Spec Kitのテストファースト原則に基づき、TDDサイクルを使って実装を進めます。
Task 2.1の実装例:ユーザーエンティティとRepository
プロンプト例:
'@speckit.implement Task 2.1'
AIの動作例:
- まずテストを生成(Red phase)
UserRepositoryTest.java:
package com.example.demo.repository;
import com.example.demo.entity.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.jdbc.AutoConfigureTestDatabase;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
import org.testcontainers.containers.MySQLContainer;
import org.testcontainers.junit.jupiter.Container;
import org.testcontainers.junit.jupiter.Testcontainers;
import java.util.Optional;
import static org.assertj.core.api.Assertions.assertThat;
@DataJpaTest
@Testcontainers
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
class UserRepositoryTest {
@Container
static MySQLContainer<?> mysql = new MySQLContainer<>("mysql:8.0")
.withDatabaseName("testdb");
@Autowired
private UserRepository userRepository;
@Test
void ユーザー名でユーザーを検索できる() {
// Arrange
User user = new User();
user.setUsername("testuser");
user.setPassword("hashedPassword");
userRepository.save(user);
// Act
Optional<User> found = userRepository.findByUsername("testuser");
// Assert
assertThat(found).isPresent();
assertThat(found.get().getUsername()).isEqualTo("testuser");
}
@Test
void 存在しないユーザー名で検索すると空が返る() {
// Act
Optional<User> found = userRepository.findByUsername("nonexistent");
// Assert
assertThat(found).isEmpty();
}
}
- テストを実行して失敗を確認
# AIが自動的に実行
./gradlew test --tests UserRepositoryTest
# 結果:FAILED(User.javaやUserRepository.javaがまだ存在しないため)
- 実装を生成(Green phase)
User.java:
package com.example.demo.entity;
import jakarta.persistence.*;
import lombok.Data;
@Entity
@Table(name = "users")
@Data
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, unique = true, length = 50)
private String username;
@Column(nullable = false)
private String password;
@Column(length = 100)
private String email;
}
UserRepository.java:
package com.example.demo.repository;
import com.example.demo.entity.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import java.util.Optional;
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
Optional<User> findByUsername(String username);
}
- テストを実行して成功を確認
./gradlew test --tests UserRepositoryTest
# 結果:PASSED
- リファクタリング(Refactor phase)
テストが通った状態で、コードを改善します。AIが以下のようなリファクタリングを実行します。
- 変数名・メソッド名の改善
- 重複コードの削除
- 可読性の向上
テストが通り続けることを確認しながら、安全にコードを改善します。
TDDサイクルの反復ポイント
#Red → Green → Refactor のサイクル:
-
Red(失敗するテストを書く)
- 期待する振る舞いをテストで表現
- 実装がないため、テストは失敗する
-
Green(テストが通る最小限の実装)
- テストを通過させるコードを書く
- この段階では「美しさ」より「動作」を優先
-
Refactor(リファクタリング)
- テストが通った状態で、コードを改善
- 重複を削除、可読性を向上
実践③:デプロイ - 自然言語だけでAWS構築
#前提条件
#- AWS CLIがインストール済み(DevContainerに含まれる)
- AWSプロファイル(認証情報)が設定済み
- EC2を起動する権限があるIAMユーザー/ロール
今回のデプロイはテスト用途のため、以下は簡略化しています。
- HTTPSではなくHTTP
- 単一EC2インスタンス
- ロードバランサーなし
- データベースはコンテナ内
ステップ1:EC2インスタンスの作成
#プロンプト例:
Amazon Linux 2023、t3.smallでEC2インスタンスを作成してください。
セキュリティグループは、22番ポート(SSH)と3000番ポート(アプリ)を
自分のIPアドレスからのみ許可してください。
キーペアは "aidd-demo-key" という名前で作成してください。
AIの動作例:
AIが以下を自動実行します。
- 現在のIPアドレスを取得
- セキュリティグループを作成(SSH: 22、App: 3000)
- キーペアを作成
- EC2インスタンスを起動
- インスタンスIDとパブリックIPを出力
ステップ2:DockerとDocker Composeのインストール
#プロンプト例:
EC2インスタンス((パブリックIP))にSSHで接続し、
Docker と Docker Compose をインストールしてください。
ユーザーをdockerグループに追加し、再ログインせずに使えるようにしてください。
AIの動作例:
AIが以下を自動実行します。
- EC2インスタンスにSSH接続
- システムパッケージを更新
- Dockerをインストール・起動・自動起動設定
- ユーザーをdockerグループに追加
- Docker Composeをインストール
- インストール完了を確認
ステップ3:アプリ一式をEC2へ転送
#プロンプト例:
カレントディレクトリのdocker-compose.ymlと、
backend、frontend、dbディレクトリを、
EC2インスタンス((パブリックIP))の /home/ec2-user/aidd-demo へ転送してください。
AIの動作例:
AIが以下を自動実行します。
- EC2インスタンス上に転送先ディレクトリを作成
- docker-compose.yml、backend、frontend、dbディレクトリをSCPで転送
ステップ4:Docker Composeでアプリ起動
#プロンプト例:
EC2インスタンスで、転送したディレクトリに移動し、
docker compose up -d を実行してください。
全コンテナが Up(healthy) で起動していることを確認してください。
AIの動作例:
AIが以下を自動実行します。
- EC2インスタンスにSSH接続
- 転送したディレクトリに移動
docker compose up -dでコンテナを起動- 全コンテナのステータスを確認し、Up (healthy) であることを報告
ステップ5:アプリ動作確認
#ブラウザでアクセス:
http://(パブリックIP):3000
API疎通確認:
curl http://(パブリックIP):8080/api/health
# 出力例:
# {"status":"UP"}
ログイン確認:
ブラウザでログイン画面にアクセスし、以下のテストユーザー情報でログインします。
- ID: test@example.com
- PW: aiddTest
ログイン後TOP画面が表示され、そのリンクから社員検索システムに遷移します。
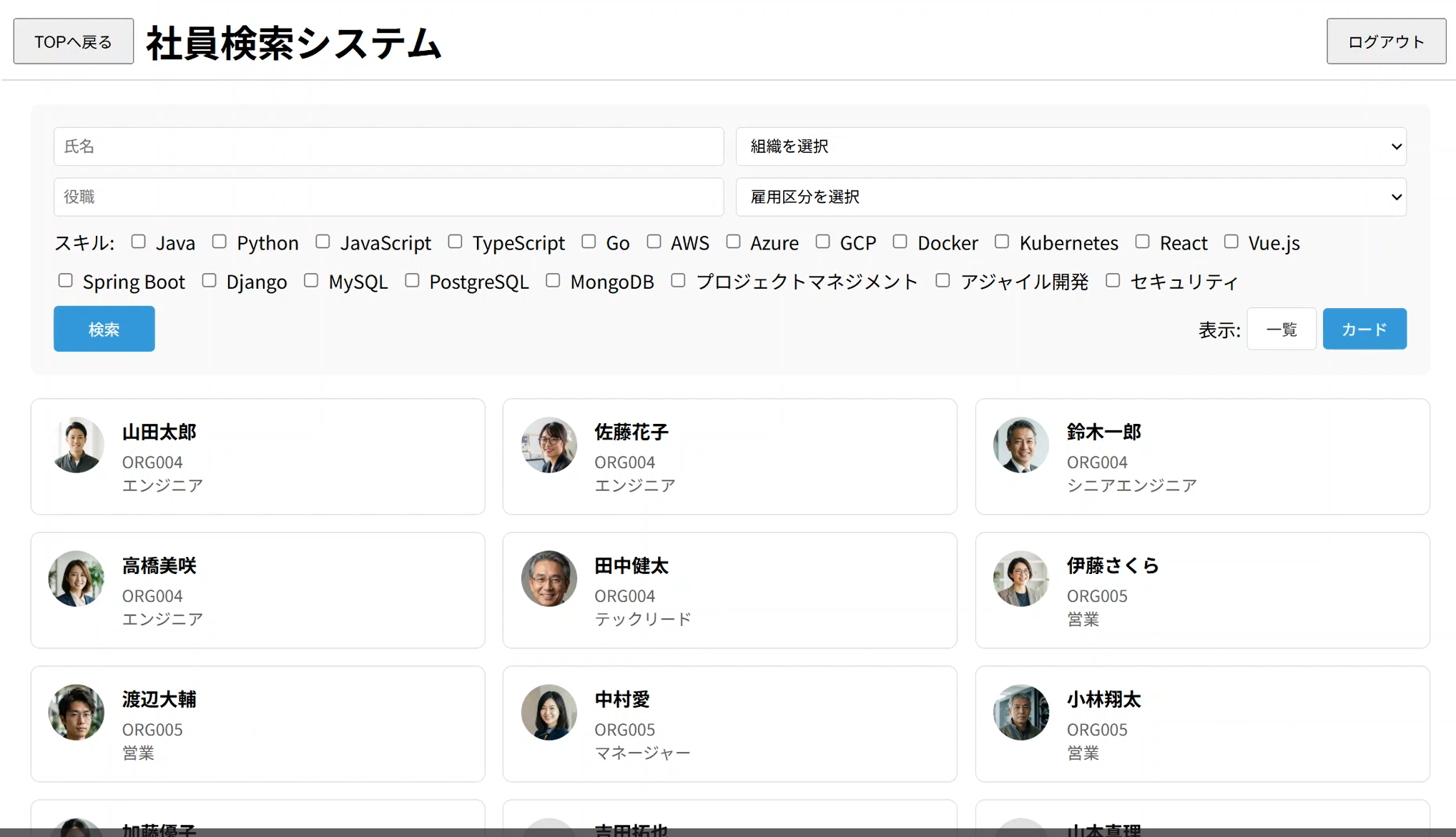
※登録データおよび顔写真はすべてAI生成によるものです。
CORS問題の修正(必要に応じて)
#もしCORSエラーが発生した場合は以下を実行します。
プロンプト例:
バックエンドのCORS設定を修正してください。
フロントエンドのオリジン(http://(パブリックIP):3000)からのリクエストを許可してください。
修正後、EC2上でアプリを再起動してください。
まとめと参考資料
#本記事のポイント
#本記事では、Amazon Q Developer × Spec Kitを使ったAI駆動開発の全工程を解説しました。
環境構築:
- GitHubリポジトリのクローンだけで開始可能
- DevContainerで依存関係を自動解決
仕様策定:
- specify → clarify の反復で仕様を精緻化
- 曖昧さを排除することがAI活用の鍵
実装:
- TDDサイクル(Red → Green → Refactor)の実践
- テストファーストの原則でAIの生成精度が向上
デプロイ:
- 自然言語でAWSリソースを構築
重要な学び
#- 人間の役割は不可欠:上流工程と品質確保は現段階では人間が担う
- 仕様とテストが資産:高品質な成果物は次のAI駆動開発で再利用可能
Amazon Web Services. Amazon Q Developer. ↩︎
Xu et al. AI-assisted Programming and Maintenance Burden. arXiv, 2025. ↩︎
Amasanti & Jahić. The Impact of Generative AI-Generated Solutions on Software Maintainability. arXiv, 2025. ↩︎
GitHub. Spec-driven development with AI: Get started with a new open source toolkit. 2024. ↩︎
Mathews et al. Test-Driven Development for Code Generation. arXiv, 2024. ↩︎
Chen et al. TENET: Leveraging Tests Beyond Validation for Code Generation. arXiv, 2025. ↩︎
Classmethod. Amazon Q Developer Pro をメンバーアカウントでサブスクライブ利用してみた. 2024. ↩︎
Ahanoff. Amazon Q Developer を使用した Spec Kit:発見事項と癖. 2024. ↩︎