Using the Newly Updated File Search (Vector Stores) in OpenAI Assistants API(v2)
Back to TopTo reach a broader audience, this article has been translated from Japanese.
You can find the original version here.
Recently, there have been active updates to the OpenAI API (perhaps GPT-5 will be announced soon...). There was a major update to the Assistants API a little while ago.
Introducing a series of updates to the Assistants API 🧵
— OpenAI Developers (@OpenAIDevs) April 17, 2024
With the new file search tool, you can quickly integrate knowledge retrieval, now allowing up to 10,000 files per assistant. It works with our new vector store objects for automated file parsing, chunking, and embedding. pic.twitter.com/SL0gYknlyA
The version of the Assistants API has been updated to v2.
A particularly significant update is the file search function, previously introduced as Retrieval.
Using this feature, you can obtain optimal responses based on file search results from the assistant. This allows you to handle information that GPT has not learned, such as the latest information and confidential internal information[1].
In v2 of the Assistants API, a new API for Vector Store has been established, and its name has been changed to File Search.
Additionally, v1 (Retrieval) had a constraint of up to 20 files (each file up to 512MB/5 million tokens), and it was necessary to combine files to fit within these limits (huge datasets were not possible).
In v2, the number of files that can be registered has been significantly expanded to up to 10,000 files, making it usable in many use cases.
This time, I tried it out and will introduce it to you.
As of now, the Vector Store and even the Assistants API v2 itself are still in beta (eventually v1 became deprecated without reaching GA).
Please refer to the latest official documentation when actually using it.
Preliminary Preparation
#Here, we will upload some of the latest articles from this site to the Vector Store and try using the Assistants API.
The script is created in Node.js (TypeScript).
Install the following in any NPM project (TypeScript-related settings are omitted as they are not the main topic).
npm install openai
The OpenAI library used is currently the latest version 4.38.2. The v2 Assistants API has been available since 4.36.0.
Note that you are assumed to have already created an OpenAI API account and issued an API key.
Creating a Vector Store and Adding Files
#Let's create a new Vector Store.
In v1 Retrieval, knowledge files were uploaded (purpose=retrieval), and their file IDs were attached to the assistant.
In v2 File Search, instead of directly attaching files to the assistant, you attach a Vector Store.
Here is the code to create a Vector Store.
import OpenAI, { toFile } from 'openai';
const openai = new OpenAI({
apiKey: 'sk-xxxxxxxxxx' // OpenAI API key
});
const vectorStore = await openai.beta.vectorStores.create({ name: 'Blog Articles' });
console.log('vectorStoreId', vectorStore.id); // ID of the Vector Store to attach (vs_xxxxxxxxxxxxxxxxxxxxxxxx)
Now the Vector Store has been created. By attaching this Vector Store to an assistant or thread, you can use File Search.
Note that you will be charged for the size of this Vector Store in File Search (there is no charge at this point since no files have been added yet). Currently, File Search incurs a cost of $0.1 / 1GB per day (the first 1GB is free).
Here is an excerpt from the official documentation.
The file_search tool uses the vector_stores object as its resource and you will be billed based on the size of the vector_store objects created. The size of the vector store object is the sum of all the parsed chunks from your files and their corresponding embeddings.
You first GB is free and beyond that, usage is billed at $0.10/GB/day of vector storage. There are no other costs associated with vector store operations.
This means that you are charged based on the size of the Vector Store, so if you forget to delete a Vector Store created for testing purposes, unexpected costs may occur (if the size exceeds the free tier).
As mentioned in the official documentation, setting expires_after will cause the Vector Store to expire after a specified period of inactivity.
const vectorStore = await openai.beta.vectorStores.create({
name: 'Blog Articles',
expires_after: { anchor: 'last_active_at', days: 3 } // Expires 3 days after last use
});
Now, let's add files to the newly created empty Vector Store.
The following source code uploads blog articles (Markdown files) located in a specific directory to the Vector Store.
const articleDir = '/path/to/blogs';
const fileNames = (await fs.promises.readdir(articleDir))
.filter(name => name.endsWith('.md'));
const files = await Promise.all(fileNames
.map(fileName => toFile(fs.createReadStream(path.join(articleDir, fileName)))));
await openai.beta.vectorStores.fileBatches.uploadAndPoll(vectorStore.id, { files });
Inside uploadAndPoll, the following tasks are performed:
- File upload
- Attach files to the Vector Store
- Monitor (poll) until the Vector Store is ready to use
Files are not immediately usable upon attachment; you must wait for OpenAI to complete a series of preparations such as file chunking and vectorization.
Once the process is complete, you can see the Vector Store on the OpenAI dashboard (Storage -> Vector Stores toggle).
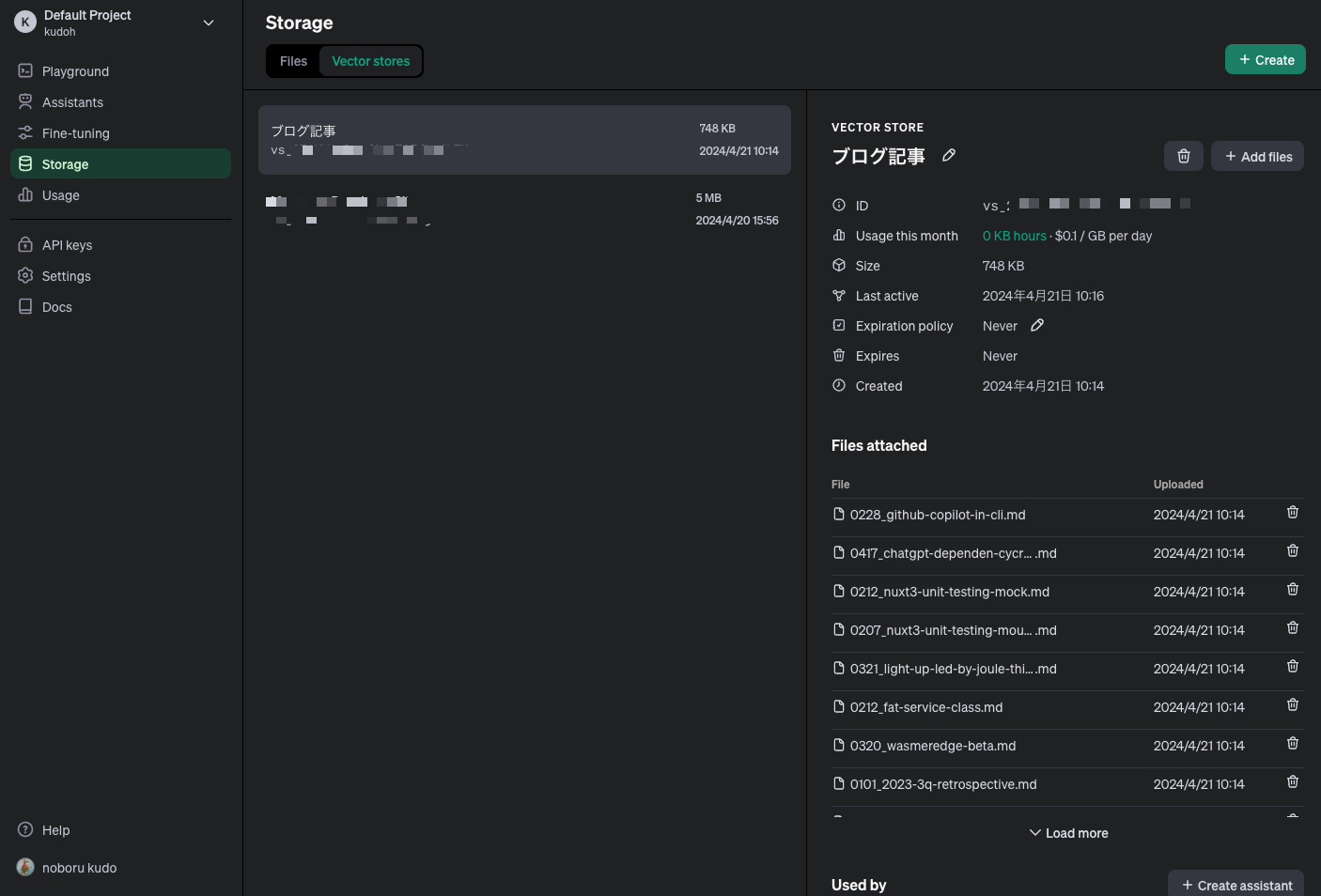
The Vector Store and the files stored there (about 40 files in this case) are displayed.
The size is 748KB, so it is within the free range (1GB).
Creating an Assistant
#Now let's attach the Vector Store we just created to an assistant and try using it.
const assistant = await openai.beta.assistants.create({
name: 'Blog Master',
model: 'gpt-4-turbo',
tools: [{ type: 'file_search' }], // retrieval -> file_search
tool_resources: { // Instead of file_id, add the Vector Store's ID
file_search: {
vector_store_ids: [vectorStore.id] // ID of the created Vector Store
}
}
});
The major difference is that the type specified in tools has changed from retrieval to file_search.
Also, whereas v1 specified the IDs of the search target files in file_ids, v2 adds the ID of the newly added Vector Store in tool_resources.file_search.vector_store_ids.
After execution, you can see on the OpenAI dashboard that the Vector Store has been attached to the created assistant.
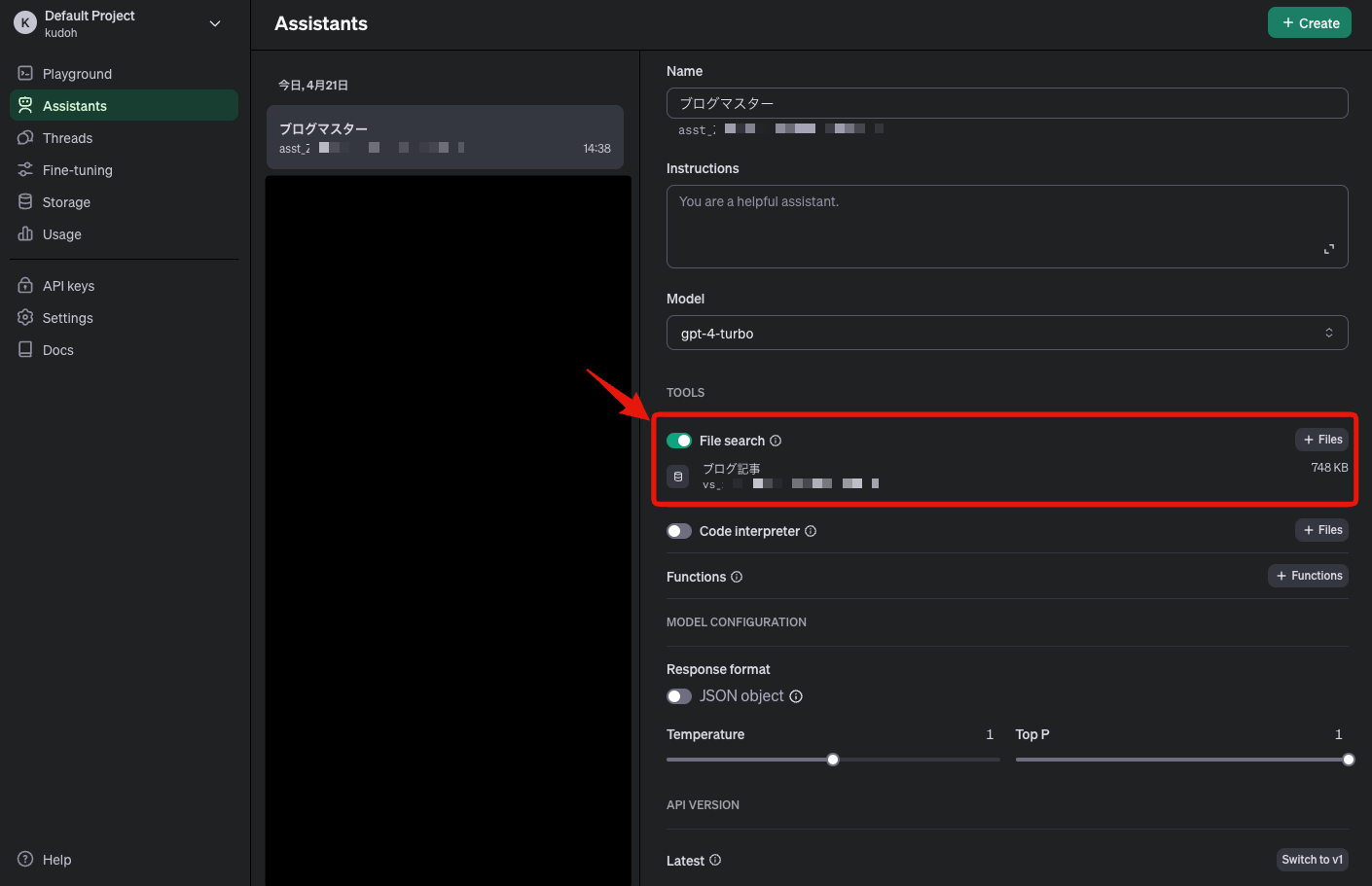
Here, we created the Vector Store in advance, but there is also a feature that allows you to create a Vector Store at the same time as creating an assistant.
The following source code uses this feature to create a Vector Store at the same time as creating an assistant.
const newFile = await openai.files.create({
purpose: 'assistants',
file: await toFile(fs.createReadStream('/path/to/file-A'), 'file-A')
});
const assistant = await openai.beta.assistants.create({
name: 'Blog Master',
model: 'gpt-4-turbo',
tools: [{ type: 'file_search' }],
tool_resources: {
file_search: {
// Directly specify the file ID
vector_stores: [{
file_ids: [newFile.id]
}]
}
}
});
Instead of the Vector Store's ID, the tool_resources.file_search.vector_stores specifies the ID of the file to be registered.
Creating and Running a Thread
#This part has not changed from before. Let's chat with the assistant about the contents of the uploaded files.
Currently, I will ask about OpenAI's batch API, which is not available in GPT-4 Turbo.
The following article file is expected to be searched:
The source code is as follows.
// Create a thread
const thread = await openai.beta.threads.create({
messages: [
{
role: 'user',
content: 'When was the OpenAI batch API announced? Tell me the details'
}
]
});
// Execute & poll the thread
const run = await openai.beta.threads.runs.createAndPoll(thread.id, {
assistant_id: assistant.id
});
// Output results
const messages = await openai.beta.threads.messages.list(
thread.id
);
const reply = messages.data[0]?.content[0];
if (reply.type === 'text') {
console.log('message: ', reply.text.value); // Text content
console.log('annotations: ', reply.text.annotations); // Annotations from File Search
}
Executing this returns the following result.

It is clear that the latest article has been searched. The annotations correctly set the source of the quote.
By contrast, sending the same prompt to an assistant with File Search disabled resulted in the following outcome.

Because it is unlearned information, it could not return an appropriate response (although no hallucinations occurred and the honest answer was somewhat pleasing).
Vector Stores can be attached not only to assistants but also to threads.
The following source code attaches an existing Vector Store to a thread.
const thread = await openai.beta.threads.create({
tool_resources: {
file_search: {
vector_store_ids: [vectorStore.id]
}
},
messages: [
{
role: 'user',
content: 'When was the OpenAI batch API announced? Tell me the details'
}
]
});
Just like when creating an assistant, the tool_resources.file_search.vector_store_ids sets the ID of the Vector Store.
Not only that, but you can also create a new Vector Store when creating a thread.
const thread = await openai.beta.threads.create({
tool_resources: {
file_search: {
// Create a Vector Store
vector_stores: [{
file_ids: ['file-xxxxxx']
}]
}
},
messages: [
{
role: 'user',
content: 'When was the OpenAI batch API announced? Tell me the details'
// Attachments can also be specified for the message as follows
// attachments: [{
// tools: [{ type: 'file_search' }],
// file_id: "file-xxxxxx"
// }]
}
]
});
Files are specified for the thread or message, resulting in the creation of a Vector Store.
Note that the Vector Store created for a thread is singular, and subsequently, files are added to the created Vector Store.
The Vector Store created for a thread has an expiration period of 7 days from the last use. If it expires, you need to update the thread to use a new Vector Store.
Summary
#This time, we focused on the significantly updated File Search feature in OpenAI's Assistants API v2.
The substantial increase in the number of registrable files is noteworthy, but personally, I feel that the accuracy of the responses has improved considerably compared to v1's Retrieval.
With only size-based charges for the Vector Store and a 1GB free tier, the costs are also attractive, so I am thinking of actively using it.
Nowadays, such features are called knowledge base search or RAG, and are provided as a wide range of managed services by companies other than OpenAI. ↩︎