Rust でML に挑戦してみた
Back to Topこの記事は夏のリレー連載2023の10日目の記事です。
1. はじめに
#こんにちは。この記事が初投稿となります、松本です。よろしくお願いします。
さて、C/C++ に代わる言語として注目を浴びている Rust ですが、ML や NN の記事量は圧倒的に Python で、Rust で書いた例はググってもあまり見ない気がします。しかし速度を重視する場合、必ずしもメモリ安全ではない C/C++ を使わざるを得ず、メモリ安全で高速な Rust は魅力があります。
そこで、Rust 界隈でどのような crate があるか調査してみました。
2. Rust + CUDA で使えそうな crate
#最近 Update されていて、面白そうな crate を挙げてみました。
- Rust-CUDA/Rust-GPU
- darknet(ちょっと違うか)
- tch
- tensorflow
- opencl3
この中で、革新的な Rust-CUDA/Rust-GPU プロジェクトと PyTorch を使う tch について触れたいと思います。
2.1 Rust-CUDA/Rust-GPU
#| 前提条件 |
|---|
| LLVM7 |
| CUDA11.4.1以上 |
Nightly Build が前提。
LLVM 利用で、CUDA 用のコードも(属性がちょっと鬱陶しいが) Rust で書ける点が革新的です。
ただし、Dockerfile を見ればわかりますが、Ubuntu 18.04.01 が前提で、LLVM も version 7 を必要とします。
現状では Docker 環境で動かすのが安全と言えそうです。
是非、Ubuntu 22.04.02 + LLVM15 + CUDA12.2 に対応して欲しいものですが、2022年以来アップデートされていないのが惜しいです。
2.2 tch
#| 前提条件 |
|---|
| PyTordch == 2.0.0 |
| CUDA11.7以上 |
libtorch のラッパーなので、PyTorch に可能なことは全部できます。
また、libtorch をわざわざインストールしなくても、PyTorch がインストールされていれば PyTorch の libtorch.so を指定することで利用可能です。
アクセラレータは CUDA の他、Apple Silicon の MPS(Metal Performance Shaders)、Vulkan API にも対応しています。
ただし、PyTorch の安定版最新(2.0.1)には対応していません。
3. 生き残る crate はどれだ
#crates.io をみると分かりますが、他にも様々な人が crate を作ろうとしていた時期があるようです。けれども、ほとんどの crate は 2023 年になってからメンテナンスされていません。
現時点では、結局 PyTorch とか Tensorflow のコンパイル済みライブラリを呼び出すのが(C++に落ちるのが悔しいけど)現実的のようです。
4. まだ生きていそうな tch crate を使って libtorch を使ってみる
#この章では、tch crate を使って libtorch を呼び出してみます。
(tensorflow を使わなかったのは、単に私が PyTorch になれていると言う理由だけです。)
お題としては、CIFAR-10 の画像を NN に学習させてみます。
最初に全結合型NN(隠れ層1536)で学習します。
次に CNN→Max Pooling→CNN→Max Pooling で学習します。
4.1 パラメータ学習に使う PC のスペック
#NN学習に使う PC のスペックは以下のとおりです。Google Colaborator を使えばよかったとの思いもありますが、手持ち資産でどこまでできるか調べたいというのもあったので、ローカルで実行することにしました。
| パーツ | スペック |
|---|---|
| CPU | Core i7 13700F |
| GPU | Nvidia RTX 4090 GRAM 24GB |
| RAM | DDR5 128GB |
| SSD | NVM.e 1TB+2TB |
4.2 CIFAR-10 を全結合型NNで判定する
#PyTorch では基本データ型として Tensor を使いましたが、tch でも基本的なデータ型は Tensor となります。
従って、読み込んだデータは一旦 Tensor に変換する必要があります。
CIFAR-10 データは幸い Tensor データに変換する専用のローダがありますので、これを利用して Tensor を読み込むことにします。
さて、全結合型NNを tch で表現するには以下のようにします。
use std::time::Instant;
use tch::{no_grad_guard, nn, nn::Module, nn::OptimizerConfig, Device};
const IMAGE_DIM: i64 = 3 * 32 * 32;
const HIDDEN_NODES: i64 = 3 * 32 * 32;
const LABELS: i64 = 10;
fn net(vs: &nn::Path) -> impl Module {
nn::seq()
.add(nn::linear(
vs / "layer1",
IMAGE_DIM,
HIDDEN_NODES,
Default::default()
))
.add_fn(|x| x.relu())
.add(nn::linear(
vs / "layer2",
HIDDEN_NODES,
LABELS,
Default::default()
))
}
fn main() {
let m = tch::vision::cifar::load_dir("data").unwrap();
let vs = nn::VarStore::new(Device::cuda_if_available());
let net = net(&vs.root());
let mut opt = nn::Adam::default().build(&vs, 1e-02).unwrap();
let start = Instant::now();
println!("epoch,time,acc");
let images_d = m.train_images.to_device(vs.device()).reshape(&[-1,IMAGE_DIM]);
let label_d = m.train_labels.to_device(vs.deevice());
let t_images_d = m.test_images.to_device(vs.device()).reshape(&[-1,IMAGE_DIM]);
let t_labels_d = m.test_labels.to_device(vs.device());
loop {
let loss = net.forward(&images_d)
.cross_entropy_for_logits(&labels_d);
opt.backward_step(&loss);
{
let _guard = no_grad_guard();
acc = net.forward(&t_images_d)
.accuracy_for_logits(&t_labels_d);
let end = start.elapsed();
let acc_cpu = acc.to_device(Device::Cpu);
println!(
"{:4},{}.{:03},{:8.5},{:?}",
epoch,
end.as_secs(),
end.subsec_nanos() / 1000000,
&acc_cpu
);
epoch += 1;
}
}
}
この NN の最終的な正解率は約 41% となりました。
4.3 CIFAR-10 を CNN で判定する
#せっかくの画像データなので、今度は CNN で学習させてみます。
作成したNNは CNN→Max Pooling→CNN→Max Pooling→linear です。
この NN は tch だと以下のように記述できます。
use std::time::Instant;
use tch::{no_grad_guard, nn, nn::Module, nn::OptimizerConfig, Device};
const LABELS: i64 = 10;
fn net(vs: &nn::Path, config: &nn::ConvConfig) -> impl Module {
nn::seq()
.add(nn::conv2d(
vs / "layer1", 3, 16, 3, config
))
.add_fn(|x| x.relu())
.add_fn(|x| x.max_pool2d(2))
.add(nn::conv2d(
vs / "layer2", 16, 8, 3, config
))
.add_fn(|x| x.relu())
.add_fn(|x| x.max_pool2d(2))
.add_fn(|x| x.reshape(&[-1, 512]))
.add(nn:linear(
vs / "labels",
8 * 8 * 8,
LABELS,
Default::default()
))
}
fn main() {
let m = tch::vision::cifar::load_dir("data").unwrap();
let vs = nn::VarStore::new(Device::cuda_if_available());
let mut config = nn::ConvConfig::default();
config.padding=1;
let net = net(&vs.root(), config);
let mut opt = nn::Adam::default().build(&vs, 1e-03).unwrap();
let images_d = m.train_images.to_device(vs.device()).reshape(&[-1, 3, 32, 32]);
let labels_d = m.train_labels.to_device(vs.device());
let t_images_d = m.test_images.to_device(vs.device()).reshape(&[-1, 3, 32, 32]);
let t_labels_d = m.test_labels.to_device(vs.device());
let start = Instant::now();
let mut epoch: u64 = 1;
println!("epoch,time,acc");
loop {
let loss = net.forward(&images_d)
.cross_entropy_for_logits(&labels_d);
opt.backward_step(&loss);
{
let _guard = no_grad_guard();
let acc_d = net.forward(&t_images_d)
.accuracy_for_logits(&t_labels_d);
let end = start.elapsed();
let acc_cpu = acc_d.to_device(Device::Cpu);
println!(
"{:4},{}.{:03},{:?}",
epoch,
end.as_secs(),
end.subsec_nanos() / 1000000,
&acc_cpu
);
epoch += 1;
}
}
}
最終的な正解率は 67% となりました。
全結合型NNに比べると正解率が向上しています。
4.4 おまけ: Autoencoder の実装
#CIFAR-10 の画像なので、Autoencoder を構成してみます。
Encoder は 4.3 同様とし、Decoder は ConvTranspose2d×2 を追加しました。
画像ファイルの生成には png crate を使用しました。
use std::time::Instant;
use tch::{nn, IndexOp, Tensor, nn::Module, nn::OptimizerConfig, Device, Reduction, Kind};
use std::path::Path;
use std::fs::File;
use std::io::BufWriter;
use png::Encoder;
fn net(vs: &nn::Path, config: &nn::ConvConfig, conv_config: &nn::ConvTransposeConfig) -> impl Module {
nn::seq()
.add(nn::conv2d(
vs / "layer1", 3, 16, 3, *config
))
.add_fn(|x| x.relu())
.add_fn(|x| x.max_pool2d(2, 2, 0, 1, false))
.add(nn::conv2d(
vs / "layer2", 16, 8, 3, *config
))
.add_fn(|x| x.relu())
.add_fn(|x| x.max_pool2d(2, 2, 0, 1, false))
.add(nn::conv_transpose2d(
vs / "rev_layer2", 8, 16, 2, *conv_config
))
.add(nn::conv_transpose2d(
vs / "rev_layer1", 16, 3, 2, *conv_config
))
}
fn write_image(p: &str, t: &Tensor) {
let path = Path::new(p);
let file = File::create(path).unwrap();
let ref mut wb = BufWriter::new(file);
let mut encoder = Encoder::new(wb, 32, 32);
encoder.set_color(png::ColorType::Rgb);
encoder.set_depth(png::BitDepth::Eight);
let mut writer = encoder.write_header().unwrap();
let mut v = Vec::<u8>::new();
let yb = t.unbind(2);
for y in 0..32 {
let xb = yb[y].unbind(1);
for x in 0..32 {
let cb = xb[x].unbind(0);
let r = u8::try_from(&cb[0] * 255.0).unwrap();
let g = u8::try_from(&cb[1] * 255.0).unwrap();
let b = u8::try_from(&cb[2] * 255.0).unwrap();
v.push(r);
v.push(g);
v.push(b);
}
}
writer.write_image_data(&v).unwrap();
}
fn main() {
let m = tch::vision::cifar::load_dir("data").unwrap();
let vs = nn::VarStore::new(Device::cuda_if_available());
let mut config = nn::ConvConfig::default();
config.padding = 1;
let mut conv_config = nn::ConvTransposeConfig::default();
conv_config.stride = 2;
// test_images を訓練に使う
let train_images = m.test_images;
let images_d = train_images.to_device(vs.device()).reshape(&[-1, 3, 32, 32]);
let net = net(&vs.root(), &config, &conv_config);
let mut opt = nn::Adam::default().build(&vs, 1e-02).unwrap();
let start = Instant::now();
println!("epoch,time,test");
for epoch in 1..10000 {
let loss = net.forward(&images_d)
.mse_loss(&images_d, Reduction::Mean);
opt.backward_step(&loss);
let loss_cpu = loss.to_device(Device::Cpu);
let end = start.elapsed();
println!(
"{:4},{}.{:03},{:?}",
epoch,
end.as_secs(),
end.subsec_nanos() / 1000000,
&loss_cpu
);
}
// 任意の5個のテスト画像を選択する
let indices = Tensor::randint(50000, 5, (Kind::Int64, Device::Cpu));
let indices = Vec::<i64>::try_from(indices).unwrap();
let indices = indices.as_slice();
let test_images = m.train_images.i(indices);
let tests_d = test_images.to_device(vs.device()).reshape(&[-1, 3, 32, 32]);
let sample_dst = net.forward(&tests_d);
// 画像を保存する
let sample_srcs = tests_d.unbind(0);
let sample_dsts = sample_dst.unbind(0);
for c in 0..5 {
let fname = format!("result/org_{}.png", &c);
write_image(&fname, &sample_srcs[c]);
let fname = format!("result/defer_{}.png", &c);
write_image(&fname, &sample_dsts[c]);
}
}
この Autoencoder で 1 万枚を学習させ、テストセットからランダムに選んだ 5 枚を出力させたところ、以下のようになりました。
| Input | Output |
|---|---|
 |
 |
 |
 |
 |
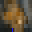 |
 |
 |
 |
 |
色相はあまり再現できていませんが、輪郭は何となく再現されているようです。
5. まとめ
#Nvidia がネイティブに Rust サポートしてくれないとバージョン対応が遅れるなど厳しい面があります。
推論については Nvidia の TensorRT があるので、あまり旨味がないかも知れません。
Rust で ML するのはまだ時期早尚なのかもしれません。