Pythonのライブラリ管理をきっかけに、仮想化のレベルについて調べてみました
Back to Topこれは豆蔵デベロッパーサイトアドベントカレンダー2023第12日目の記事です。
はじめに
#初めまして、BS事業部の山下と申します。
いわゆる第二新卒枠で2023年8月に転職したばかりのものですが、この度寄稿させていただきました。
日々の業務ではJavaで開発をしていますが、個人開発ではPythonを使うことが多いです。
今回は、Pythonの開発環境の構築で少し苦戦した経験とそれを踏まえて、Pythonでよく使われる仮想がどんな形で行われているのかについて学んだことを記そうと思います。
Pythonについて
#代表的な言語の一角となっているPythonですが、その人気を担う一因として、豊富なライブラリを網羅していることによる多用途性が挙げられます。
機械学習・深層学習に関わらず、GPUを用いた科学技術計算やWebアプリケーション等、幅広い用途にPythonは対応可能です。
これらに関わるサードパーティの皆様の助力により、日進月歩でライブラリが発展しているのと同様、それらのライブラリを管理する技術・ツールも進歩しています。
Pythonにおけるライブラリ管理と仮想化について
#ここで、ライブラリを適切に使う上で重要なものである「ライブラリ管理」と「仮想化」について簡単に触れたいと考えております。
一般的な話として、ライブラリ管理と仮想化は全く別の概念です。しかしながら、Pythonで開発する際には切っても切り離せない関係となっております。
具体的には、①プロジェクト毎に仮想な環境を用意し、②その仮想環境の中でライブラリを管理するというのが大まかな流れとなっております。
ライブラリ管理と仮想化の片方(もしくはその両方)を行うツールはいくつか存在していますが、基本的にこの考え方には変わりありません。
また、一部の方からすれば、「仮想」という単語からDockerが連想されるでしょう。
ここでいう「仮想化」の部分をDockerコンテナに任せるというのも、本記事では広い意味で仮想化であると考えます[1]。
ライブラリ管理や仮想化を行うツールとその組み合わせについては、色々なものが存在しております。
いくつか紹介したいのは事実ですが、それらの詳細な説明につきましては、本記事の趣旨から逸れるため割愛させていただきます。
ちなみに筆者は、使いやすさの観点からryeを推しています。
あらまし
#私事ではありますが、geopandasと呼ばれるライブラリをJupyter Notebook上で動かさなければない機会がありました。
地理空間データを扱うライブラリであり、表形式データを扱うpandasを拡張したものです。
pandasをベースにしたデータ形式を用いて、地理空間データの読み書き、分析や可視化などの処理ができるライブラリです。
詳細はgeopandas公式リンクを参照してください。
Jupyter NotebookはWebブラウザ上でPythonコードを書いて実行するツールです。
ノートブックと呼ばれる形式になっており、コードを書いた後の実行結果が直下に表示されるような形となっております。
これにより、逐一結果を確認しながらコードを記述できます。
また、マークアップ言語によるコードの説明もでき、他の開発者との情報共有もスムーズに行えます。
当然、件のgeopandasパッケージを準備して使えるようにする必要があります。
普段であれば、いつもと同じようにryeを使ってサクッとライブラリを管理していたところでしょう。
しかしながら、折角の機会であるため、あえて寄り道してコンテナで開発環境を準備してみようと考えてしまいました(ライブラリの管理にはpipを使う方向で進めました)。
サクッと用意したDockerfileは次のとおりです。
FROM jupyter/scipy-notebook:python-3.11
WORKDIR /app
COPY requirements.txt .
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
CMD ["jupyter", "notebook", "--ip", "0.0.0.0", "--port", "8888", "--no-browser", "--allow-root"]
また、requirements.txtには導入したいライブラリの一覧を記述します。
pandas
numpy
opencv-python
geopandas
folium
plotly
lxml
html5lib
しかしながら、この試みは失敗に終わってしまいます。
結局、時間までに導入できなかったため、その場は別の手段で乗り切る羽目になってしまいました。
煮え切らない気持ちで帰路についたことは記憶に新しいです。
ちなみにryeを使ったところ、何の問題もなくインストールできました。
エラーの内容の抜粋は次のとおりです。
4.479 Requirement already satisfied: tzdata>=2022.1 in /opt/conda/lib/python3.11/site-packages (from pandas->-r requirements.txt (line 3)) (2023.3)
4.632 Collecting fiona>=1.8.21 (from geopandas->-r requirements.txt (line 7))
4.733 Downloading fiona-1.9.5.tar.gz (409 kB)
4.935 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 409.3/409.3 kB 2.0 MB/s eta 0:00:00
4.995 Installing build dependencies: started
15.77 Installing build dependencies: finished with status 'done'
15.77 Getting requirements to build wheel: started
15.86 Getting requirements to build wheel: finished with status 'error'
15.86 error: subprocess-exited-with-error
15.86
15.86 × Getting requirements to build wheel did not run successfully.
15.86 │ exit code: 1
15.86 ╰─> [3 lines of output]
15.86 <string>:86: DeprecationWarning: The 'warn' function is deprecated, use 'warning' instead
15.86 WARNING:root:Failed to get options via gdal-config: [Errno 2] No such file or directory: 'gdal-config'
15.86 CRITICAL:root:A GDAL API version must be specified. Provide a path to gdal-config using a GDAL_CONFIG environment variable or use a GDAL_VERSION environment variable.
15.86 [end of output]
15.86
15.86 note: This error originates from a subprocess, and is likely not a problem with pip.
15.86 error: subprocess-exited-with-error
問題の解決について
#改めてエラー出力を確認すると、ライブラリ管理ツールであるpipの問題ではないことが強調されています。
具体的な原因は、前提となる共有ライブラリ(もっと言うと開発用パッケージ)がインストールされていなかったというpip管理外の問題にありました。
したがって、pip installの前に別のライブラリをインストールすれば、ライブラリの導入に成功します。
Dockerfileは次のようになります。
FROM jupyter/scipy-notebook:python-3.11
# ユーザに関する制限を回避するため追記しています。
USER root
RUN mkdir -p /root/work
WORKDIR /root/work
RUN apt-get update
COPY requirements.txt .
RUN pip install --upgrade pip
# ここでgeopandasライブラリを動かすのに必要となるライブラリをインストールします
RUN apt-get -y install libgdal-dev
RUN pip install -r requirements.txt
CMD ["jupyter", "notebook", "--ip", "0.0.0.0", "--port", "8888", "--no-browser", "--allow-root"]
jupyter/scipy-notebookイメージにおいては、「defaultのユーザ(jovyan)ではsudoを実行できない」という制約[2]があるようです。
ひとまずrootユーザで動作させていますが、話の本筋から大きく逸れるのでここでは追求しません。
ライブラリ管理ツールなどで単純に導入できないケース
#先ほど示したgeopandas on Linuxでは、依存する共有ライブラリをインストールすることで解決できましたが、OSとの相性でライブラリをどうしても導入できないケースはいくつかあるようです。
例えば、Pythonコード実行時のメモリ使用量等を計算してくれるmemrayというライブラリはWindowsにそのまま導入できません。
また、ライブラリの導入までが複雑すぎて、Dockerコンテナの形で提供されているものもあるようです[3]。
根本的な原因について
#前置きが長くなってしまいましたが、このようなことが起こってしまった根本的な原因として、私自身が「どのレベルでの仮想化をしているのか」をいまいち理解できていなかったことが挙げられます。
これを機に、仮想化のレベルについて調べてみることにしました。
図に示すように、仮想化には5段階あるとされています[4]
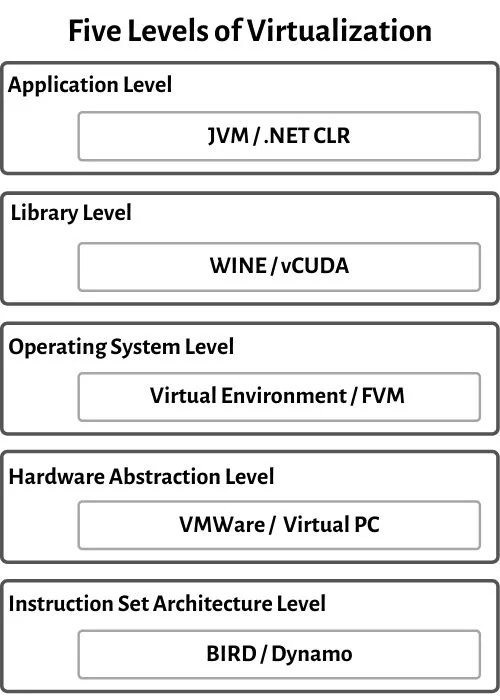
詳しい説明は各種リファレンスにに譲らせていただきますが、簡潔にまとめると次のように分類されます。
1:Instruction Set Architecrure Level
- 異なる命令セットに対応できるように仮想的なプロセッサを用意する
2:Hardware Abstraction Layer Level
- 仮想的なハードウェアを用意する
3:OS Level
- 仮想的なOSを用意する
4:Library Level
- 特定のアプリケーションの実行に必要なライブラリを管理するための仮想的な環境を提供する
5:Application Level
- アプリケーションをライブラリに依存せず、実行するための仮想的な環境を用意する
今回考えた2つの例に当てはめると、次のように分類できそうです。
| Pythonライブラリ管理における仮想化手法 | → | 対応する仮想化のレベル |
|---|---|---|
| ツールを用いた仮想化 | → | Library Level |
| コンテナによる仮想化 | → | OS Level |
たかがライブラリの管理ではありますが、何かしら仮想化する際には以下の2点をきちんと抑えておくべきであると認識させられました。
- 検討している仮想化をどのレベルで行うのか
- OSとライブラリの相性は問題ないか
余談:どういう時にOSレベルの仮想化が求められるのか
#今回の例はともかく、Pythonの仮想化にDockerを用いた方がいいケースとして、次のようなものが挙げられるのではないでしょうか。
- Pythonだけでなく、他のプログラム(DBや監視ツールなど)を内包した環境も用意したい場合
- コンテナ環境と密接に関連せざるを得ない場合
- チームの使っているマシンに依存せず開発する場合
- etc...
個人開発でかつライブラリを試す程度であれば、パッケージ管理ツールを利用する方向でいいのかもしれませんね。
結び
#本稿ではPythonでのライブラリ管理に関する経験から、仮想化のレベルを考察したという旨の内容でした。
「ライブラリ管理なら仮想化してよしなにする」と安易に認識するのではなく、
どのように環境の仮想化されているのかを、より真剣に考えるきっかけになりました。
また、本記事の執筆に際し、社内外問わずサポートしてくださった関係者の皆様には改めて感謝の意を表させていただきます。
Pythonコミュニティの意図する「仮想」とコンテナによる仮想化は別の概念であるようです。いわゆるPythonについてはリンクをご参照ください。 ↩︎
筆者が学生時代に一時期使用していたFEniCSxという科学技術計算のライブラリについてはコンテナが提供されていました。コンテナの導入については別のリンクに示されています。 余談ですが、2020年くらいに使ってたときには名前の末尾にxの文字は入っていませんでした。 ↩︎
意外とまとまっている記事が見つからなかったのですが、hitechnectarの記事(上にあげた図の参照元)やHUAWEI社のブログなどに書かれていました。 ↩︎