ChatGPTに自然言語処理モデル「GPT2-Japanese」の使用方法を聞きながら実装したら想像以上に優秀だった件
Back to Top前回は ChatGPT と Hugging Face を簡単に触ってみました。
今回は ChatGPT に自然言語処理モデル「GPT2-Japanese」の使用方法を聞きながらプログラムを実装してみたところ、想像以上に優秀だったので、その過程をご紹介したいと思います。
(想像以上ではありましたが、そのままコピペでは動作しなかったので、エラーの回避方法も ChatGPT に問いかけをしながら実装を進めました)
ChatGPT にプログラムを教わる
#ChatGPT の登場以降、SNSでは「プログラマーは失業する」とか「ソフトウェアエンジニアの危機」みたいな情報が散見されるので、ChatGPT がソフトウェア開発にどれくらい役に立つのかを試してみたくなりました。
前回は ChatGPT のベース技術である「Transformer」について調べていたので、その流れで今回は「”ChatGPT”の力を借りて自然言語処理を”実際に”プログラミング」してみようと思います。
ChatGPT に次の問いかけをしました。
GPTを使った自然言語処理のサンプルプログラムを教えて
すると ChatGPT が以下のように応答してきました。
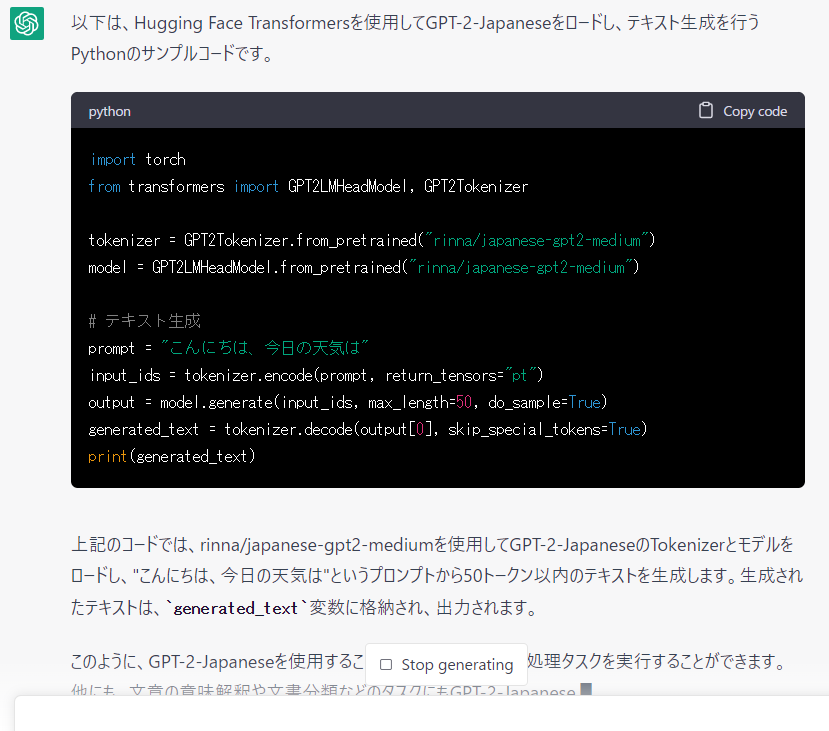
参考として出力されたプログラムには「rinna/japanese-gpt2-medium」というモデルが使われているようです。
Hugging Face のサイトで見たことがあるので、今回はこのモデルを利用することにします。
一応、使用する言語(Python)を指定して問いかけ直してみます。
PythonでGPT-2-Japanseを使ったプログラムを書きたいので、サンプルを教えて
ChatGPT が以下のように応答してきました。
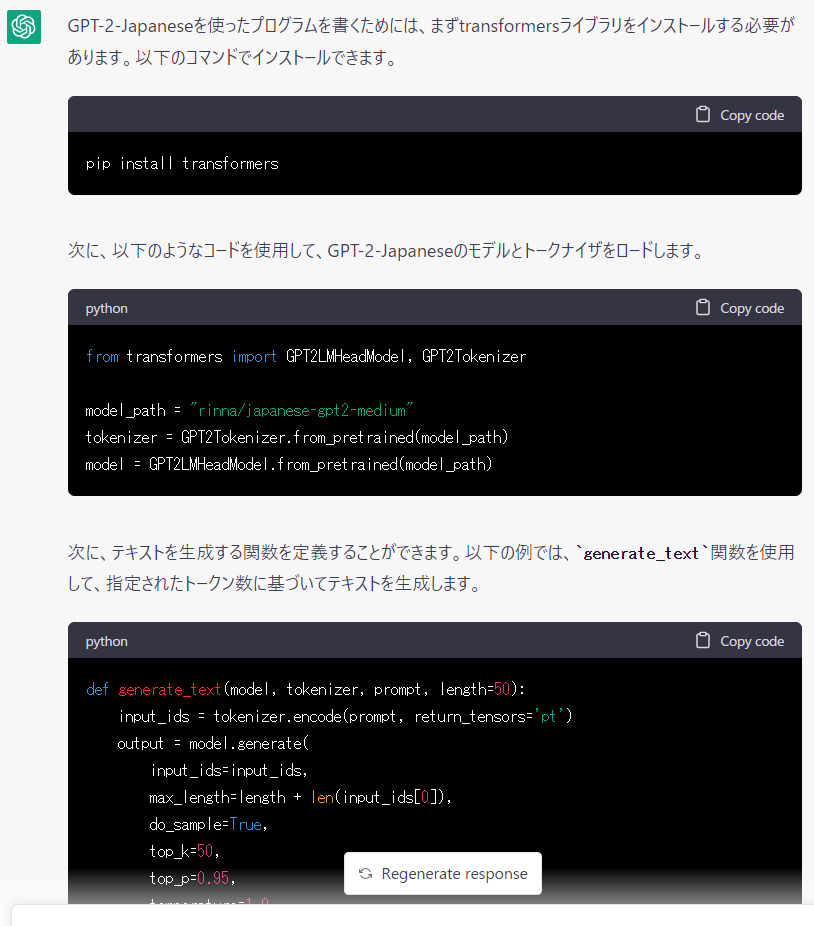
この時点で既に「すげー」ってなってしまいました。
必要なライブラリのインストール方法やサンプルプログラムまで詳細に提示してくれています。
ググっても同様の情報を得ることはできると思いますが、ChatGPT は情報を集約して表示してくれるので非常に助かります。
さっそくpipで「transformers」ライブラリをインストールします。
pip install transformers
次に GPT2-Japanse 事前学習済みモデル「rinna/japanese-gpt2-medium」を取得します。
このモデルは Hugging Face で公開されているモデルです。
モデルは、次のプログラムを実行すると自動的にダウンロードが開始され取得できるはずです。
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model_path = "rinna/japanese-gpt2-medium"
tokenizer = GPT2Tokenizer.from_pretrained(model_path)
model = GPT2LMHeadModel.from_pretrained(model_path)
プログラムを実行してみましたが、次のようなエラーが発生してしまいました。


エラーの内容を ChatGPT に問いかける
#今までだったら上記のエラー内容を普通に”ググって”調べていたと思いますが、今回はエラー内容を ChatGPT に問いかけをしてみます。
上記のエラーの文章をそのまま ChatGPT にコピペして、更に「と言われました。どうすればいいですか?」を追記して問いかけてみました。
すると、以下のように応答してきました。
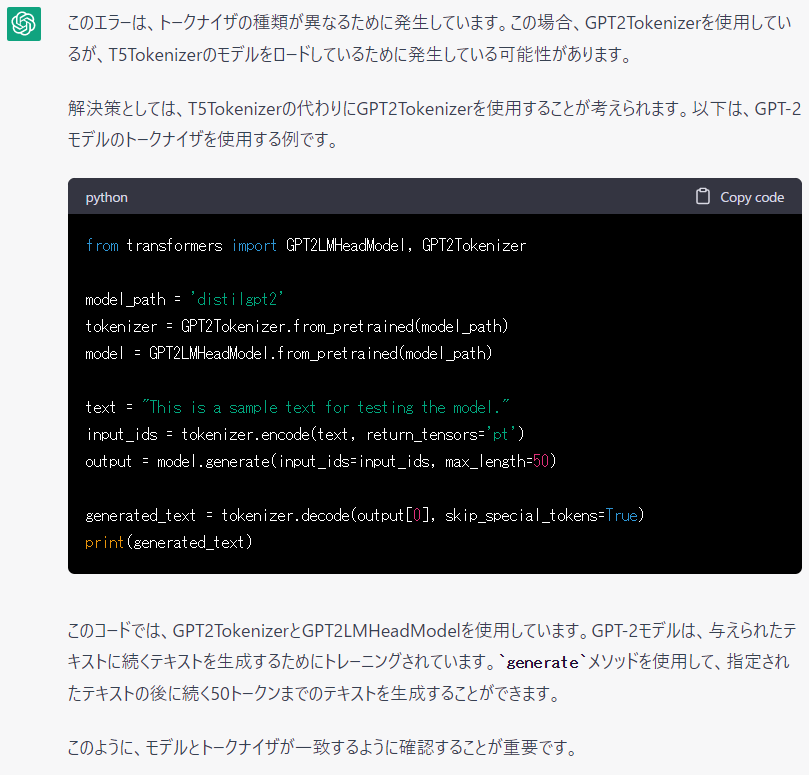
更に「すげーーー」ことではあるのですが、うーん・・・ちょっと違う。
「rinna/japanese-gpt2-medium」を使いたいので、再度 ChatGPT に以下のように問いかけます。
rinna/japanese-gpt2-medium にあったTokenizerとmodelを教えて
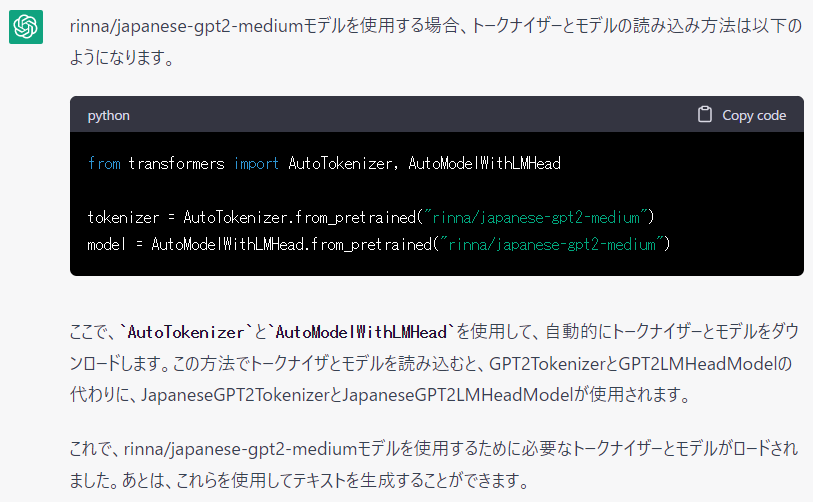
なるほど、ありがとう!
ということで早速試してみます。
from transformers import AutoTokenizer, AutoModelWithLMHead
model_path = "rinna/japanese-gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelWithLMHead.from_pretrained(model_path)
今度は警告が出ました。

「AutoModelWithLMHead」ではなく「AutoModelForCausalLM」を使えと言っているようです。
「AutoModelForMaskedLM」や「AutoModelForSeq2SeqLM」も候補として上がっていますが、ここは「AutoModelForCausalLM」を使用することにします。
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "rinna/japanese-gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path)
プログラムを実行しても警告は出なくなりました。
続いて以下の関数を登録します。
テキスト生成用の関数です。
関数内部でモデルの「generate」メソッドを使用しています。
def generate_text(model, tokenizer, prompt, length=50):
input_ids = tokenizer.encode(prompt, return_tensors='pt')
output = model.generate(
input_ids=input_ids,
max_length=length + len(input_ids[0]),
do_sample=True,
top_k=50,
top_p=0.95,
temperature=1.0,
num_return_sequences=1,
)
text = tokenizer.decode(output[0], skip_special_tokens=True)
return text
関数の登録を実行した後、次のコマンドを実行します。
prompt = "私は今日も"
generated_text = generate_text(model, tokenizer, prompt, length=50)
print(generated_text)
すると、今度は違う警告が表示されました。

内容がよくわからないので、そのままの内容(+「で、どうしたらいいですか?」)を ChatGPT に問いかけます。
以下のように応答がありました。
問いかけをする度に、前に提示されたサンプルプログラムとはちょっとずつ違うサンプルプログラムが提示されるのは、まあ致し方ないところでしょう。
(チャットなので前の方の文章をある程度は踏襲しているとは思うのですが)
この後は何度かやり取りを繰り返し、更に”人間の曖昧さ” をフルに使ってツギハギで修正を行いました。
とりあえず動くものが出来上がった
#プログラムは最終的には以下のようになりました。
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "rinna/japanese-gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(model_path, padding_side='left')
model = AutoModelForCausalLM.from_pretrained(model_path)
def generate_text(model, tokenizer, prompt, length=50):
input_ids = tokenizer.encode(prompt, return_tensors='pt', padding=True, truncation=True)
attention_mask = input_ids.ne(tokenizer.pad_token_id).float()
output = model.generate(
input_ids=input_ids,
max_length=length + len(input_ids[0]),
attention_mask=attention_mask,
pad_token_id=tokenizer.eos_token_id,
do_sample=True,
top_k=50,
top_p=0.95,
temperature=1.0,
num_return_sequences=1,
)
text = tokenizer.decode(output[0], skip_special_tokens=True)
return text
prompt = "私は今日も"
generated_text = generate_text(model, tokenizer, prompt, length=50)
print(generated_text)
ただ、やはり実行時に「padding_side='left'」を使えと警告されてしまいますが、とりあえず無視して先に進めます。
(指定した通りに実装したはずですが、何かが違うのでしょう)
出来上がったプログラムの実行結果は次のようになりました。

私は今日も に続く生成された文章の中に顔文字まで出力されているのには驚きました。
ファインチューニングの方法を ChatGPT に問いかける
#事前学習済みモデルを更に微調整してみましょう。
調整に使うデータには有名な小説「老人と海」を使用します。
データは事前に青空文庫からダウンロードして、テキストファイル(UTF-8)に格納しておきました。
ChatGPT に以下の問いかけを行います。
GPT-2-Japanseのファインチューニングをするプログラムを教えて
以下のように応答がありました。

めっちゃ丁寧に説明してくれています。
ただし、使用していた事前学習済みモデルが違うものだったので、モデルを「"rinna/japanese-gpt2-medium"」に指定して、何度か問いかけ直すことで以下のプログラムを得ることが出来ました。
(使用している「TextDataset」モジュールは非推奨であると警告が出ますが、今回は警告は無視しています)
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "rinna/japanese-gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side="left")
model = AutoModelForCausalLM.from_pretrained(model_name)
# ファインチューニングに使用するテキストデータに「老人と海」(青空文庫からダウンロード)を使用しました。
from transformers import TextDataset
train_dataset = TextDataset(
tokenizer=tokenizer,
file_path="roujin_to_umi.txt",
block_size=128
)
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=False
)
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=32,
save_steps=5000,
save_total_limit=2,
prediction_loss_only=True,
logging_steps=1000,
logging_dir='./logs',
overwrite_output_dir=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator,
tokenizer=tokenizer,
)
trainer.train()
# ファインチューニングされたモデルを保存します
trainer.save_model("fine-tuned-model")
プログラムの実行にかなりの時間を要しましたが、無事にチューニングできたようです。

チューニング後のモデルを使用するには、モデルを次のように読み込んで使用します。
model_name = "fine-tuned-model"
tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side="left")
model = AutoModelForCausalLM.from_pretrained(model_name)
チューニング前とチューニング後の結果
#今回、ファインチューニングのデータに「老人と海」(青空文庫からダウンロード)を使ったので、書き出しの文章を
彼は老いていた。漁師は
にします。
チューニングする前のモデルで
彼は老いていた。漁師は
の後の文章がどうなるかを見てみます。
チューニング前:
「彼は老いていた。漁師は、魚をとることの楽しみを知っていた、また、魚を取って食べること をより身近に感じてもいた。そしてそれは 漁師が魚の調理や魚の調理についてより関心が持てるように なった理由の一つであった。そのような魚を 生から殺すのに躊躇することは、釣りに夢中になる者にとって 、ある種不本意な ことである、と人々は考える。 魚を調理するというのも 、魚を食べさせることへの夢をなくすということ と同じぐらい 難しいことだ。」
次にチューニングした後のモデルで
彼は老いていた。漁師は
の後の文章がどうなるかを見てみます。
チューニング後:
「彼は老いていた。漁師は、海が荒れたので、船を曳いて戻った。しかし、その船は波に流されて、潮の満ち引きに逆らって、海面に浮かんでいた。老人は船尾に手をついて、風を待ち続けた。 「船頭は手すりにつかまって、ずっと波を見ていたんだ。でも、もう大丈夫だよ」 「老人が船に手をかけて、岸まで引き寄せてくれた。彼は満足して、甲板から出た。船は大きめの船だった。」
チューニング後の文章は何となくですが「老人と海」の語り口に近くなっているように思います。
助手としては優秀
#今回、ChatGPT を使ったプログラム作成に挑戦してみました。
ChatGPT は、サンプルプログラムの提示、エラーの内容確認、回避方法の提案、調査など、もろもろの要求にかなりしっかりと応えていると感じました。
難易度の高いプログラム作成の場合に ChatGPT がどれほど有効かはわかりませんが、かなり優秀な助手であることは間違いないでしょう。
いずれ近い未来にはやってくる技術とは思っていましたが、異常に早い速度で進化しているのを感じます。
そのうちに、SF小説「月は無慈悲な夜の女王」やSF番組「スター・トレック」の中に登場するコンピュータのように「ハロー、コンピュータ」と言ってコンピュータと会話する日がくるかもしれません。