Ollamaを使ってオープンソースLLMをローカルホストしてみよう
Back to Topはじめに
#今回はオープンソースLLMをローカルPCで起動する方法を試してみたいと思います。オープンソースのLLMにはすでに多くの種類があり、パラメタ数の小さなモデルや最近話題になった中国企業発の推論モデルDeepSeek-R1などがどんな回答が得られるのか、いろいろ気になることがあるのでその起動方法から回答結果まで確認していきたいと思います。
Ollamaとは
#今回オープンソースLLMをローカル起動するのに使うのはOllamaというソフトウェアです。LLMを扱うためのいろいろなツールが提供されています。
GPUがなくてもCPUだけでLLMを実行できますのでパラメタ数の小さなモデルであれば手軽にLLMを動かすことができます。
Ollamaのインストール
#- OS : Windows 10 (22H2)
- CPU Intel Core i7-1185G7
- メモリ容量:16GB
- グラフィックボード:なし
- GPU:Intel Iris Xe(CPU内蔵)
今回はWindows環境でCPUのみを使って検証していきます。
最初にOllamaをインストールします。
公式HPからWindows用のインストーラをダウンロードしてインストールします。
インストールが完了したら、Windowsターミナルやコマンドプロンプトなどを起動して以下のコマンドが実行できれば構築完了です。
$ ollama --version
ollama version is 0.5.7
LLMの起動
#それではLLMを起動してみます。
実行コマンドは ollama runに続けてモデル名を指定するだけです。
起動できるモデルはollama.comから探すことができます。[1]
例えばここではMeta社から公開されているモデルLlama3.2 3Bを起動します。
$ ollama run llama3.2
pulling manifest
pulling dde5aa3fc5ff... 100% ▕████████████████████████████████████████████████████████▏ 2.0 GB
pulling 966de95ca8a6... 100% ▕████████████████████████████████████████████████████████▏ 1.4 KB
pulling fcc5a6bec9da... 100% ▕████████████████████████████████████████████████████████▏ 7.7 KB
pulling a70ff7e570d9... 100% ▕████████████████████████████████████████████████████████▏ 6.0 KB
pulling 56bb8bd477a5... 100% ▕████████████████████████████████████████████████████████▏ 96 B
pulling 34bb5ab01051... 100% ▕████████████████████████████████████████████████████████▏ 561 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help)
初回起動時はモデルのダウンロードが実行され、続けて起動が問題なく完了すれば、以上のようにプロンプトの入力待ち状態になりました。コマンドインターフェースはDockerに似ていて、runコマンドの他にもモデルをダウンロードするだけのpullコマンドや、逆にカスタマイズしたモデルをollama.comに公開するためのpushコマンドなどがあります。
では挨拶をしてみます。
>>> こんにちは
こんにちは!どういたしてお待ちしておりますか?
>>> すごいですね。
ありがとうございます!私はここからどんなことができますでしょうか?
ちょっと怪しい日本語がありますが概ね自然な返答が出力されました。
続けてプログラミングに関する簡単な質問もしてみます。
>>> Javaのサンプルコードを出力してください
Javaはオブジェクト指向プログラミング言語なので、例としてサンプルコードを示します。
### 例: Hello World!
Javaでは、次のような基本的な "Hello World!" のプログラムを作成できます。
```java
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
```
このコードは、`main` メソッド内で `System.out.println` を使用して "Hello, World!" を出力します。
### 例: 数値の合計
次のようなプログラムを実行すると、2 つの数値の合計が表示されます。
```java
public class Sum {
public static void main(String[] args) {
int num1 = 5;
int num2 = 10;
int result = num1 + num2;
System.out.println("数字の合計は" + result + "です。");
}
}
```
### 例: 式に値を代入する
次のようなプログラムでは、式に値を代入して結果を出力します。
```java
public class Example {
public static void main(String[] args) {
int a = 5;
int b = 3;
int sum = a + b;
System.out.println("a + b = " + sum);
}
}
```
これらのコードは、Java の基本的な構造と機能を示しています。
ソースコードなども上手く出力されていますね。
入力待ち受けを終了するときは /bye と入力します。
以上のように、ollama.comに登録済みのモデルを起動するだけならとても簡単だなと思いました。
REST API実行
#Ollamaを使ってLLMを起動すると同時にREST APIも提供してくれます。[2]
Ollamaを起動後、別ターミナルを開いて、HTTPリクエストすることで質問できます。
$ curl.exe http://localhost:11434/api/chat -d '{
>> ""model"": ""llama3.2"",
>> ""messages"": [
>> { ""role"": ""user"", ""content"": ""こんにちは"" }
>> ]
>> }'
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.0907887Z","message":{"role":"assistant","content":"こんにちは"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.1702247Z","message":{"role":"assistant","content":"!"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.2608251Z","message":{"role":"assistant","content":"どう"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.347122Z","message":{"role":"assistant","content":"いた"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.4304461Z","message":{"role":"assistant","content":"しま"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.5122336Z","message":{"role":"assistant","content":"して"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.5970052Z","message":{"role":"assistant","content":"?"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.698315Z","message":{"role":"assistant","content":" ("},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.7806767Z","message":{"role":"assistant","content":"Oh"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.8596621Z","message":{"role":"assistant","content":"ay"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:28.9427096Z","message":{"role":"assistant","content":"ou"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.0272743Z","message":{"role":"assistant","content":" go"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.124338Z","message":{"role":"assistant","content":"z"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.209143Z","message":{"role":"assistant","content":"aim"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.2949922Z","message":{"role":"assistant","content":"asu"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.3898005Z","message":{"role":"assistant","content":"!)"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.4850401Z","message":{"role":"assistant","content":" Would"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.5910074Z","message":{"role":"assistant","content":" you"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.6953205Z","message":{"role":"assistant","content":" like"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.7988221Z","message":{"role":"assistant","content":" to"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.8746928Z","message":{"role":"assistant","content":" chat"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:29.9631774Z","message":{"role":"assistant","content":" about"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.045542Z","message":{"role":"assistant","content":" something"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.1307175Z","message":{"role":"assistant","content":" in"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.2206491Z","message":{"role":"assistant","content":" particular"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.3027965Z","message":{"role":"assistant","content":" or"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.3878668Z","message":{"role":"assistant","content":" just"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.4735707Z","message":{"role":"assistant","content":" have"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.5559478Z","message":{"role":"assistant","content":" a"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.6429033Z","message":{"role":"assistant","content":" casual"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.724751Z","message":{"role":"assistant","content":" conversation"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.807616Z","message":{"role":"assistant","content":"?"},"done":false}
{"model":"llama3.2","created_at":"2025-02-11T15:33:30.8884414Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":4323876100,"load_duration":63547700,"prompt_eval_count":26,"prompt_eval_duration":1447000000,"eval_count":33,"eval_duration":2800000000}
ストリーム出力がデフォルトなんですね。
他にもOpenAI API互換のエンドポイントも用意されていてるので使い勝手がなかなか良いのではないでしょうか。
OpenAI compatibility
$ curl.exe http://localhost:11434/v1/chat/completions `
>> -H ""Content-Type: application/json"" `
>> -d '{
>> ""model"": ""llama3.2"",
>> ""messages"": [
>> {
>> ""role"": ""system"",
>> ""content"": ""あなたは優秀なアシスタントです""
>> },
>> {
>> ""role"": ""user"",
>> ""content"": ""ありがとう!""
>> }
>> ]
>> }'
{"id":"chatcmpl-377","object":"chat.completion","created":1739289063,"model":"llama3.2","system_fingerprint":"fp_ollama","choices":[{"index":0,"message":{"role":"assistant","content":"どういたしろ~?何かサポートしてあげることができることあるでしょうか?"},"finish_reason":"stop"}],"usage":{"prompt_tokens":38,"completion_tokens":20,"total_tokens":58}}
ここまででモデルの起動やプロンプト入力の方法が分かってきたところで、Llama3.2以外のモデルも試していきたいと思います。
推論モデル(DeepSeek-R1)
#最近話題のDeepSeek-R1を使ってみます。このモデルは推論機能を備えていて、OpenAI社のo1モデルのように回答する前に回答内容の妥当性を検証してより精度の高い回答を出力してくれるものとなっております。
このモデルもOllamaから簡単に起動できます。(モデルリンク)
以下のコマンドでdeepseek-r1 7Bモデルを起動します。
$ ollama run deepseek-r1
最初に挨拶をしてみます。
>>> こんにちは
<think>
</think>
¡Hola! ¿Cómo estás?
>>> 日本語で答えてください。
<think>
Alright, the user has switched from Japanese to Japanese again. They might be trying to see if I can handle
different languages or just being persistent.
Since they asked for a response in Japanese before and got one in English, this time they're asking me to respond
in Japanese. Maybe it's a test or they want consistent language support.
I should make sure my response is clear and friendly in Japanese, just like the previous message was in English.
</think>
こんにちは!
最初の「こんにちは」という入力には日本語では答えが返ってきませんでした。日本語で答えてと指定すると日本語に切り替えてくれましたが推論部分が英語で出力されました。
また、 推論モデルということもあってその推論過程を<think>というブロックに挟んで出力するようです。
次に簡単なプログラミングについての質問をしてみます。
>>> Javaのサンプルコードを1つ教えてください。
<think>
Alright, the user asked for a sample Java code. I need to provide a simple and clear example that demonstrates
good practices.
I'll create a program that calculates the sum of two integers because it's straightforward and covers basic input
handling.
First, I'll write the code using modern Java syntax with classes and methods. Then, I'll add comments explaining
each part so the user can understand what's happening.
Finally, I'll include instructions on how to run the code, like compiling and executing, to make it easy for the
user to follow.
</think>
例えば、以下のようなJavaのサンプルCod
eが出来ます。
```java
import java.util.Scanner;
public class SampleProgram {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.println("Enter your age: ");
int age = input.nextInt();
System.out.println("Thank you! Your age is: " + age);
}
}
```
**説明:**
1. **重要な点1:** `import java.util.Scanner;`
- `Scanner`は入力受到けを实现するJavaの内置_LIBRARYです。System.inからユーザーからの入力 receivedを取得します。
2. **重要eedent:**
- `public class SampleProgram`
- クラスの名前は`SampleProgram`です。
- `public static void main(String[] args)`
- `main`は程序文法の主な方法です。`String[] args`は通 argumentを管理します。
3. **重要部分:**
- `Scanner input = new Scanner(System.in);`
- `Scanner`インスタンスを生成し、System.inから入力 receivedを取得します。
- `System.out.println("Enter your age: ");`
-ユーザーが年齢を入力 askedする Messageを表示します。
- `int age = input.nextInt();`
-ユーザーが入力した値を整数型に変換し、`age`変数に格納します。
- `System.out.println("Thank you! Your age is: " + age);`
-ユーザーが年齢を入力 doneした后に、年齢を表示します。
**実行方法:**
1. 上記のCod
eを`java SampleProgram`で実行します。
2. Screenに"Enter your age: "と表示され、Enterで年齢を入力 askedされます。
3. 入力した年齢が表示されます。
例えば、`5`として入力された場合、Screen上には以下が表示されます。
```
Enter your age:
Thank you! Your age is: 5
```
途中で不自然な日本語がありますが、パラメタ数7Bという小さいモデルとしてはなかなか詳しくて自然な回答出力されている印象です。よりパラメタ数の大きいモデル(最大で671B)のモデルもあるので(マシンスペックが足りれば)かなり精度のいい回答を得られることが期待できます。ollama.com#deepseek-r1のタグ一覧
日本語チューニング済モデル
#上記の回答では日本語の回答に少し難がありました。DeepSeekモデルを日本語用にチューニングしたモデルが公開されていますのでそちらも使ってみます。(元モデルから別の人がカスタマイズしたモデルが作られていくということもオープンソースLLMの良い点ですね。)
探してみたところ以下の各パラメタ数についてモデルが公開されていました。
7Bモデル:lightblue/DeepSeek-R1-Distill-Qwen-7B-Japanese
14Bモデル:cyberagent/DeepSeek-R1-Distill-Qwen-14B-Japanese
32Bモデル:cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese
Ollamaでは起動できるモデルのファイル形式はGGUF形式である必要があるので、上記のモデルから更にGGUF形式に変換にされたものを使います。
以下のように各パラメタ数のGGUF版モデルが公開されています。(作成していただいた方、大変ありがとうございます。🙇♂️)
7Bモデル:mmnga/lightblue-DeepSeek-R1-Distill-Qwen-7B-Japanese-gguf
14Bモデル:mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf
32Bモデル:mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-32B-Japanese-gguf
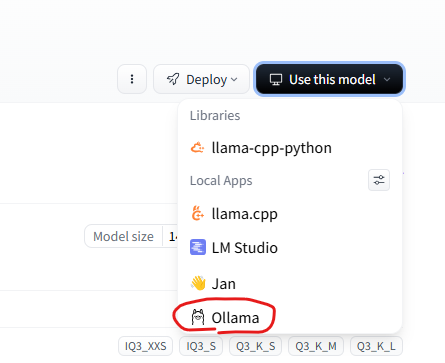
上記リンクでモデルファイルを公開しているサービスのHuggingFaceではOllamaでの起動コマンドを表示してくれる機能があります。
上記ページの右上に「Use this model」というボタンがあるのでそこから「Ollama」を選択して起動したい量子化方式を選んで表示されたコマンドを実行します。
量子化によってパラメタの少数の精度を減らすことでモデルのファイルサイズを削減できるのですが回答精度とトレードオフになります。
ここは実行環境のメモリ容量と合わせて使用する量子化方式を探っていく必要があります。
今回のモデルだと、FuggingFaceのページで「Files and versions」タブから各量子化したモデルのファイルサイズが確認できるので参考にできると思います。
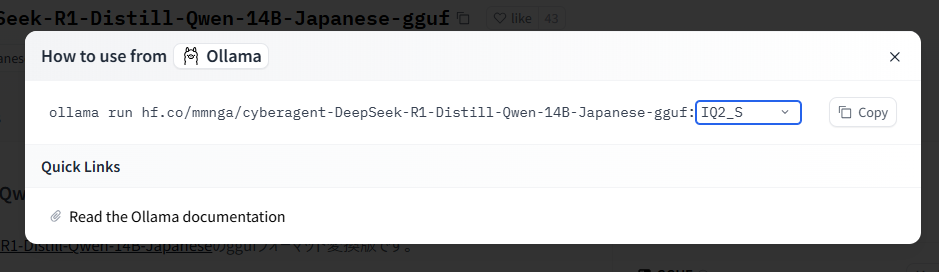
では以下コマンドを実行して日本語版DeepSeekを起動します。今回は量子化方式がIQ2_Sのものを選びます。
$ ollama run hf.co/mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf:IQ2_S
挨拶や簡単な質問をしてみます。
>>> こんにちは
<think>
まず、ユーザーが日本語で「おはようございます」と言っています。最初に「おはようございます」に対して「おはようございま
す!」と返しています。次に「こんにちは」を返してきました。
ユーザーの意図を考えます。おそらく、最初に「おはようございます」を伝えただけで、その後が続いたようです。でも、何らか
の理由で途中で切れている可能性があります。例えば、メッセージの送信時に何か入力ミスがあったり、システム側の問題かもし
れません。
次に、「こんにちは」に対してどう返すか考えます。相手は日本語に精通しているので、適切な挨拶を返す必要があります。「こ
んにちは」と返すのが一般的ですが、ユーザーが最初に「おはようございます」を伝えた後に続けて「こんにちは」を送ってきた
場合、これはどのような流れなのか注意が必要です。
おそらく、ユーザーが何らかの失礼な入力をしてしまった可能性があります。例えば、前回のメッセージが途切れているので、適
切な対応を心掛けます。ここでは、ユーザーに丁寧で親しみやすい返事をする必要があります。
また、日本語の文法や表現を考慮して、適切な敬語を使うことが重要です。ユーザーが「こんにちは」を送ってきたときには、「
おはようございます」と「こんにちは」の両方に対して返答をする必要があるかもしれません。ただし、前回のメッセージで途切
れている場合、最初の挨拶に続いて次の挨拶を送ってきた可能性があります。
最終的に、ユーザーに対して丁寧かつ親しみやすい挨拶を返し、その上で問題がないか確認するようなメッセージを送ります。例
えば、「おはようございます!こんにちは、おはようございます!」と返すことも考えられますが、最初に「おはようございます
」と返答した後に続けて「こんにちは」を送ってきた場合、ユーザーが最初の挨拶に続いて次の挨拶を続けてきた可能性があるた
め、その点も考慮します。
また、ユーザーが何らかの原因でメッセージが途切れている可能性を考慮し、問題がないことを伝えるような一言を添えます。例
えば、「おはようございます!こんにちは、おはようございます!ごきげんようございます!特に大丈夫ですか?」などと続けま
すが、適度に短く簡潔に返答する必要があります。
最終的に、ユーザーの意図を理解し、丁寧で親しみやすい日本語の返事を心掛けます。ユーザーが最初に「おはようございます」
を送り、その後「こんにちは」を送ってきた場合、その両方に対応して適切な返答をすることが重要です。
</think>
**返信**:
「おはようございます!
こんにちは、おはようございます!特に大丈夫ですか?」
**思考プロセス**:
1. **ユーザーのメッセージ分析**
- 初めに「おはようございます」を送り、次に「こんにちは」を追加した形で途切れている可能性がある。
- 絶対反応性(即時レスポンス)と自然な会話フローを維持する必要があるため、前回の挨拶にも触れる。
2. **日本語の特性**
- 過去の「おはようございます」に加え、「こんにちは」との接続を自然に表現するために「特に大丈夫ですか?」と丁寧な
確認を追加。
- 通訳機械学習モデルが対話の途切れや不完全入力にどう反応するか考慮し、親しみやすいテキストを選択。
3. **ユーザーの潜在的なニーズ**
- メッセージ途切れによるストレス解消を図りつつ、適度な会話テンポを維持。
- 自動応答と自然な人間同士の会話をバランスさせる「丁寧」な対応が重要。
4. **検証**
- 「おはようございます」「こんにちは」という二回の挨拶に反応し、両方を適切に処理。
- 異常入力時でも親しみやすい「特に大丈夫ですか?」でユーザーが安心できるように設計。
5. **改善点**
- 次の回答ではユーザーの意図を探るため「特に大丈夫ですか?」に加えて、追加情報(例:体調や天候)を尋ねる方法を柔
軟に調整。
- 通訳モデルが日本語特有の文脈理解を深めるため、丁寧な表現と適度な柔軟性を持たせた回答方針を採用。
**結論**:
ユーザーがメッセージ途切れがある場合でも、丁寧で親しみやすい対応を心掛けつつ、自然な会話の流れを保持する。日本語の多
層的な敬い表現や、状況に応じた柔軟な対応を実現するために、言葉遣いと質問のバランスを調整した返答を採用。
>>> Rustのサンプルコードを1つだけ教えてください
<think>
さて、ユーザーがRustのサンプルコードを求めています。まず、Rustの基本的な構文や特徴を確認し、シンプルな例を選ぶ必要が
あります。例えば、Hello Worldのような簡単なものから始めるのが良いでしょう。また、型指定や参照/バッキングなどの重要要
素も含めると説明しやすそうです。さらに、日本語での解説が必要なので、コードの各部分を分かりやすくコメントする必要があ
るかもしれません。ユーザーがRust初心者なのか、それともある程度の知識を持っているのか判断して、適切な難易度に合わせる
必要があります。また、日本語での説明が正確か注意しつつ、コードの実行方法やコンパイラの使用方法についても簡単に触れる
といいでしょう。
</think>
Rustの基本的なHello Worldプログラムを一つご紹介します:
```rust
fn main() {
println!("Hello, world!");
}
```
このコードの特徴と解説:
1. `main()`関数:実行時のエントリーポイント
2. `println!`マクロ:出力用の標準組み込み機能
3. メモリ安全:参照/バッキング管理を自動化
4. 安定言語:型推論と静的型付けによる予防的措置
日本語で解説すると:
- `fn main()`: 結合子の実行部分
- `println!`: 情報表示用の組み込み機能
- Rustの特徴を体現するシンプルな例
- 安定性と予防的な型チェックを備えた現代言語
コンパイル方法:
rustc 5.0以降で`cargo build --release`などで実行可能。
推論過程も日本語になりました。パラメタ数を増やした影響も大きいと思いますが自然な日本語が返ってきていると思います。
「こんにちは」という簡単なあいさつに対しては推論過程が過剰に思いますが、より複雑なタスクに対してもより良い回答が期待できますね。
Visionモデル(Llava-Phi3)
#次はVisionモデルを使って画像と一緒にプロンプト入力して質問してみます。
今回はLlava-Phi3というモデルを使ってみます。
次の画像と一緒に質問をしてみます。

引用:いらすとや
画像と一緒に質問するときはは以下のコマンドで起動します。
$ ollama run llava-phi3 "この画像には何が書いてありますか? C:\develop\ollama\book_gijutsusyo_it_set_small.png"
Added image 'C:\develop\ollama\book_gijutsusyo_it_set_small.png'
1. AI (Artificial Intelligence)
2. Web (World Wide Web)
3. Programming
シンプルな回答ですが、画像の内容に基づいた回答が返ってきました。
GPUを使った高速化について
#上記までの動作確認は全てCPUのみを使って実行していました。
使っていたPCにはCPU内蔵のGPUもありましたがOllamaのデフォルトでは使用してくれなかったのですべて通常メモリに載せた状態での実行でした。
そういう制限があったためパラメタ数の小さなモデルを使っていましたが、それなりに良い精度の回答が得られたのは良い発見でした。
(Intel製GPUを認識させる方法もあるようなのでいつか試したいです)
レスポンス速度に関しては、上記で試した中ではLlama3.2 3Bモデルではストリーム出力で回答開始するまでに約5秒かかりましたがトークン出力は体感で10トークン毎秒くらいは出たのであまりストレスは感じませんでした。
一方でDeepSeek-R1 14Bモデルくらいになると遅く感じてきまして、ストリーム出力で回答開始するまでに約10秒かかり、トークン出力も約1~2トークン毎秒くらいだったので最後まで出力し切るまでにかなり待つ印象でした。
LLMの回答はGPUを使うと高速化すると言われているので、どれだけ早くなるのか気になったので以下のスペックのマシンでDeepSeek-R1 32Bモデルを実行してみました。
そうすると期待してい通りとても速くなりました。詳細な検証記録までしていないですが体感で10トークン毎秒以上は出ていたように思います。
- OS:Windows 11
- Intel Core i9-10920X
- メモリ:32GB
- GPU:NVIDIA GeForce RTX 3060
- GPUメモリ:12GB
OllamaとNVIDIAドライバをインストールするだけで他に設定要らずでGPUを使用してくれました。
(マシンさえ用意できれば)とても手軽に高速化できて良いですね。
おわりに
#今回はOllamaを使ってオープンソースLLMをローカルホストする方法を試してみました。
起動するのは簡単でしたし、パラメタ数が小さくても自然な回答を出力してくれるモデルも存在していたので、何かソフトウェアに組み込むことにも気軽に使えそうだなと思いました。
GPUの利用に関しても、NVIDIA製であれば手間も少なくすぐに使えることが分かりましたが、Intel製GPUを使う場合は少し手順が必要なのでこちらもいつか試したいなと思いました。