Raspberry Pi5 で挑戦!YOLOv8を使った生物の個体識別
Back to Topこの記事は夏のリレー連載2024 10日目の記事です。
Raspberry Pi5 で生物の個体識別にチャレンジしてみましたので、簡単に報告します。
Raspberry Pi5 や個体識別について簡単におさらいした後、YOLOv8 を使った自動アノテーションを紹介します。
YOLOv8 をCUDA が動く PC で追加学習し、そのパラメータをRaspberry Pi5 にダウンロードして識別可能か試します。
Raspberry Pi 5 とは
#RaspberryPi.com が2023/10/23 に発売した SBC (Single Board Computer) です(日本の技適通過は2024/1/11)。
ラップトップPCと比べると非力ですが、価格が安く、たばこの箱以下の小さい筐体に全部入りなので、世界中で大人気となっています。
OS は独自の Raspberry Pi OS の他、Ubuntu など、Linux の他のディストリビューションも搭載できるようになっています。
公式サイトで専用書き込みツールが提供されるようになり、SD カード書き込みがより便利になりました。
Raspberry Pi5 は25W 必要なのが難点ですが、MIPI インタフェースでカメラを接続可能など、アウトドア用途にも魅力が大きい製品です。
個体識別とは
#物体認識は例えばトラックであれば、どんな形状でもトラックと思われる物体を「トラック」として認識させることを目的としています。
一方、個体識別はトラックと認識した上で、「トラックA」なのか、「トラックB」なのかを認識させます。
トラックのような工業製品は個体差が分かりづらいですが、鳥などの生物は個体固有の形状・色彩をしていることがあり、これを画像から識別できれば個体や群体の移動が計測しやすくなるのではないかと考えました。
顔認識等では特徴量を抽出して計測するようですが、この稿ではマガモの個体画像をニューラルネットに追加学習することで個体識別が出来ないか模索します[1]。
過学習の危険もありますが、個体識別にニューラルネットでどこまで迫れるのか興味がわきます。
YOLOv8 とは
#YOLOv5 を開発したUltralytics 社 が開発した高速なニューラルネットキットです。
YOLO シリーズの特徴として、画像のどこに何があるかを判定する機能がありますが、YOLOv8 はそれだけでなく、以下の機能も持っています。
- 画像分類
- 静止画からの物体検出
- 動画からの物体検出と追跡
- ポーズ推定
もっとも小さなモデル(yolov8n)のパラメータ数は320万程度となっています。
Raspberry Pi5 で何も工夫せずに動作させると500~600 msec 要しますが、ひとまず検出できることを目指します。
学習編(on GeForce RTX 4090 PC)
#学習は識別に比べ、大きなCPU/GPU パワーを必要とします。YOLOv8の最小モデルの学習には4GB以上のVRAMが搭載されたGPUを必要とします。
そのため、手持ちの GeForce RTX 4090 PC を Ubuntu 22.04.4 LTS 上で使用することにしました[2][3][4][5]。
ニューラルネットの学習時の問題点
#通常、分類問題をニューラルネットに学習させるには、教師あり学習すると思います。
しかし、 教師あり学習だと、人間がアノテーションをしなければならず、用意するのが大変です。
そこで、自動的にアノテーションを行う方法を模索しました。
自動アノテーション
#ネットを漂っていたところ、Meta 社の SAM (Segment Anything Model) というものが目に留まりした。
動画を基本としていて、最初のフレームで対象を指定すると、ビデオが進んだ時、自動的にセグメンテーションも移動してくれるというものです。
最終的には SAM は利用しませんでしたが、ビデオから教師データを作成するという貴重なヒントが得られました。
YOLOv8 自体で自動アノテーションを行う
#YOLOv8 には bird という分類があり、マガモを見せるとbird に分類されます(当たり前ですが)。
そこで、bird に分類されるオブジェクトとその周辺を追加学習対象とすればよいと考えました。
ビデオからの自動アノテーション
#元データとしてビデオを探さなければなりませんが、ひとまずPixabay から2つのマガモの動画[6][7]をダウンロードして追加学習を行うことにしました。
また、学習結果が汎化されているか検証するため別動画もダウンロードしておきます。
追加学習
#少数画像からの学習
#YOLOv8 はどのくらいの枚数を用意すれば追加学習が可能なのか探ります。
ビデオ自体は20秒程度なので、OpenCV で動画を静止画にスライスし、学習:検証:テスト=6:2:2 くらいに分割してJPEG 化します[8]。
通常は更に拡大・縮小、回転、アフィン変換しますが、少数の画像でどこまで行けるか試したかったので、ビデオの出力をそのまま使用することにしました。学習用の入力画像枚数は、387×2=774枚となりました。
また、epochs[9] はデフォルト100ですが、50以上にしても検出に改善が見られなかったので、epochs=50 としました。
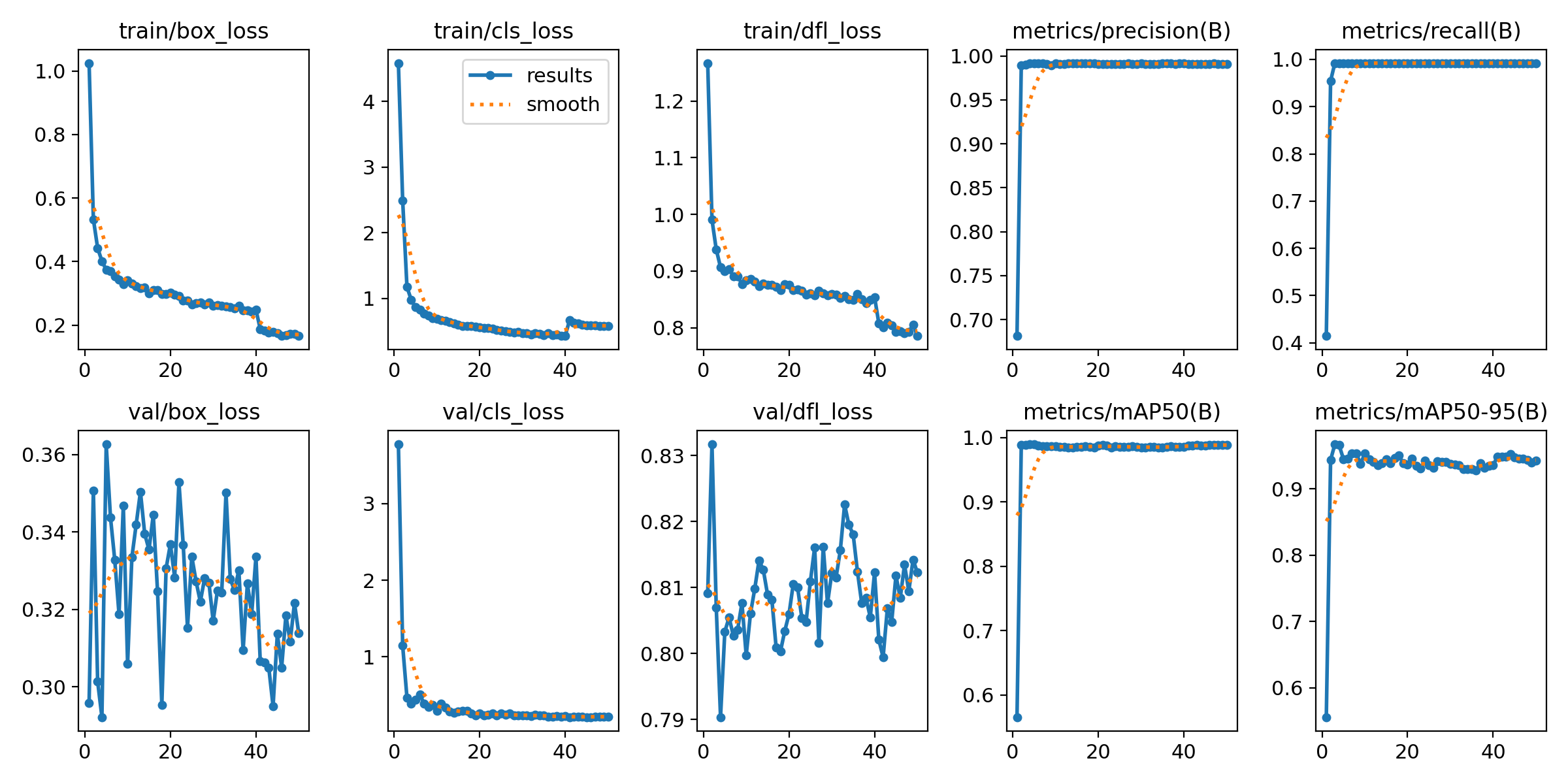
個体学習結果
#図に2匹のマガモに対する学習結果を示します。 学習は順調に進みました。
識別編 (on Raspberry Pi5)
#個体識別の実施
#テスト画像に対する識別結果を示します。画像の大きさは640 x 360 です。
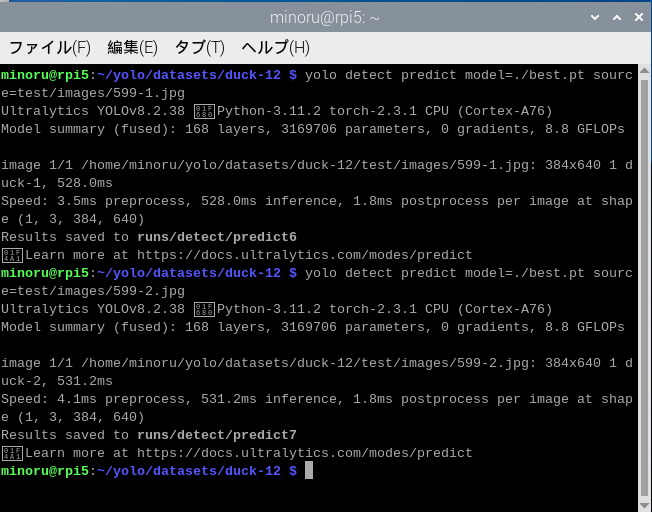


当然かもしれませんが、テスト用に分離したJPEG 画像は正しく分類しています。
しかし、検証画像を認識させると迷ってしまいました。


検証画像では二羽の鳥が映っていますが、一羽と誤検出しています。
PyTorch ベースではINT8の検証ができませんが、yolo コマンドはTensorFlow Lite(TFLite) のフロントエンドとして利用できます。
ニューラルネットパラメータをTFLite にエクスポートするAPI が用意されているので、TFLite でも計測してみました。
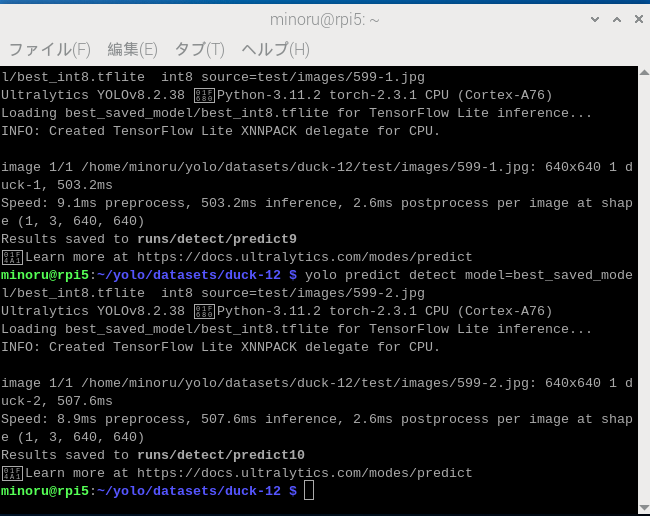
結果は識別処理が30 msec ほど速くなりました。
今後の展望
#RPi5 用13TOPS イスラエル製AI Board がアナウンスされています。人気が高くてなかなか購入が出来ませんが、機会があれば試してみたいと思います。
今回の実験ではあまりいい成果は出せませんでしたが、マガモ個体に「特徴的な」パターンがあれば特徴量を検出することで精度を向上できる可能性があります。
別の生物でも試してみたいと考えています。
マガモを使ったのは後述するYOLOv8にbird分類が存在するのと、無料ロイヤリティフリー画像が豊富だったからです。 ↩︎
当初はWSLで実施しようとしましたが、F.conv2dでエラーを吐くなど謎現象が発生したため、断念しました。 ↩︎
M1 Mac Book Air でも試してみましたが、CPU モードは正しく動くものの、MPS を使うとなぜか40GBのメモリを要求して動きませんでした。 ↩︎
M3 Mac Book Air だとcounts.max() == -1 となり、計算が続行できません。 ↩︎
CUDA は12.4 を使用しましたが、PyTorch のホームページの記述とは異なり、pip3 パッケージでインストールしても問題なく稼働しました。 ↩︎
YOLOv8の学習機能は学習用画像と検証画像のみ学習に使用します。テスト画像は手動でテストするときに使います。 ↩︎
学習の繰り返し回数 ↩︎