LangMemの長期記憶をPostgreSQL(pgvector)に永続化する
Back to Top前回はこちらの記事で、AIの長期記憶を効率的に管理するLangMemの概要と使い方を説明しました。
この記事では、長期記憶としてインメモリストアを使用しましたが、LangMemではPostgreSQL(pgvector拡張)ベースのストアも利用可能です。
今回は、このPostgreSQLベースのストアを使い、より実践的な長期記憶の活用を試してみます。
ここでは、利用するPostgreSQLとしてゼロスケール可能なAurora Serverless v2で試してみたいと思います。
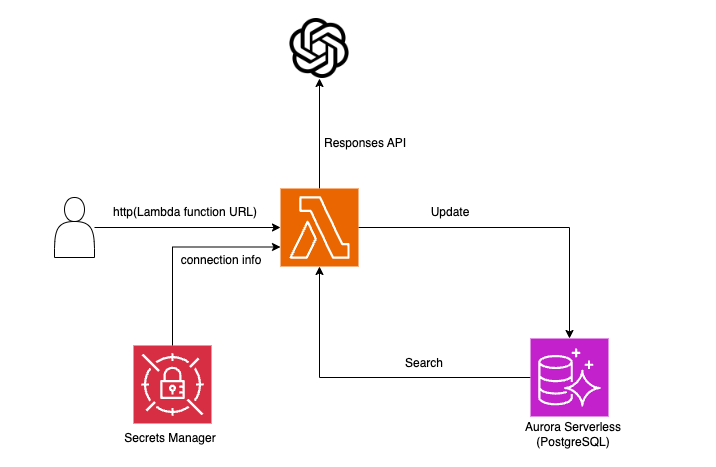
Lambda関数上のLangMemがOpenAIのResponses APIにアクセスし、ユーザーの嗜好をAurora ServerlessのPostgreSQLに長期記憶として保存します。後続のやり取りでは、この保存された情報を活用します。
極力シンプルな構成にするため、接続プール(RDS Proxy)やAPI Gateway等の関連リソースは使用しません。
セットアップ
#LangMemの永続化機能を担うLangGraphのBaseStoreには、以下のPostgreSQL向けの実装を使用します。
このPostgreStoreはデフォルトでは含まれていません。
LangMemと合わせてlanggraph-checkpoint-postgresを別途インストールします。
pip install langmem langgraph-checkpoint-postgres psycopg[binary]
今回の検証では、LangMemのバージョンは現時点で最新の0.0.15を使用しています。
Lambda関数
#早速Lambda関数の実装を進めます。全体のソースコードはこちらです。
まずはLambdaの初期化部分です。
長期記憶に保存するデータのスキーマをPydanticのクラスで定義します。
class UserTechInterest(BaseModel):
"""ユーザーの技術に関する関心情報"""
topic: str = Field(..., description="技術トピック(例:プログラミング言語、クラウドサービスなど)")
category: str | None = Field(
None, description="技術の分野(例:フロントエンド、バックエンド、ネットワークなど)"
)
interest_level: conint(ge=0, le=100) | None = Field(
None, description="関心度(0~100のスコアで表現)"
)
description: str | None = Field(
None, description="その他の補足説明(具体例や詳細な知識など)"
)
ユーザーの技術的な嗜好をスキーマ化し、長期記憶として保存します。
続いてPostgreSQLの接続URLを作成します。
def create_conn_url():
secret_name = os.environ['SECRET_NAME']
session = boto3.session.Session()
sm_client = session.client(service_name='secretsmanager')
get_secret_value_response = sm_client.get_secret_value(SecretId=secret_name)
secret = json.loads(get_secret_value_response['SecretString'])
return f"postgresql://{secret["username"]}:{secret["password"]}@{secret["host"]}:{secret["port"]}/{secret["dbname"]}"
postgres_conn_url = create_conn_url()
定石通り、DB接続情報はSecrets Managerから取得して生成します。
続いて、LangMemのStore Managerやユーザーとやり取りすることになるOpenAIクライアントを初期化しておきます。
# LangMemのStore Manager
manager = create_memory_store_manager(
"openai:gpt-4o-2024-11-20",
namespace=("chat", "{user_id}"),
schemas=[UserTechInterest],
instructions="ユーザーの興味や技術的背景を詳細に抽出してください",
enable_inserts=True,
enable_deletes=False,
)
# OpenAIクライアント
client = OpenAI()
Store Managerには先ほどのPydanticのスキーマ(UserTechInterest)を設定して、長期記憶のスキーマを強制します。
Store ManagerはLangMemのStorage APIの1つです。
LLMを活用して長期記憶の抽出や既存情報の更新を行い、LangGraphの永続化機能を通して実ストレージに反映します。
詳細は前回記事をご参照ください。
続いて、Lambdaのイベントハンドラを実装します。
まずは、PostgreSQLへの接続を確立します。
def lambda_handler(event, context):
# 1. LangGraphのPostgreStoreを作成
with PostgresStore.from_conn_string(postgres_conn_url, index={
"dims": 1536,
"embed": "openai:text-embedding-3-small",
}) as store:
# 2. PostgerSQLのスキーママイグレーション
store.setup()
まずPostgreSQLへの接続を確立するため、PostgresStore.from_conn_string を使ってコンテキストマネージャを生成しています。
これにより、接続の確保と終了処理が自動的に管理されます。
また、データの次元数 (dims=1536) や、使用する埋め込みモデル (openai:text-embedding-3-small) を設定しています。
接続が確立された後、store.setup() により、データベース内に必要なテーブルが作成されます。
次に、LangGraphのFunctional APIを使用してワークフローを定義します。
# 3. LangGraph Functional APIのワークフロー
@entrypoint(store=store)
def app(params: dict):
message = params["message"]
user_id = params["user_id"]
# ストアから関連する長期記憶を検索
memories = store.search(("chat", user_id))
developer_msg = ("You are a helpful assistant.\n"
f"## Memories\n <memories>\n{memories}\n</memories> ")
# OpenAIのResponses API実行
response = client.responses.create(
model="gpt-4o-2024-11-20",
input=[{"role": "developer", "content": developer_msg}, message],
tools=[{"type": "web_search_preview"}],
)
# 該当ユーザーの嗜好を抽出して長期記憶を更新
manager.invoke(
{"messages": [message]},
config={"configurable": {"user_id": user_id}}
)
return response.output_text
ここでの流れは次のとおりです。
- PostgreSQLからユーザーの長期記憶を検索
- 取得した情報を、OpenAIのResponses APIのコンテキストに反映
- OpenAIのAPIを呼び出し適切な応答を生成
- ユーザーの嗜好をLangMemのStore Managerを通して長期記憶を更新
- OpenAIのAPIで生成されたテキストを返す
以下は残りのソースコードです。
body = json.loads(event["body"])
user_id = body["user_id"]
# LangGraphワークフロー起動
output = app.invoke({
"message": {
"role": "user",
"content": body["prompt"]
},
"user_id": user_id
})
# レスポンス返却
return {
"statusCode": 200,
"headers": {"Content-Type": "plain/text"},
"body": output
}
HTTPリクエストからユーザーIDとプロンプトを取得し、先ほど定義したLangGraphのワークフローを起動します。
最後に、ワークフローから生成されたテキストを結果として返します。
AWSリソースを作成する
#ここで、Aurora ServerlessやLambda関数等のAWSリソースを作成します。
今回はIaCツールとしてAWS CDKを使用しました。
本記事の主題はPostgreSQLを使用したLangMemの長期記憶の永続化であり、AWSリソースの詳細な構築手順は割愛します。
ここでは、Aurora Serverless と Lambda に関する部分のみ抜粋して紹介します。
全体のソースコードはこちらです。
# Create Aurora Serverless v2 Cluster
dbname = "memory"
cluster = rds.DatabaseCluster(
self, "AuroraCluster",
engine=rds.DatabaseClusterEngine.aurora_postgres(
version=rds.AuroraPostgresEngineVersion.VER_16_6
),
writer=rds.ClusterInstance.serverless_v2("writer"),
readers=[
rds.ClusterInstance.serverless_v2(
"reader1", scale_with_writer=True),
],
vpc=vpc,
serverless_v2_min_capacity=0, # ゼロスケール
serverless_v2_max_capacity=1,
vpc_subnets=ec2.SubnetSelection(
subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS
),
# Secrets Managerのリソース作成(RDS統合)
credentials=rds.Credentials.from_generated_secret(
username="langmem"),
security_groups=[aurora_sg],
default_database_name=dbname,
enable_data_api=True
)
シンプルなゼロスケール対応のAurora Serverless(v2)クラスターです。
Secrets ManagerのRDS統合を利用して、リソース作成時に接続情報のエントリも作成しています。
Lambda関数は以下です。
lambda_role = iam.Role(
self, "LambdaExecutionRole",
assumed_by=iam.ServicePrincipal("lambda.amazonaws.com"),
inline_policies={
"SecretsManagerAccessPolicy": iam.PolicyDocument(
statements=[
iam.PolicyStatement(
actions=["secretsmanager:GetSecretValue"],
resources=[cluster.secret.secret_arn]
)
]
)
},
managed_policies=[
iam.ManagedPolicy.from_aws_managed_policy_name(
"service-role/AWSLambdaBasicExecutionRole"),
# for VPC attached Lambda
iam.ManagedPolicy.from_aws_managed_policy_name(
"service-role/AWSLambdaVPCAccessExecutionRole"),
]
)
lambda_function = _lambda.Function(
self, "LongTermMemHandler",
function_name="LongTermMemHandler",
runtime=_lambda.Runtime.PYTHON_3_12,
code=_lambda.Code.from_asset(
"path/to/deployment_package.zip"),
handler="lambda_function.lambda_handler",
security_groups=[lambda_sg],
vpc=vpc,
timeout=Duration.seconds(180),
memory_size=1024,
environment={
"SECRET_NAME": cluster.secret.secret_name,
"OPENAI_API_KEY": os.environ["OPENAI_API_KEY"],
},
role=lambda_role
)
lambda_url = lambda_function.add_function_url(
auth_type=_lambda.FunctionUrlAuthType.NONE
)
CfnOutput(self, "LongTermMemFunctionUrl", value=lambda_url.url)
AuroraはVPCリソースなので、そこにアクセスするLambdaもVPCにアタッチしています。
また、OpenAIのAPIやPostgreSQLへの接続[1]をするので、タイムアウトは少し長めにする必要があります。
メモリサイズもデフォルトだとメモリ不足でエラーになったので調整しました。
Auroraベースの長期記憶を検証する
#これで、検証環境が整いました。
ここではcurlを使って、生成されたLambda関数のURLから、Aurora Serverlessへの長期記憶の保存・活用を検証します。
まず、以下のリクエストを送信し、ユーザーの関心情報を保存します。
LAMBDA_URL=$(aws lambda get-function-url-config --function-name LongTermMemHandler --query FunctionUrl --output text)
> https://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.lambda-url.ap-northeast-1.on.aws/
curl -H 'Content-Type: application/json' "$LAMBDA_URL" -d @- <<'EOF'
{
"user_id": "MZ0001",
"prompt": "クラウドサービス全般に興味があり、特にAWS、Azureの基本的な知識を徐々に深めていきたいと思っています"
}
EOF
このリクエストを送ると、AIが適切なレスポンスを生成し、それに基づいてユーザーの興味を長期記憶として保存します。
レスポンスの内容自体は省略しますが、内部的にはこの情報がAurora Serverlessに蓄積されていきます。
次に、さらに新しい関心情報を追加してみます。
curl -H 'Content-Type: application/json' "$LAMBDA_URL" -d @- <<'EOF'
{
"user_id": "MZ0001",
"prompt": "新しく気になる技術として、AIエージェントを活用した取り組みにも強い興味を持つようになりました"
}
EOF
ここで、AWS マネジメントコンソールの RDS Query Editor を使い、Aurora Serverless内のデータを確認してみます。
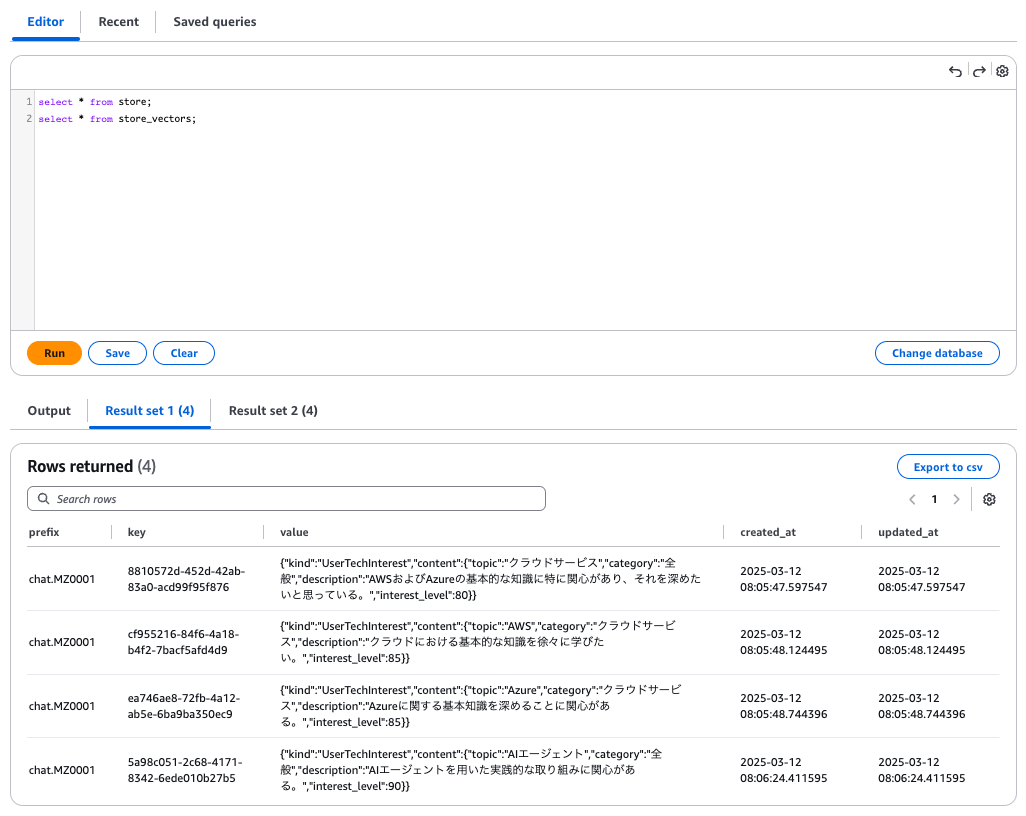
LangMemの長期記憶は store テーブルに生データが、store_vectors テーブルにベクトル化された情報が格納されます。
storeテーブル
store_vectorsテーブル
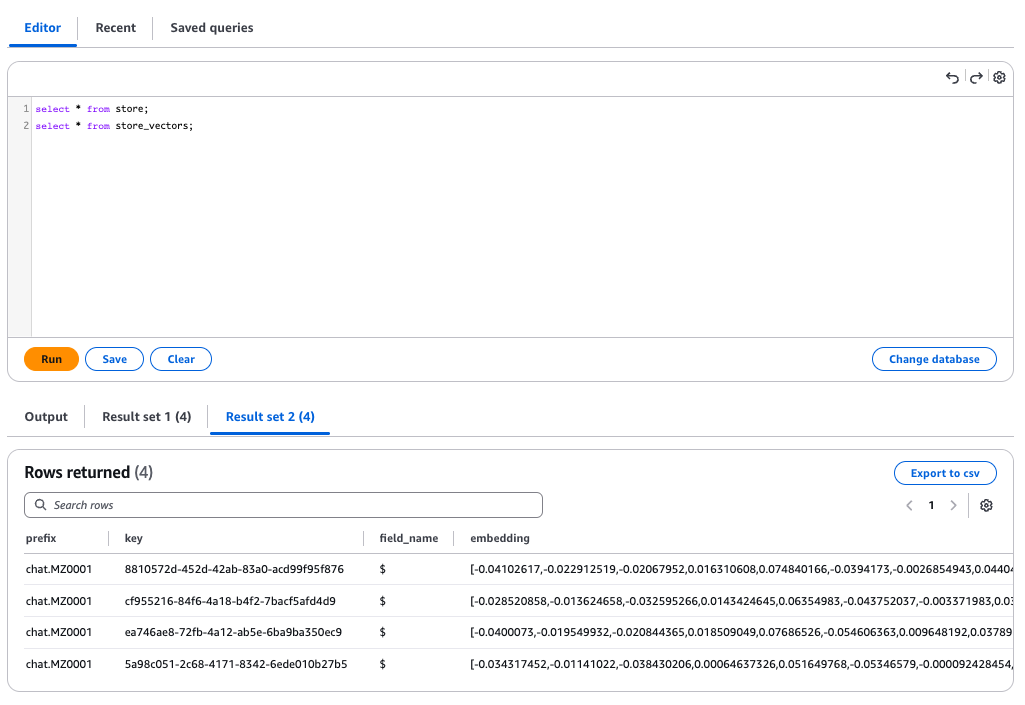
PostgreSQLにユーザーの関心情報が適切に格納されていることが確認できました。
次に、登録された情報を基に、長期記憶を活用した応答ができるか確認します。
ユーザーの過去の発言を与えずに、一般的な技術トピックを尋ねてみます。
curl -H 'Content-Type: application/json' "$LAMBDA_URL" -d @- <<'EOF'
{
"user_id": "MZ0001",
"prompt": "おすすめの技術トピックを3つ挙げて簡潔にまとめて!"
}
EOF
以下のレスポンスが返ってきました。
以下の3つの技術トピックをおすすめします!興味の深さや関連性に基づいて選びました。
1. **AIエージェント**
- 実践的な活用方法や開発手法を学び、日常業務の効率化や革新的な課題解決に応用可能。
特に最新のAIツールやAPI利用は注目です。
2. **Azure (クラウドサービス)**
- Microsoft Azureの基本知識を習得し、クラウド上でのアプリケーション開発や運用スキルを強化。
特にAIやデータ解析と連携するサービスはおすすめポイント。
3. **AWS (クラウドサービス)**
- Amazonのクラウドソリューションに触れて、幅広い基礎技術を学べます。
特に、サーバーレスアーキテクチャやデータストレージを効率化するノウハウを重点的に取り組むのがおすすめです。
これらは学習と実務の両面で役立つトピックです!
ユーザーの関心情報を反映しつつ、適切な技術トピックを提案する応答が生成されました。
長期記憶を持たない新規ユーザー(user_idを変更)で、同じプロンプトを送信してみると、一般的な技術トピックが提案されました。
### 1. **生成AI(Generative AI)**
- テキスト、画像、音楽などを生成するAI技術が急速に進化中。
- 特にChatGPTやStable Diffusionのようなモデルが注目され、クリエイティブ分野や効率化に活用される。
- 技術の進展は、業務自動化からエンタメまで幅広い影響を持つ。
### 2. **量子コンピューティング**
- 現在の計算機では困難な問題を高速に解ける次世代技術。
- 暗号解読、分子シミュレーション、金融最適化など、特定分野での大革命を期待される。
- 専門的知識が必要な一方、基礎研究から応用例が増えつつある。
### 3. **Web3およびブロックチェーン**
- 非中央集権のインターネットを目指す技術。暗号資産やスマートコントラクトが中心。
- 金融(DeFi)やデジタル資産(NFT)の分野での活用が進む一方、規制や環境負荷の課題も議論されている。
- 新しい経済圏や所有権の概念を形成している。
長期記憶を持つユーザーと持たないユーザーで、異なる応答が生成されることが確認できました。
まとめ
#今回、LangMemの長期記憶をインメモリではなく、実運用で推奨される PostgreSQL(pgvector)を用いて検証しました。
Aurora Serverlessのセットアップには少し手間がかかりましたが、実環境での長期記憶の運用イメージが実感できました。
この仕組みを活用すれば、ユーザーごとの知識や嗜好を蓄積し、よりパーソナライズされたAIシステムを構築できそうです。
これを利用して、いろんなアイデアにチャレンジしてみたいなと思います。
ゼロスケールしている場合はPostgreSQLの接続に10秒以上かかります。 ↩︎