Super Simple! Extending Claude Code's Searchability with OpenSearch MCP
Back to TopTo reach a broader audience, this article has been translated from Japanese.
You can find the original version here.
Introduction
#This article is part of the Summer Relay Series 2025, Day 2.
I’m Tsukano from the Business Solutions Division. Claude Code has seen explosive adoption over the last few months, and after finally setting it up, I was truly blown away by its capabilities.
Agentic AI like Claude Code manages specified files or folders as “context.” Context is, in essence, the “cognitive scope” of the Agentic AI, including user inputs or conversations, task history, and information from loaded files or APIs. This allows Agentic AI to generate project-specific answers and execute tasks based on that content.
By specifying folder or file paths, you can directly incorporate them into the context. However, if you have many files, large files, or immensely large content, ingestion itself may fail, consume a huge number of tokens, and quickly hit service rate limits. Moreover, excessive information can make it difficult for the LLM to generate appropriate answers.
There may also be situations where you want to access documents stored on Google Drive or source code managed in GitHub or Subversion repositories. However, since such external information cannot be directly ingested into the context, you need to employ workarounds like saving it locally.
In this article, I’d like to recommend using OpenSearch MCP as a way to enable access to information that Agentic AI cannot directly reach, greatly extending search capabilities.
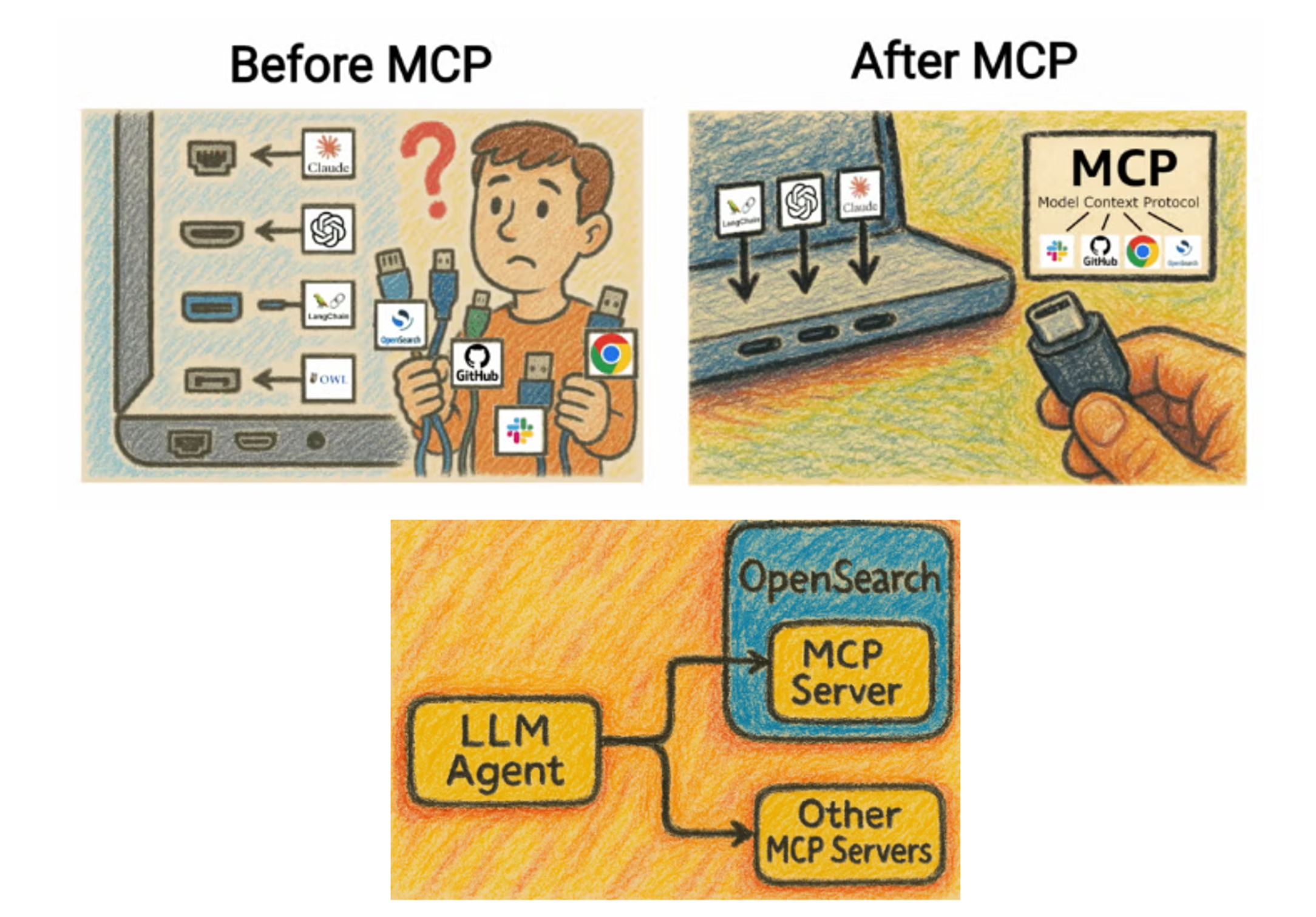
Excerpt and modified from the OpenSearch official documentation. MCP is often likened to USB-C as a unified platform.
MCP stands for Model Context Protocol, a platform for Agentic AI, such as Claude Code, to integrate with external services. By using MCP, Agentic AI can operate external services and perform more advanced tasks. OpenSearch is an open-source, distributed search and analytics engine that supports high-speed full-text search, log analysis, real-time data visualization, and various use cases. From version 2.11.0 onward, it supports vector search using k-NN (k-Nearest Neighbors) and approximate k-NN.
Starting with version 3.0.0, OpenSearch natively supports MCP. It includes a built-in local MCP server, and by simply enabling the MCP server in the settings, you can use an OpenSearch instance as a local MCP server.
By leveraging OpenSearch MCP, you can enable Agentic AI to access external data without complex environment setups and make documents and source code searchable more efficiently and flexibly.
Prerequisites
#In this guide, I’ll show how to start an OpenSearch instance as a Docker container, enable the MCP server, and connect from Claude Code. When creating an OpenSearch index, we’ll use FESS, an open-source full-text search service with a GUI that makes index creation simple. FESS uses OpenSearch as its search engine.
With FESS, you can easily configure crawls from various sources, including GitHub repositories, and use FESS itself as a full-text search service. In this article, we’ll use a GitHub repository as an example and walk through the steps to let Claude Code access it. The MCP settings are the same for other Agentic AI tools such as Cursor or Claude Desktop, so these steps should work there as well.
Software versions used in this article:
- OpenSearch: 3.0.0
- FESS: 15.0.0
- Docker: 27.3.1
My environment is Windows, running Docker on WSL2 (Ubuntu 22.04).
Starting FESS + OpenSearch
#First, start the FESS and OpenSearch Docker containers using Docker Compose. Download the compose files provided by codelibs:
$ curl -O https://raw.githubusercontent.com/codelibs/docker-fess/refs/tags/v15.0.0/compose/compose.yaml
$ curl -O https://raw.githubusercontent.com/codelibs/docker-fess/refs/tags/v15.0.0/compose/compose-opensearch3.yaml
Edit compose-opensearch3.yaml to enable the MCP server by adding just one line:
services:
search01:
image: ghcr.io/codelibs/fess-opensearch:3.0.0
container_name: search01
environment:
- node.name=search01
- discovery.seed_hosts=search01
- cluster.initial_cluster_manager_nodes=search01
- cluster.name=fess-search
- bootstrap.memory_lock=true
- node.roles=cluster_manager,data,ingest,ml
+ - plugins.ml_commons.mcp_server_enabled=true
- "OPENSEARCH_JAVA_OPTS=-Xms1g -Xmx1g"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- "FESS_DICTIONARY_PATH=/usr/share/opensearch/config/dictionary"
...
Next, set the vm.max_map_count parameter required by OpenSearch:
$ sudo sysctl -w vm.max_map_count=262144
vm.max_map_count=262144
OpenSearch requires vm.max_map_count to be set to at least 262144. If your OpenSearch instance fails to start, check the current value (default is usually 65530):
$ cat /proc/sys/vm/max_map_count
vm.max_map_count = 65530
Now start the FESS and OpenSearch containers:
docker compose -f compose.yaml -f compose-opensearch3.yaml up -d
After they’ve started, visit:
http://localhost:8080/
and confirm the FESS top page is displayed. This completes the OpenSearch side setup. Next, verify that Claude Code can connect to the OpenSearch MCP server.
Claude Code MCP Server Configuration
#Claude Code manages available MCP servers in a configuration file, and the scope depends on which file you create (MCP Installation Scope - Anthropic). We’ll configure it at the project scope, which can then be shared by other Agentic AI tools. Create a file named .mcp.json in your project root with the following content:
{
"mcpServers": {
"opensearch": {
"command": "uvx",
"args": ["test-opensearch-mcp"],
"env": {
"OPENSEARCH_URL": "http://localhost:9200"
}
}
}
}
Since we’re running this OpenSearch instance locally for testing, we disabled the security plugin in compose-opensearch3.yaml ("DISABLE_SECURITY_PLUGIN=true"). The security plugin provides features such as index encryption and API authentication. If you want to enable it, you’ll need to add authentication information in .mcp.json. For details, see the Authentication methods section. You can put any string in args.
To launch the MCP server, use uvx. If you don’t have uvx installed, install it via the Python package manager uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
Now Claude Code will be able to connect to the OpenSearch MCP server. Launch Claude Code—here, we assume you’re using VSCode integration. When you start Claude Code and it detects a new MCP server, you’ll see a confirmation dialog:
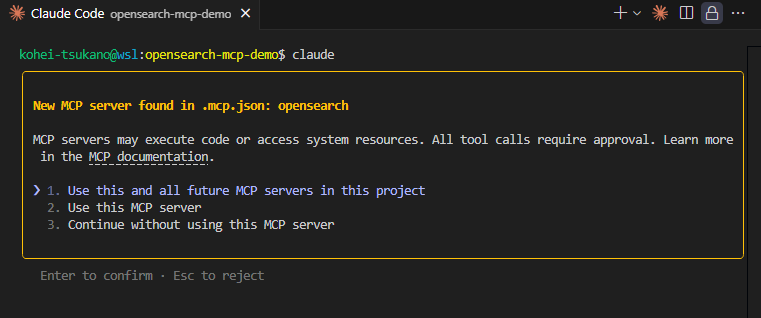
Claude Code MCP server initial setup confirmation dialog
Select “Use this and all future MCP servers in this project.” The MCP server you configured will now be available within this project. You can then try verifying connectivity to OpenSearch from the prompt.
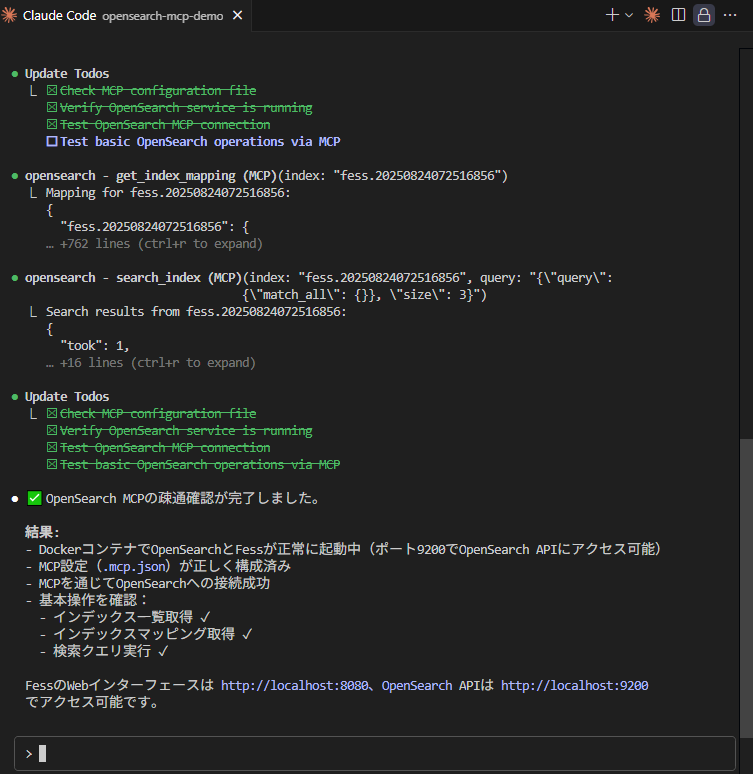
You should see that commands like get_index_map and search_index are available, confirming that you’re connected to the OpenSearch MCP server.
Creating an Index
#Once Claude Code is connected to the OpenSearch MCP server, let’s create an index and have Claude Code search it. To keep things “super simple,” we’ll crawl a GitHub repository that’s easy to set up and then perform searches.
In this example, we’ll target the open-source full-text search service FESS itself:
https://github.com/codelibs/fess
Create the index from the FESS management UI by navigating to:
http://localhost:8080/admin
Log in with username admin and initial password admin. You’ll be prompted to change the password on first login—choose any password you like.
To crawl from GitHub, you need to install a plugin. In the FESS admin UI, go to “System” > “Plugin” > “Install,” switch to the Remote tab, select the plugin fess-ds-git-xx.xx, and click “Install.”
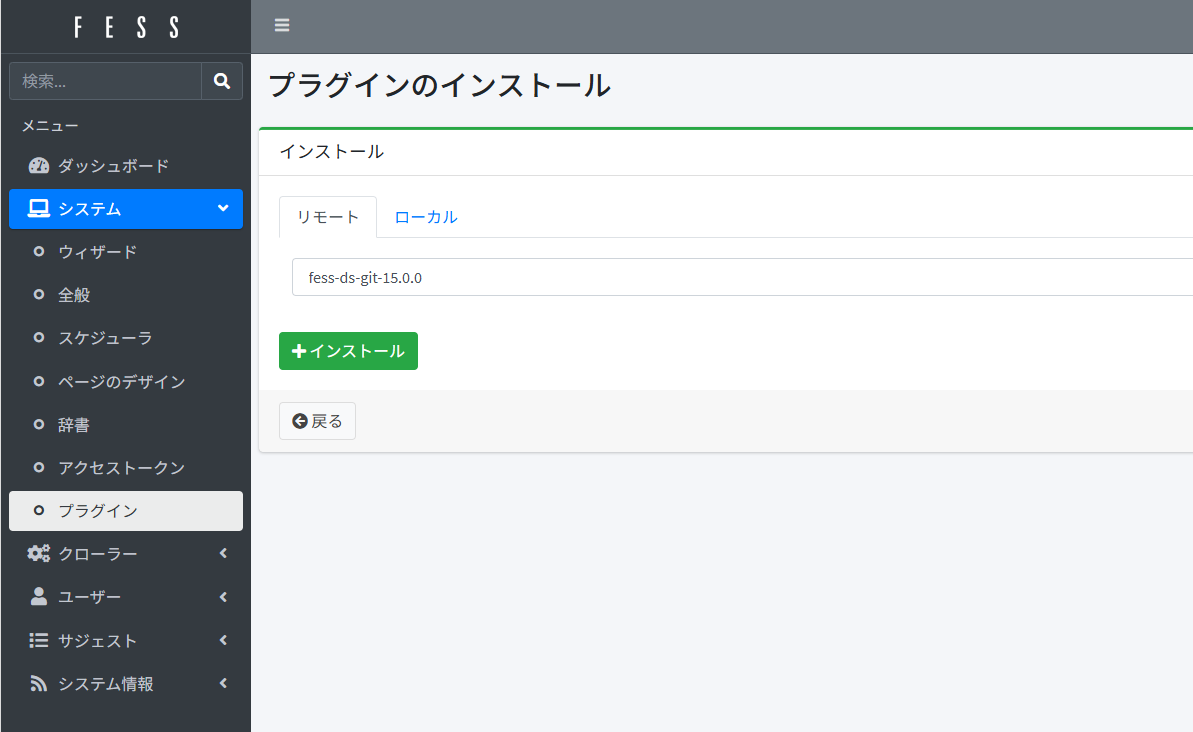
Next, go to “Crawler” > “Data Store” in the sidebar and click “New Add”:
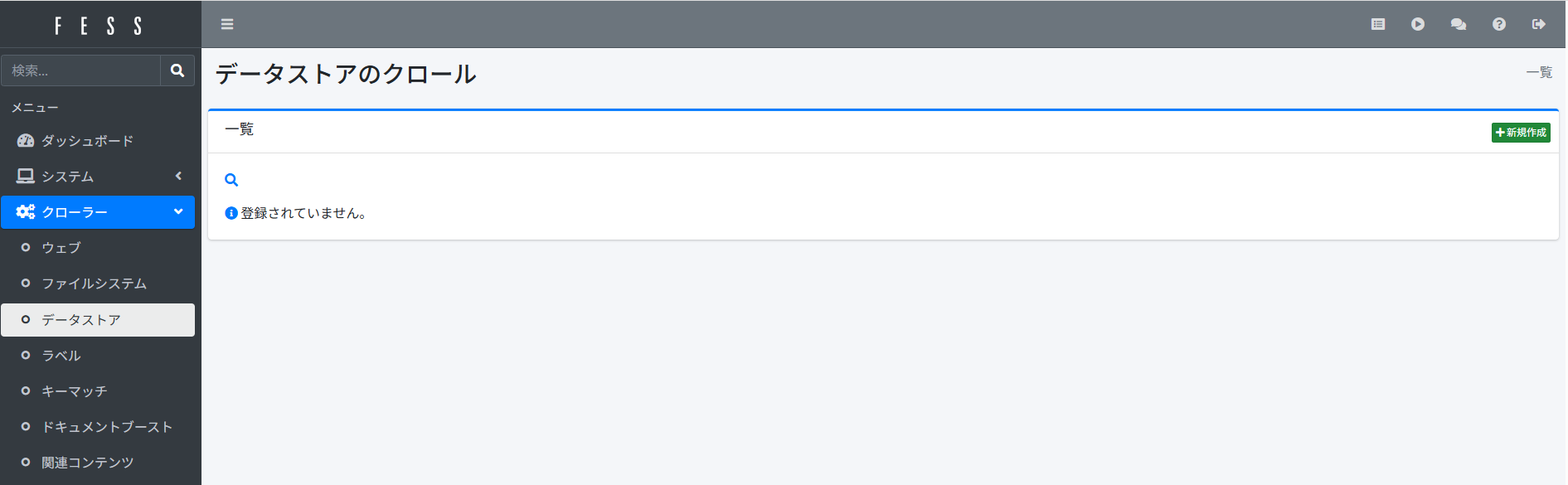
Enter the following:
- Name: Any name (e.g.,
fess-github) - Handler Name:
GitDataStore - Parameters:
uri=https://github.com/codelibs/fess.git
base_url=https://github.com/codelibs/fess/blob/master/
extractors=text/.*:textExtractor,application/xml:textExtractor,application/javascript:textExtractor,application/json:textExtractor,application/x-sh:textExtractor,application/x-bat:textExtractor,audio/.*:filenameExtractor,chemical/.*:filenameExtractor,image/.*:filenameExtractor,model/.*:filenameExtractor,video/.*:filenameExtractor,
delete_old_docs=false
- Script:
url=url
host="github.com"
site="github.com/codelibs/fess/" + path
title=name
content=content
cache=""
digest=content != null && contentLength > 200 ? content.substring(0, 200) + "..." : content;
anchor=
content_length=contentLength
last_modified=timestamp
timestamp=timestamp
filename=name
mimetype=mimetype
domain="github.com"
organization="codelibs"
repository="fess"
path=path
repository_url="https://github.com/codelibs/fess"
filetype=container.getComponent("fileTypeHelper").get(mimetype)
owner=""
homepage=""
Only the repository’s domain (github.com), organization (codelibs), and repository name (fess) need to be changed if you target a different repo. If you need to crawl a private repository, add authentication parameters:
username=your-username
password=ghp_xxxxxxxxxxx
commit_id=main
GitHub no longer supports password authentication; use a personal access token (PAT) in the password field. If you’ve changed your main branch name from master, specify it via commit_id to ensure you can fetch the HEAD commit. For more details on available parameters and scripts, see the Git Data Store repository.
Leave the other fields at their defaults and click “Create” to save the configuration.
Finally, run the crawler job. Navigate to “System” > “Scheduler” in the sidebar, select “Default Crawler,” and click “Run Now”:
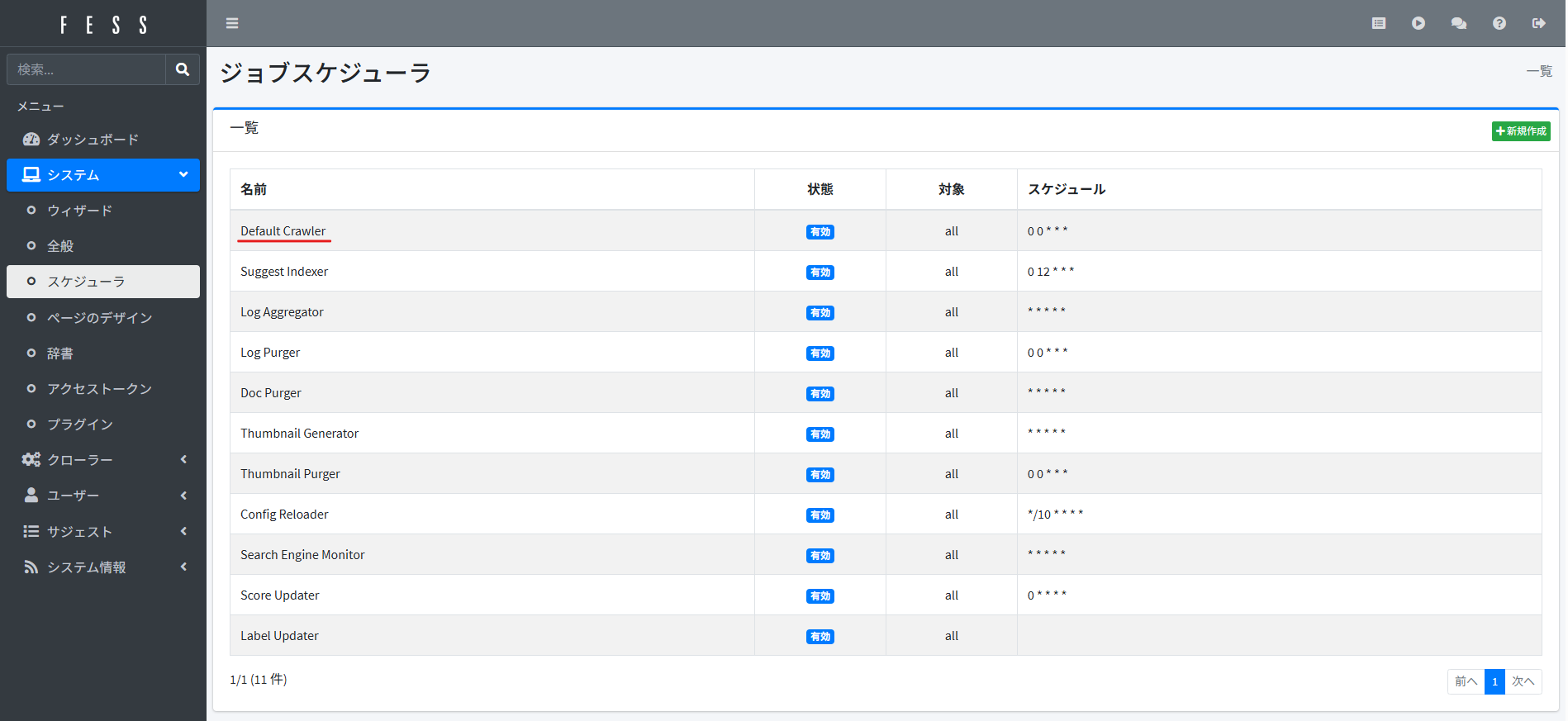
The Default Crawler executes all configured[1] crawler jobs in FESS. While the job is running, the scheduler’s “Status” will show “Running.” Wait until it returns to “Enabled.”[2]
Searching with Claude Code
#After the crawl completes, let’s have Claude Code perform a search. Enter the following in the Claude Code prompt:
I want to implement a regexp prefix that allows regular expression search by including "regexp:pattern" in the search query. \
Search the FESS source code from the connected MCP server and find out which classes to extend.
In about 1–2 minutes, you’ll get a response like this:
To implement the regexp: prefix in FESS, you need to extend the following classes:
Key extension points
1. RegexpQueryCommand (Create new)
src/main/java/org/codelibs/fess/query/RegexpQueryCommand.java
- Inherit from QueryCommand to handle regular expression queries
2. QueryStringBuilder (Extend)
src/main/java/org/codelibs/fess/util/QueryStringBuilder.java:177-193
- Add regexp: handling in the appendConditions method
- Follows the same implementation pattern as site: and filetype:
3. RegexpQueryFilter (Create new)
- Implement QueryParser.Filter
- Detect and transform the regexp: prefix from the query string
4. Configuration files
- /src/main/resources/app.xml – Component registration
- /src/main/resources/fess_config.properties – Add settings
Existing architecture
FESS already supports the following prefixes, which you can implement in the same pattern:
- site: – Site search
- filetype: – File type filter
- sort: – Sort specification
- timestamp: – Timestamp filter
Register the command in QueryProcessor (src/main/java/org/codelibs/fess/query/QueryProcessor.java:67-70) and chain the filters in QueryParser (src/main/java/org/codelibs/fess/query/parser/QueryParser.java:78-85).
...Amazing. It properly reviewed the existing implementation and proposed the changes. Since we’re not adding new search fields, editing fess_config.properties doesn’t seem necessary, but the Java files to modify look correct.
I then asked how it conducted the investigation and what queries it used, and received this response (slightly modified):
1. Confirm MCP server connection
- Retrieve the list of available indexes
- Identify FESS-related indexes using the fess* pattern
2. Confirm data existence
- Verify that the FESS-related indexes contain data
3. Source code search (**using the Task tool**)
**Request the following search task to a dedicated agent**:
Search targets:
- Java source code files
- Query processing and parsing related classes
- Existing prefix processing mechanisms
- Main query processing pipeline classes
Search queries the agent likely executed:
- QueryParser – core of query parsing
- QueryProcessor – routing of query processing
- QueryStringBuilder – existing prefix processing
- site: filetype: – existing implementation patterns
- QueryCommand – command pattern implementation
- Filter – filter chain implementation
4. Architecture analysis
It seems Claude Code was able to independently generate queries and perform the searches.
Also, it used the Task tool for the search process. This is one of Claude Code’s features that allows it to launch dedicated agents separate from the main agent handling the user’s prompt, to autonomously and concurrently execute complex tasks. (What is the Task Tool in Claude Code - ClaudeLog) The main agent then integrates the information obtained by these agents and generates the final response.
In this example, the dedicated agents performed exploratory searches repeatedly until they arrived at the desired answer. Furthermore, upon closer inspection, it appeared that they directly referenced file contents when needed, not just keyword searches. This is possible because the search results include the actual file paths within the repository.
From these tests, we can see that the operations Claude Code normally performs on local files—file search and detailed content analysis—can also be executed easily and efficiently on files in a GitHub repository using OpenSearch MCP.
Conclusion
#In this article, we introduced how to extend the searchability of Claude Code by connecting it to a full-text search engine. As mentioned at the beginning, OpenSearch can also serve as a vector database, allowing Claude Code to perform semantic search or a hybrid of semantic and full-text search. It might be a good approach to use semantic search for documents and keyword-based, exact-match search[3] for source code.
In recent years, the cost of introducing vector databases has decreased and embedding accuracy has improved, but I still feel that they have not yet reached the level of being “super easy!” to implement. On the other hand, if Agentic AI can come up with its own queries and perform exploratory searches, there are many cases where simply using full-text search without introducing RAG is sufficient. Moreover, in semantic search (RAG), the process through which answers are derived tends to become a black box, whereas with full-text search, you can directly trace the basis of the search results.
Another advantage of having Claude Code perform full-text search is token savings. Token consumption is determined by the amount of information sent to the LLM, such as user prompts and files loaded by the agent. Claude Code uses grep searches to explore files, but if a matched file is a minified file like .log, the amount of information per line can be enormous, potentially consuming a large number of tokens just by reading the file. On the other hand, responses from OpenSearch MCP are in a structured JSON format and contain indexed information, meaning you won’t consume a large number of tokens from the search results alone.
In this article, we experimentally crawled a GitHub repository, but with FESS plugins you can also crawl sources like Google Drive and Microsoft SharePoint. This allows you to request tasks like “search design documents in Google Drive and then search the GitHub source code based on them.”
Additionally, FESS allows you to extend crawl targets and search functionality by authoring custom plugins. For example, I’ve developed a plugin to crawl Subversion, which is not officially supported. If there is an opportunity, I would like to write articles on plugin development and methods for crawling other data sources, though this is a bit niche.
By default, the maximum number of crawler configurations that can be executed at once is set to 100 each for datastore, web, and filestore crawlers. To change these limits, modify
page.data.config.max.fetch.size,page.web.config.max.fetch.size, andpage.file.config.max.fetch.sizein/etc/fess/fess_config.propertiesinside thefess01container. ↩︎If a crawl fails, the failed URL and stack trace will be displayed under “Failed URLs” in the “System Information” tab in the sidebar. You can also view log files from “Log Files” in “System Information” to investigate the cause. ↩︎
FESS does not distinguish between uppercase and lowercase letters and, by default, has fuzzy search enabled for words of four characters or more, so it is not a strict search. However, you can enable case sensitivity by disabling the lowercase filter in the analyzer in
fess.jsoninside the FESS container. You can also turn off fuzzy search by specifyingquery.boost.fuzzy.min.length=-1infess_config.json. ↩︎