机器学习与伦理之谈
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
这是is开发者网站Advent日历2024第25天的文章。
我是江川。我是一名从事机器学习的软体工程师。
江川崇先生是一位专注于机器学习领域的软件工程师。由于他是is的前成员,也因此有幸请他来为Advent日历撰写文章。
江川先生以其众多著作和翻译作品而闻名,其中与本文密切相关的是,他翻译的书籍《机器学习系统设计》于去年由O'Reilly Japan出版。
在机器学习中,数据是一个不可分割的重要元素。然而,数据的处理非常复杂,尤其在伦理和隐私方面潜藏着许多风险。今天,我想通过介绍一些与机器学习数据相关的案例,与大家一起思考数据所涉及的问题。希望能为大家提供一些启发。请多多指教。
话说回来,今天是圣诞节。大家过得怎么样呢?今年只剩下短短的几天了,不知这一年对大家来说如何呢?是否挑战了些什么新事物呢?
挑战与Strava
#对我个人而言,今年的挑战是在6月左右开始跑步。由于以适度的节奏逐步坚持,这个习惯至今也没有间断。其结果是,我回到了15年前的体重,感觉身心都更加健康了。
说到跑步,有一个不可或缺的App,那就是 Strava。Strava是一项可以记录和分享活动的线上服务,可以通过图表和地图直观地记录每天跑了哪些路线以及跑步的速度。此外,还可以通过时间轴与其他用户分享这些数据。Strava于2009年在美国上线,目前在全球拥有约1亿名用户。
Strava收集的数据经过匿名化处理,并提供了用户常用路线的热力图。这项功能让用户可以了解哪些是热门的跑步路线。以下的图片展示了is所在的都厅前区域的全球热力图。

不过,曾在2018年,因Strava的全球热力图意外泄露了大量机密信息而引发了全球性的讨论。通过热力图,人们可以看到阿富汗的前线基地位置,或叙利亚俄罗斯作战区域的巡逻路线等,美国军队的活动因此被暴露[1]。以下图片展示了一则有关这一事实的发布内容。
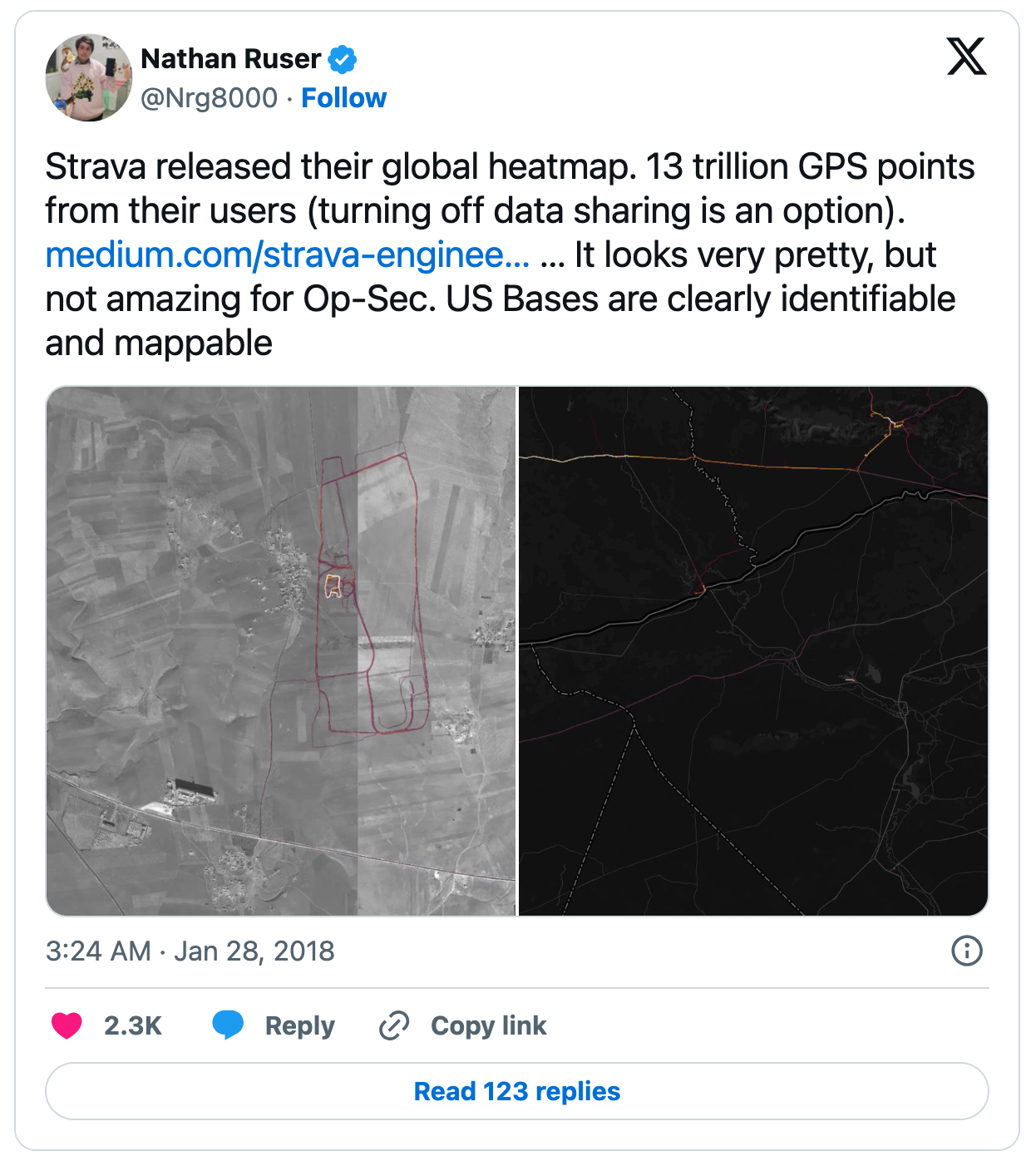
为何会发生这样的情况呢?原因在于许多军人日常进行训练并使用Strava记录活动的数据。最终,他们的活动数据不知不觉被纳入了大数据中。
作为一名从事机器学习的软件工程师,我能说的是,良好的数据对机器学习至关重要。开发机器学习系统极大程度上依赖于数据的质量,因此用户数据的收集尤为重要。然而,在收集或共享数据集时,总会伴随侵害用户隐私或安全的潜在风险。
虽然Strava并未直接公开私人信息,所收集的数据也都经过匿名处理,无法直接识别个人身份,但这已经充分表明了数据收集隐藏的各种潜在风险。
在训练机器学习模型时,有人可能认为“数量至上”,也就是说数据越多越好。尽管并非绝对如此,但在一定规模的数据量上,确实是许多从事机器学习工作的人所面临的共识和挑战。然而,在不侵犯数据伦理或隐私的前提下进行数据收集,实际上困难重重。
大规模数据集中潜藏的偏见
#那么,使用那些全世界众多开发人员和研究人员常用的著名数据集,是否就安全无虞呢?答案并不是绝对的。
即使是全球知名的图像数据集 ImageNet,其也曾被指出存在伦理方面的问题[2]。
像ImageNet这样的庞大数据集之所以对机器学习有用,在于其不仅包含大量图像,还为这些图像提供了类别标签或元数据。而一项名为 ImageNet Roulette 的研究项目,以ImageNet为对象进行了一次反思。ImageNet Roulette是一个网页,人们可以上传人物图片,然后通过使用ImageNet训练的机器学习模型对这些图像进行分类。

来自ImageNet Roulette
此前有人指出ImageNet中的部分标签涉及外貌、种族、民族背景和性别等存在问题的分类。ImageNet Roulette旨在通过这些问题分类,让普通大众直观地感受到:模型的判断如何受到不恰当类别的影响,以及这种偏见会如何被再生产。比如,当上传泳装照片时,会将人标记为“荡妇(slut)”,而上传戴墨镜的孩子的照片时,则标注为“失败者(loser)”或“一无所成之人(non-starter)”。因此,这个网站上线后不久,由于提供了冒犯性标签和歧视性分类结果,引发了巨大的争议。
然而,这并不意味着有人恶意地对ImageNet进行了主观分类。ImageNet的构想来源于WordNet项目,后者是一个旨在提供词汇概念的字典项目,拥有反映概念关系和关联的层次结构。然而,一些在1980年代被认为是合理的概念,在当今社会已无法被接受。
这一事件使人们重新认识到: “即使是著名且广泛使用的数据集,也不能盲目地认为绝对安全”,以及 “在中立地收集和组织数据方面存在的难题”。
谁在遭受损害?
#从反映人类社会偏见和先入为主的数据中训练出的机器学习模型,往往会让社会处于弱势地位的人群受到损害。在社会保障或公共政策领域使用时,这一点需要特别注意,并已多次成为引发重大问题的原因。
澳大利亚的案例
#澳大利亚的政府机构Centrelink(类似于日本的厚生劳动省)面临福利补贴过度分配的问题。然而,由于人力不足,他们开发了一种名为“Robodebt”的AI债务检测系统并投入使用。不料,该系统在圣诞节期间向大量合法领取福利的人错误地发送了债务通知[3]。
受益者突然收到通知,称由于多支付福利产生债务并被要求偿还。然而,对于为何被判定为过度支付却百思不得其解。当他们向Centrelink咨询时,却被告知“系统根据数据做出了适当的判断,债务已移交至债权回收公司,因此请直接与其联系。”更糟的是,债权公司对受惠者进行了恐吓性催收。
这种“错误的债务通知”让受益者承受了巨大的精神痛苦及经济压力,并在国内引发了广泛的社会讨论。2020年,通过集体诉讼,最终政府让步,不仅退还错收的金额,还对受到损害的受益者进行了赔偿。
英国的案例
#2020年,因为新冠疫情蔓延影响,英国取消了具有决策性意义的“A-level考试”。负责大考中心运作的Ofqual宣布,通过AI算法自动算出考试成绩并作定量。然而,分数的结果主要依赖于学校历史数据(注优劣学校校偏担}).
Mashable - Strava’s fitness heatmap has a major security problem for the military https://mashable.com/article/strava-fitbit-fitness-tracker-global-heatmap-threat ↩︎
WIRED.jp - AIによる人物写真のラベリングは、どこまで適切なのか? ある実験が浮き彫りにした「偏見」の根深い問題 https://wired.jp/2019/11/27/viral-app-labels-you-isnt-what-you-think/ ↩︎
New Matilda - High Farce: The Turnbull Government’s Centrelink ‘Robo-Debt’ Debacle Continues To Grow https://newmatilda.com/2017/01/06/the-turnbull-governments-centrelink-robo-debt-debacle-continues-to-grow/ ↩︎