超簡単!OpenSearch MCPでClaude Codeの検索性を拡張する
Back to Topはじめに
#この記事は夏のリレー連載2025 2日目の記事です。
ビジネスソリューション事業部の塚野です。
ここ数か月で爆発的に普及しているClaude Codeですが、ようやく導入しましたところそのすごさに無事ぶったまげました。
Claude CodeをはじめとするAgentic AIは、指定したファイルやフォルダを「コンテキスト」に含めて管理します。
コンテキストとは、いわばAgentic AIの「認知範囲」であり、ユーザーからの入力や会話、タスクの履歴、さらに読み込ませたファイルやAPIから取得した情報などが含まれます。これにより、Agentic AIはプロジェクトに特化した回答を作成し、その内容に基づいてタスクを実行することができます。
フォルダやファイルのパスを指定すれば、それらを直接コンテキストに取り込むことも可能です。しかし、ファイル数が多かったりサイズが大きかったり、あるいは内容が膨大だったりすると、取り込み自体ができなかったり、大量のトークンを消費してすぐにサービスのリミットレートに達してしまうといった問題が生じます。加えて、情報量が過剰になると、LLMが適切な回答を生成しにくくなることもあります。
さらに、Google Driveに保存したドキュメントや、GitHub、Subversionのリポジトリで管理しているソースコードなどにアクセスしたい場面もあるでしょう。ただし、こうした外部の情報は直接コンテキストに取り込めないため、一度ローカルに保存するなどの工夫が必要です。
こうしたAgentic AIが直接アクセスできない情報へのアクセスを可能にし、検索性を大きく拡張させる方法として本記事ではOpenSearch MCPをおすすめしたいと思います。
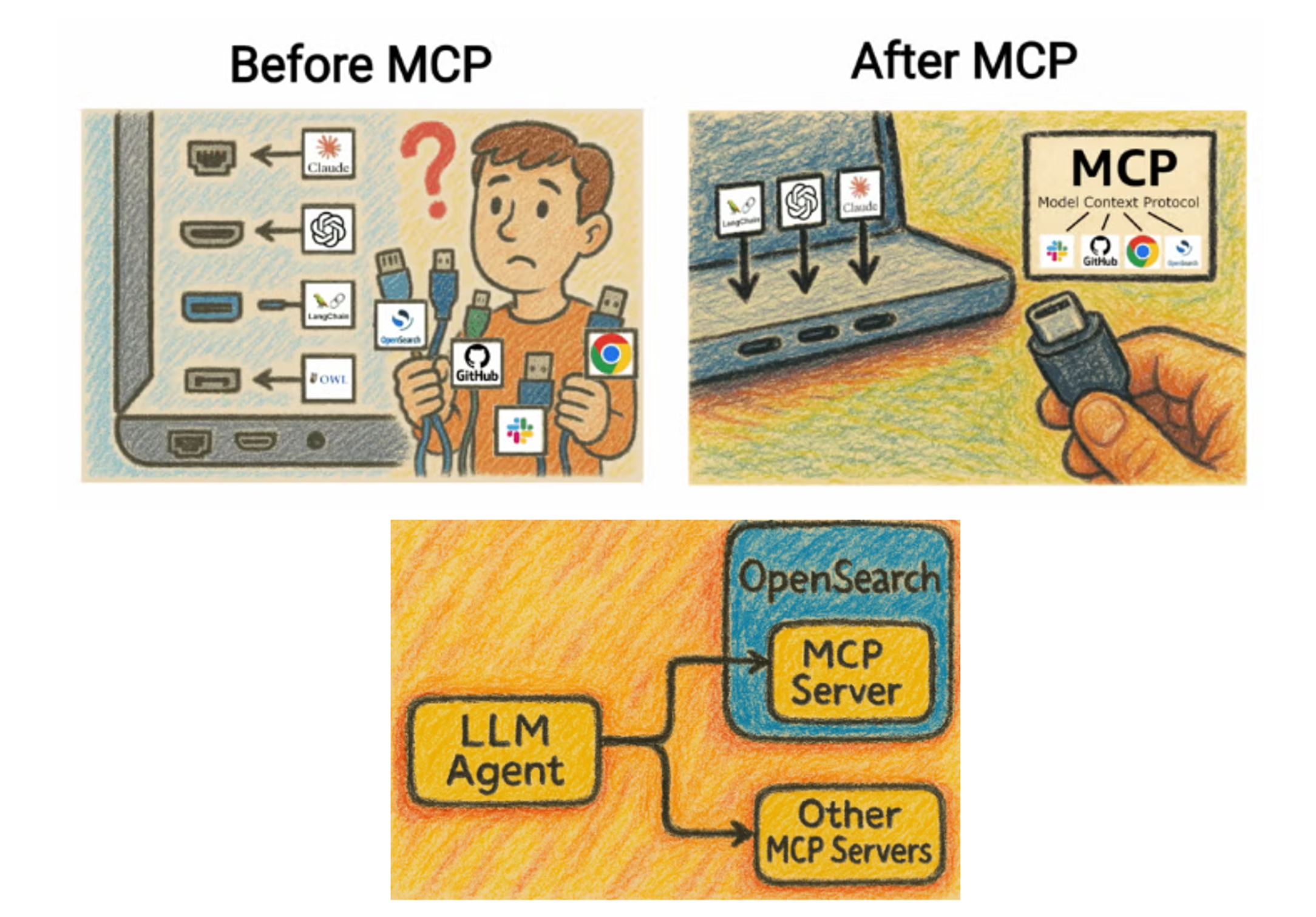
OpenSearch公式ドキュメントより抜粋、改変。MCPは統一的プラットフォームとしてよくUSB-Cに例えられます。
MCPとはModel Context Protocol の略で、Claude CodeをはじめとするAgentic AIが外部のサービスと連携するためのプラットフォームです。MCPを利用することで、Agentic AIは外部のサービスを操作でき、より高度なタスクを実行することが可能になります。
OpenSearchは、オープンソースの分散型検索および分析エンジンであり、高速な全文検索、ログ分析、リアルタイムのデータ可視化など、多様なユースケースに対応しています。また、version 2.11.0以降ではk-NN(k-Nearest Neighbors)及び近似k-NNを用いたベクトル検索をサポートしています。
このOpenSearchですが、version 3.0.0からネイティブにMCPをサポートするようになりました。ローカルMCPサーバーが内蔵されており、設定でMCPサーバーを有効にするだけでOpenSearchインスタンスをそのままローカルMCPサーバーとして利用できます。
OpenSearch MCPを活用することで、複雑な環境構築を行わずにAgentic AIが外部データへアクセスでき、ドキュメントやソースコードをより効率的かつ柔軟に検索できるようになります。
前提条件
#今回はOpenSearchのインスタンスをDockerコンテナとして起動し、MCPサーバーを有効にしてClaude Codeから接続するまでの手順を紹介します。
また、OpenSearchのインデックスを作成する際には、OSSの全文検索サービスであるFESSを利用します。
FESSはOpenSearchを検索エンジンとして利用しており、GUIでの操作で簡単にインデックスが作成できます。
FESSを利用すればGitHubのリポジトリをはじめ様々な場所からのクロールも簡単に設定でき、FESS自体全文検索サービスとしても利用可能です。
クロール先として、今回はGitHubのリポジトリを例にし、Agentic AIとしてClaude Codeにアクセスさせるまでの手順を紹介します。
使用するAgentic AIですが、MCPの設定は共通のため、Claude Code以外のCursorやClaude Desktop等でも同様の手順で利用可能です。
今回使用するソフトウェアのバージョンは以下の通りです。
- OpenSearch: 3.0.0
- FESS: 15.0.0
- Docker: 27.3.1
また、筆者の環境はWindowsなので、WSL2(Ubuntu 22.04)上でDockerを動かしています。
FESS + OpenSearchの起動
#まず、FESSとOpenSearchのDockerコンテナを起動します。
起動にはdocker composeを利用します。composeファイルはFESSの提供元であるcodelibsが配布しているためそちらを利用します。
以下のコマンドでcompose.yaml、compose-opensearch3.yamlをプロジェクトディレクトリにダウンロードしてください。
$ curl -O https://raw.githubusercontent.com/codelibs/docker-fess/refs/tags/v15.0.0/compose/compose.yaml
$ curl -O https://raw.githubusercontent.com/codelibs/docker-fess/refs/tags/v15.0.0/compose/compose-opensearch3.yaml
compose-opensearch3.yamlを編集しMCPサーバーを有効化します。と言っても付け足すのはたった1行です。
services:
search01:
image: ghcr.io/codelibs/fess-opensearch:3.0.0
container_name: search01
environment:
- node.name=search01
- discovery.seed_hosts=search01
- cluster.initial_cluster_manager_nodes=search01
- cluster.name=fess-search
- bootstrap.memory_lock=true
- node.roles=cluster_manager,data,ingest,ml
+ - plugins.ml_commons.mcp_server_enabled=true
- "OPENSEARCH_JAVA_OPTS=-Xms1g -Xmx1g"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- "FESS_DICTIONARY_PATH=/usr/share/opensearch/config/dictionary"
...
これだけです。
編集できたら、OpenSearchの起動に必要なパラメータを設定します。
$ sudo sysctl -w vm.max_map_count=262144
vm.max_map_count=262144
OpenSearchの起動にはこのvm.max_map_countの値を262144以上に設定する必要があります。
OpenSearchインスタンスの起動に失敗していたらまずは以下のコマンドでこの値を確認してください。デフォルトは65530になっているはずです。
$ cat /proc/sys/vm/max_map_count
vm.max_map_count = 65530
以下のコマンドでFESSとOpenSearchのコンテナを起動します。
docker compose -f compose.yaml -f compose-opensearch3.yaml up -d
起動後は以下のURLにアクセスし、FESSのトップ画面が表示されることを確認します。
http://localhost:8080/
これでOpenSearch側の準備は完了です。インデックスを作成する前に、次はClaude CodeからOpenSearchのMCPサーバーに接続できることを確認しておきます。
Claude CodeのMCPサーバー設定
#Claude Codeは利用可能なMCPサーバーを設定ファイルで管理しています。設定するファイルによってスコープが変わります(MCPインストールスコープ - Anthropic)。
今回はプロジェクトスコープで設定します。この設定の場合、作成する設定ファイルは他のAgentic AIでも共通で利用可能です。
プロジェクト直下に.mcp.jsonを作成し、以下の内容を記述します。
{
"mcpServers": {
"opensearch": {
"command": "uvx",
"args": ["test-opensearch-mcp"],
"env": {
"OPENSEARCH_URL": "http://localhost:9200"
}
}
}
}
今回はOpenSearchのインスタンスをテスト・ローカル用として起動するため、compose―opensearch3.yaml内で"DISABLE_SECURITY_PLUGIN=true"としてセキュリティプラグインを無効化しています。
セキュリティプラグインはインデックスの暗号化やAPIにユーザー認証を求めるようにするなどの機能を提供します。
これを有効化する場合、.mcp.jsonに認証情報を追加する必要があります。詳しくはこちらのドキュメントを参照してください。
また、argsには任意の文字列を入れます。
MCPサーバーの起動にはuvxを使います。uvxがインストールされていない場合は、以下のコマンドでPythonのパッケージ管理ソフトであるuvをインストールしてください。
curl -LsSf https://astral.sh/uv/install.sh | sh
これでClaude CodeからOpenSearchのMCPサーバーへ接続できるようになります。
早速Claude Codeを起動し、MCPサーバーに接続できることを確認しましょう。
Claude Codeのセットアップに関してここでは触れませんが、VSCodeとの連携が便利ですのでここではVSCodeでの起動を想定します。
Claude Codeを起動すると、MCPサーバーが追加された場合以下のようなメッセージが表示されます。
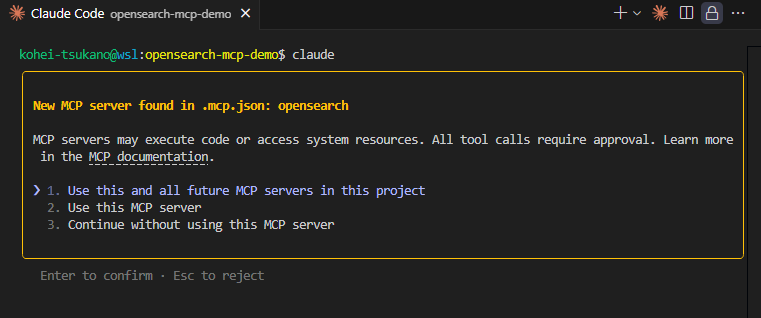
Claude Code MCPサーバー初回設定時の確認ダイアログ
Use this and all future MCP servers in this projectを選択。設定に記述したMCPサーバーがこのプロジェクト内で利用可能になります。
プロンプトでOpenSearchへの疎通確認をお願いしてみました。
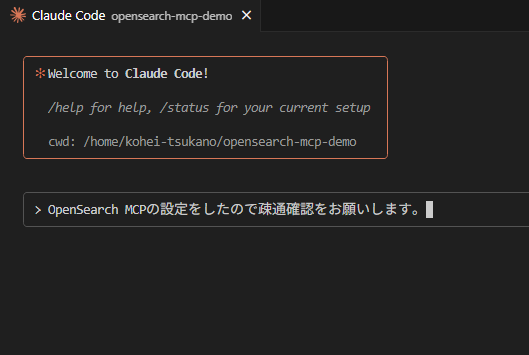
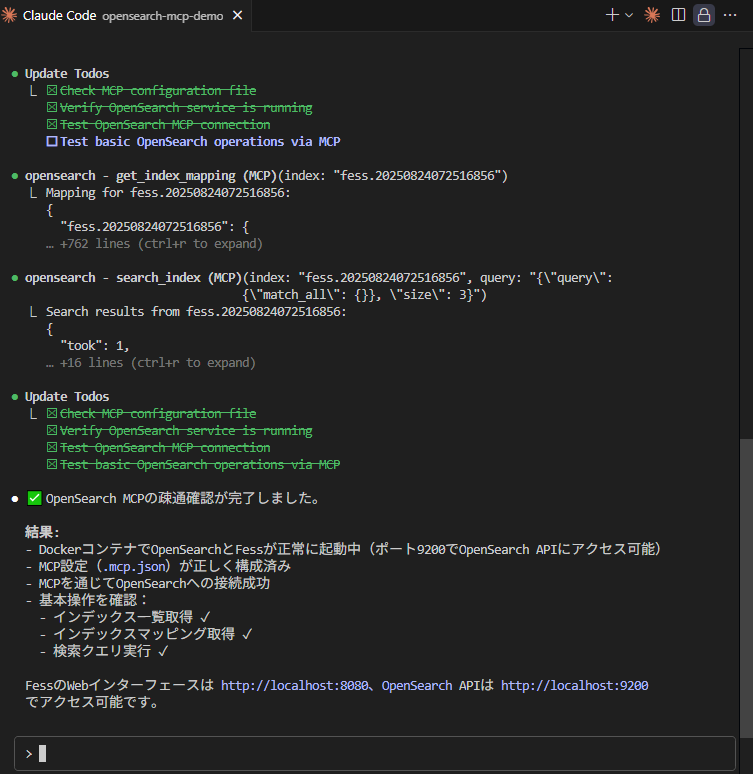
get_index_mapやsearch_indexなどのコマンドが利用でき、OpenSearchのMCPサーバーに接続できていることが確認できました。
インデックスの作成
#Claude CodeからOpenSearchのMCPサーバーに接続できたら、次はインデックスを作成し実際にClaude Codeに検索させてみたいと思います。
今回は「超簡単!」と銘打っていることもあり、簡単に設定ができるGitHubリポジトリをまずは対象にクロールを行い、検索してみます。
今回クロールするGitHubのソースコードは、本記事でも使用しているオープンソースの全文検索サービスであるFESSを対象としてみます。
インデックスはFESSの管理画面から作成します。FESSの管理画面には、FESSのURLに/adminを付けてアクセスします。
http://localhost:8080/admin
ユーザー名はadmin、初期パスワードもadminです。
初回ログイン時はパスワードの変更が求められますので、任意のパスワードに変更してください。
GitHubからのクロールにはプラグインの導入が必要となるため、FESS管理画面からプラグインをインストールします。
管理画面にログイン後、サイドバーの「システム」>「プラグイン」>「インストール」からプラグインインストール画面に移り、
リモートタブでプラグイン「fess-ds-git-xx.xx」を選択します。「インストール」をクリックするとプラグインがFESSへインストールされます。
続いて、サイドバーの「クローラー」>「データストア」からクローラーの設定画面に移り、「新規追加」ボタンをクリックします。
設定画面で以下のように入力します。
- 名前: 任意(今回は「fess-github」としました)
- ハンドラー名: GitDataStore
- パラメーター:
uri=https://github.com/codelibs/fess.git
base_url=https://github.com/codelibs/fess/blob/master/
extractors=text/.*:textExtractor,application/xml:textExtractor,application/javascript:textExtractor,application/json:textExtractor,application/x-sh:textExtractor,application/x-bat:textExtractor,audio/.*:filenameExtractor,chemical/.*:filenameExtractor,image/.*:filenameExtractor,model/.*:filenameExtractor,video/.*:filenameExtractor,
delete_old_docs=false
- スクリプト:
url=url
host="github.com"
site="github.com/codelibs/fess/" + path
title=name
content=content
cache=""
digest=content != null && contentLength > 200 ? content.substring(0, 200) + "..." : content;
anchor=
content_length=contentLength
last_modified=timestamp
timestamp=timestamp
filename=name
mimetype=mimetype
domain="github.com"
organization="codelibs"
repository="fess"
path=path
repository_url="https://github.com/codelibs/fess"
filetype=container.getComponent("fileTypeHelper").get(mimetype)
owner=""
homepage=""
クロール先のリポジトリによって変わるのはリポジトリのドメイン(github.com)、組織名(codelibs)、リポジトリ名(fess)です。上記のパラメータ、スクリプトのうち、これらの値を変更してください。
privateリポジトリをクロールする場合は、パラメータに以下のように認証情報を含める必要があります。
username=hogehoge
password=ghp_xxxxxxxxxxx
commit_id=main
現在GitHubではパスワード認証を廃止しています。代わりにpersonal access token(PAT)をGitHubで発行し、password欄に入れてください。
また、メインとなるブランチ名をmasterから変更している場合、そのままだとHEADコミットが取れないのでcommit_idでメインとなるブランチを指定してください。
どのようなパラメータ、スクリプトが利用できるのか知りたい場合はFESS Git Data Storeのリポジトリ(Git Data Store)を参照してください。
後の欄は初期のままで大丈夫です。
「作成」ボタンをクリック。設定を保存します。
最後に、クローラージョブを実行してクロールを開始します。
サイドバーの「システム」>「スケジューラ」からジョブスケジューラの画面に移り、「Default Crawler」を選択。
「今すぐ実行」をクリックでクロールが開始されます。
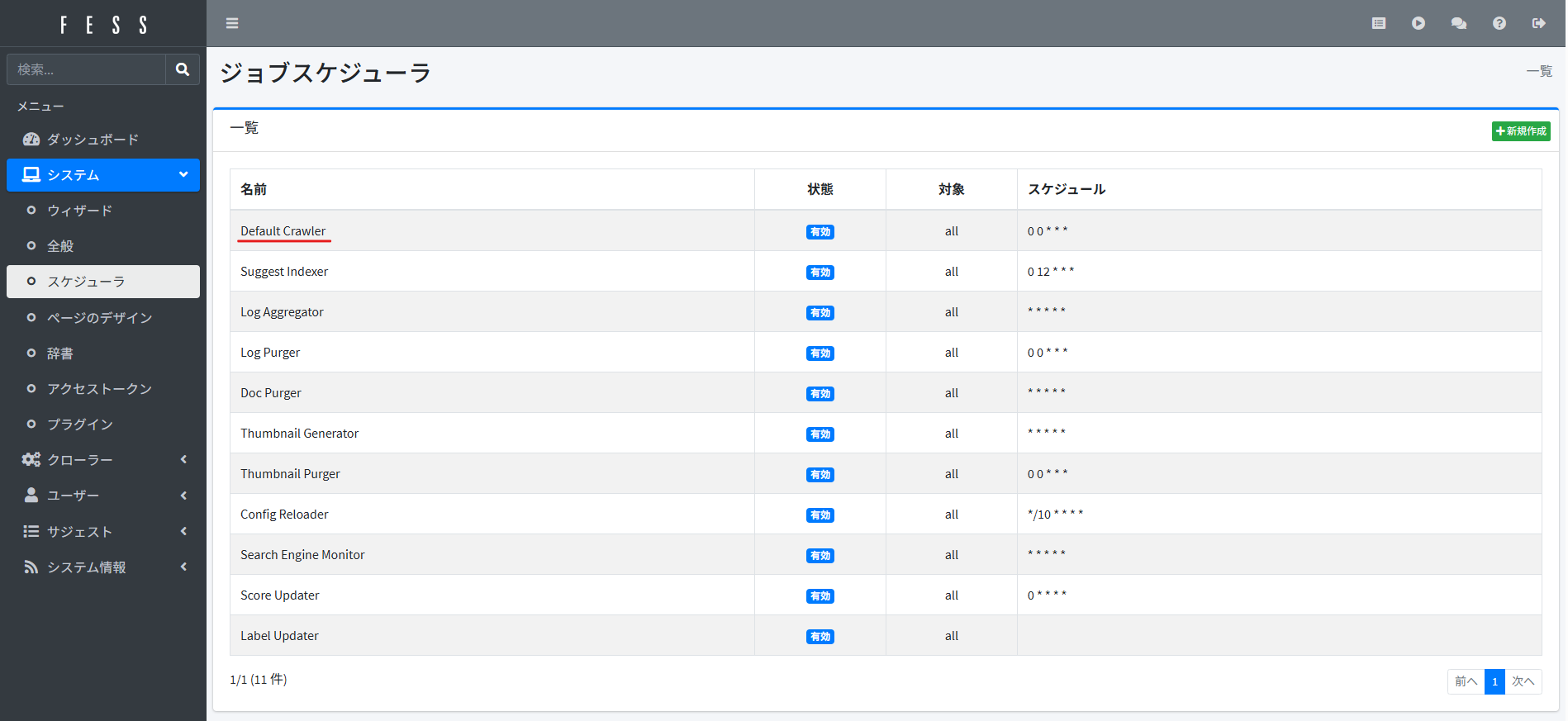
Default CrawlerはFESSで設定されている全ての[1]クローラージョブを実行します。
クロールジョブの実行中はスケジューラの「状態」が「実行中」になります。この状態が「有効」に戻るまでしばらく待ちましょう[2]。
Claude Codeでの検索
#クロールが完了したら、Claude Codeで検索してみます。
Claude Codeのプロンプトに以下のように入力し、試しにFESSのソースコードを検索してもらいました。
検索クエリに「regexp:パターン」を含めることで正規表現で検索ができるようになるregexpプレフィックスを実装したいです。\
接続したMCPサーバーからFESSのソースコードを検索し、どのクラスを拡張すればいいか調べてください
するとこのような結果が1~2分ほどで返ってきました。
FESSでregexp:プレフィックスを実装するには、以下のクラスを拡張する必要があります:
主要な拡張ポイント
1. RegexpQueryCommand (新規作成)
src/main/java/org/codelibs/fess/query/RegexpQueryCommand.java
- QueryCommandを継承して正規表現クエリを処理
2. QueryStringBuilder (拡張)
src/main/java/org/codelibs/fess/util/QueryStringBuilder.java:177-193
- appendConditionsメソッドにregexp:処理を追加
- 既存のsite:、filetype:と同様の実装パターン
3. RegexpQueryFilter (新規作成)
- QueryParser.Filterを実装
- クエリ文字列からregexp:プレフィックスを検出・変換
4. 設定ファイル
- /src/main/resources/app.xml - コンポーネント登録
- /src/main/resources/fess_config.properties - 設定追加
既存アーキテクチャ
FESSは既に以下のプレフィックスをサポートしており、同じパターンで実装可能:
- site: - サイト検索
- filetype: - ファイルタイプフィルタ
- sort: - ソート指定
- timestamp: - タイムスタンプフィルタ
QueryProcessor(src/main/java/org/codelibs/fess/query/QueryProcessor.java:67-70)でコマンド登録
し、QueryParser(src/main/java/org/codelibs/fess/query/parser/QueryParser.java:78-85)でフィルタ
チェーン処理します。
…すごい。ちゃんと既存の実装を見て変更点について提案してくれています。
検索フィールドを増やすわけではないのでfess_config.propertiesの編集は必要なさそうですが、編集するjavaファイルなどは正解っぽい感じがします。
さらにどのように調査したのか、どのようなクエリで検索したのかと聞いたところ、以下のような回答が返ってきました。(一部改変)
1. MCPサーバー接続確認
- 利用可能なインデックス一覧を取得
- fess*パターンでFESS関連インデックスを特定
2. データ存在確認
- FESS関連インデックスにデータが存在することを確認
3. ソースコード検索(**Taskツール使用**)
**専用エージェントに以下の検索タスクを依頼**:
検索対象:
- Javaソースコードファイル
- クエリ処理・解析関連クラス
- 既存プレフィックス処理メカニズム
- メインクエリ処理パイプラインクラス
エージェントが実行したと推測される検索クエリ:
- QueryParser - クエリ解析の中核
- QueryProcessor - クエリ処理ルーティング
- QueryStringBuilder - 既存プレフィックス処理
- site: filetype: - 既存実装パターン
- QueryCommand - コマンドパターン実装
- Filter - フィルタチェーン実装
4. アーキテクチャ分析
具体的な検索キーワードを出さずとも、Claude Codeの方でクエリを考えて検索を行ってくれたようです。
また、検索処理にはTaskツールを使っていました。
これはClaude Codeの機能の一つで、ユーザーからのプロンプトを受けたメインのエージェントとは別に専用エージェントを起動して、複雑なタスクを自律的かつ並列的に実行させることができます。(What is the Task Tool in Claude Code - ClaudeLog)
これによって得られた情報を、メインエージェントが統合し、回答を生成します。
今回作成された専用エージェントは目的の回答にたどり着くまで探索的に検索を何度も繰り返していました。
また、さらに詳しく調べたところ、キーワード検索だけでなく必要があればファイルの中身も直接参照して回答を生成しているようでした。これは検索結果にリポジトリ内の実際のファイルパスも含まれるためです。
以上の検証から、ファイルの検索とファイル内容の詳細解析というClaude Codeがローカルファイルに対して普段行う操作を、OpenSearch MCPを使ってGitHubリポジトリ上のファイルに対しても簡単かつ効率的に実行できるということが分かりました。
まとめ
#今回はClaude Codeに全文検索エンジンを接続して検索性を拡張する方法をご紹介しました。
OpenSearchは冒頭で述べたようにベクトルデータベース化もできるため、Claude Codeに意味検索もしくは全文検索とのハイブリッド検索も行わせることができます。
ドキュメント類は意味検索、ソースコードはキーワード検索で厳密な一致検索[3]を行うという使い分けもいいかもしれません。
近年はベクトルデータベースの導入コストが下がり、Embedding精度も向上してきていますが、それでも「超簡単!」に導入というレベルにはまだ達していないと感じています。
一方で、Agentic AIがクエリを考え、探索的に検索を繰り返してくれるのであれば、RAGを導入しなくても全文検索だけで十分なケースも少なくありません。
さらに、意味検索(RAG)では「どのようにその回答が導かれたのか」がブラックボックス化しがちですが、全文検索であれば検索結果の根拠を直接追跡できるという利点もあります。
Claude Codeに全文検索させるメリットとしてもう1つ、トークンの節約があります。
トークンはユーザーが入力したプロンプトや、エージェントが読み込んだファイルなど「LLMへ送信された情報量」によって消費量が決まります。
Claude Codeはファイルの探査にgrep検索を行うのですが、例えばマッチしたファイルが.logのようなminifiedファイルの場合、1行の情報量が膨大でファイルを読むだけで大量のトークンを消費してしまうということもありえます。
一方、Open Search MCPからのレスポンスは構造化されたjson形式かつインデックス化された情報なので、検索結果によって大きくトークンを消費するといったこともありません。
本記事では実験的にGitHubリポジトリをクロール対象としましたが、FESSでは他にもプラグインの導入でGoogle DriveやMicrosoft Share Pointなどもクロール対象にできます。これにより、「Google Driveで設計資料を検索して、それを元にGitHubのソースを検索して」といったタスクも依頼可能です。
Google Driveのクロール設定方法はこちらの記事を参考にしてください。
また、FESSはプラグインを自作することによりクロール対象や検索機能の拡張も可能です。
公式では配布していないSubversionをクロール対象とするプラグインを自作したりなどしているので、機会があればちょっとニッチですがプラグイン作成についてや他のデータソースのクロール方法など記事にしたいと思います。
一度に実行可能なクローラー設定数はデータストア、ウェブ、ファイルストアクローラーで各100個までがデフォルトの上限で設定されています。この上限を変更する場合は
fess01コンテナ内/etc/fess/fess_config.propertiesのpage.data.config.max.fetch.size、page.web.config.max.fetch.size、page.file.config.max.fetch.sizeをそれぞれ変更してください。 ↩︎クロールに失敗した場合は、サイドバー「システム情報」タブの「障害URL」にクロールが失敗したURLとスタックトレースが表示されます。「システム情報」の「ログファイル」からログファイルの参照も行えるのでこれらを使って原因を調査してください。 ↩︎
FESSは大文字小文字を区別せず、デフォルトで4文字以上の単語に対してあいまい検索が有効になっているため厳密な検索ではないですが…。FESSコンテナ内
fess.jsonからanalyzerでlowercase filterを使用しないようにすれば大文字小文字の区別は可能になります。また、あいまい検索もfess_config.json内でquery.boost.fuzzy.min.length=-1を指定することでOFFにできます。 ↩︎