画像AIで異常検知:事例に合わせたモデル選定と実践
Back to Top画像AIの技術は急速に進化しており、異常検知や物体検出、セグメンテーションなど、さまざまなタスクに活用されています。この記事では、異常検知に利用できるモデルの特徴と選定の指標、オープンデータで実際に異常検知用AIを学習してみた結果を記述しています。
異常検知に利用できるモデル
#画像AIで異常検知がしたい場合、学習に使用するモデルを選定する必要があります。異常検知に利用できるモデルには異常検知モデル、物体検出モデル、セグメンテーションモデル、分類モデルなどが考えられます。それぞれの特徴とメリット・デメリットをまとめます。
異常検知モデル(Anomaly Detection Models)
#特徴:主に正常データのみを使用して学習を行います。正常なパターンを学習し、それから逸脱するデータを異常として検出します。
メリット:
- 正常のパターンからの逸脱を検出するため、正常データだけで学習が可能。
- アノテーション不要ですぐに学習することができる。
- 時系列データ、画像データ、ネットワークトラフィックなど多様なデータに適用可能。
デメリット:
- 一般的に位置ずれや複雑な背景に場合に精度が下がりやすいと言われる。
物体検出モデル(Object Detection Models)
#特徴:画像内の特定の領域をバウンディングボックスで囲み、その領域の特徴を捉えます。学習するデータはバウンディングボックスでアノテーション(ラベル付け)する必要があります。
メリット:
- 異常の領域をバウンディングボックスで囲んで特定できる。
- リアルタイム検出モデルが豊富。
デメリット:
- 異常部位のアノテーション(ラベル付け)が必要。アノテーションは基本的に手動で行うため手間と時間がかかる。
セグメンテーションモデル(Segmentation Models)
#特徴:ピクセル単位でデータを分類し、異常箇所を特定します。画像データにおいて異常箇所を詳細に特定することが可能です。学習するデータは検出する物体の輪郭に沿ってアノテーションする必要があります。
メリット:
- 異常箇所をピクセルレベルで特定できるため、画像データなどで精密な異常検出が可能。
デメリット:
- ピクセル単位でのデータ分類を行うため、計算コストが高くリソースが多く必要。
- アノテーションコストが高く、学習データを用意するには手間と時間がかかる。
分類モデル(Classification Models)
#特徴:教師あり学習で正常データと異常データの両方を使用して学習します。異常を特定のクラスとして分類し、検出します。
メリット:
- 正常データと異常データがある場合、分類モデルは高精度で異常を検出可能。
- 異常の種類が複数ある場合でも、それぞれの異常を特定することが可能。
デメリット:
- 学習時に正常データと同程度の異常データが必要。
- 学習していない異常のパターンは検出しにくいため、異常データを網羅的に収集しなければならない。
モデル選定の指標
#上記で示した各モデルの特徴を踏まえたうえで、実際に異常検知に向けてモデルを選ぶ際には以下の点を考慮して選定しています。
-
SOTA(State-of-the-Art)モデルのチェック
最新の研究や実績のあるモデルを確認し、性能を比較します。 -
リアルタイム推論の必要性
リアルタイムでの異常検知が必要かどうかを判断します。リアルタイム推論が必要な場合、処理が高速なモデルが求められます。 -
モデルを学習するためのリソース
使用可能なGPUやクラウドのリソースを考慮し、事例に応じてモデルを選びます。学習時に使用できるリソースと想定している運用時のリソースの両方を確認して決めます。 -
異常の部位の判定の必要性
異常部位の特定が必要な場合、異常検知系モデルでヒートマップを使用したり、物体検出モデルでバウンディングボックスを使ったり、セグメンテーションで推論する必要があります。この場合分類モデルは適していません。
AIモデルの選定においては、以下の点も重要です。
- すぐに動かせるコードが手に入るか
モデルの実装はスクラッチで書くことはほとんどなく、既存のフレームワークやライブラリを活用することが一般的です。すぐに利用できるコードがあれば、開発コストと開発にかかる時間を削減できます。
実際に異常検知してみる
#ここまではモデルの選び方を述べてきましたが、実際にオープンデータで異常検知モデルPatchcoreと物体検出モデルRTMdetを使って学習結果を比較してみたいと思います。いずれもリアルタイム推論に適したモデルです。
使用したデータはMVTecのscrewです。
screwのデータセットには正常画像と5種類の異常画像が含まれています。
このうちgood(正常)のデータとscratch_neck(異常5種類あるうちのひとつ)を使用して実験をしてみたいと思います。
データセット作成
#MVTecのscrewデータセットはもともと位置ずれナシ、明るさ一定、背景一定のデータです。
しかしながら実際に異常検知をしたい現場ではこのような良い条件のデータが取れないことがしばしばあります。
そのため次の3つの要素に着目し、4パターンのデータセットを作成しました。
- 位置ずれ:screwが画像の真ん中に映っているか否か
- 明るさ:画像の明るさ・コントラストが一定か否か
- 背景:背景が一定か否か(一定ではない条件では背景にランダムにカラフルな四角を描画)
データセット4パターン
- 位置ずれナシ・明るさ一定・背景一定
- 位置ずれ有り・明るさ一定・背景一定
- 位置ずれナシ・明るさ変更・背景一定
- 位置ずれナシ・明るさ一定・背景変更
各データセットに含まれる画像の枚数
#異常検知モデルでは正常データのみで学習し、物体検出モデルでは異常データのみで学習することになるため
異常検知モデル用
学習:正常20枚
テスト:正常5枚、異常5枚
物体検出モデル用
学習:異常20枚(アノテーション済)
テスト:正常5枚、異常5枚
で実施しています。
学習済みモデルの評価方法
#学習したモデルはAUC(area under the curve)と再現率を1にした場合の適合率を使って比較します。
詳しい説明は割愛しますが、再現率は異常の見逃しの指標となり、再現率=1では見逃しなし、0.9では1割見逃しとなります。再現率を1に設定した際の適合率を比較することで、見逃しがない条件下でどれくらい推論が正解したかがわかります。
AUCはROC曲線の下側面積のことで、0~1の値を取り1に近いほど良いモデル、0.5ではランダムな推論と同等となる指標です。
異常検知モデル(Patchcore)の学習と評価
#テストデータは上段5枚が正常、下段5枚が異常データです。
Patchcoreでは異常の可能性が高い部分ほど暖色で示されるヒートマップが出力されます。
ヒートマップを利用して異常部位の検出も可能となりますが、今回は1画像に対する正常or異常の判定のみを精度の計算に使用します。
- 位置ずれナシ・明るさ一定・背景一定
MVTecのデータそのまま使用しています。学習データ20枚と少な目ですが異常部位を捉えているようです。
閾値を0.49に設定すると再現率=1になります。
このとき適合率:0.83、AUC:0.92となり、すごく良いモデルといえるのではないでしょうか。

- 位置ずれアリ・明るさ一定・背景一定
ランダムクロップ処理を行い中心部からずらしたあと、元サイズにリサイズしています。
閾値を0.40に設定すると再現率=1になります。
このとき適合率:0.83、AUC:0.88となりました。

- 位置ずれナシ・明るさ変更・背景一定
明るさとコントラストをランダムに変更しています。
閾値を0.49に設定すると再現率=1になります。
このとき適合率:1.0、AUC:1.0となり、明るさを変更したデータではむしろ元の加工していないデータを使うときよりも良い結果になりました。

- 位置ずれナシ・明るさ一定・背景変更
背景にバラエティを持たせるため、ランダムにカラフルな四角を描画したものです。
閾値を0.41にすると再現率=1になります。
このとき適合率:1.0、AUC:1.0となり、こちらも元の加工していないデータよりも良い結果が出ています。

物体検出モデル(RTMdet)の学習と評価
#テストデータは異常検知モデルの場合と同様に上段5枚が正常、下段5枚が異常データです。
RTMdetの場合、推論時には確信度スコア(0-1で1に近いほど異常)とそれに付帯するバウンディングボックスが出力されます。今回はスコアの閾値を0.5に設定しました。0.5より大きいスコアが存在する場合はそれらの最小値(異常と判定された部位の中で最も正常に近い数値)を、0.5以下の数値しかない場合はスコアの最大値(正常と判定された部位の中で最も異常に近い数値)を右上に表示しています。
Patchcoreと比較するために異常部位の正確さは求めず、1画像に対する正常or異常の判定のみを精度の計算に使用します。
- 位置ずれナシ・明るさ一定・背景一定
閾値0.5で再現率=1になります。
このとき適合率:1.0、AUC:1.0となりました。異常部位をしっかり捉えているようです。

- 位置ずれアリ・明るさ一定・背景一定
閾値0.5で再現率=1になります。
このとき適合率:1.0、AUC:1.0となりました。位置ずれはほとんど影響なしと言えます。

- 位置ずれナシ・明るさ変更・背景一定
閾値0.5で再現率=1になります。
このとき適合率:1.0、AUC:1.0となりました。明るさの変更に対してもロバストなようです。

- 位置ずれナシ・明るさ一定・背景変更
閾値0.5で再現率=1になります。
このとき適合率:1.0、AUC:1.0となりました。背景の変化もほとんど影響しないようでした。

実際にやってみたまとめ
#- 異常検知モデルは明るさや背景の変化に弱いと予想していましたがPatchcoreでは推論結果が悪くなることはありませんでした。
- 物体検出モデルは位置ずれ、明るさ、背景の変化いずれも学習結果にほとんど影響しませんでした。
- 結局、データセットを作成して学習してみないと結果がわからないということを強調する結果が得られました。
- 今回は位置ずれ、明るさ、背景それぞれの影響を見るために一つずつ変化させてみましたが、位置ずれ&明るさ変更など複数の要素が絡む場合の結果を予測するのは困難です。
- 経験的にモデルはデータで学習してみないと結果は分からない、という考えを持っていましたがまさにその通りの結果が得られたと感じます。
番外編:AWSのLookout for visionを使ってみる
#これまではオープンソースのコードを利用していましたが、AWSのLookout for visionを使うとUIをポチポチするだけで簡単に異常検知AIが構築できます。エンジニアなしでも簡単に異常検知の学習ができるということでこちらも試してみました。
同じように4種のデータセットを使用して学習しました。
Lookout for visionのテストデータセットでは正常10枚異常10枚が最低限必要なため、異常検知モデルで使用したテスト用データセットに正常5枚異常5枚を追加しています。
学習結果
#Lookout for visionではトレーニングが終わると精度とリコールとF1スコアが表示されます。
これら3つの指標を4つのデータセットそれぞれの学習結果で比較してみます。
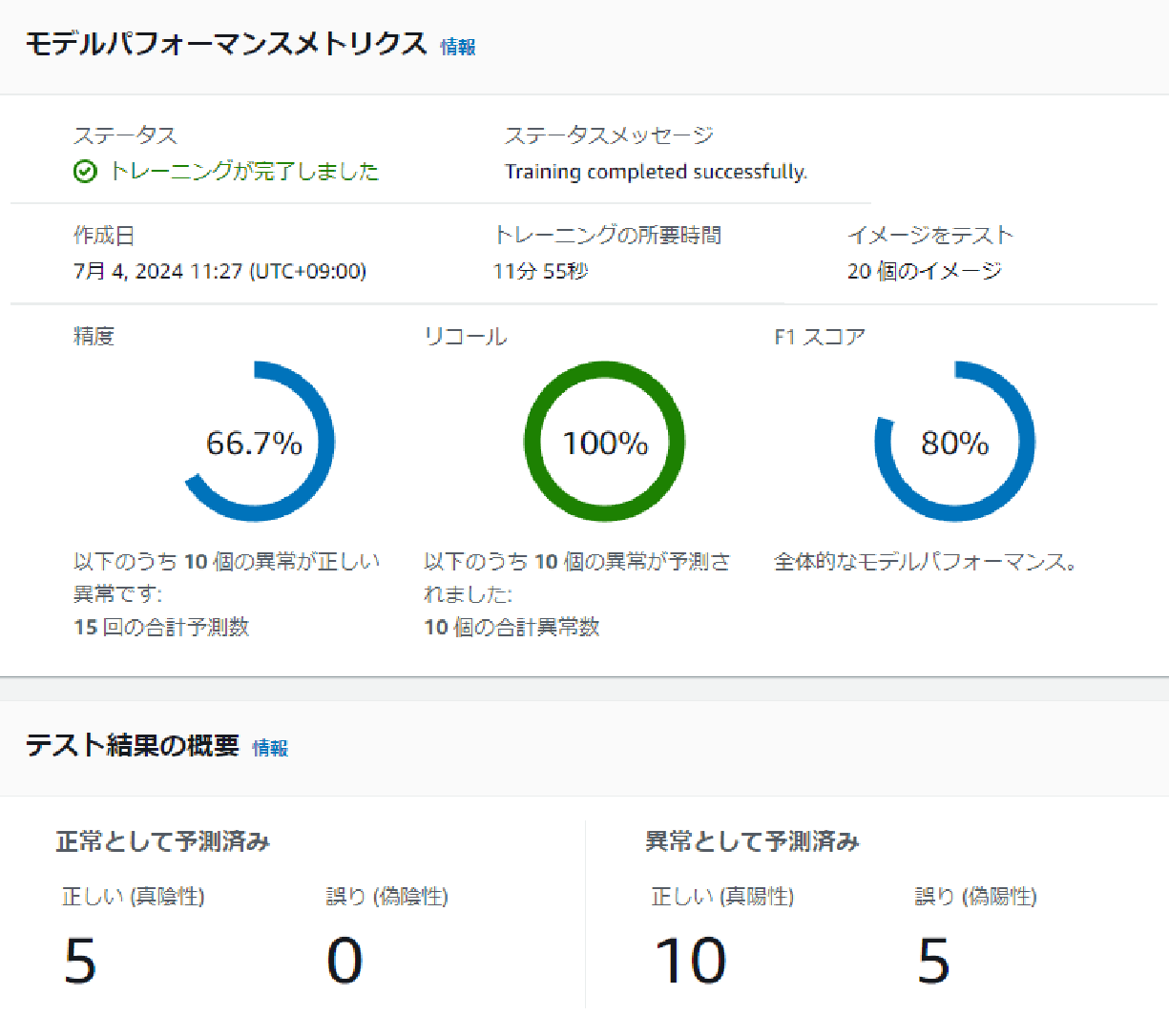
- 位置ずれナシ・明るさ一定・背景一定
まずはMVTecの元データです。閾値を手動で設定できないためF1スコアで比べるのが良いでしょうか。F1スコアは80%となりました。
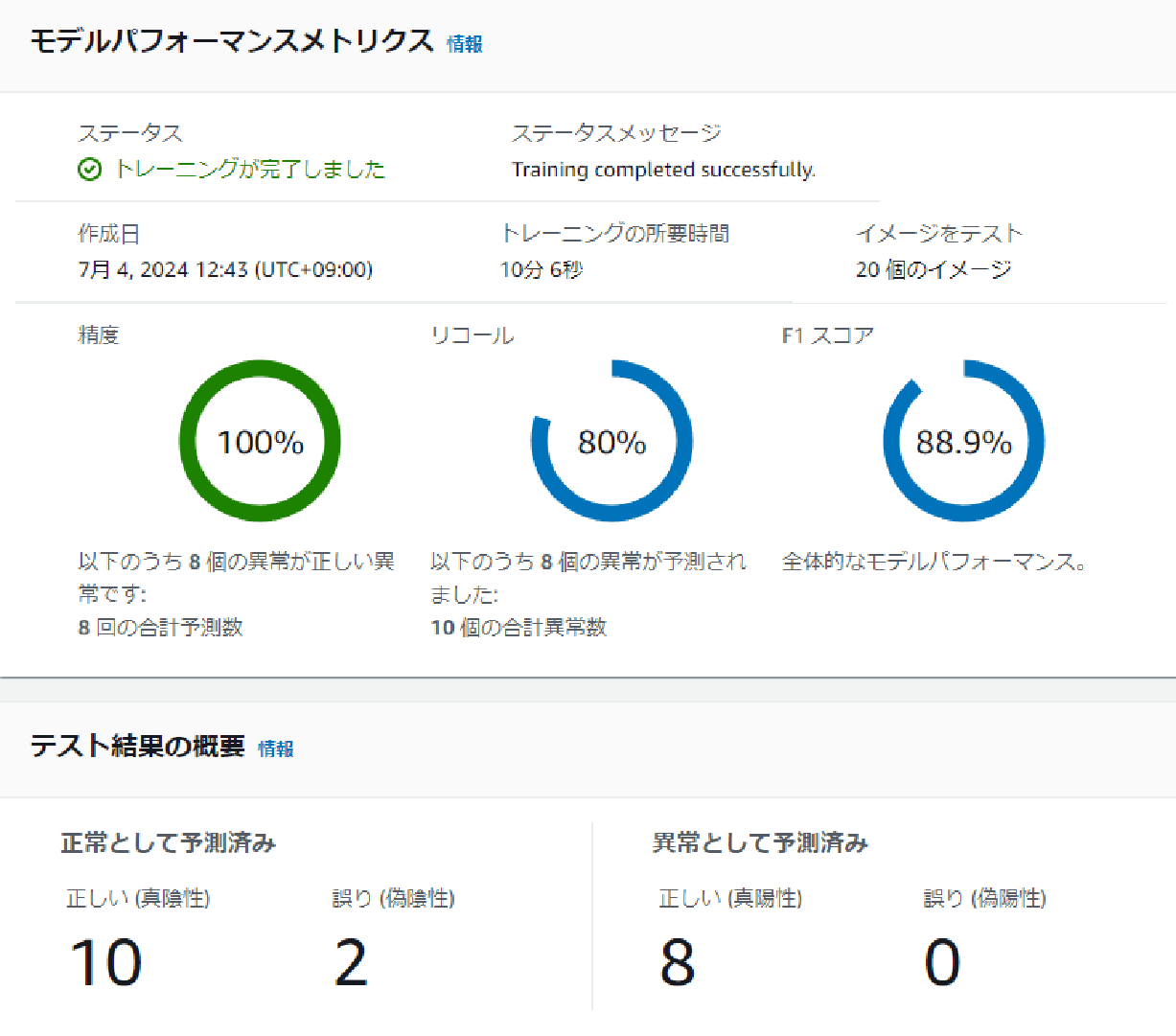
- 位置ずれアリ・明るさ一定・背景一定
位置ずれデータではF1スコア88.9%となり、元データよりも良い結果です。
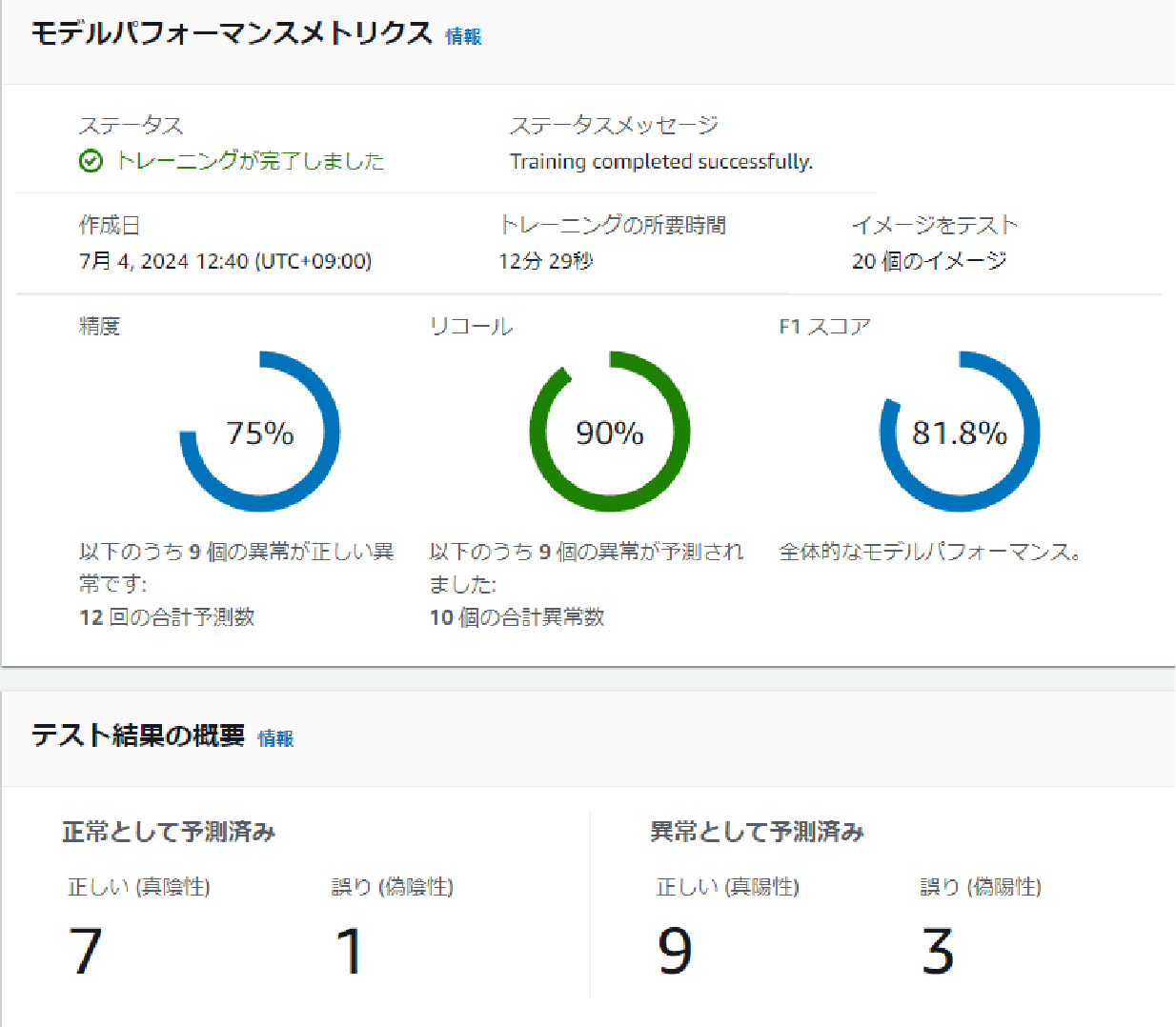
- 位置ずれナシ・明るさ変更・背景一定
明るさを変更したデータではF1スコアは81.8%となり、元データとあまり変わらない結果が出ました。
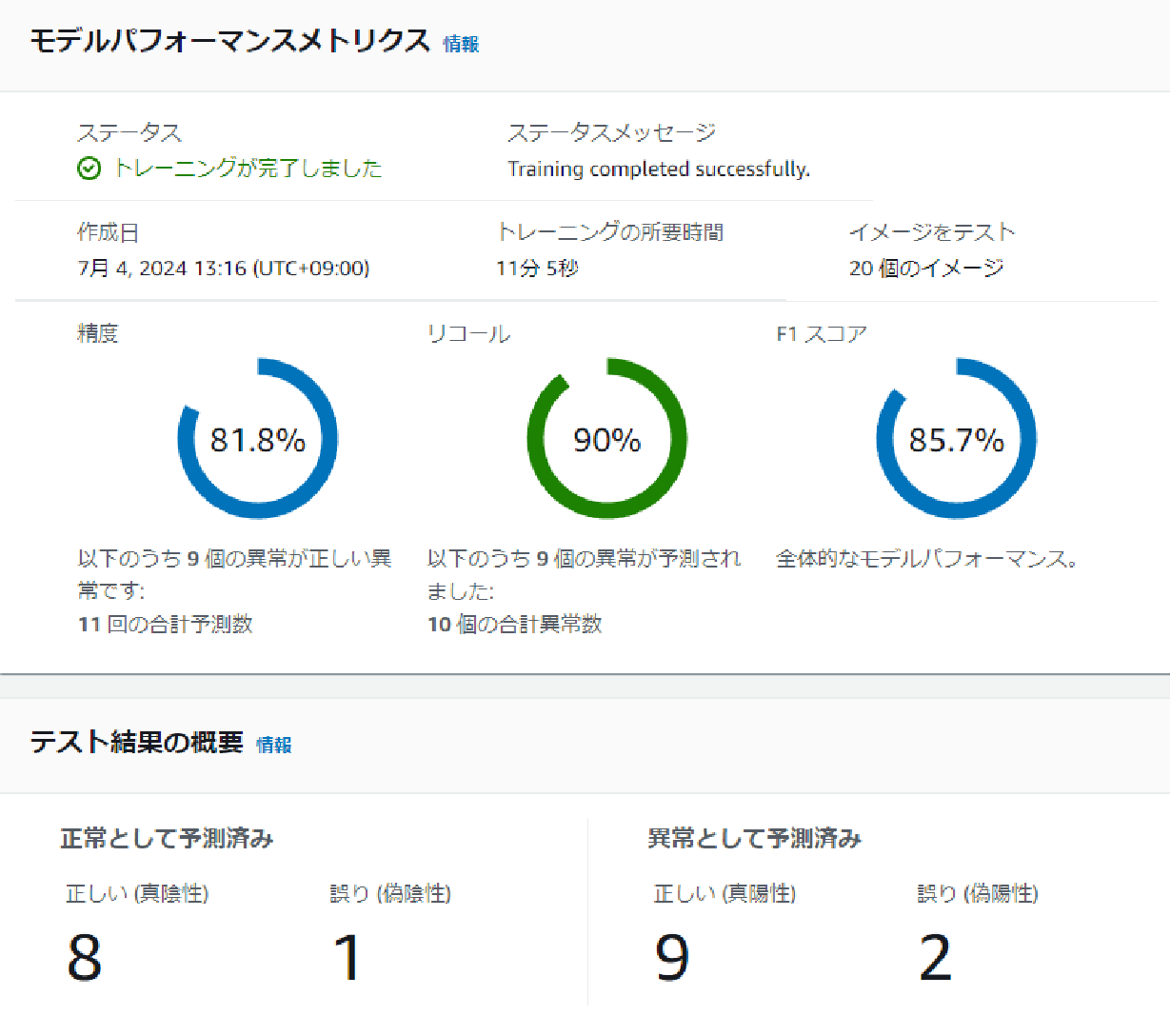
- 位置ずれナシ・明るさ一定・背景変更
背景にランダムに四角を描画したデータではF1スコアは85.7%でした。
Lookout for visionの結果まとめ
#Lookout for visionのFAQでは
例えば、照明、ズームレベル、関心領域へのフォーカス、および位置合わせが一定である場合、わずか 30 枚の画像から始めることができますが、多くのバリエーション (照明、位置合わせ、視点) を使用するより複雑なユースケースでは、何百ものトレーニング例と高品質のアノテーションが必要となる可能性があります。
と記載されており位置ずれなどに強いモデルではなさそうだと予想していました。
しかしながら、今回は位置ずれ、明るさ変更、背景変更ともに精度に大きく影響することはないという結果になりました。
再現率=1になるように閾値を設定したかったのですが、そのような機能は見つけられませんでした。またAUCも計算できる機能はついていないようです。
Lookout for visionのメリット・デメリット
#Lookout for visionを使ってみて感じたメリット・デメリットをまとめます。
メリット:
- ノーコードで簡単に異常検知ができる。
- デプロイが簡単。
デメリット:
- 閾値がデフォルトで設定されている(再現率=1になるような閾値に簡単に変えられない?)
これに関してはAWSのFAQに以下のような記載があります。
Amazon Lookout for Vision では Amazon Augmented AI (Amazon A2I) を使用できるため、Amazon Lookout for Vision から人間のレビュー担当者 (プロセスエンジニア、品質マネージャー、またはオペレーター) に信頼性の低い予測をルーティングできます。Amazon A2I が予測をレビュー担当者にルーティングする条件を、信頼スコアのしきい値またはランダムサンプリングのパーセンテージのいずれかで指定できます。これらのしきい値を調整して、精度と費用対効果の適切なバランスを実現できます。
しきい値の調整は可能なようです。 - AUCの計算機能はない。
最後に
#画像AIを用いた異常検知には、データセットに合わせた適切なモデル選定が重要です。異常検知、物体検出、セグメンテーション、分類の各モデルには、それぞれメリットとデメリットがあり、具体的なユースケースに応じて選ぶ必要があります。最終的には、データを用いて実際に学習し、結果を検証することが不可欠です。