Excelを使って簡単にオープンデータを分析する(発展編)
Back to Top前回の記事ではExcelとPowerQueryを利用して簡単にインターネット上の公開データを分析する手法を紹介しました。これでも手軽にデータを取得/分析するには十分ではあるのですが、もう少し作り込むことで簡単なデータ分析ツールとして活用できるようになります。
特にデータ取得の部分に関しては、取得したいデータのAPI仕様などに由来して痒いところに手を届かせたくなることがあります。そこで今回はPowerQueryの内容を作り込んでみます。少しだけ(GUI操作のみでなく)コーディング作業も入っていますが、なるべく理解し易いように[1]説明します。
コンピュータの処理内容などを、プログラミング言語などの「人間が理解し易い」記法ルールに則って記載したものをソースコード(またはソース、コードなど)と呼びます。この「ソースコード」を作成してコンピュータの処理内容を定義することがコーディングです。
前回のおさらい
#Excelに組み込まれているPowerQueryを利用して、Gitlabが公開しているAPIから筆者の作成したプロジェクトの一覧を取得して作成日ごとに集計[2]する例を紹介しました。
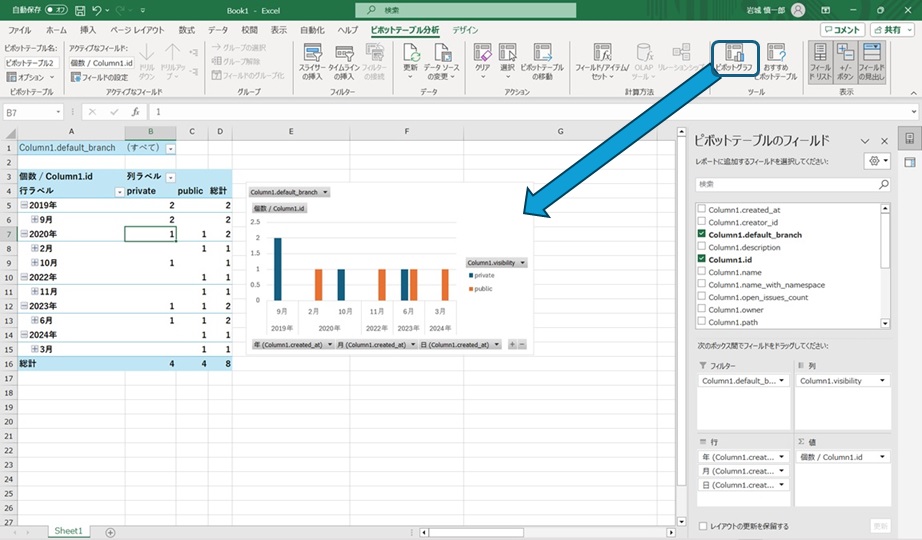
この内容であれば特にコーディングを意識することもなくGUIからの設定だけで実現できます。しかし、実際に使用することを考えると 例えば以下にあげるような点は改善しておきたいところです。
- PowerQueryのステップの作り直しや修正を行うことなくデータ取得条件を切り替えたい
- 取得データを筆者のプロジェクトではなく自分のものに変更したい、自社運用している(gitlab.comではない)Gitlabサーバをデータ取得先にしたい、など
- 取得してきた1連のプロジェクトを対象に、プロジェクト以下の別のデータを取得して分析したい
- 取得対象のデータ量が多く、1度のAPI呼び出しでは必要なデータが取得できない場合にも対応したい
ということで、「データ取得先のサーバやユーザアカウントを切り替えて 取得した一連のプロジェクトのパイプライン利用実績を集計したい」という想定のもとで前回のツールをより汎用性の高いものに発展させます。
PowerQueryの作り込みパターンは概ね説明していきますので、参考にしつつ色々な作り込みを試してみてもらえるとプログラムってどう動いているかのイメージがし易いのではないかと思います。
開発をしているとソースコードを変更した際に変更内容に問題がないかテストをしておいたり、変更したソースコードから実際に動作するアプリケーションを作成したりしたくなることがあります。Gitlabはそのようなケースに対応するために「パイプライン」という機能を提供しており、設定した内容にしたがってGitlabのサーバ側で処理を実行することができます。
処理条件のパラメータ化
#筆者のサンプルはGitlabが公開しているAPIhttps://gitlab.com/api/v4/users/shinichiro-iwaki/projectsからデータを取得し、プロジェクトを作成日付ごとに集計するものでした。筆者のプロジェクトではなくtaro-yamada[3]さんのプロジェクト情報を集計したい場合にはAPIのアクセス先をusers/taro-yamada/projectsに変更して同じ処理を実施すれば良いことになります。
taro-yamadaさんのプロジェクト集計用にクエリを作り直しても良いのですが、取得したデータに対する同じ処理を何度も作ることは無駄な労力ですので、APIのユーザーID部分だけを切り替えて使えるようにできると便利です。このようなケースにはPowerQueryの「パラメータ」を利用できます。数学で出てきた変数xなどのように、「パラメータ」の設定箇所にはその「パラメータ」値が反映されます。例えばユーザーIDをtarget_user_idという名前のパラメータを使用するようにすればパラメータの値を切り替えるだけで指定したユーザーのプロジェクト一覧が取得できるようにクエリを変更できます。
PowerQueryでパラメータの作成はリボンメニューからGUI上で可能です。たとえば「パラメータの管理」から「新規作成」を選択してパラメータの名前、種類、現在の値を設定するとエディタ上に設定した名前のパラメータが追加されます。パラメータの種類は数値、日付、テキストなどのPowerQueryで取り扱い可能な値の種類が選択可能です。ここではURLの中の文字列に使用したいので「テキスト」を選択します。
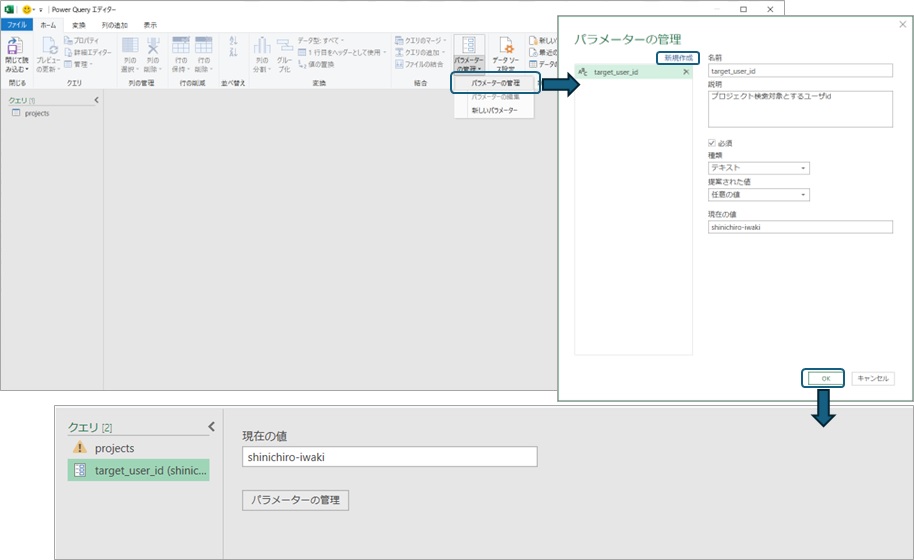
作成したパラメータは、PowerQueryのエディタ上で指定可能になります。データ取得時のURLの一部にパラメータを利用したいので、作成した「ソース」のクエリの設定を開き、URLの詳細設定画面上で「パラメータ」を指定することで作成したパラメータをデータ取得先のURLに含めることができます。これでパラメータの値を変更することでクエリを変更することなくデータ取得対象とするユーザーIDを変更することが可能になりました。
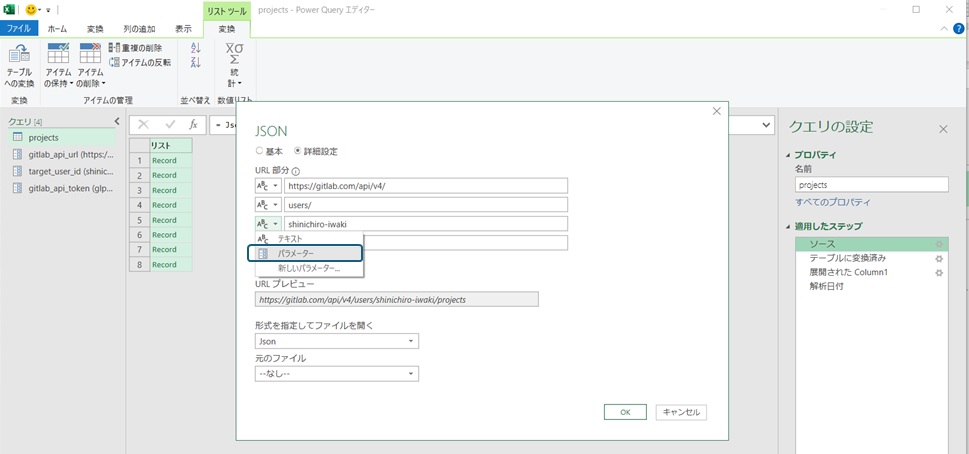
ここで、エディタ上部の小窓を確認すると、"shinichiro-iwaki"という値がtarget_user_idという変数に変更[4]されています。ここには各ステップの処理内容が、Power Query M式言語(M言語)の記法で表示されています。表示内容はQueryエディタ上で処理内容を変更した場合に変更されますが、記載内容を直接編集して処理内容を変更することも可能です。
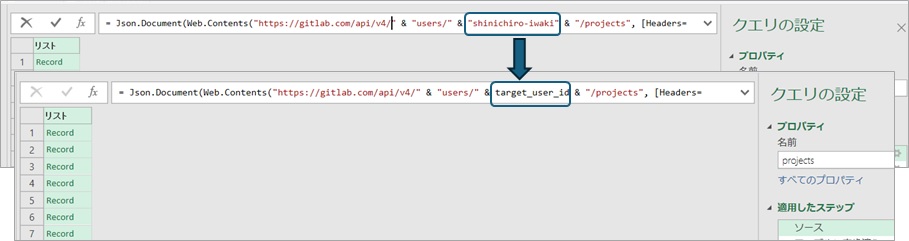
前回記事でAPI呼出し時のヘッダに設定したトークンの値などのように、エディタのGUIからは変更できないものもありますが、M言語で定義されたソースコードを直接修正すれば値をパラメータ化することも可能です。文字列値を変数に変更する修正は上記のように単純な書き換えですのでソースコードを直接修正してトークンはパラメータ化しておくと安全です。
アクセストークンはログインなどの認証が必要となる情報にアクセスする際に、認証済みアクセスをする際に利用する情報です。
ID/パスワードや指紋などによるログインを家の鍵のようなものと例えるならば、トークンは決まった扉だけを開けられる合鍵のようなものと言えます。
前回記事の「データ分析ツール」を個人利用している限りはトークンの情報が直接書かれていても「自宅の合鍵を自分で持っている」ようなものでさほど問題にはならないのですが、他人に渡す場合は注意が必要です。
合鍵を公開していたとしたら泥棒に入られたとしても責任の一部が自分自身にも出てしまうように(同情はしてもらえるかもしれませんが。。)、アクセストークンのような認証アクセスを可能にする情報は慎重に取り扱わなければなりません。
差し当って他人に渡す際に情報を残してしまうリスクを避けるためにも、トークンのような情報はパラメータなどの形でまとめて「誤って人に渡してしまう」ことが無いかを確認できるようにする癖をつけておくことをお勧めします。
カスタム関数の作成と利用
#取得した一連の「Gitlabプロジェクト」に対して各プロジェクトの保持データを取得したいことはよくあります。例えば各プロジェクトで利用したパイプラインの情報は/projects/:プロジェクトID:/pipelinesで取得できます。Gitlabは開発に必要な機能のほとんどが無料アカウントで利用できるため手軽に開発をするのに非常に便利[5]なのですが、執筆時点ではストレージが5GiBまで/パイプラインの利用が月400分まで、といった利用制限があります。パイプライン利用状況が無料枠に収まっているかなどの大まかな情報はGitlabのアカウント画面から確認できるのですが、いつ/どのプロジェクトでどのくらい利用したのか?といった分析をする場合は利用情報を個別に確認していく必要があります。
さて、指定したユーザーIDからGitlabのプロジェクト一覧を取得できるようになりました。同様に、指定したプロジェクトIDからプロジェクトのパイプラインの一覧を取得するクエリの作成もできるかと思います。しかし、現状のクエリはそれぞれが指定されたIDに対してデータを作成するものなので、筆者の利用したパイプラインの一覧を取得しようとするとプロジェクト一覧の取得結果のIDを1つ1つ指定してパイプライン一覧を出力する必要があります。せっかくデータの抽出処理を作成したのに、抽出を手作業で何度もやらないといけないのはあまりに不便です。
このように「あるクエリAの結果を用いて別のクエリBを使用」したい場合には、クエリBと同等の処理をするカスタム関数を作成してクエリAのステップの中で呼び出すことが可能です。これには多少のコーディング作業が必要になりますのでパイプライン一覧を取得するクエリの内容を確認してみます。リボンメニューの「詳細エディター」を選択すると選択しているクエリのソースコードが確認できます。
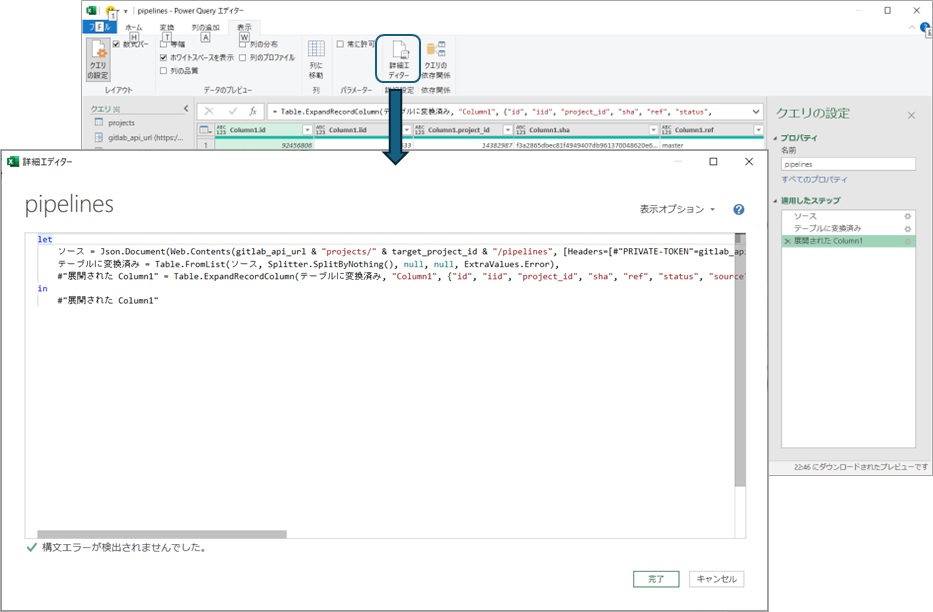
筆者が作成したパイプライン一覧のクエリは、「①GitlabのAPIからプロジェクトの一覧を取得」し、その「②結果をテーブルに変換」した後に「③全てのデータを展開」して表を出力するものですので、以下のようなソースコードになっています。なお、「//」で始まる行は説明のために付け加えたコメントですので、実際のソースコードには含まれません。
//クエリの処理定義。let以下の式は中間計算を行う(これによりエディタGUI上でステップ毎の途中経過が確認できる)
let
// ① Gitlabのprojects APIに対してtarget_project_idで指定されたURLでWebアクセス(Web.Contents)した結果をJSON形式のデータに格納(Json.Document)したものが「ソース」である
ソース = Json.Document(Web.Contents(gitlab_api_url & "projects/" & target_project_id & "/pipelines", [Headers=[#"PRIVATE-TOKEN"=gitlab_api_token]])),
// ② 「ソース」をテーブル形式に変換(Table.FromList)したものが「テーブルに変換済み」である
テーブルに変換済み = Table.FromList(ソース, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
// ③ 「テーブルに変換済み」の{"id", "iid", "project_id",・・・}のデータを{"Column1.id", "Column1.iid", "Column1.project_id",・・・}の形で列に展開(Table.ExpandRecordColumn)したものが「"展開された Column1"」である
#"展開された Column1" = Table.ExpandRecordColumn(テーブルに変換済み, "Column1", {"id", "iid", "project_id", "sha", "ref", "status", "source", "created_at", "updated_at", "web_url", "name"}, {"Column1.id", "Column1.iid", "Column1.project_id", "Column1.sha", "Column1.ref", "Column1.status", "Column1.source", "Column1.created_at", "Column1.updated_at", "Column1.web_url", "Column1.name"})
//このクエリの出力を定義する箇所
in
// このクエリが出力するものは「"展開された Column1"」=「Gitlabから取得したJSONデータ(ソース)をテーブル形式に変換(テーブルに変換済み)したデータを各列に展開したもの」である
#"展開された Column1"
このソースコードはPower Query M式言語(M言語)の書式に従って記載されており、「関数型」と呼ばれる記法で書かれています。ちょっと学生時代の数学の授業を思い出していただくと、「y=x+2、z=2y-3のときのzを求める」ようなイメージです。数学では四則演算の式を書いていましたが、M言語では「Web.Contents」などの言語が提供する機能を利用して処理の式を定義します。
具体的な内容を説明しだすと本が書けるくらいにはなりますので、まずは「こういう書き方をするんだ」というくらいに捉えておいてもらえれば十分です。
何度となく「関数型」という表現を使っていますが、これはソースコードにどのような内容を定義するかという考え方を示しています。対応する考え方には「手続き型」というものがあります。
「手続き型」のプログラミングはコンピュータが行うべき処理を具体的に定義していく考え方です。コンピュータの処理レベルで定義するため、「データ格納のためにメモリを確保」や「処理エラーの場合に中断」のように中間状態の制御や処理の分岐なども行います。状態を制御する必要がある場合との相性が良く、業務システムやWeb系システムなどで使用されることが多いです。
対して「関数型」のプログラミングはコンピュータが達成すべき入力と出力の関係のみを定義するもの[6]で、具体的な処理内容はプログラミング言語に任せます。シンプルで副作用のない定義が可能ですが、慣れていないと直感的な理解は難しいことがあります。
非プログラミングなイメージとしては、大阪に出張して会議に出て欲しい時に「12時に大阪のA社を訪問して会議に参加」することだけ指示して途中経路を任せるのが関数型、「9時東京発の新幹線に乗って新大阪駅で11時30分発の阪急電車に乗り換えて・・・」と具体的な手順を指示するのが手続き型のイメージになるでしょうか。
手続き型の場合、前提が崩れない限りは最適な経路のチューニングまで可能ですが、想定外のダイヤ変更などがあった際には指示通りに動くと会議に間に合わなくなるリスクもあります。
| \ | ソースコード定義内容 | 利点 | 欠点 |
|---|---|---|---|
| 手続き型 | コンピュータの具体的処理 状態や制御処理なども含む |
性能チューニングが可能 直感的な理解がし易い |
記述量が多くなりがち 予期せぬ副作用リスク |
| 関数型 | コンピュータに求める入出力の関係のみ | 記述がシンプル (状態を保持しないため)副作用を排除し易い |
性能面では非効率な可能性あり 直感理解が難しい傾向 |
どちらが正解といったものではないので、そういう流派があるんだな というくらいにイメージできるとこれから先の理解が進みやすいのではないかと思います。
独自の処理を行う関数を作成したい時にはリボンメニューの「新しいソース -> その他のソース -> 空のクエリ」などでクエリを追加し、(好きな名前をつけて)詳細エディタでソースコードを記載します。
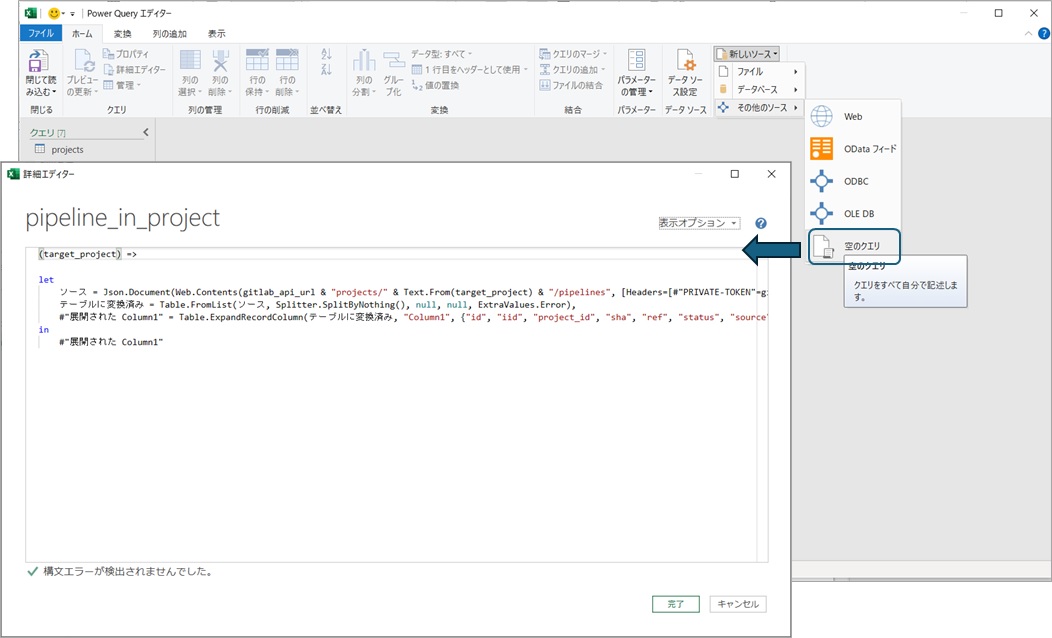
慣れている人はソースコードを直接作成しても良いのですが、エディタで表示されるソースコードをコピーすればクエリと同じ処理をする関数を作れます。ここで、先程のクエリではパラメータで指定していたtarget_project_idは処理の呼出し時に指定したい値です。M言語では入力を定義する場合は関数定義の冒頭に(入力値を,設定したいだけ,カンマ区切りで定義) => のよう定義すればよいので以下のようになります。
//この関数はtarget_projectという名前の変数で入力値を受けるものであることを定義
(target_project) =>
let
// URLは(クエリパラメータのtarget_project_idでなく)入力値のtarget_projectを利用して作成。URLは文字列なので入力値はテキスト形式に変換して使用している
ソース = Json.Document(Web.Contents(gitlab_api_url & "projects/" & Text.From(target_project) & "/pipelines", [Headers=[#"PRIVATE-TOKEN"=gitlab_api_token]])),
// 以後のコードはGUIから作成したクエリをそのまま流用すれば良い
テーブルに変換済み = Table.FromList(ソース, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"展開された Column1" = Table.ExpandRecordColumn(テーブルに変換済み, "Column1", {"id", "iid", "project_id", "sha", "ref", "status", "source", "created_at", "updated_at", "web_url", "name"}, {"Column1.id", "Column1.iid", "Column1.project_id", "Column1.sha", "Column1.ref", "Column1.status", "Column1.source", "Column1.created_at", "Column1.updated_at", "Column1.web_url", "Column1.name"})
in
#"展開された Column1"
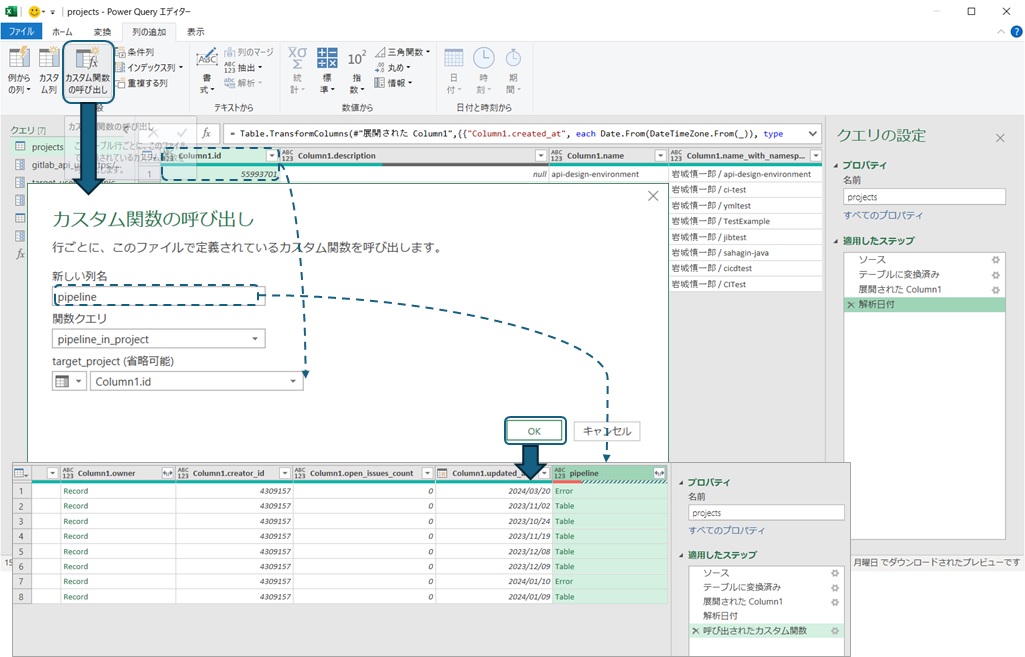
作成したクエリはエディタ上で入力値を指定して実行できますが、「関数」のため別のクエリから呼び出すこともできます。今回はプロジェクトのIDを入力にパイプラインの情報を取得してデータに追加したいので、「列の追加」メニューからカスタム関数の追加を選択します。新しい列名が追加される列の名前になるので分かり易い名前を入力して作成したクエリを選択します。今回のクエリは入力値target_projectを設定しているので、クエリを選択すると入力値を設定できるようになります。ここに元のデータ中にあるプロジェクトのIDの列名(Column1.id)を設定すると行ごとにプロジェクトIDを入力にしたパイプラインの一覧が取得できます。
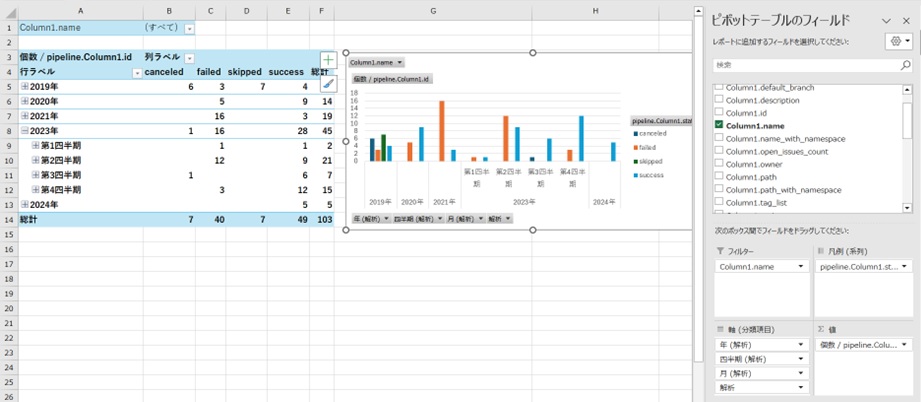
パイプラインを実行していないプロジェクトではpipeline列の結果がエラーになることもありますので、エラー行を除外してpipelineの結果を展開すればパイプラインの実行結果が分析できるようになります。例えばパイプラインのステータス(成功/失敗)ごとに件数を集計すると以下のようなグラフが作成できます。
発展編:コーディングによるカスタム関数の作り込み
#前節で作成したパイプライン一覧ですが、実は取得できているパイプラインの情報は一部だけのものです。
GitlabのAPIは応答するデータの量が多い場合は複数ページのデータに分割して応答する[7]ため、プロジェクトごとに最大20件のパイプライン実績を集計するものになっていました。
APIを介してパイプラインの全データを取得したい場合、「データがなくなるまでページを切り替えながらデータを取得していく」ような繰り返し処理が必要になります。この繰り返し処理のようにGUI操作で作成できない[8]処理を行う場合、コードを書いて処理を作り込む必要があります。
繰り返し処理の実現方法はいくつかありますが、マイクロソフトが提供しているM言語のドキュメントを探すとList.Generate関数が「条件を満たすまで処理を実行して結果を一覧で出力する」動きをしてくれそうです。
List.Generate(initial as function, condition as function, next as function, optional selector as nullable function) as list:initialで指定した関数の状態からスタートして、conditionの関数で指定した条件を満たす限りnextを実行する。selectorで指定した条件で出力値を指定することもできる(List.generateの説明文を筆者が意訳)。
nextで順にAPIを呼び出して、conditionalで取得したデータが空になるまで繰り返せばやりたいことが実現できそうです。ページ数を切り替えるためのpagecounterとデータを格納するitemsを初期状態に設定捨てList.genarete関数を定義してみます。
- initialに「ページを指定するカウンター」と「APIが返却するデータを格納するための変数」を設定
- conditionは「APIが返却するデータ」の個数が0でないことを設定
- nextは「ページ指定カウンター」のページ数を次に進め、APIで指定したページのデータを取得
- optional:出力データ は「APIが返却するデータを格納するための変数」の集合
let
// URLは(クエリパラメータのtarget_project_idでなく)入力値のtarget_projectを利用して作成。URLは文字列なので入力値はテキスト形式に変換して使用している
ソース =
List.Generate(
() => [ pagecounter = 0, items = {null}],
each List.Count( [items] ) > 0,
each [
pagecounter = [pagecounter] + 1,
items = Json.Document(
Web.Contents(
gitlab_api_url & "projects/" & Text.From(target_project) & "/pipelines?per_page=100&page=" & Text.From(pagecounter) ,
[Headers=[#"PRIVATE-TOKEN"=gitlab_api_token]]
)
)
],
each [items]
),
// 初期データとして内容が空(null)のデータを作成しているので、List.generateの結果からnullを除外してからテーブル作成を行うように変更
リスト = List.RemoveNulls(List.Combine(ソース)),
テーブルに変換済み = Table.FromList(リスト, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
・・・
List.generate関数の入力は関数なので、M言語の関数形(入力) => 関数の内容の書式で入力を定義してあります。eachは入力の要素ごとに関数を設定する(_) => {関数の内容}を省略した書き方で、このように省略した書き方を「糖衣構文」と呼びます。
作成したカスタム関数の内容を書き換えることで、データ件数が多い場合にも全データが取得できるようになります。
まとめ
#簡単なコーディングを挟みつつではありますが、Excelの機能を活用して簡単なデータ分析ツールを作り込んでみました。
なお、「簡単な」とは言いましたが、筆者の主観では関数型プログラミングは処理内容を直感的に理解することが難しく、習得難易度が高めだと思います。とはいえGUIのサポートなども活用して「途中の状態を目で見ながら」動きを確認できるので理解をサポートしてくれるツールでもあります。
筆者がプログラミングを始めた当初は、書いたコードがどのように動くのかをイメージするのに苦労しました。簡単にコードの動きを確認しながら開発ができるので、データの分析が必要な時にでも試してもらえると理解がし易いかと思います。
今回は触り程度の紹介ですが、プログラミングの雰囲気をつかんで便利さを感じてもらえればということで記事にしてみました。作成したPowerQueryツールはGitlabに公開してありますので興味のある方は触ってみて下さい。
PowerQueryを極めたいと思ってしまった頼もしい方はMicrosoftが公開しているPowerQueryやM式言語のドキュメントなどに進んでもらえればと思います。
筆者はPowerQueryの専門家ではないので正確な説明でない部分もあるかもしれないですが、分かり易さを優先しているので許してくださいネ という自己弁護でした ↩︎
未読の方向けに簡単にまとめると、PowerQueryで「Gitlabが公開しているプロジェクトAPIから筆者のプロジェクトを取得(GET /users/shinichiro-iwaki/projects)」したデータを「作成日、公開/非公開やプロジェクトのIDなどの表に変換」し、Excelの「ピボットテーブルを利用して作成日ごとに集計したグラフを作成」しました。本記事の前提になっている部分もありますので、イメージが湧かない方は一読していただけると理解し易いかと思います ↩︎
もちろんダミーの名前です。Gitlabに実在するユーザーIDなのかどうかも確認していません。筆者のアイコンを見てもらえば誰をイメージしているかわかる方もいるかもしれませんね ↩︎
M言語の記法では「"」で囲った値は実際の値、"なしの値はその名称の変数として扱われます。
"shinichiro-iwaki"は「shinichiro-iwaki」という文字列の値、target_user_idは「target_user_id」という値 ではなく パラメータtarget_user_idに設定されている値を反映することを意味します。細かいお話は置いておき、いったん「そういう書き方なんだ」と理解していただければ十分です ↩︎筆者がアカウントを作成した当時は無料アカウントであればパイプラインを使うことまでは非常に気軽にできていたのですが、最近の公式ページを見ると不正利用防止のために無料アカウントでも支払情報の登録が必要になっている可能性があります。 ↩︎
少し調べると、「①副作用の無さ」、「②参照透過性」、「③高階関数(第一級関数)」といった難し気なキーワードが出てくるかと思います。筆者の拙い理解の範囲で簡単に説明すると、「①入力に対して決めた出力以外の作用(例えばデータベースへのデータ保存など)を何もしない」、「②同じ入力に対して常に同じ結果を出力する」ような関数によって処理を定義する考え方です。数学で
y=x+2をz=2y-3のyに代入してz=2(x+2)-3=2x+1と計算できたように、「③関数の定義は変数に格納して演算が可能」です。 ↩︎ページネーションと呼ばれる手法でデータを返却します。1ページあたりのデータ件数はAPI呼出し時に設定可能ですが、上限値を超えるデータ量の場合には1回のAPI呼出しで全データの取得はできません。 ↩︎
エディタ上から設定可能な操作には繰り返し処理を制御するような内容はありません。と、いったん断言してしまいましたが、筆者はPowerQueryエディタにそこまで詳しくはないので、実はできたらごめんなさい。 ↩︎