超简单!使用 OpenSearch MCP 扩展 Claude Code 的可搜索性
Back to Top为了覆盖更广泛的受众,这篇文章已从日语翻译而来。
您可以在这里找到原始版本。
引言
#本文为 2025 年夏季接力连载的第 2 篇。
我是业务解决方案事业部的塚野。
Claude Code 在过去几个月里爆发性普及,我最近终于引入后,其强大功能令我大吃一惊。
以 Claude Code 为代表的 Agentic AI 会将指定的文件或文件夹纳入「上下文」进行管理。所谓上下文,可视作 Agentic AI 的「认知范围」,包括用户的输入和对话、任务历史,以及加载的文件或从 API 获取的信息等。借此,Agentic AI 能生成针对特定项目的回答,并根据回答内容执行任务。
通过指定文件夹或文件路径,也可以将它们直接纳入上下文。但是,当文件数量过多、体积过大或内容过于庞大时,可能无法完成纳入,或者会消耗大量 Token 而很快达到服务的速率限制。再者,信息量过剩也会导致 LLM 难以生成恰当的回答。
此外,也会有想要访问保存在 Google Drive 上的文档,或在 GitHub、Subversion 等仓库中管理的源代码的场景。不过,这类外部信息无法直接纳入上下文,需要先将其保存到本地等加以处理。
作为一种能够让 Agentic AI 访问此类无法直接访问的信息,并大幅扩展搜索能力的方法,本文推荐使用 OpenSearch MCP。
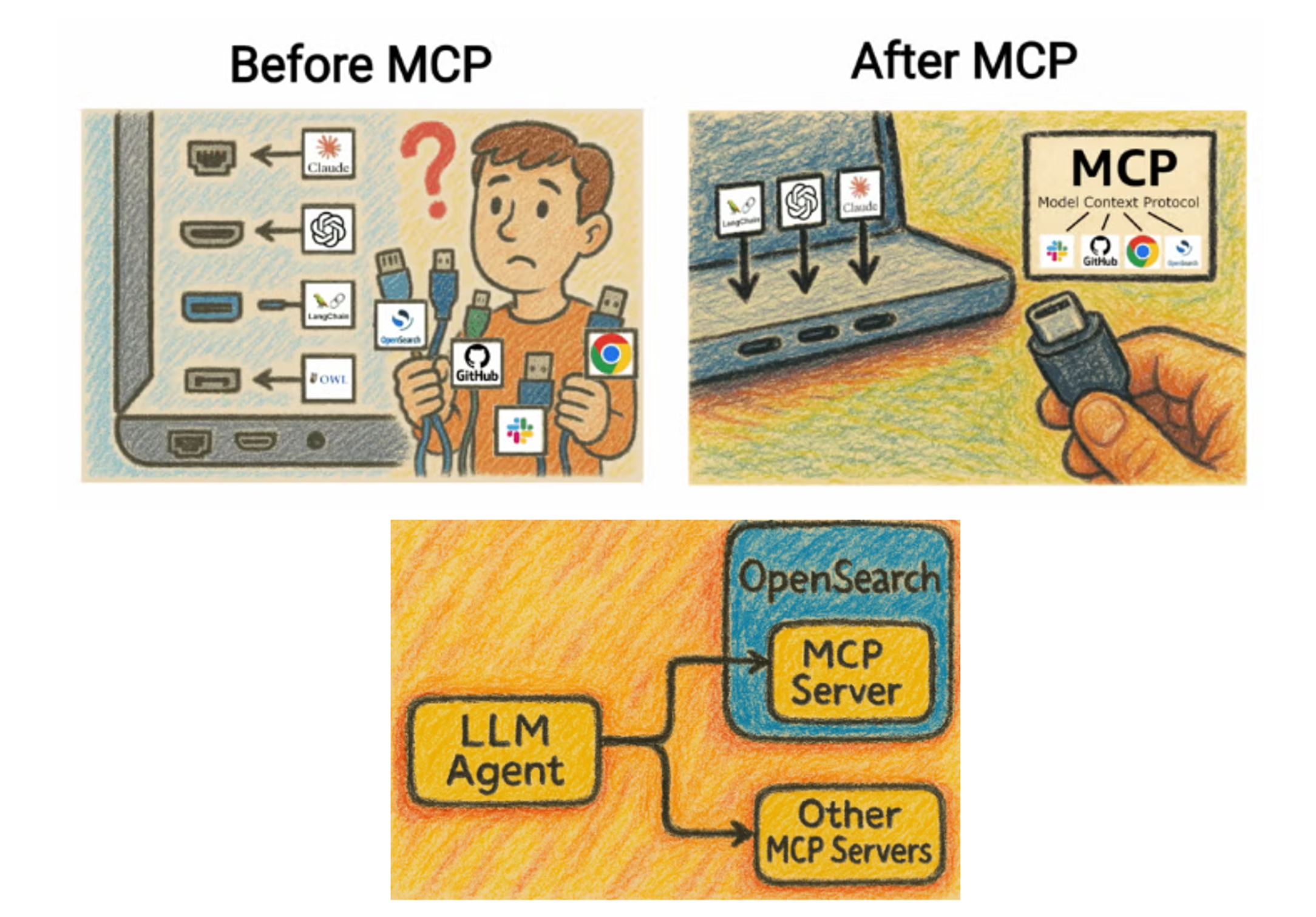
节选并修改自 OpenSearch 官方文档。MCP 常被比作统一平台的 USB-C。
MCP 即 Model Context Protocol(模型上下文协议)的缩写,是 Claude Code 等 Agentic AI 与外部服务联动的平台。通过 MCP,Agentic AI 可以操作外部服务,执行更高级的任务。
OpenSearch 是一个开源的分布式搜索与分析引擎,支持高速全文检索、日志分析、实时数据可视化等多种应用场景。此外,从版本 2.11.0 起支持基于 k-NN(k-Nearest Neighbors)及近似 k-NN 的向量搜索。
从 3.0.0 版本开始,OpenSearch 原生支持 MCP。它内置了本地 MCP 服务器,只需在配置中启用 MCP 服务器,就可将该 OpenSearch 实例直接用作本地 MCP 服务器。
利用 OpenSearch MCP 可让 Agentic AI 在无需复杂环境搭建的情况下访问外部数据,更高效、灵活地搜索文档和源代码。
前提条件
#本文将介绍如何以 Docker 容器方式启动 OpenSearch 实例,启用 MCP 服务器,并从 Claude Code 进行连接的全过程。
此外,在创建 OpenSearch 索引时,我们将使用开源全文搜索服务 FESS。
FESS 以 OpenSearch 作为搜索引擎,通过 GUI 操作即可轻松创建索引。
借助 FESS,可轻松配置从 GitHub 仓库等各种来源的爬取,FESS 本身也可作为全文搜索服务使用。
本次将以 GitHub 仓库为例,介绍从爬取到让作为 Agentic AI 的 Claude Code 访问的全过程。
所使用的 Agentic AI 由于 MCP 配置通用,因此除了 Claude Code,还可用相同步骤在 Cursor、Claude Desktop 等工具中使用。
本次使用的软件版本如下:
- OpenSearch: 3.0.0
- FESS: 15.0.0
- Docker: 27.3.1
另外,作者的环境为 Windows,Docker 在 WSL2(Ubuntu 22.04)上运行。
启动 FESS + OpenSearch
#首先,启动 FESS 和 OpenSearch 的 Docker 容器。
启动使用 docker compose。compose 文件由 FESS 提供方 codelibs 发布,可直接使用。
通过以下命令将 compose.yaml 和 compose-opensearch3.yaml 下载到项目目录:
$ curl -O https://raw.githubusercontent.com/codelibs/docker-fess/refs/tags/v15.0.0/compose/compose.yaml
$ curl -O https://raw.githubusercontent.com/codelibs/docker-fess/refs/tags/v15.0.0/compose/compose-opensearch3.yaml
编辑 compose-opensearch3.yaml,启用 MCP 服务器。实际上只需添加一行。
services:
search01:
image: ghcr.io/codelibs/fess-opensearch:3.0.0
container_name: search01
environment:
- node.name=search01
- discovery.seed_hosts=search01
- cluster.initial_cluster_manager_nodes=search01
- cluster.name=fess-search
- bootstrap.memory_lock=true
- node.roles=cluster_manager,data,ingest,ml
+ - plugins.ml_commons.mcp_server_enabled=true
- "OPENSEARCH_JAVA_OPTS=-Xms1g -Xmx1g"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- "FESS_DICTIONARY_PATH=/usr/share/opensearch/config/dictionary"
...
就这些。
完成编辑后,设置 OpenSearch 启动所需的参数。
$ sudo sysctl -w vm.max_map_count=262144
vm.max_map_count=262144
OpenSearch 启动要求将该 vm.max_map_count 值设为不低于 262144。
若 OpenSearch 实例启动失败,可先通过以下命令检查该值,默认应为 65530。
$ cat /proc/sys/vm/max_map_count
vm.max_map_count = 65530
使用以下命令启动 FESS 与 OpenSearch 容器:
docker compose -f compose.yaml -f compose-opensearch3.yaml up -d
启动后,访问以下 URL,确认 FESS 的首页已正常显示:
http://localhost:8080/
至此,OpenSearch 端的准备工作完成。在创建索引前,接下来先确认能从 Claude Code 连接至 OpenSearch 的 MCP 服务器。
Claude Code 的 MCP 服务器配置
#Claude Code 通过配置文件管理可用的 MCP 服务器。不同配置文件作用域各异 (MCP 安装作用域 - Anthropic)。
本次使用项目作用域配置。在该作用域下,创建的配置文件可被其他 Agentic AI 共用。
在项目根目录下创建 .mcp.json,并写入以下内容:
{
"mcpServers": {
"opensearch": {
"command": "uvx",
"args": ["test-opensearch-mcp"],
"env": {
"OPENSEARCH_URL": "http://localhost:9200"
}
}
}
}
由于本次将 OpenSearch 实例作为测试/本地使用,已在 compose-opensearch3.yaml 中通过 "DISABLE_SECURITY_PLUGIN=true" 禁用安全插件。
安全插件提供索引加密或 API 用户认证等功能。
若需启用安全插件,需要在 .mcp.json 中添加认证信息。详情请参阅 此处 文档。
此外,args 可填写任意字符串。
MCP 服务器启动使用 uvx。如未安装 uvx,可通过以下命令安装 Python 包管理工具 uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
至此,Claude Code 已可连接至 OpenSearch MCP 服务器。
立即启动 Claude Code,确认能否连接至 MCP 服务器。
本文不赘述 Claude Code 的安装配置,因与 VSCode 集成十分便捷,此处假定在 VSCode 中启动。
启动 Claude Code 后,若添加了 MCP 服务器,界面将显示如下信息:
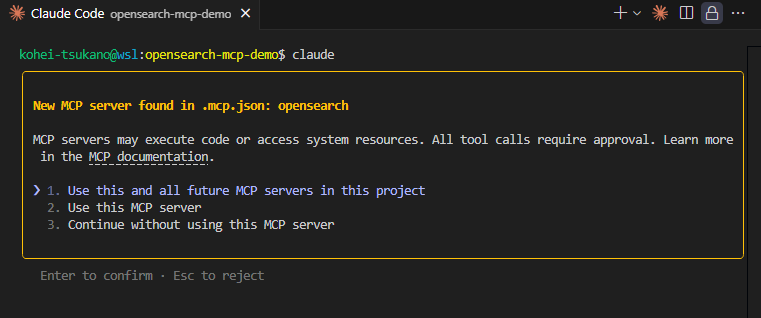
Claude Code MCP 服务器首次设置时的确认对话框
选择 “Use this and all future MCP servers in this project”。此项目中即可使用配置文件中指定的 MCP 服务器。
然后在提示符中请求测试与 OpenSearch 的连通性。
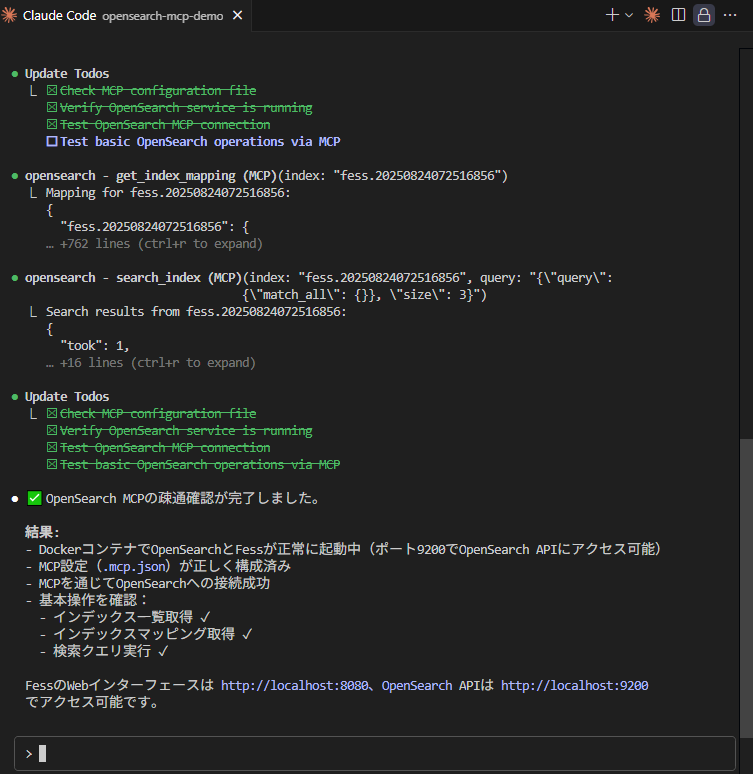
可以看到已可使用 get_index_map、search_index 等命令,确认已连接至 OpenSearch MCP 服务器。
创建索引
#在确认 Claude Code 已连接至 OpenSearch MCP 服务器后,接下来创建索引并实际让 Claude Code 进行搜索。
既然标榜「超简单!」,我们先对一个易于配置的 GitHub 仓库执行爬取并尝试搜索。
本次爬取的 GitHub 源代码为本文也使用的开源全文搜索服务 FESS。
索引通过 FESS 管理界面创建。访问 FESS 管理界面,只需在 FESS URL 后加上 /admin。
http://localhost:8080/admin
用户名为 admin,初始密码同样为 admin。
首次登录时系统会要求修改密码,请更改为任意密码。
由于从 GitHub 爬取需要插件,需在 FESS 管理界面中安装插件。
登录管理界面后,在侧栏依次点击「系统」>「插件」>「安装」,进入插件安装页面,
在「远程」选项卡中选择插件「fess-ds-git-xx.xx」,点击「安装」即可将插件安装到 FESS。
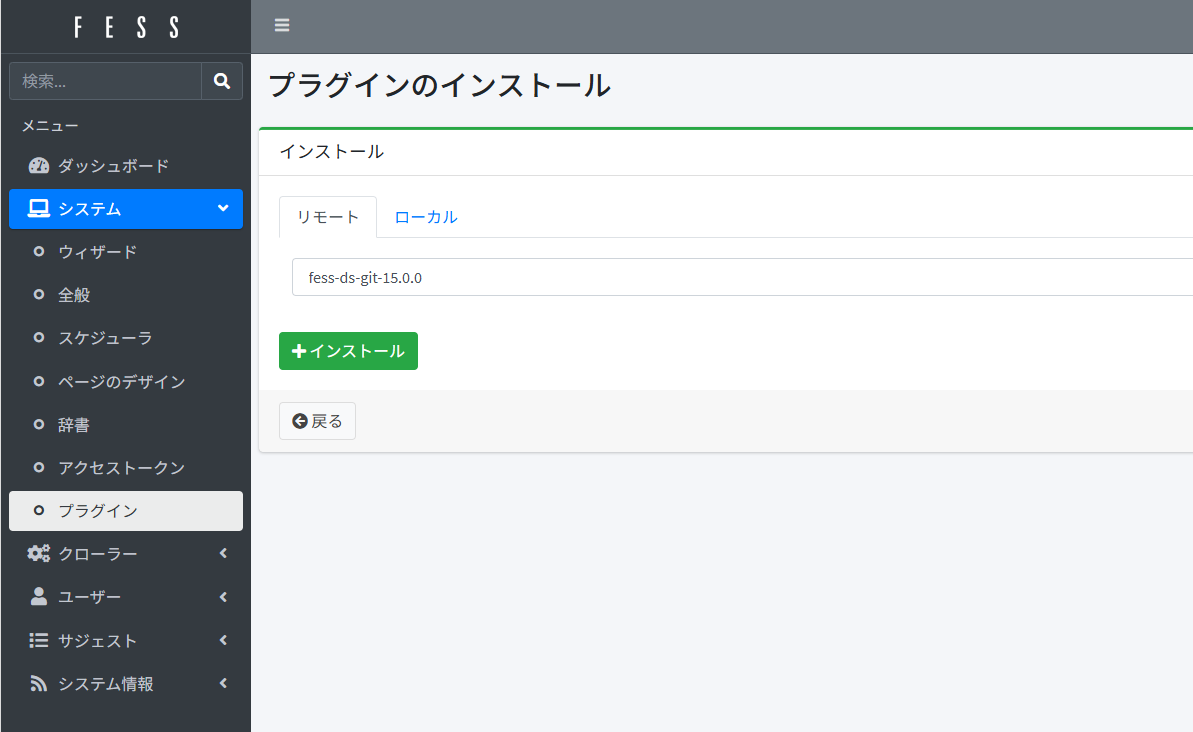
接着,在侧栏点击「爬虫」>「数据存储」,进入爬虫设置页面,然后点击「新增」按钮。
在设置页面按如下填写:
- 名称:任意(本例命名为「fess-github」)
- 处理器名称:GitDataStore
- 参数:
uri=https://github.com/codelibs/fess.git
base_url=https://github.com/codelibs/fess/blob/master/
extractors=text/.*:textExtractor,application/xml:textExtractor,application/javascript:textExtractor,application/json:textExtractor,application/x-sh:textExtractor,application/x-bat:textExtractor,audio/.*:filenameExtractor,chemical/.*:filenameExtractor,image/.*:filenameExtractor,model/.*:filenameExtractor,video/.*:filenameExtractor,
delete_old_docs=false
- 脚本:
url=url
host="github.com"
site="github.com/codelibs/fess/" + path
title=name
content=content
cache=""
digest=content != null && contentLength > 200 ? content.substring(0, 200) + "..." : content;
anchor=
content_length=contentLength
last_modified=timestamp
timestamp=timestamp
filename=name
mimetype=mimetype
domain="github.com"
organization="codelibs"
repository="fess"
path=path
repository_url="https://github.com/codelibs/fess"
filetype=container.getComponent("fileTypeHelper").get(mimetype)
owner=""
homepage=""
根据要爬取的仓库不同,需要修改参数和脚本中的仓库域名(github.com)、组织名(codelibs)和仓库名(fess)。
若要爬取私有仓库,需要在参数中加入如下认证信息:
username=hogehoge
password=ghp_xxxxxxxxxxx
commit_id=main
目前 GitHub 已弃用密码认证,请在 GitHub 上生成 personal access token(PAT),并填入 password 字段。
此外,若将主要分支名从 master 改为其他名称,需要通过 commit_id 指定主要分支,否则无法获取 HEAD 提交。
如想了解可用的参数和脚本,请参考 FESS Git Data Store 仓库 (Git Data Store)。
其他字段保持默认即可。
点击「创建」按钮,保存设置。
最后,执行爬虫任务以开始爬取。
在侧栏依次点击「系统」>「调度器」,进入任务调度页面,选择「Default Crawler」。
点击「立即执行」开始爬取。
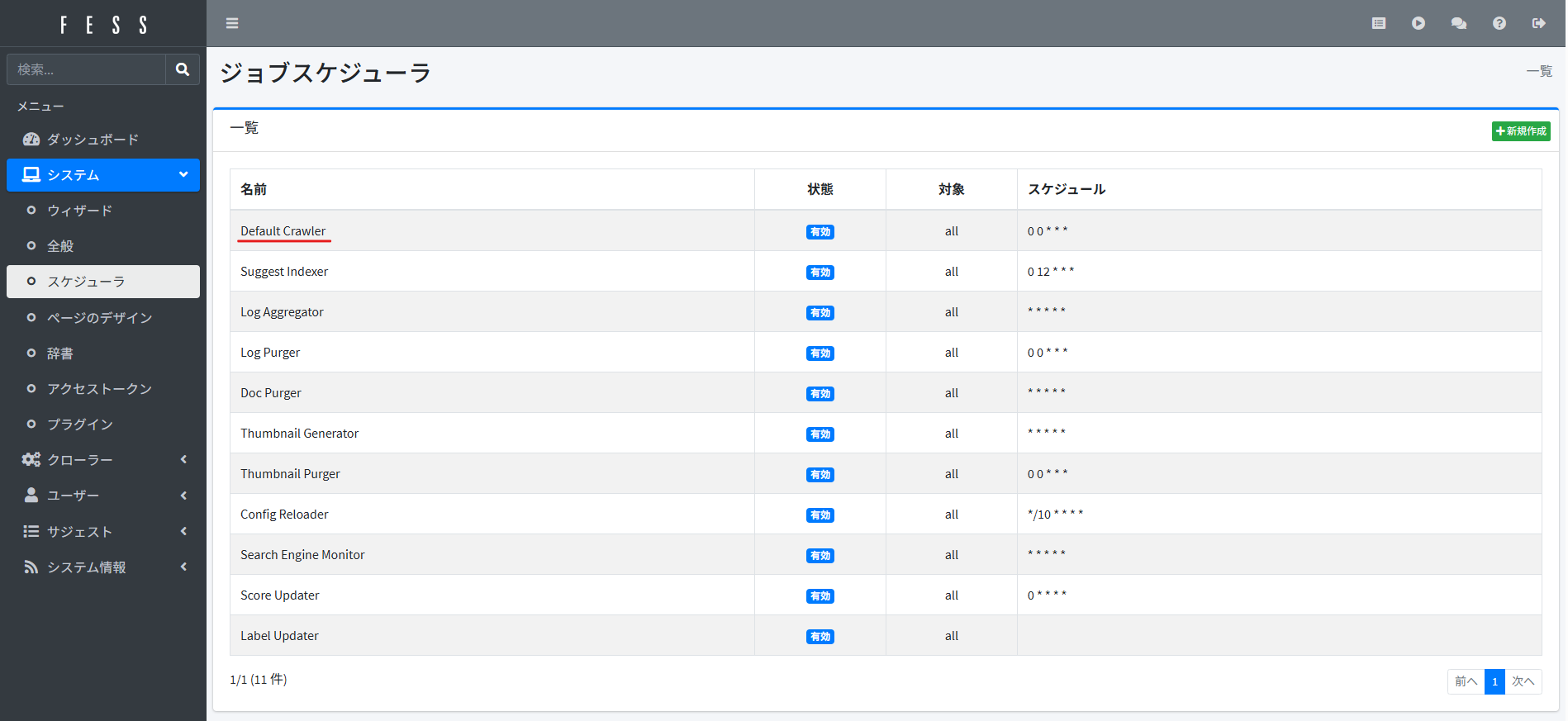
Default Crawler 会执行 FESS 中配置的全部[1]爬虫任务。
爬虫任务执行期间,调度器的「状态」会显示为「执行中」。请等待状态恢复为「已启用」[2]。
在 Claude Code 中搜索
#爬取完成后,用 Claude Code 进行搜索。
在 Claude Code 的提示框中输入以下内容,让它试着搜索 FESS 的源代码。
我想实现一个 regexp 前缀,使得在搜索查询中包含「regexp:模式」时可以进行正则表达式搜索。\
请从已连接的 MCP 服务器搜索 FESS 的源代码,帮我找出需要扩展哪一个类。
结果约在 1~2 分钟内返回如下:
若要在 FESS 中实现 regexp: 前缀,需要扩展以下类:
主要扩展点
1. RegexpQueryCommand (新建)
src/main/java/org/codelibs/fess/query/RegexpQueryCommand.java
- 继承 QueryCommand 以处理正则表达式查询
2. QueryStringBuilder (扩展)
src/main/java/org/codelibs/fess/util/QueryStringBuilder.java:177-193
- 在 appendConditions 方法中添加 regexp: 处理
- 与现有的 site:、filetype: 实现模式相同
3. RegexpQueryFilter (新建)
- 实现 QueryParser.Filter
- 从查询字符串中检测并转换 regexp: 前缀
4. 配置文件
- /src/main/resources/app.xml - 组件注册
- /src/main/resources/fess_config.properties - 添加配置
现有架构
FESS 已支持以下前缀,可按相同模式实现:
- site: - 站点搜索
- filetype: - 文件类型过滤
- sort: - 排序指定
- timestamp: - 时间戳过滤
在 QueryProcessor (src/main/java/org/codelibs/fess/query/QueryProcessor.java:67-70) 中注册命令,
在 QueryParser (src/main/java/org/codelibs/fess/query/parser/QueryParser.java:78-85) 中进行过滤链处理。
……太厉害了。它确实查看了现有实现,并对变更点提出了建议。因为并不需要增加搜索字段,似乎不需要编辑 fess_config.properties,但所需修改的 Java 文件等看起来很准确。
当询问它是如何调查的,以及使用了什么查询时,返回了如下回答。(部分改写)
1. MCP 服务器连通性确认
- 获取可用索引列表
- 通过 fess* 模式定位 FESS 相关索引
2. 数据存在性确认
- 确认 FESS 相关索引中存在数据
3. 源代码搜索(**使用 Task 工具**)
**向专用代理请求以下搜索任务**:
搜索对象:
- Java 源代码文件
- 与查询处理/解析相关的类
- 现有前缀处理机制
- 主查询处理管线类
推测代理执行的搜索查询:
- QueryParser - 查询解析核心
- QueryProcessor - 查询处理路由
- QueryStringBuilder - 现有前缀处理
- site: filetype: - 现有实现模式
- QueryCommand - 命令模式实现
- Filter - 过滤链实现
4. 架构分析
看来 Claude Code 即使没有给出具体的搜索关键词,也能自行构思查询并执行搜索。
另外,搜索处理使用了 Task 工具。这是 Claude Code 的一项功能,可以在接收用户提示后,除主代理外另行启动专用代理,自主并行地执行复杂任务。(What is the Task Tool in Claude Code - ClaudeLog)由此获取的信息会被主代理整合,并生成最终回答。
本次创建的专用代理在达到目标回答前,进行了多次探索式搜索。并且进一步调查发现,它不仅进行关键词搜索,必要时还会直接查看文件内容来生成回答。这是因为搜索结果中包含了仓库内的实际文件路径。
通过上述验证可知,Claude Code 对本地文件通常执行的文件搜索与文件内容详细解析操作,借助 OpenSearch MCP 也能轻松高效地应用于 GitHub 仓库中的文件。
总结
#本文介绍了如何将全文搜索引擎连接到 Claude Code 以扩展搜索能力。OpenSearch 还能用作向量数据库,因此可让 Claude Code 执行语义搜索或与全文搜索结合的混合搜索。例如,将文档采用语义搜索,将源代码采用关键词搜索并进行严格匹配[3],可能是一种不错的组合。
近年来,向量数据库的引入成本降低,Embedding 精度也不断提升,但要达到「超简单!」级别的入门门槛仍有差距。另一方面,如果 Agentic AI 能自行构思查询并进行探索式搜索,许多场景下仅靠全文搜索就足够,无需引入 RAG。此外,语义搜索(RAG)往往会将「回答的推导过程」变为黑盒,而全文搜索则具有可直接追踪搜索结果依据的优势。
让 Claude Code 使用全文搜索的另一个优势是可节省 Token。Token 的消耗取决于用户输入的提示和代理加载的文件等「发送给 LLM 的信息量」。Claude Code 在文件探查时会使用 grep 搜索,例如当匹配到 .log 这类精简压缩文件时,一行中包含的信息量巨大,仅读取就可能消耗大量 Token。而来自 OpenSearch MCP 的响应是结构化的 JSON 格式且为已索引信息,因此不会因搜索结果而大量消耗 Token。
本文中我们以 GitHub 仓库作为实验爬取对象,但在 FESS 中通过安装插件,还可将 Google Drive、Microsoft Share Point 等纳入爬取范围。这样,就能实现「先在 Google Drive 搜索设计文档,再根据其内容搜索 GitHub 源代码」等任务。有关 Google Drive 的爬取配置方法,请参考此文章。
此外,通过自制插件,FESS 也能扩展爬取对象及搜索功能。例如已自行编写官方未提供的用于爬取 Subversion 的插件,如果有机会,会撰写略显小众的插件开发及其他数据源爬取方法相关文章。
默认情况下,每类爬虫(数据存储、Web、文件存储)一次最多可执行 100 个爬虫配置。如需修改该上限,请在
fess01容器内的/etc/fess/fess_config.properties中分别调整page.data.config.max.fetch.size、page.web.config.max.fetch.size和page.file.config.max.fetch.size。 ↩︎若爬取失败,可在侧栏「系统信息」选项卡的「故障 URL」中查看失败的 URL 及堆栈跟踪;也可在「系统信息」的「日志文件」中查看日志,以便排查原因。 ↩︎
FESS 默认不区分大小写,并对 4 个字符以上的单词启用模糊搜索,因此并非严格意义上的精确搜索……。若在 FESS 容器内的
fess.json中将 analyzer 的 lowercase filter 设为不使用,则可实现大小写区分;此外,亦可在fess_config.json中指定query.boost.fuzzy.min.length=-1来关闭模糊搜索。 ↩︎