ディープラーニング初心者がOpenVINOを使ってみる(その2:MobileNet画像分類編)
Back to Top前回、ディープラーニング・アプリケーション開発キット OpenVINO のインストールと動作確認を実施しました。
今回は、ディープラーニングモデルの中の画像分類モデル「MobileNet V3」を見ていきたいと思います。
画像分類モデル MobileNet とは
#MobileNet は「Mobile」という名を冠している通り、組み込みアプリケーションなどの限られたリソースでも、精度を最大化するように設計された軽量な高性能CNN(Convolutional Neural Network:畳み込みニューラルネットワーク)です。
2017年にGoogleからV1が発表されました。
その後いくつか改良が施され、OpenVINO の OMZ(Open Model Zoo) から V1,V2,V3 のそれぞれのバージョンが取得できます。
CNN ってなに?
#CNN(Convolutional Neural Network:畳み込みニューラルネットワーク)について少しだけ説明します。(自分の理解のためにも)
「CNN」の「NN(ニューラルネットワーク)」とは”脳の神経回路を模倣した数理モデル”のことです。
モデルの構造が、脳の神経細胞の構造を模倣しているように見えることから「Neural」=「神経(系)」のネットワークと呼ばれています。
その中で「CNN」は「畳み込み層」を持つなどの特徴を備えたニューラルネットワークになります。
物凄く簡単にいうと NN よりも更に学習可能な深い層構造を持つニューラルネットワークということになります。
現在、CNNは画像認識の分野で高い性能を発揮しています。
今回は OpenVINO チュートリアルの「画像分類」を試して見ましょう。
OpenVINO チュートリアル 001 「画像分類」
#OpenVINO チュートリアルから 001「画像分類」を試してみます。
このチュートリアルでは事前学習済みモデルとして「MobileNet V3」が使用されています。
jupyter lab で「001-hello-world」フォルダを開き、「001-hello-world.ipynb」ファイルをダブルクリックします。
jupyter lab 上のセル単位にPythonプログラムをインタラクティブに実行していきます。
最初のセルで以下のライブラリを読み込んでいます。
import cv2
import matplotlib.pyplot as plt
import numpy as np
from openvino.runtime import Core
- cv2 : OpenCV ライブラリ
- matplotlib : グラフ描画用ライブラリ
- numpy : 数値計算用ライブラリ
- openvino : ディープラーニング・アプリケーション開発キット OpenVINO ライブラリ
「openvino.runtime」から「Core」モジュールを読み込みます。
これが OpenVINO ランタイムの中核モジュールになります。
次のセルでモデルを読み込み、出力レイヤを取り出しています。
ie = Core()
model = ie.read_model(model="model/v3-small_224_1.0_float.xml")
compiled_model = ie.compile_model(model=model, device_name="CPU")
output_layer = compiled_model.output(0)
今回使用したモデルは MobileNet の「v3-small_224_1.0_float」になります。
レイヤの内容を確認すると
<ConstOutput: names[MobilenetV3/Predictions/Softmax:0] shape[1,1001] type: f32>
と表示されました。
1行1001列の配列のようです。
次のセルで、分析する画像を読み込んでいます。
# The MobileNet model expects images in RGB format.
image = cv2.cvtColor(cv2.imread(filename="../data/image/coco.jpg"), code=cv2.COLOR_BGR2RGB)
# Resize to MobileNet image shape.
input_image = cv2.resize(src=image, dsize=(224, 224))
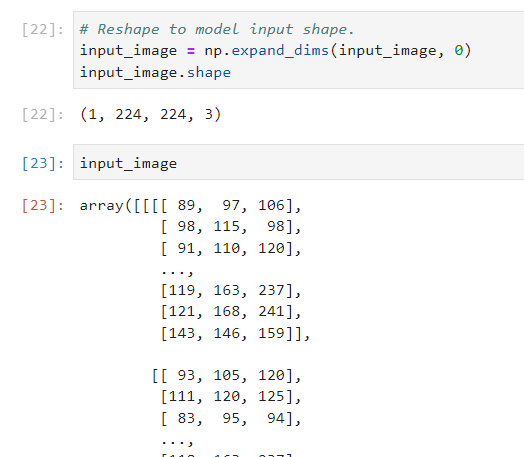
# Reshape to model input shape.
input_image = np.expand_dims(input_image, 0)
plt.imshow(image);
チュートリアルでは犬の写真を使用しているようでした。
読み込みにOpenCVを使用しています。
(OpenCVで読み込んだ画像の色の順番は「BGR」の順なので、「RGB」の順番に変換して利用します)
今回使用した MobileNet V3 モデルは分類する画像の「高さ」と「幅」が「224」のサイズである必要があるので、numpy でサイズを(224, 224)に変換します。
また、軸0で配列を拡張変換します。
matplotlib の描画メソッドで画像を確認しています。
分類対象の画像

上記の処理をもう少し詳しく見てみましょう。
最初の画像読み込み後の image の配列の構造を shapeメソッドで確認します。
image.shape の結果は
(577, 800, 3)
でした。
画像は、高さ:577、幅:800、RGBの3層であることがわかります。
次にリサイズした後の input_image の構造は
(224, 224, 3)
になっており、MobileNet V3 モデルが要求する画像の高さ、幅に調整されています。
では、このデータをこのまま入力データとして使えるのでしょうか?
答えは「NO」です。
モデルで想定する画像イメージの構造についてここで確認すると、構造は
(1, 224, 224, 3)
が期待されています。
先頭の「1」は”バッチサイズ”にあたります。
ここでは詳細は説明しませんが、モデルへの入力には「バッチ」という単位での入力が求められているようです。
入力するデータの準備が出来たので、推論を実行します。
result_infer = compiled_model([input_image])[output_layer]
result_index = np.argmax(result_infer)
得られた「result_index」の値は「206」でした。
この値は何なのでしょうか?
種明かしをすると、この値はモデルが学習したデータで、入力データにもっともマッチする学習済みデータのインデックス番号になります。
どのインデックスがどの学習済みデータに対応しているのかの対応リストが「utils/imagenet_2012.txt」ファイルに用意されています。
次のセルでリストを読み込んでいます。
# Convert the inference result to a class name.
imagenet_classes = open("utils/imagenet_2012.txt").read().splitlines()
このTXTファイルの中には1000種類の学習済みのクラス名が列挙されています。
次の処理で「インデックス番号に相当するクラス名」を指定して出力しています。
# The model description states that for this model, class 0 is a background.
# Therefore, a background must be added at the beginning of imagenet_classes.
imagenet_classes = ['background'] + imagenet_classes
imagenet_classes[result_index]
(最初の方の処理で得た出力レイヤが1001列あったことを思い出してください。次の処理ではクラス名の先頭に「background」というデータを追加してインデックスを調整しています)
画像の分類結果として
'n02099267 flat-coated retriever'
が出力されました。
画像に写っていた犬の名前は「フラットコーテッド・レトリーバー」だと答えているのがわかりました。
オリジナル画像に変更して分類してみる
#チュートリアルで予め用意してあった画像だからうまく言い当てられた可能性もありますので、オリジナルな別の画像を持ってきて分類させてみましょう。
サンプル画像は次です。(我が家の愛猫「しおん」です)

分析結果は
'n02123045 tabby, tabby cat'
と表示されました。
「トラ猫」「ぶち猫」
と認識したようです。
確かにトラ(縞模様)の部分が多く写っているので、そのように認識しても間違いではないでしょう。
(しおんの譲渡主さんからは「キジ白」だと聞いていましたが、さすがに学習データの中には「キジ白」は無かったのでしょうか)
それにしても、上記の画像からよく「猫」だと認識できたと思います。
ただの毛糸玉にしか見えないのですが。
別の画像を用意して分類させてみました。
今度は、少し白い部分が多く写った画像に変更してみました。

分析結果は
'n02106166 Border collie'
と表示されました。
「ボーダー・コリー」・・・あれ?
まあ、そのように見えなくはないですが(笑)
つづく
#今回は OpenVINO の MobileNet を使って画像分類を行いました。
手持ちの画像で実践してみましたが、そこそこ分類できることが確認できました。
背景画像も写り込んでいる中で、物体を認識する能力の高さがわかりました。
ディープラーニングは奥が深いので、今後も順次チュートリアルを解析しつつ、その魅力に迫っていきたいと思います。