箱ひげ図と散布図を同時に描画して概要を把握する(層別・分析編)
Back to Top前回は仕様書レビューの品質データを「箱ひげ図」と「散布図」に同時に描画して可視化するところまで実施しました。
今回は可視化したデータを”層別”して分析し、品質のチェックポイント(勘所)を見つけていきたいと思います。
層別
#「層別」とは、数多くのデータを、データの特徴に基づいて、いくつかのグループに分けることです。
層別することでデータを分析し易くなります。
「分析」とは「物事を理解する」ことです。
”層別”を使って物事を理解するところから始めましょう。
段階を追って層別していきます。
層別の方法は以下に示すものが全てではありません。
データを見て、色々な層別方法を検討してみてください。
外れ値による層別
#前回使用したデータの散布図をもう一度見てみましょう。
(外れ値も含めたデータです)
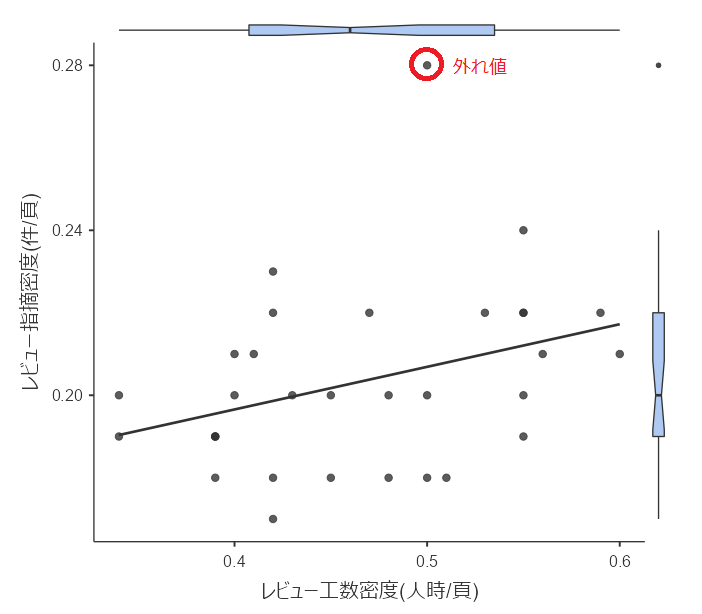
「外れ値を含むデータ」と「それ以外」で”層別”します。
図で見ると、外れ値は「レビュー指摘密度」側に現れています。
外れ値以外のデータに比べて、外れ値は明らかに指摘密度が高いことがわかります。
品質チェックの観点としては「当該仕様書に含まれていた欠陥が他の仕様書よりも多い可能性」などが考えられます。
ただし、指摘の内容が重要度の低い「誤字脱字」や「表現上の指摘」ばかりで、指摘件数が”水増し”されていないかを確認する必要があります。
よくある事例として、欠陥の抽出件数に”ノルマ”のようなものを課してしまうと、無理に欠陥数を捻出しようとして、重箱の隅をつつくように軽微な欠陥を掘り出すことがあるので、その点は注意すべきです。
直線近似で2分割して層別する
#次に、外れ値を除外したデータで確認していきます。
散布図に描いた直線近似線で、グラフを2分割して考えてみます。
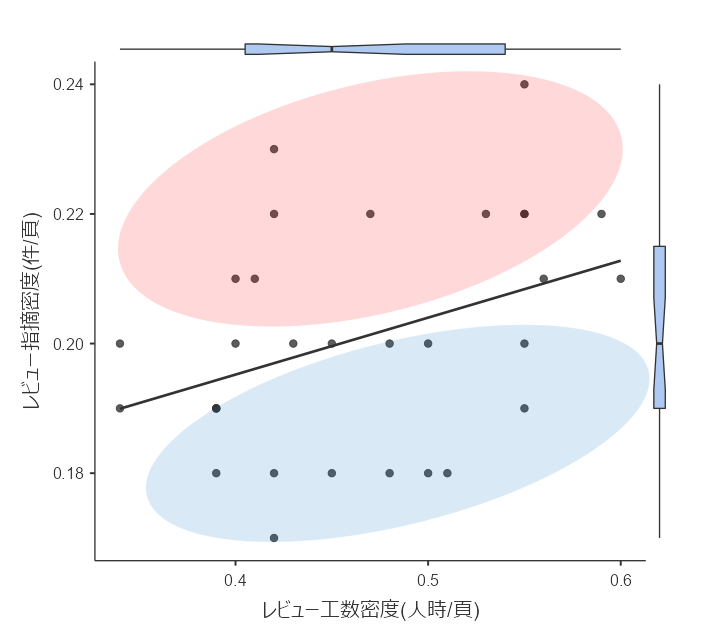
上図のように、大まかにですが「レビュー指摘密度が多いグループ」と「指摘密度が少ないグループ」に別けられました。
ですが、これだけだと「レビュー工数を投入しているからレビュー指摘件数が多い」「レビュー工数を投入していないからレビュー指摘件数が少ない」かどうかの判断に人間の主観が入ってしまいそうです。
次はもう少し細かく層別してみます。
中央値で4分割して層別する
#データの中央値で、グラフを4象限に分割して考えてみます。
中央値とは、データを小さい順に並べたとき、ちょうど中央に位置するデータのことです。データ数が偶数の場合は最も中央に近い2つのデータの平均値を用います。
中央値は箱ひげ図の第2四分位数として描画されています。
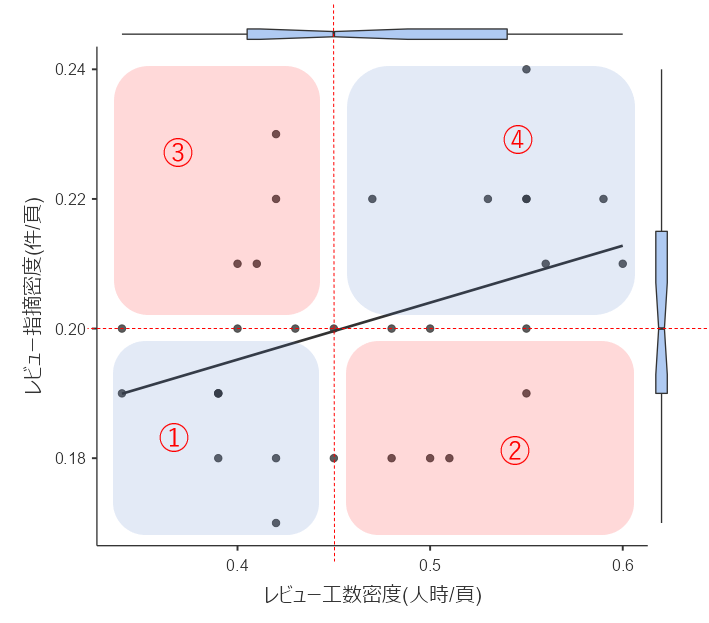
層別したエリアを、わかりやすいように赤と青の網掛けをして着色し、さらにエリアに番号を振りました。
- 1番:レビュー工数密度「小」、レビュー指摘密度「小」
- 2番:レビュー工数密度「大」、レビュー指摘密度「小」
- 3番:レビュー工数密度「小」、レビュー指摘密度「大」
- 4番:レビュー工数密度「大」、レビュー指摘密度「大」
1番と4番のエリアのデータについては、投入した工数に相当する指摘が確認されていると考えて「レビューは適切に行われた」可能性が高いと考えました。
ただし、1番のエリアにおいて、あまりにレビュー工数が少ないレビューは十分にレビューできていない可能性があり、要注意と判断すべきでしょう。
2番と3番のエリアのデータについては、投入した工数に対して説明がつかない指摘件数が上がっています。
2番では、工数を多く投入したにも関わらず指摘が少ない状況です。
考えられる原因としては「適切なレビューアがレビューに参加していない」などが考えられます。このデータを出した仕様書については少し詳しく調査する必要がありそうです。
3番では、工数を少ししか投入していないにも関わらず指摘が多い状況です。
考えられる原因としては「仕様書の品質が悪い」「未完成の仕様書をレビューした」などが考えられます。これも詳しく調査する必要がありそうです。もっと工数をかけてレビューをすれば欠陥が抽出される可能性があります。
グラフの中央値の線上に乗っているデータで、箱ひげ図の箱の外側に位置するデータについては要調査対象とするべきでしょう。
更に分析を進めたい場合、箱ひげ図の第1四分位数と第3四分位数で分割すると説明がしやすくなります。
通常、箱ひげ図の第1四分位数や第3四分位数を手計算で求めるのは大変ですが、jamoviであれば簡単に箱ひげ図を描画してくれます。
箱ひげ図の内側・外側で9分割して層別する
#箱ひげ図の内側・外側で、グラフを9分割して考えてみます。
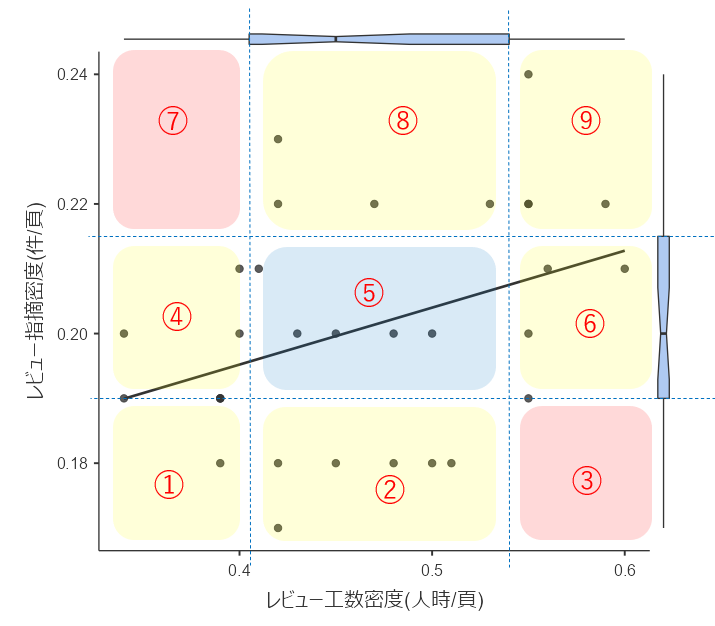
層別したエリアを、わかりやすいように赤と黄、青色の網掛けをして着色し、さらにエリアに番号を振りました。
- 1番:レビュー工数密度「箱下」、レビュー指摘密度「箱下」
- 2番:レビュー工数密度「箱中」、レビュー指摘密度「箱下」
- 3番:レビュー工数密度「箱上」、レビュー指摘密度「箱下」
- 4番:レビュー工数密度「箱下」、レビュー指摘密度「箱中」
- 5番:レビュー工数密度「箱中」、レビュー指摘密度「箱中」
- 6番:レビュー工数密度「箱上」、レビュー指摘密度「箱中」
- 7番:レビュー工数密度「箱下」、レビュー指摘密度「箱上」
- 8番:レビュー工数密度「箱中」、レビュー指摘密度「箱上」
- 9番:レビュー工数密度「箱上」、レビュー指摘密度「箱上」
上記の「箱上」「箱中」「箱下」の意味は
- 箱上:箱ひげ図の第3四分位数よりも上側
- 箱中:箱ひげ図の第1四分位数~第3四分位数の中
- 箱下:箱ひげ図の第1四分位数よりも下側
です。
4象限分割のときと同様に、5番のエリアのデータについては、投入した工数に相当する指摘が確認されていると考えて「レビューは適切に行われた」可能性が高いと考えました。
1番については、投入した工数が少なすぎます。
必要なレビュー工数が投入できていない可能性があるので注意が必要です。
9番については、あまり神経質になる必要はありませんが、極端に工数を消費しているレビューについては、工数を投入しすぎている可能性もあるので、どうしてそのようなレビューになったのかを確認したほうがいいかもしれません。
2番、4番、6番、8番のデータについても、「投入した工数」と「指摘件数」のいずれかが箱ひげ図の箱の外側のデータに存在します。
全件チェックするのが大変であれば、個別にサンプリングして内容を確認すべきでしょう。
3番、7番のエリアに今回のデータはほぼ見当たりませんが、品質チェックの観点から言うと「このエリアがもっとも危険度が高い」と思われます。
3番では、工数を多く投入したにも関わらず指摘が少ない状況です。
考えられる原因としては「適切なレビューアがレビューに参加していない」などが考えられます。このデータを出した仕様書については少し詳しく調査する必要がありそうです。
7番では、工数を少ししか投入していないにも関わらず指摘が多い状況です。
考えられる原因としては「仕様書の品質が悪い」「未完成の仕様書をレビューした」などが考えられます。これも詳しく調査する必要がありそうです。もっと工数をかけてレビューをすれば欠陥が抽出される可能性があります。
まとめ
#全データをしらみつぶしにチェックしていくのは大変ですが、今回のように「箱ひげ図」と「散布図」を組み合わせて、色々な視点で層別することで、どのデータについてどのような品質チェックを行えば良いか、ざっくりと判断することができました。
このように可視化することで、品質確認の必要性を説明し易くなると思います。
データ分析に活用して頂ければ幸いです。