Using Ollama to Host an Open-Source LLM on localhost
Back to TopTo reach a broader audience, this article has been translated from Japanese.
You can find the original version here.
Introduction
#In this article, I will attempt to launch an open-source LLM on a local PC. There are already many types of open-source LLMs available – from models with a small number of parameters to recently popular inference models like DeepSeek-R1 from a Chinese company. I’m curious about what kind of responses they produce, so I plan to examine everything from the launch method to the output.
What is Ollama
#To launch an open-source LLM locally, we will be using a software called Ollama. It provides various tools for handling LLMs. Since it can run LLMs on the CPU even without a GPU, you can easily run models with a small number of parameters.
Installing Ollama
#- OS : Windows 10 (22H2)
- CPU Intel Core i7-1185G7
- Memory: 16GB
- Graphics Card: None
- GPU: Intel Iris Xe (integrated in CPU)
In this test, we will be using a Windows environment with CPU only.
First, install Ollama.
Download the Windows installer from the official website and install it.
Once the installation is complete, open Windows Terminal or Command Prompt and if you can successfully execute the following command, then the setup is complete.
$ ollama --version
ollama version is 0.5.7
Launching the LLM
#Now, let’s launch the LLM.
The command is simply ollama run followed by the model name.
You can find models that can be launched from ollama.com.[1]
For example, here we will launch the model Llama3.2 3B released by Meta.
$ ollama run llama3.2
pulling manifest
pulling dde5aa3fc5ff... 100% ▕████████████████████████████████████████████████████████▏ 2.0 GB
pulling 966de95ca8a6... 100% ▕████████████████████████████████████████████████████████▏ 1.4 KB
pulling fcc5a6bec9da... 100% ▕████████████████████████████████████████████████████████▏ 7.7 KB
pulling a70ff7e570d9... 100% ▕████████████████████████████████████████████████████████▏ 6.0 KB
pulling 56bb8bd477a5... 100% ▕████████████████████████████████████████████████████████▏ 96 B
pulling 34bb5ab01051... 100% ▕████████████████████████████████████████████████████████▏ 561 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help)
During the first launch, the model is downloaded, and if it completes without any issues, you will see the prompt waiting for input as shown above. The command interface is similar to Docker; in addition to the run command, there is also a pull command to download models and a push command to publish your customized models to ollama.com.
Now, let’s try a greeting.
>>> こんにちは
こんにちは!どういたしてお待ちしておりますか?
>>> すごいですね。
ありがとうございます!私はここからどんなことができますでしょうか?
Although there is a bit of odd Japanese, overall the responses were quite natural.
Next, I also asked a simple programming-related question.
>>> Javaのサンプルコードを出力してください
Java is an object-oriented programming language, so here is a sample code as an example.
### Example: Hello World!
In Java, you can create a basic "Hello World!" program like the following.
```java
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
```
This code uses `System.out.println` within the `main` method to output "Hello, World!".
### Example: Sum of Numbers
When you run a program like the following, it displays the sum of two numbers.
```java
public class Sum {
public static void main(String[] args) {
int num1 = 5;
int num2 = 10;
int result = num1 + num2;
System.out.println("数字の合計は" + result + "です。");
}
}
```
### Example: Assigning Values to an Expression
In the following program, a value is assigned to an expression and its result is output.
```java
public class Example {
public static void main(String[] args) {
int a = 5;
int b = 3;
int sum = a + b;
System.out.println("a + b = " + sum);
}
}
```
These code examples illustrate the basic structure and functionality of Java.
The source code is output correctly.
To end input mode, type /bye.
I found that simply launching a model registered on ollama.com is very straightforward.
Executing the REST API
#When you launch an LLM using Ollama, it also provides a REST API.[2]
After launching Ollama, open another terminal and you can ask questions by sending an HTTP request.
$ curl.exe http://localhost:11434/api/chat -d '{
>> ""model"": ""llama3.2"",
>> ""messages"": [
>> { ""role"": ""user"", ""content"": ""こんにちは"" }
>> ]
>> }'
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.0907887Z","message":{"role":"assistant","content":"こんにちは"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.1702247Z","message":{"role":"assistant","content":"!"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.2608251Z","message":{"role":"assistant","content":"どう"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.347122Z","message":{"role":"assistant","content":"いた"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.4304461Z","message":{"role":"assistant","content":"しま"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.5122336Z","message":{"role":"assistant","content":"して"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.5970052Z","message":{"role":"assistant","content":"?"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.698315Z","message":{"role":"assistant","content":" ("},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.7806767Z","message":{"role":"assistant","content":"Oh"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.8596621Z","message":{"role":"assistant","content":"ay"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.9427096Z","message":{"role":"assistant","content":"ou"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.0272743Z","message":{"role":"assistant","content":" go"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.124338Z","message":{"role":"assistant","content":"z"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.209143Z","message":{"role":"assistant","content":"aim"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.2949922Z","message":{"role":"assistant","content":"asu"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.3898005Z","message":{"role":"assistant","content":"!)"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.4850401Z","message":{"role":"assistant","content":" Would"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.5910074Z","message":{"role":"assistant","content":" you"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.6953205Z","message":{"role":"assistant","content":" like"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.7988221Z","message":{"role":"assistant","content":" to"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.8746928Z","message":{"role":"assistant","content":" chat"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.9631774Z","message":{"role":"assistant","content":" about"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.045542Z","message":{"role":"assistant","content":" something"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.1307175Z","message":{"role":"assistant","content":" in"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.2206491Z","message":{"role":"assistant","content":" particular"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.3027965Z","message":{"role":"assistant","content":" or"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.3878668Z","message":{"role":"assistant","content":" just"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.4735707Z","message":{"role":"assistant","content":" have"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.5559478Z","message":{"role":"assistant","content":" a"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.6429033Z","message":{"role":"assistant","content":" casual"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.724751Z","message":{"role":"assistant","content":" conversation"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.807616Z","message":{"role":"assistant","content":"?"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.8884414Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":4323876100,"load_duration":63547700,"prompt_eval_count":26,"prompt_eval_duration":1447000000,"eval_count":33,"eval_duration":2800000000}
Streaming output is the default, it seems.
There is also an endpoint that is compatible with the OpenAI API, which makes it quite user-friendly.
OpenAI compatibility
$ curl.exe http://localhost:11434/v1/chat/completions `
>> -H ""Content-Type: application/json"" `
>> -d '{
>> ""model"": ""llama3.2"",
>> ""messages"": [
>> {
>> ""role"": ""system"",
>> ""content"": ""あなたは優秀なアシスタントです""
>> },
>> {
>> ""role"": ""user"",
>> ""content"": ""ありがとう!""
>> }
>> ]
>> }'
{"id":"chatcmpl-377","object":"chat.completion","created":1739289063,"model":"llama3.2","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":"どういたしろ~?何かサポートしてあげることができることあるでしょうか?"},"finish_reason":"stop"}],"usage":{"prompt_tokens":38,"completion_tokens":20,"total_tokens":58}}
At this point, now that we understand how to launch a model and how to enter prompts, I’d like to try some models other than Llama3.2.
Inference Model (DeepSeek-R1)
#Let’s try the trending DeepSeek-R1. This model comes with an inference function that, similar to OpenAI’s o1 model, verifies the validity of its answer before responding to produce a more accurate response.
This model can also be easily launched via Ollama. (Model Link)
Launch the deepseek-r1 7B model with the following command.
$ ollama run deepseek-r1
Let's start with a greeting.
>>> こんにちは
<think>
</think>
¡Hola! ¿Cómo estás?
>>> 日本語で答えてください。
<think>
Alright, the user has switched from Japanese to Japanese again. They might be trying to see if I can handle
different languages or just being persistent.
Since they asked for a response in Japanese before and got one in English, this time they're asking me to respond
in Japanese. Maybe it's a test or they want consistent language support.
I should make sure my response is clear and friendly in Japanese, just like the previous message was in English.
</think>
こんにちは!
The initial "Hello" input did not get a response in Japanese. When I specified “please answer in Japanese”, it switched to Japanese—but the inference process was output in English. Also, perhaps because it’s an inference model, the inference process is output enclosed in a <think> block.
Next, let’s ask a simple programming-related question.
>>> Javaのサンプルコードを1つ教えてください。
Alright, the user asked for a sample Java code. I need to provide a simple and clear example that demonstrates good practices.
I'll create a program that calculates the sum of two integers because it's straightforward and covers basic input handling.
First, I'll write the code using modern Java syntax with classes and methods. Then, I'll add comments explaining each part so the user can understand what's happening.
Finally, I'll include instructions on how to run the code, like compiling and executing, to make it easy for the user to follow.
For example, the following sample Java code can be created.
```java
import java.util.Scanner;
public class SampleProgram {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.println("Enter your age: ");
int age = input.nextInt();
System.out.println("Thank you! Your age is: " + age);
}
}
```
**Explanation:**
1. **Important Point 1:** `import java.util.Scanner;`
- `Scanner` is a built-in Java library used for receiving input. It takes the user’s input from System.in.
2. **Important Point 2:**
- `public class SampleProgram`
- The class name is `SampleProgram`.
- `public static void main(String[] args)`
- `main` is the primary method of the program. `String[] args` handles command-line arguments.
3. **Important Section:**
- `Scanner input = new Scanner(System.in);`
- Creates a `Scanner` instance to obtain input from System.in.
- `System.out.println("Enter your age: ");`
- Displays a message prompting the user to enter their age.
- `int age = input.nextInt();`
- Converts the user’s input into an integer and stores it in the variable `age`.
- `System.out.println("Thank you! Your age is: " + age);`
- After the user enters their age, it is displayed.
**Execution Method:**
1. Execute the above code with `java SampleProgram`.
2. The screen will display "Enter your age: " prompting you to input your age.
3. The entered age is then displayed.
For example, if you input `5`, the screen will display:
```
Enter your age:
Thank you! Your age is: 5
```
Although some of the Japanese seems a bit awkward, it is impressive that a small model with 7B parameters is capable of providing such detailed and natural responses. There are also models with larger parameter counts (up to 671B), so if you have sufficient hardware, you can expect to obtain extremely accurate responses. ollama.com#deepseek-r1 Tag List
Japanese-Tuned Models
#The responses above had some issues with Japanese output. A version of the DeepSeek model that has been tuned for Japanese is available, so I'll try that as well. (One of the great aspects of an open-source LLM is that different people can create customized models based on the original.)
I found that models have been released for the following parameter counts:
7B model: lightblue/DeepSeek-R1-Distill-Qwen-7B-Japanese
14B model: cyberagent/DeepSeek-R1-Distill-Qwen-14B-Japanese
32B model: cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese
With Ollama, models must be in GGUF format, so we will use the versions converted to GGUF format from the models mentioned above.
GGUF versions of the models for each parameter count have been released as follows. (Many thanks to those who prepared them. 🙇♂️)
7B model: mmnga/lightblue-DeepSeek-R1-Distill-Qwen-7B-Japanese-gguf
14B model: mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf
32B model: mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese-gguf
On HuggingFace, which is hosting these model files, there is a feature that displays the launch command for Ollama. Click the "Use this model" button at the top-right of the page, select "Ollama", choose the desired quantization method, and then execute the displayed command.
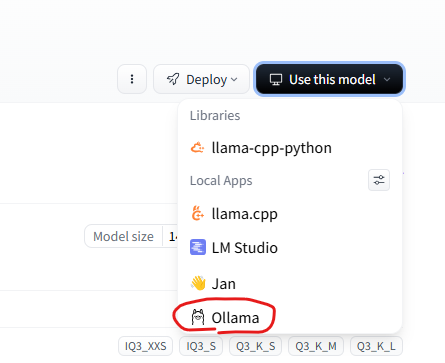
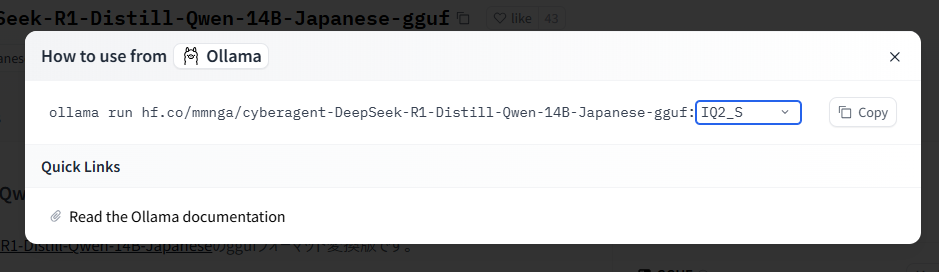
Quantization reduces the precision of some parameters, which decreases the model’s file size, but there is a trade-off with response accuracy. You need to determine the appropriate quantization method in accordance with your system’s memory capacity. For this model, you can refer to the file sizes of the various quantized models on the Files and versions tab on the HuggingFace page.
Now, execute the following command to launch the Japanese version of DeepSeek. In this case, I will choose the IQ2_S quantization method.
$ ollama run hf.co/mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf:IQ2_S
Let’s try a greeting and a simple question.
>>> こんにちは
First, the user said "Good morning" in Japanese. Initially, the reply was "Good morning!" in response to "Good morning", and then it responded with "Hello".
Considering the user’s intent, it seems they might have intended to only say "Good morning" initially, with the rest being a continuation. However, for some reason, the message might have been cut off mid-sentence—for example, due to a typing error or a system issue.
Next, I consider how to respond to "Hello". Since the other party is fluent in Japanese, an appropriate greeting is necessary. While typically replying with "Hello" is common, if the user sends "Hello" after already saying "Good morning", the flow requires careful handling.
Perhaps the user inadvertently entered something impolite. For instance, since the previous message was cut off, a proper and courteous response is needed. Here, it is important to provide a polite and friendly reply.
Additionally, considering the nuances of Japanese grammar and expressions, it is important to use the appropriate honorifics. When the user sends "Hello", it might be necessary to respond to both "Good morning" and "Hello". However, if the previous message was cut off, it could simply be that the user intended to send a second greeting.
Ultimately, the response should be a polite and friendly greeting that also checks if everything is okay. For example, one might reply with "Good morning! Hello, good morning! Are you alright?"—yet if the user sends "Hello" after the initial "Good morning", it’s important to acknowledge both.
**Reply**:
"Good morning!
Hello, good morning! Are you alright?"
**Thought Process:**
1. **Analysis of the User's Message**
- The user initially sent "Good morning" and then added "Hello", which might have been cut off.
- It is important to maintain immediate responsiveness and a natural conversational flow, so the initial greeting must be acknowledged as well.
2. **Characteristics of the Japanese Language**
- To naturally connect the previous "Good morning" with "Hello", a polite confirmation such as "Are you alright?" is added.
- The chosen text considers how the inference model handles fragmented or incomplete input while maintaining a friendly tone.
3. **User's Potential Needs**
- It aims to alleviate any stress from fragmented messages while maintaining a proper conversation pace.
- A polite response that balances automated replies with natural human conversation is crucial.
4. **Verification**
- The response handles both greetings, "Good morning" and "Hello", appropriately.
- Even in cases of abnormal input, adding a reassuring "Are you alright?" is designed to make the user feel at ease.
5. **Points for Improvement**
- In future responses, consider asking for additional information (e.g., about health or the weather) along with "Are you alright?" to better gauge the user’s intent.
- Adopt a response strategy that combines polite expressions with some flexibility to improve the model’s contextual understanding of Japanese.
**Conclusion:**
Even if the user’s message is fragmented, the reply should maintain a polite and friendly tone while keeping the natural flow of conversation. Balancing respectful expressions and thoughtful questions ensures the response is appropriate.
>>> Rustのサンプルコードを1つだけ教えてください
Now, the user is requesting a sample Rust code. First, we need to look at Rust’s basic syntax and characteristics and choose a simple example. For instance, beginning with a simple "Hello World" program is a good idea. Also, including important elements like type specification and reference/borrowing might make it easier to explain. It is necessary to determine whether the user is a Rust beginner or already has some experience and adjust the difficulty accordingly. Additionally, since an explanation in Japanese is required, it might be necessary to comment on each part of the code in an easy-to-understand way.
Here is a basic Hello World program in Rust:
```rust
fn main() {
println!("Hello, world!");
}
```
Features and explanation of this code:
1. `main()` function: The entry point at runtime
2. `println!` macro: A built-in function for output
3. Memory safety: Automatic management of references/borrowing
4. Stable language: Preventive measures provided by type inference and static typing
Explained in Japanese:
- `fn main()`: The execution part of the program
- `println!`: The built-in functionality for displaying information
- A simple example that embodies the characteristics of Rust
- A modern language equipped with stability and preventive type checks
Compilation Method:
Can be compiled with rustc 5.0 or later (for example, using `cargo build --release`).
The inference process was also output in Japanese. I think the increased parameter count has contributed to a more natural Japanese output. Although the inference process seems a bit excessive for a simple greeting like "Hello", it can be expected to produce even better responses for more complex tasks.
Vision Model (Llava-Phi3)
#Next, let’s try asking a question by providing an image along with the prompt using a vision model.
This time, we will use the model Llava-Phi3.
Let's ask a question along with the following image.

Source: いらすとや
When asking a question with an image, you can launch it with the following command.
$ ollama run llava-phi3 "この画像には何が書いてありますか? C:\develop\ollama\book_gijutsusyo_it_set_small.png"
Added image 'C:\develop\ollama\book_gijutsusyo_it_set_small.png'
1. AI (Artificial Intelligence)
2. Web (World Wide Web)
3. Programming
It is a simple response, but it returned an answer based on the content of the image.
Accelerating with GPU
#All of the tests above were executed using only the CPU.
Although the PC used had an integrated GPU in the CPU, by default Ollama did not utilize it—everything was executed in regular memory. Due to this limitation, I used models with a small number of parameters. It was a pleasant discovery, however, that reasonably accurate responses could still be obtained. (It seems that there is a way to enable recognition of Intel GPUs, so I’d like to try that sometime.)
Regarding response speed, in the tests above the Llama3.2 3B model took about 5 seconds to begin streaming its response, outputting roughly 10 tokens per second, which wasn’t too bothersome. On the other hand, the DeepSeek-R1 14B model felt slower, taking about 10 seconds to start its streaming response and outputting roughly 1–2 tokens per second. This made it feel like you had to wait quite a long time to see the complete output.
Since it is said that using a GPU can speed up LLM responses, I was curious to see just how much faster it could be, so I executed the DeepSeek-R1 32B model on a machine with the following specifications.
- OS: Windows 11
- Intel Core i9-10920X
- Memory: 32GB
- GPU: NVIDIA GeForce RTX 3060
- GPU Memory: 12GB
Simply installing Ollama and the NVIDIA driver was enough to enable GPU usage without any additional configuration. (If you have the machine, it’s very easy to speed things up, which is great.)
Conclusion
#In this article, I tried hosting an open-source LLM on localhost using Ollama. It was very simple to launch, and there are models that deliver natural responses even with a small number of parameters, making them promising for integrating into various software. Regarding GPU usage, it is clear that if you use NVIDIA hardware, it’s straightforward and quick to set up, whereas using Intel GPUs may require a few additional steps—which I’d like to try sometime.
The model list in the GitHub repository’s README also displays models along with their sizes in an easy-to-read list. ↩︎
https://github.com/ollama/ollama?tab=readme-ov-file#rest-api ↩︎